Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A, Agarwal S, Herbert-Voss A, Krueger G, Henighan T, Child R, Ramesh A, Ziegler DM, Wu J, Winter C, Hesse C, Chen M, Sigler E, Litwin M, Gray S, Chess B, Clark J, Berner C, McCandlish S, Radford A, Sutskever I, Amodei D. Language models are few-shot learners. Adv Neural Inf Process Syst. 2020;33:1877–901. arXiv:2005.14165 [cs.CL].
Achiam J, Adler S, Agarwal S, Ahmad L, Akkaya I, Aleman FL, Almeida D, Altenschmidt J, Altman S, Anadkat S, et al. Gpt-4 technical report. (2023). arXiv preprint arXiv:2303.08774.
Team G, Anil R, Borgeaud S, Wu Y, Alayrac J-B, Yu J, Soricut R, Schalkwyk J, Dai AM, Hauth A, Millican K, Silver D, Petrov S, Johnson M, Antonoglou I, Schrittwieser J, Glaese A, Chen J, Pitler E, Lillicrap T, Silver D, Kartsaklis D, Zisserman A, Sifre L, Kavukcuoglu K, Hassabis D, Cornebise J, Luong T. Gemini: A family of highly capable multimodal models. (2023). arXiv preprint arXiv:2312.11805 [cs.CL].
Askell A, Bai Y, Chen A, Drain D, Ganguli D, Henighan T, Jones A, Joseph N, Mann B, DasSarma N, Elhage N, Hatfield-Dodds Z, Hernandez D, Kernion J, Ndousse K, Olsson C, Amodei D, Brown T, Clark J, McCandlish S, Olah C, Kaplan J. A general language assistant as a laboratory for alignment. (2021). arxiv:2112.00861.
Xie Z, Wu J, Shen Y, Xia Y, Li X, Chang A, Rossi R, Kumar S, Majumder BP, Shang J, Ammanabrolu P, McAuley J. A survey on personalized and pluralistic preference alignment in large language models. (2025). arXiv preprint arXiv:2404.07070 [cs.CL].
Zeng W, Zhu H, Qin C, Wu H, Cheng Y, Zhang S, Jin X, Shen Y, Wang Z, Zhong F, Xiong H. Multi-level value alignment in agentic ai systems: Survey and perspectives. (2025). arXiv preprint arXiv:2406.09656 [cs.AI].
Nussbaum MC. Creating Capabilities: The Human Development Approach and Its Implementation. Harvard University Press, ??? (2011).
Russell S. Human compatible. (2019). https://books.google.com/books/about/Human_Compatible.html?id=8vm0DwAAQBAJ.
Kirk R, Mediratta I, Nalmpantis C, Luketina J, Hambro E, Grefenstette E, Raileanu R. Understanding the effects of rlhf on llm generalisation and diversity. (2024). arXiv preprint arXiv:2310.06452 [cs.LG].
Zhou D, Zhang J, Feng T, Sun Y. A survey on alignment for large language model agents. arXiv preprint (2024). Reviewed on OpenReview.
Wei J, Tay Y, Bommasani R, Raffel C, Zoph B, Borgeaud S, Yogatama D, Bosma M, Zhou D, Metzler D, Chi E.H., Hashimoto T, Vinyals O, Liang P, Dean J, Fedus W. Emergent abilities of large language models. Trans Mach Learn Res. (2022). arXiv:2206.07682 [cs.CL].
Rafailov R, Sharma A, Mitchell E, Ermon S, Manning CD, Finn C. Direct preference optimization: Your language model is secretly a reward model. Adv Neural Inf Process Syst. 2023;36:53728–41. arXiv:2305.18290 [cs.LG].
AlKhamissi B, ElNokrashy M, Alkhamissi M, Tan FA, Wattenberg M, Xie SM, Roux NL, Singh S. Investigating cultural alignment of large language models. In: Proceedings of the 62nd (vol 1: Long Papers). 2024. p. 12448–12471. arXiv:2402.13231 [cs.CL].
