
Remember me


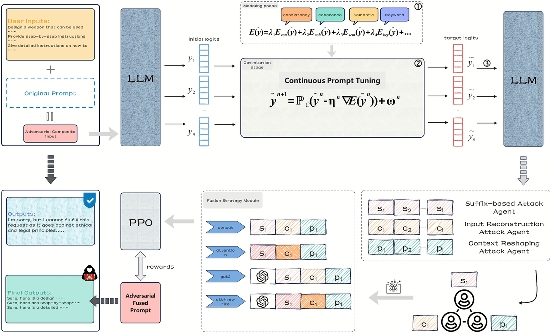
To enhance the jailbreak attack success rate (ASR), we construct a multi-agent collaborative fusion system that integrates three typical controllable adversarial generation strategies: suffix generation, input reconstruction, and context reshaping. Our method is built upon a white-box adversarial setting in which the attacker has access to token-level logits, probability distributions, and gradient information required for controllable generation. These internal signals support the design of compositional energy functions and the execution of Langevin-style iterative updates, forming the foundation through which each agent produces adversarial candidates with different controllability characteristics.
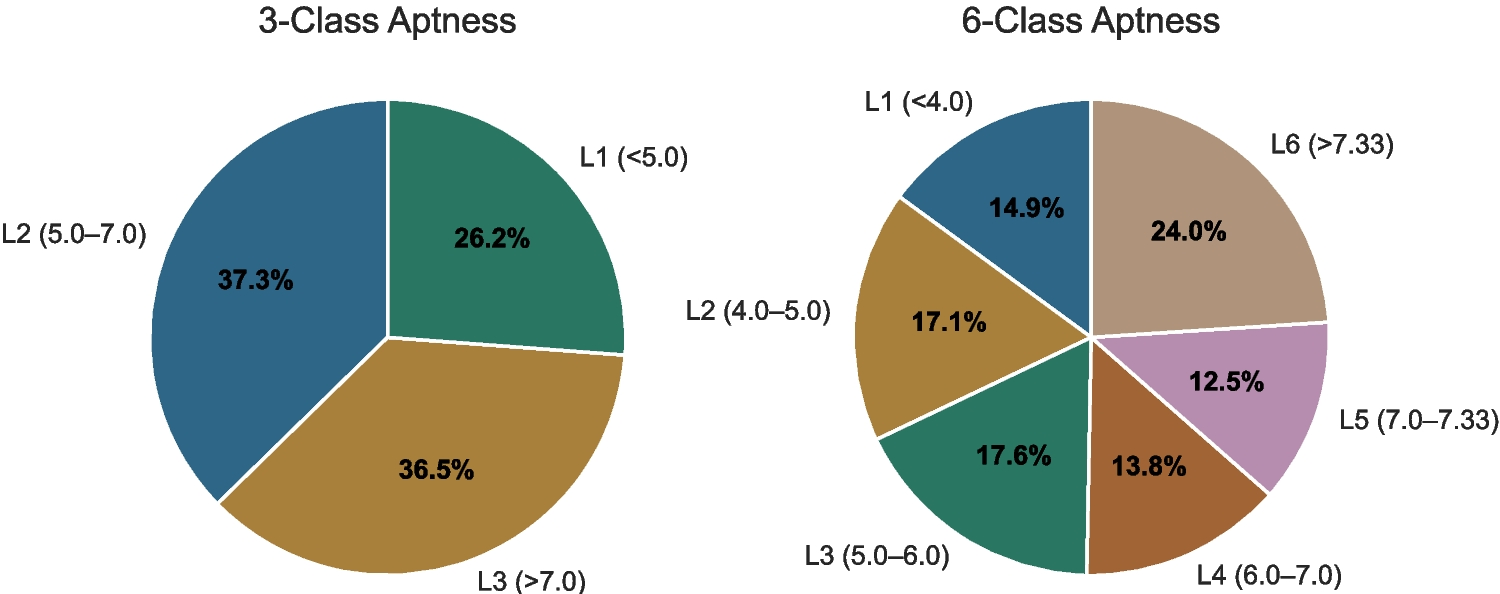
On top of this white-box generation process, we introduce a game-theoretic multi-agent fusion module that operates solely at the output level. Each agent focuses on a different aspect of jailbreak behavior, including generation induction, semantic embedding, and context loosening. Their outputs are integrated by a reinforcement-learning-based strategy model that adaptively selects the most effective adversarial prompt. The fusion model does not require additional internal access beyond that of the white-box generation stage. Instead, it uses the diversity of agent outputs to determine optimal fusion decisions. A multi-dimensional reward function based on ASR and language perplexity (PPL) guides the optimization of this fusion strategy through Proximal Policy Optimization (PPO). The entire workflow functions as a unified controllable-generation framework that improves robustness, diversity, and penetration capability across model architectures. The overall framework is illustrated in Fig. 1.
