This tutorial provides guidance on implementing a microsimulation model using the C++ programming language. We outline the conceptual steps and present a practical algorithm to operationalize these steps. As an example, we selected the Sick–Sicker model, closely following the structure introduced by Krijkamp et al. [16] in their R-based implementation. While we acknowledge certain limitations inherent to discrete-time microsimulation—such as the use of transition probability calculations that do not fully capture competing risks as naturally as continuous-time microsimulation models do—we preserved this approach to maintain conceptual simplicity and to allow direct comparison with the original model. For example, using matrix exponentiation of transition intensity matrices can better address competing risks and timing of events, but these were beyond the scope of this introductory tutorial. Our focus remained on discrete-time state-transition models, while also contrasting them conceptually with traditional Markov models characterized by the memoryless property.
We demonstrated that building a microsimulation model in C++ has several advantages. First, C++ offers superior computational performance compared with R, which is particularly crucial when dealing with large-scale simulations or models requiring numerous iterations. The compiled nature of C++ allows for significantly faster execution times and more efficient processing of complex algorithms. Second, C++ provides precise memory management capabilities, enabling developers to explicitly control memory allocation and deallocation. While we did not demonstrate this granular control over memory resources, it could be valuable especially in extensive simulations where memory efficiency is paramount and can help prevent memory leaks that might otherwise impact long-running simulations.
However, while C++ excels in computational efficiency, it lacks the comprehensive statistical analysis and visualization capabilities that R provides. R’s extensive ecosystem of statistical packages and plotting libraries makes it significantly more suitable for analyzing and presenting simulation results. To bridge this gap, researchers can utilize the Rcpp package [18], which enables seamless integration of C++ functions within R code. This approach allows for the best of both worlds: the computational efficiency of C++ for the core simulation logic combined with R’s powerful analysis and visualization capabilities. Alternatively, simulation results can be stored in external files (such as CSV) and subsequently imported into R or Excel for analysis and visualization. Finally, we demonstrated that traditional Markov modeling gains little, if any, advantage from using C++ over R.
Looking ahead, several crucial areas warrant further research and model development to expand the scope and impact of microsimulation models. While our focus has been on demonstrating C++’s computational efficiency in microsimulation, recent developments highlight the need for more sophisticated approaches that can handle increasing model complexity while maintaining computational feasibility.
The evolution of model sophistication, as exemplified by Kim et al.’s integrated disease interaction model [5] and Kazemian et al.’s community-level transmission dynamics framework [6], suggests that future microsimulation models will need to balance computational efficiency with enhanced complexity. A particularly promising direction lies in the incorporation of broader economic impacts into health-focused microsimulation models. By integrating the effects of improved health on work capacity, absenteeism, and overall economic output, these models could provide a more comprehensive assessment of health interventions’ societal value. This expansion would require sophisticated algorithms capable of handling both health state transitions and their corresponding economic implications efficiently.
The study of Wu et al. [7] in projecting socioeconomic inequalities demonstrates how modern microsimulation models must evolve beyond simple state transitions to capture multifaceted societal impacts. These models must be capable of simulating not only individual-level health trajectories themselves but also how these trajectories affect and are affected by socioeconomic factors such as income, education, and employment. Implementing such models in C++ provides access to low-level control of memory and computation, enabling efficient simulation of millions of individuals over long time horizons. Moreover, modern C++ supports parallel computing frameworks such as OpenMP [20], which allow different parts of the simulation to run simultaneously on multiple processor cores—significantly reducing runtime. In addition, vectorized instructions (SIMD [21]) allow the same operation (e.g., state update) to be applied across many individuals in parallel, further accelerating computation.
A critical direction for future research lies in expanding equity considerations within these models. For example, the UK’s National Health Service (NHS) Health Check microsimulation models [22, 23] provide a foundation that could be enhanced to evaluate not only the distribution of health benefits across different population groups but also the economic implications of health inequalities. This would involve developing algorithms capable of simultaneously tracking health outcomes, economic productivity, and equity metrics across various socioeconomic strata. In C++, this is supported by flexible data structures and templates, which allow for defining complex individual profiles without sacrificing performance.
The integration of broader societal impacts presents another crucial avenue for future research. The MICH framework [8] exemplifies how microsimulation models can analyze complex policy impacts through various socioeconomic pathways. This approach needs to be extended to incorporate more sophisticated economic modeling, including GDP impacts, workforce productivity, and broader macroeconomic effects. The coronavirus disease 2019 (COVID-19) modeling experience, particularly as demonstrated by Lustig et al. [24], provides valuable insights into integrating macroeconomic effects into microsimulation models, suggesting the need for comprehensive frameworks that can handle both health and economic outcomes efficiently. C++ offers interoperability with high-performance numerical libraries (e.g., Eigen [25]; Armadillo [26]), which enable precise and efficient implementation of such macroeconomic modules within microsimulation environments.