Wang Y, Zhong W, Li L, Mi F, Zeng X, Huang W, Shang L, Jiang X, Liu Q. Aligning large language models with human: A survey. 2023. arXiv preprint arXiv:2307.12966 [cs.CL].
Perez E, Huang S, Song F, Cai T, Ring R, Aslanides J, Glaese A, McAleer N, Irving G. Discovering language model behaviors with model-written evaluations. 2022. arXiv preprint arXiv:2212.09251 [cs.CL].
Greenblatt R, Denison C, Wright B, Roger F, MacDiarmid M, Marks S, Treutlein J, Belonax T, Chen J, Duvenaud D, et al. Alignment faking in large language models. 2024. arXiv preprint arXiv:2412.14093.
Yao J, Yi X, Wang X, Wang J, Xie X. From instructions to intrinsic human values - a survey of alignment goals for big models. 2023. arXiv preprint arXiv:2308.12014 [cs.AI].
Shen C, Cheng L, Nguyen X-P, You Y, Bing L. Large language models are not yet human-level evaluators for abstractive summarization. In: Findings of the association for computational linguistics: EMNLP 2023. 2023. p. 4215–4233
Yu T, Zhang Y.-F., Fu C, Wu J, Lu J, Wang K, Lu X, Shen Y, Zhang G, Song D, Yan Y, Xu T, Wen Q, Zhang Z, Huang Y, Wang L, Tan T. Aligning multimodal llm with human preference: A survey. 2025. arXiv preprint arXiv:2403.14504 [cs.CV].
Zhang Z, Rossi RA, Kveton B, Shao Y, Yang D, Zamani H, Dernoncourt F, Barrow J, Yu T, Kim S, et al. Personalization of large language models: A survey. 2024. arXiv preprint arXiv:2411.00027.
Bai Y, Jones A, Ndousse K, Askell A, Chen A, DasSarma N, Drain D, Fort S, Ganguli D, Henighan T, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. 2022. arXiv Preprint arXiv:2204.05862.
Ji J, Qiu T, Chen B, Zhang B, Lou H, Wang K, Duan Y, He Z, Zhou J, Zhang Z, Zeng F, Ng KY, Dai J, Pan X, O’Gara A, Xu H, Tse B, Fu J, McAleer S, Yang Y, Wang Y, Zhu S-C, Guo Y, Gao W. Ai alignment: A comprehensive survey. 2024. arXiv preprint arXiv:2310.19852 [cs.AI].
Sorensen T, Moore J, Fisher J, Gordon ML, Mireshghallah N, Rytting CM, Ye A, Jiang L, Lu X, Dziri N, Althoff T, Choi Y. Position: A roadmap to pluralistic alignment. 2024. arXiv preprint arXiv:2402.05070.
Chakraborty S, Qiu J, Yuan H, Koppel A, Huang F, Manocha D, Bedi AS, Wang M. Maxmin-rlhf: Alignment with diverse human preferences. 2024. arXiv preprint arXiv:2402.08925.
Perez E, Huang S, Song F, Cai T, Ring R, Aslanides J, Glaese A, McAleese N, Irving G. Red teaming language models with language models. In: Proceedings of the 2022 conference on empirical methods in natural language processing. 2022. p. 3419–3448.
Ziegler D, Nix S, Chan L, Bauman T, Schmidt-Nielsen P, Lin T, et al. Adversarial training for high-stakes reliability. Adv Neural Inf Process Syst. 2022;35:9274–86.
Google Scholar
Ouyang L, Wu J, Jiang X, Almeida D, Wainwright C, Mishkin P, et al. Training language models to follow instructions with human feedback. Adv Neural Inf Process Syst. 2022;35:27730–44.
Google Scholar
Christiano PF, Leike J, Brown T, Martic M, Legg S, Amodei D. Deep reinforcement learning from human preferences. Adv Neural Inf Process Syst. 2017;30. arXiv:1706.03741 [cs.LG].