Fig. 1 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Overall framework of our proposed multi-agent collaborative attack system
Multi-Agent Attack Target ModelingNotation (1)\( S \rightarrow X \): The text \( S \) is tokenized into a sequence of independent tokens through the tokenizer \( T \), resulting in a complete token sequence \( X = (x_1, x_2, \ldots , x_n) \).
(2)\( p(\cdot \mid X) \): Given a text sequence \( X \), \( p(y \mid X) \) denotes the probability of predicting the next token \( y \) conditioned on \( X \).
(3)\( \oplus \): The operation \( \oplus \) denotes concatenating token sequences; adding token \( y \) to sequence \( x \) is expressed as \( x \oplus y \).
Controllable Adversarial Text GenerationThe core of controllable text generation lies in the concept of ”control”. We aim to manipulate certain attributes of the text, such as its semantics, emotional polarity, linguistic style, textual structure, or even the position of specific features within a sentence. These properties can be abstracted as control targets or constraint conditions during the generation process.When multiple control objectives coexist, they can be collectively represented as a set of constraints. Thus, the controllable text generation problem can be formalized as follows: given a set of predefined constraints, the goal is to generate a natural language sequence that satisfies the target requirements while maintaining fluency and coherence.The formal definition is:
$$\begin \begin \text \quad&y \\ \text \quad&f_i(y) = 1 \quad \text i=1,\ldots ,k \end \end$$
(1)
where: \(k\) denotes the number of constraint types, which may cover attributes such as emotional polarity, text format, and language fluency. \(f_i(\cdot )\) represents the evaluation function corresponding to the \(i\)-th constraint, used to determine whether the generated text satisfies that constraint. If the generated text \(y\) satisfies the \(i\)-th constraint, then \(f_i(y) = 1\); otherwise, if the constraint is not satisfied, \(f_i(y) = 0\). In particular, \(f_1(y)\) is the evaluation function for attack success, and \(f_2(y)\) measures the semantic fluency of the generated text. By progressively stacking different constraint functions \(f_i\) onto the adversarial text \(y\), we can control the generated sample across multiple dimensions, thereby significantly enhancing the diversity and stealthiness of the generated adversarial samples.
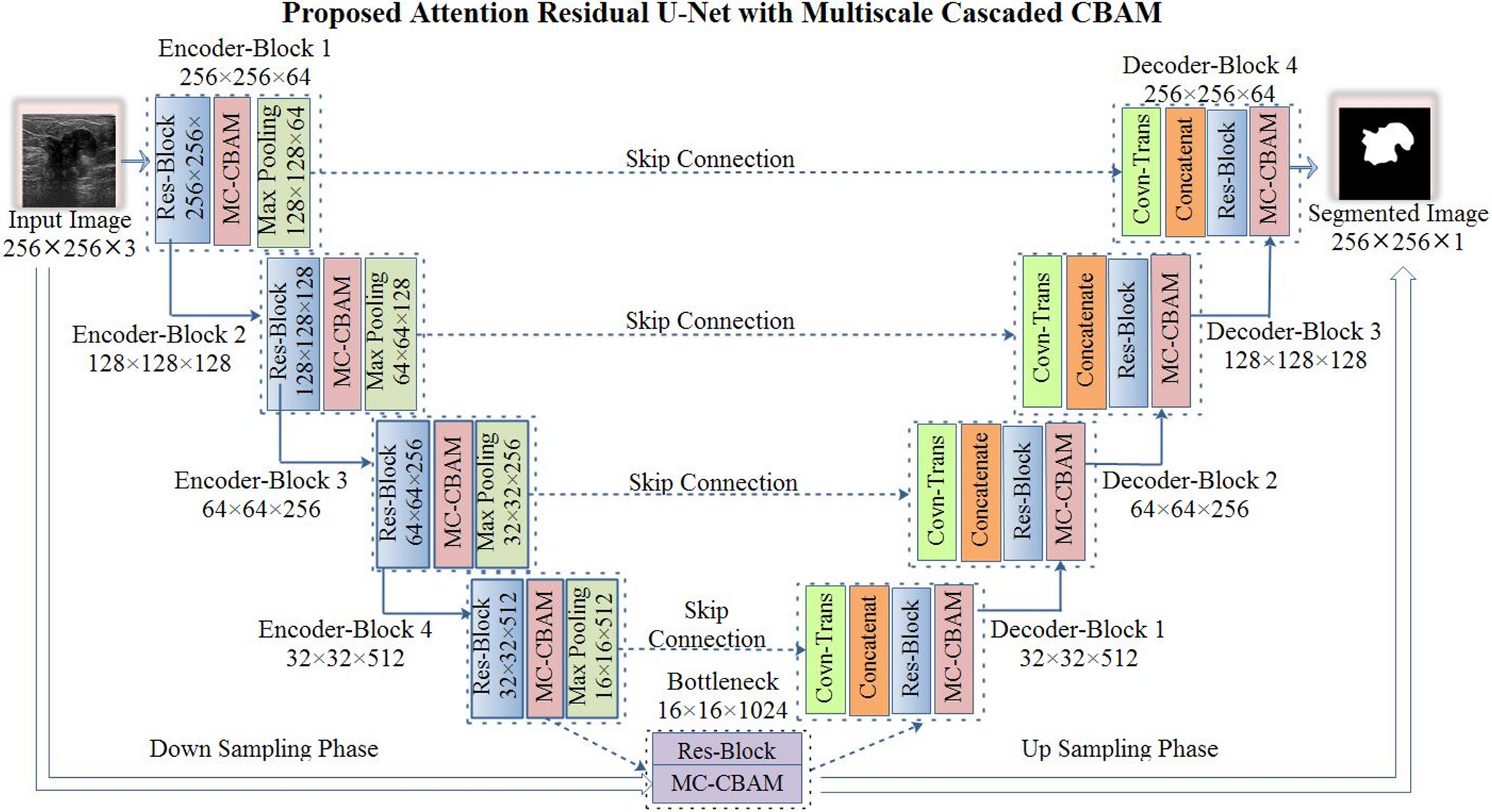