From a technical perspective, as noted by Eom and Li [27], these developments necessitate increasingly sophisticated computational approaches. Future research should explore how C++’s performance advantages can be leveraged to implement these complex economic–health interaction models while maintaining practicality in terms of development time and model maintenance. Importantly, modern C++ (C++17/20) offers features such as smart pointers, lambda functions, and improved modularity [28], which help reduce the risk of programming errors and make code more readable and maintainable—lowering the barrier for adoption by applied researchers.
Moreover, ensuring robust code validation and incorporating a transparent audit trail are critical for fostering confidence in model reliability. Tools such as the assertHE R package provide a structured framework for quality assurance by enabling automated unit testing, network visualization, and test coverage assessment, as demonstrated in recent applications of the Sick–Sicker model [29]. These practices should be adapted and integrated into C++ development workflows.
The successful integration of transmission dynamics in HIV interventions by Kazemian et al. [6] points to another important direction: developing efficient algorithms that can simultaneously handle individual-level clinical detail, population-level effects, and economic outcomes. This multi-level modeling approach requires careful consideration of data structures and computational optimization, particularly when scaling to large populations and incorporating complex economic feedback loops.
Moreover, the complexity demonstrated in Kim et al.’s [5] work on disease interactions suggests that future models will need to handle increasingly complex state spaces and transition probabilities, now extended to include economic state variables. This presents both technical challenges in terms of efficient implementation and methodological challenges in validating these complex health–economic interactions against real-world data.