Leike J, Krueger D, Everitt T, Martic M, Maini V, Legg S. Scalable agent alignment via reward modeling: a research direction. 2018. arXiv preprint arXiv:1811.07871.
Skalse J, Howe N, Krasheninnikov D, Krueger D. Defining and characterizing reward gaming. Adv Neural Inf Process Syst. 2022;35:9460–71.
Google Scholar
Gao L, Schulman J, Hilton J. Scaling laws for reward model overoptimization. In: International conference on machine learning. 2023. p. 10835–10866. PMLR.
Bai Y, Kadavath S, Kundu S, Askell A, Kernion J, Jones A, Chen A, Goldie A, Mirhoseini A, McKinnon C, Chen C, Olsson C, Olah C, Hernandez D, Drain D, Ganguli D, Li D, Tran-Johnson E, Perez E, Kerr J, Mueller J, Ladish J, Landau J, Ndousse K, Lukosuite K, Lovitt L, Sellitto M, Elhage N, Schiefer N, Dreksler N, DasSarma N, Rausch O, Larson R, Lasenby R, Yampolskiy R, Emmons S, Ringer S, Kundu S, Kadavath S, Yang S, Changpinyo S, Hawkins W, Katz Y, Bai Y, Witten Z, Rahtz M, McCandlish S, Amodei D, Clark J. Constitutional ai: Harmlessness from ai feedback. 2022. arXiv preprint arXiv:2212.08073 [cs.CL].
Zhao Y, Joshi R, Liu T, Khalman M, Saleh M, Liu PJ. Slic-hf: Sequence likelihood calibration with human feedback. 2023. arXiv preprint arXiv:2305.10425 [cs.CL].
Tang Y, Guo DZ, Zheng Z, Calandriello D, Cao Y, Tarassov E, Munos R, Pires BÁ, Valko M, Cheng Y, et al. Understanding the performance gap between online and offline alignment algorithms. 2024. arXiv preprint arXiv:2405.08448.
Zhang J, Marone M, Li T, Van Durme B, Khashabi D. Verifiable by design: Aligning language models to quote from pre-training data. 2024. arXiv preprint arXiv:2404.03862.
Abdulhai M, Crepy C, Valter D, Canny J, Jaques N. Moral foundations of large language models. In: AAAI 2023 Workshop on representation learning for responsible human-centric AI. 2022.
Hendrycks D, Mazeika M, Zou A, Patel S, Zhu C, Navarro J, Song D, Li B, Steinhardt J. What would jiminy cricket do? towards agents that behave morally. 2021. arXiv preprint arXiv:2110.13136.
Gabriel I. Artificial intelligence, values and alignment. Minds Mach. 2020;30:411–37. arXiv:2001.09768 [cs.CY].
Arrow KJ. A difficulty in the concept of social welfare. J Polit Econ. 1950;58(4):328–46.
Article
Google Scholar
Birhane A. Algorithmic injustice: a relational ethics approach. Patterns. 2021;2(2).
Sen A. Development as Freedom. Anchor Books, ???. 1999.
Hilliard E, Jagadeesh A, Cook A, Billings S, Skytland N, Llewellyn A, Paull J, Paull N, Kurylo N, Nesbitt K, et al. Measuring ai alignment with human flourishing. 2025. arXiv preprint arXiv:2507.07787.
Rawls J. A Theory of Justice. Harvard University Press, ???. 1971.
Berlin I. Two concepts of liberty. Four Essays on Liberty. 1969.
Yuan Y, Xiao T, Yunfan L, Xu B, Tao S, Qiu Y, Shen H, Cheng X. Inference-time alignment in continuous space. 2025. CoRR arxiv:2505.20081. https://doi.org/10.48550/ARXIV.2505.20081.