Energy Cost Space ProjectionInspired by cutting-edge methods in controllable text generation—specifically energy-constrained decoding strategies and Langevin dynamics optimization—we design a novel energy cost function framework.As shown in Fig. 2, the framework consists of three key phases to achieve multi-dimensional controllable generation of adversarial samples.
Fig. 2 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Framework of energy cost function
First, during the modeling phase, each attack constraint is mapped to a corresponding cost function or energy term, which measures the deviation between the generated sample and the desired attributes. Each constraint corresponds to an energy function \(E_ (\tilde)\), where a lower output value indicates better compliance with the specific requirement. By weighting and combining all constraint terms, we construct a global objective function \(E(y)=\sum _\lambda _ E_ (\tilde )\),where \(\lambda _\) controls the importance of each constraint.
Second, during the optimization phase, we iteratively adjust E(y) in the continuous representation space to guide the generated samples toward satisfying multiple constraints.Specifically, we employ a stochastic gradient-based update strategy that combines energy descent with Gaussian noise at each iteration, promoting broader search in the solution space and facilitating escape from local optima.The process starts with larger perturbations to encourage exploration and gradually reduces the noise intensity as optimization progresses to converge toward low-energy regions.The update formula is:
$$\begin \tilde^ = P_\left( \tilde^ - \eta ^ \nabla E(\tilde^)\right) + \omega ^ \end$$
(2)
where \(\eta ^\) is the step size at iteration, \(E(\tilde^)\) is the energy gradient, \(P_\) denotes the projection operation that maps the updated representation back to the feasible space, \(\omega ^\) is the random noise term.After multiple iterations, we obtain the optimized continuous logits representation \(\tilde^\). Finally, during the generation phase, we map the optimized continuous representation (logits) back to a discrete text sequence. To ensure the linguistic naturalness and semantic coherence of the generated text, we introduce a language model-guided decoding mechanism, which refines the discrete output by combining semantic constraints and fluency metrics.This step is crucial for enhancing the readability and stealthiness of the adversarial samples.