In conclusion, while C++ provides the computational foundation needed for these advances, future research must focus on developing comprehensive frameworks that can efficiently handle the increasing complexity of combined health and economic modeling while maintaining model transparency and validity. This includes exploring how modern C++ features, parallel computing (e.g., OpenMP [20]), and vectorized operations (e.g., SIMD [21]) can be leveraged to implement more sophisticated models that capture multiple disease interactions, economic impacts, socioeconomic pathways, and equity considerations. We acknowledge the important consideration regarding the trade-off between the time and effort required for implementing models in different programming languages and the benefits gained in execution speed. While ease of use and familiarity with a given language such as R are practical advantages, scientific progress occasionally requires stepping outside one’s comfort zone. Transitioning to a lower-level language such as C++ may involve a steeper learning curve and greater initial development time, but it can yield substantial performance improvements that enable more realistic and scalable microsimulations. By expanding these models to incorporate both health outcomes and broader economic impacts—including productivity effects and GDP implications—researchers can support more effective, equitable, and economically sustainable policymaking. The integration of these elements, supported by efficient implementation, will be essential for developing the next generation of policy-relevant microsimulation models.





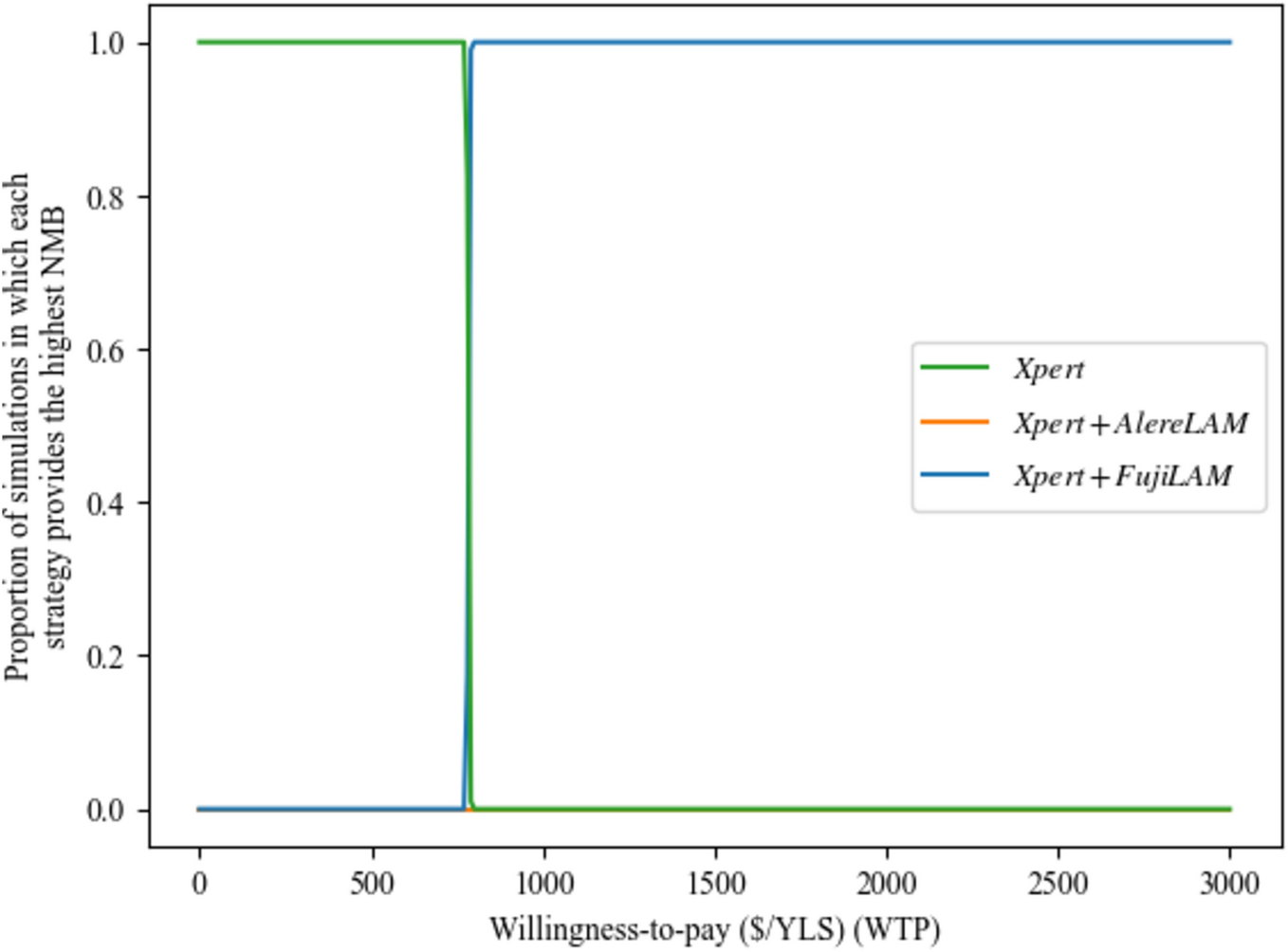
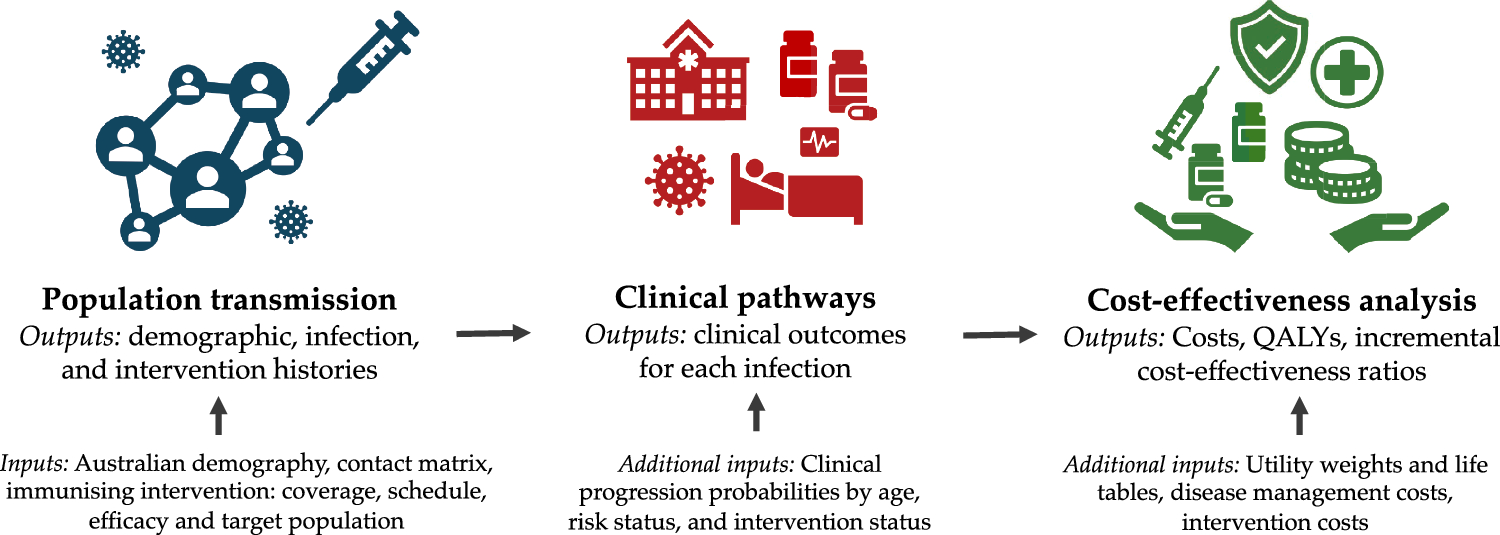
Comments (0)