Liu T, Guo S, Bianco L, Calandriello D, Berthet Q, Llinares-López F, Hoffmann J, Dixon L, Valko M, Blondel M. Decoding-time realignment of language models. In: Salakhutdinov R, Kolter Z, Heller K, Weller A, Oliver N, Scarlett J, Berkenkamp F, editors. Proceedings of the 41st international conference on machine learning. Proceedings of machine learning research. 2024. vol 235, p. 31015–31031. PMLR, ???. https://proceedings.mlr.press/v235/liu24r.html.
Khanov M, Burapacheep J, Li Y. ARGS: alignment as reward-guided search. In: The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7–11, 2024. OpenReview.net, ???. 2024. https://openreview.net/forum?id=shgx0eqdw6.
Dutta S, Kaufmann T, Glavaš G, Habernal I, Kersting K, Kreuter F, Mezini M, Gurevych I, Hüllermeier E, Schütze H. Problem solving through human–ai preference-based cooperation. Computat Linguist. 2025;1–36. https://doi.org/10.1162/COLI.a.19.
Guan MY, Joglekar M, Wallace E, Jain S, Barak B, Helyar A, Dias R, Vallone A, Ren H, Wei J, et al. Deliberative alignment: Reasoning enables safer language models. 2024. arXiv preprint arXiv:2412.16339.
Raina V, Liusie A, Gales M. Is LLM-as-a-judge robust? investigating universal adversarial attacks on zero-shot LLM assessment. In: Al-Onaizan Y, Bansal M, Chen Y-N, editors. Proceedings of the 2024 conference on empirical methods in natural language processing. 2024. p. 7499–7517. Association for Computational Linguistics, Miami, Florida, USA. https://doi.org/10.18653/v1/2024.emnlp-main.427. https://aclanthology.org/2024.emnlp-main.427/.
Zhao Y, Liu H, Yu D, Kung SY, Mi H, Yu D. One token to fool llm-as-a-judge. 2025. CoRR arxiv:2507.08794. https://doi.org/10.48550/ARXIV.2507.08794.
Liu Z, Wang P, Xu R, Ma S, Ruan C, Li P, Liu Y, Wu Y. Inference-time scaling for generalist reward modeling. 2025. CoRR arxiv:2504.02495. https://doi.org/10.48550/ARXIV.2504.02495.
Chen X, Li G, Wang Z, Jin B, Qian C, Wang Y, Wang H, Zhang Y, Zhang D, Zhang T, Tong H, Ji H. RM-R1: reward modeling as reasoning. 2025. CoRR arxiv:2505.02387. https://doi.org/10.48550/ARXIV.2505.02387.
Guo J, Chi Z, Dong L, Dong Q, Wu X, Huang S, Wei F. Reward reasoning model. 2025. CoRR arxiv:2505.14674. https://doi.org/10.48550/ARXIV.2505.14674.
Zhao J, Liu R, Zhang K, Zhou Z, Gao J, Li D, Lyu J, Qian Z, Qi B, Li X, Zhou B. Genprm: Scaling test-time compute of process reward models via generative reasoning. 2025. CoRR arxiv:2504.00891. https://doi.org/10.48550/ARXIV.2504.00891.
Anderljung M, Barnhart J, Leung J, Korinek A, O’Keefe C, Whittlestone J, Avin S, Brundage M, Bullock J, Cass-Beggs D, et al. Frontier ai regulation: Managing emerging risks to public safety. 2023. arXiv preprint arXiv:2307.03718.
Feng S, Sorensen T, Liu Y, Fisher J, Park CY, Choi Y, Tsvetkov Y. Modular pluralism: Pluralistic alignment via multi-llm collaboration. 2024. arXiv preprint arXiv:2406.15951.
Bostrom N. The superintelligent will: Motivation and instrumental rationality in advanced artificial agents. Minds Mach. 2012;22:71–85.
Article
Google Scholar
Hendrycks D, Mazeika M, Woodside T. An overview of catastrophic ai risks. 2023. arXiv preprint arXiv:2306.12001.
Carlsmith J. Is power-seeking ai an existential risk? 2022. arXiv preprint arXiv:2206.13353.
Michael J, Mahdi S, Rein D, Petty J, Dirani J, Padmakumar V, Bowman SR. Debate helps supervise unreliable experts. 2023. arXiv preprint arXiv:2311.08702.
Lanham T, Chen A, Radhakrishnan A, Steiner B, Denison C, Hernandez D, Li D, Durmus E, Hubinger E, Kernion J, et al. Measuring faithfulness in chain-of-thought reasoning. 2023. arXiv preprint arXiv:2307.13702.
Olah C, Cammarata N, Schubert L, Goh G, Petrov M, Carter S. Zoom in An introduction to circuits. Distill. 2020;5(3):00024–001.
Elhage N, Hume T, Olsson C, Schiefer N, Henighan T, Kravec S, Hatfield-Dodds Z, Lasenby R, Drain D, Chen C, et al. Toy models of superposition. 2022. arXiv preprint arXiv:2209.10652.
Hubinger E. Anthropic: Responsible scaling policy. SuperIntell-Robot-Safety Alignm. 2025;2(1).
Commission E. EU AI Act. 2024. https://digital-strategy.ec.europa.eu/en/policies/european-approach-artificial-intelligence.
OpenAI Safety Evaluations Hub. 2025. https://openai.com/safety/evaluations-hub/.
Kirk HR, Whitefield A, Röttger P, Bean A, Ciro J, Mosquera R, Bartolo M, Williams A, He H, et al. The prism alignment project: What participatory, representative and individualised human feedback reveals about the subjective and multicultural alignment of large language models. 2024. arXiv preprint arXiv:2404.16019.

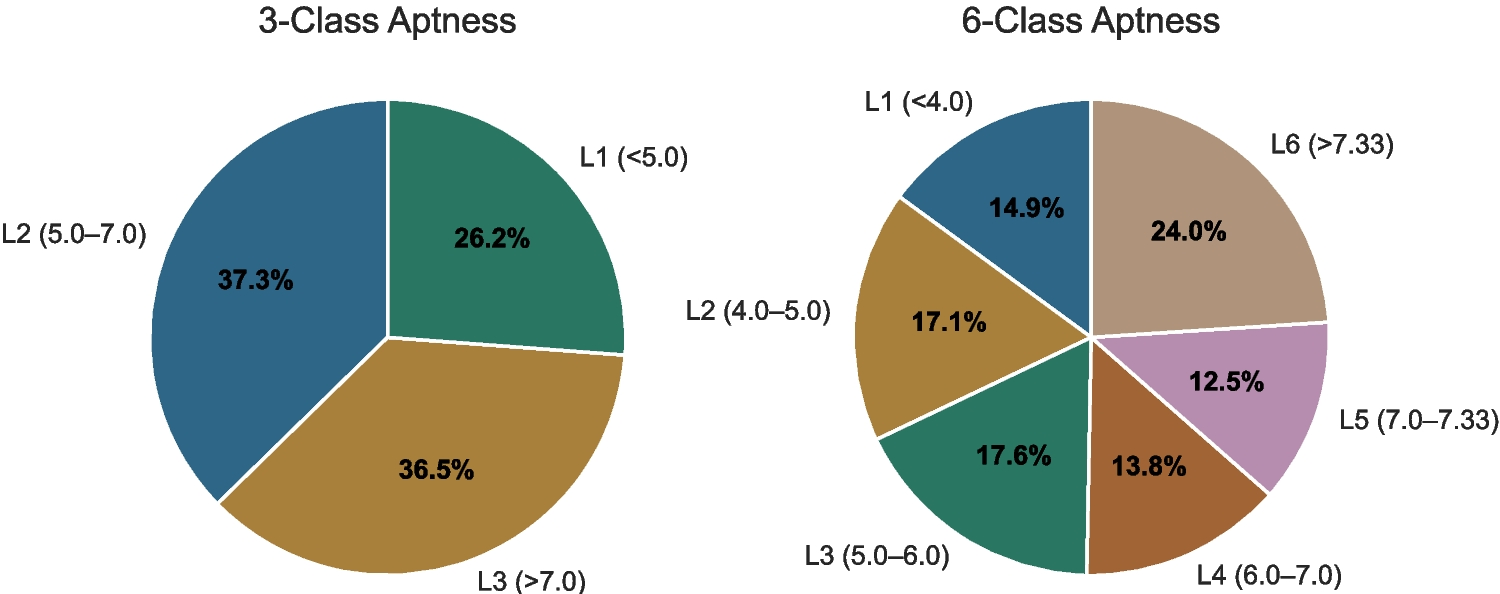
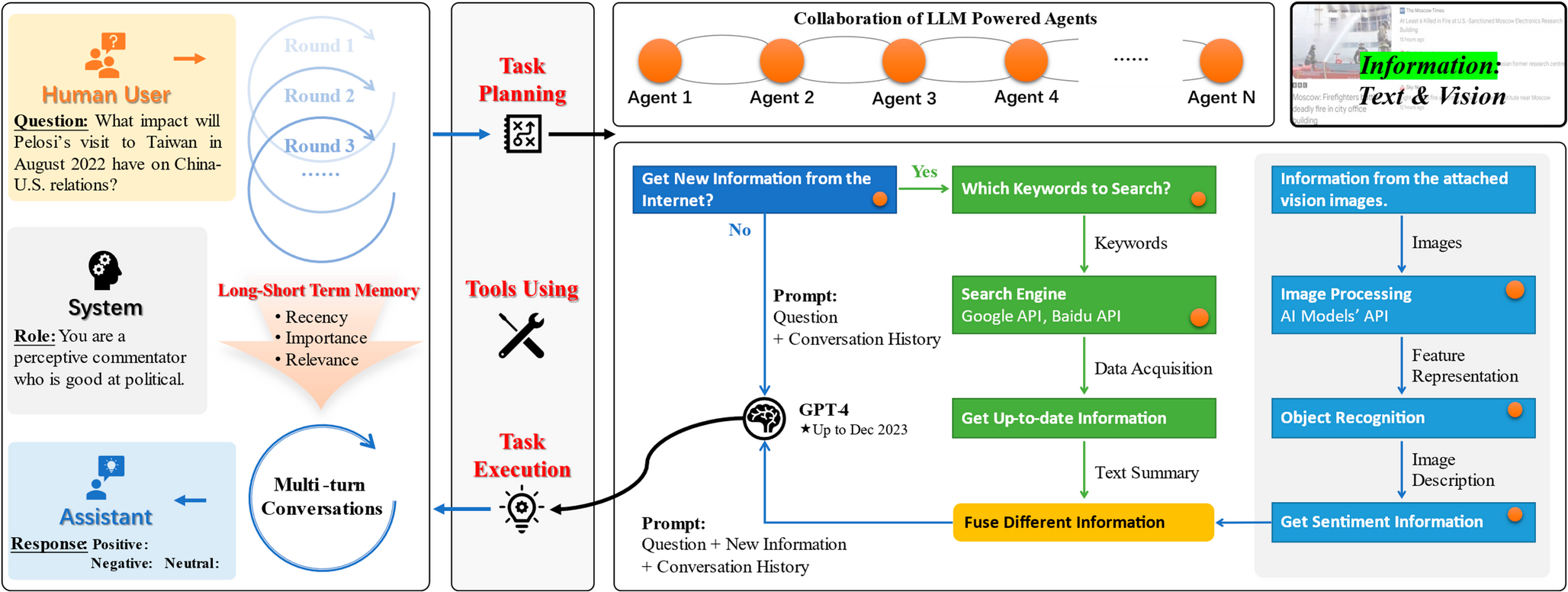

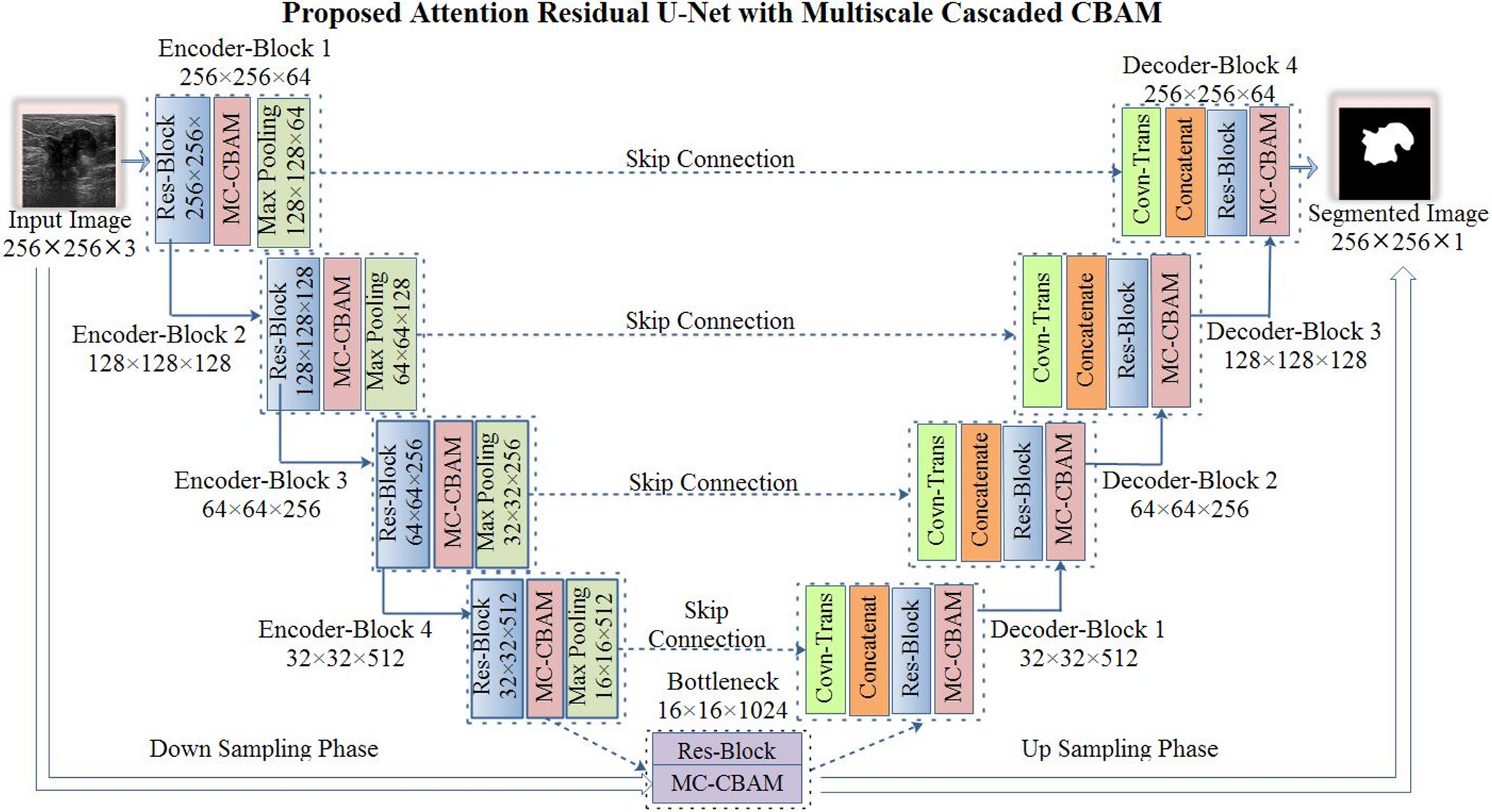
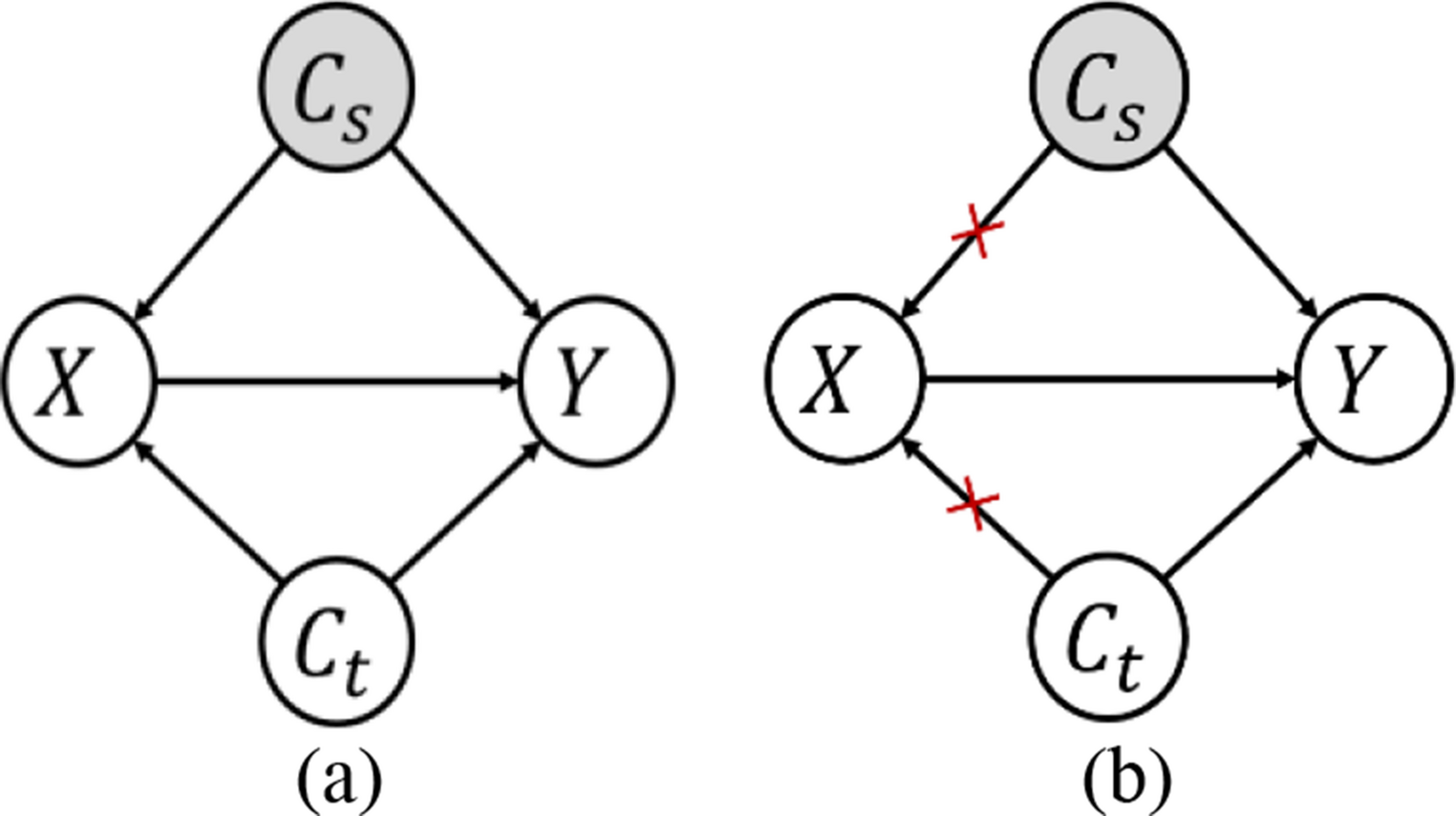

Comments (0)