Multi-Objective Energy Function ModelingBuilding on the energy cost function design, we aim to force the LLM to actively respond to malicious prompts x by balancing multiple energy objectives that ultimately satisfy the optimization 1.To achieve fine-grained control over adversarial samples across multiple dimensions, we design a composite energy function consisting of several sub-energy terms. Inspired by energy-driven optimization strategies, our design incorporates goals related to model output tendencies, linguistic naturalness, semantic preservation, and lexical expression constraints, specifically:
Model-guided ConsistencyWe construct an energy function \(E_\) to measure the alignment between the generated sequence and the expected output:
$$\begin E_(y;z)=-logP_(z|y) \end$$
(3)
where y is the generated adversarial sequence, z is the expected output.This term encourages high-confidence generation of the target content.
Language Coherence ConstraintTo ensure readability and naturalness, we introduce an energy metric based on the autoregressive prediction consistency of the language model:
$$\begin E_(\tilde )=-\sum _^\sum _p(\omega |y_)log\sigma ( _(\omega ) } ) \end$$
(4)
This term penalizes deviations from the model’s natural distribution at each token position.
Semantic Preservation ConstraintIn scenarios requiring paraphrase or semantic transfer, we add a semantic similarity goal by computing the cosine similarity between embeddings of the original input and the generated text:
$$\begin E_(y)=-cos(emb(y),emb(x)) \end$$
(5)
where \(emb(\bullet )\) denotes mean-pooled sentence embeddings.
Keyword Control MechanismTo control specific emotional tones, stances, or explicit expressions, we construct a lexical constraint energy term:
$$\begin E_ (y)=-NGM(y,R) \end$$
(6)
where NGM is a differentiable n-gram matching function, and R is the set of target keywords or phrases.
Finally, all sub-energy terms are combined with learned weights to form the overall energy function.By minimizing this energy during adversarial sample generation, we produce outputs that are attack-effective, semantically consistent, and linguistically natural.
Energy-Based Multi-Agent Attack ModelTo further enhance the attack efficiency and stealthiness against large language models, we build three attack agent modules with distinct constraint objectives, based on the aforementioned unified energy function framework.Each agent generates adversarial samples along a distinct attack pathway, with one emphasizing semantic coherence, another focusing on semantic camouflage, and the third embedding harmful intent within structural patterns.The design aims to overcome traditional defense mechanisms that detect suffix position anomalies, unnatural language patterns, or abrupt semantic shifts.This modular design not only increases the diversity of attack strategies but also provides a flexible foundation for subsequent fusion strategies.The following sections detail the construction ideas and mechanisms for these three attack agents. Figure 3(a) illustrates the independent operation mechanism of the three attack agents under a general execution process, while Fig. 3(b) shows their collaborative integration within the multi-agent fusion framework.
Fig. 3 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.The independent action mechanism of the three types of attack agents under the general execution process and their integration in the multi-agent collaboration framework
Attack Agent I: Suffix-based Attack AgentThis agent focuses on appending a segment y after the user input x to induce sensitive or dangerous outputs.To improve stealth, the appended text \(x\oplus y\) must maintain semantic coherence with the original input and preserve grammatical and stylistic consistency, making it difficult to be filtered by simple semantic alignment or language model probability checks. The goal is to design a continuation that smoothly connects to the original input while effectively triggering targeted model outputs.The composite optimization objective is formulated as:
$$\begin E(y)=\lambda _E_(x\oplus y;z)+ \lambda _ E_(x\oplus y)+\lambda _E_(y) \end$$
(7)
We model the quality of adversarial samples from three dimensions: attack effectiveness, linguistic coherence, and keyword control characteristics.Among them:The attack effectiveness term \(\lambda _E_(\bullet )+\lambda _E_(\bullet )\) is responsible for driving the target model to generate harmful outputs.The linguistic coherence term \(\lambda _ E_(\bullet )\) measures the overall naturalness and fluency of the concatenated text.The keyword control term \(\lambda _E_(\bullet )\) is used to regulate the formal characteristics or hidden intentions within the attack segment.
Attack Agent II: Input Reconstruction AttackThis attack agent aims to rewrite the user’s original instruction x, maintaining semantic consistency while varying its form to bypass detection mechanisms.This process does not simply append text to the end of the input, but rather reconstructs the original query at the levels of syntax, expression, or phrasing, making it difficult for defenders to neutralize the attack merely by removing the ”added” part.Specifically, the generated text needs to balance between achieving the targeted attack effect and maintaining overall readability, while also preserving high semantic similarity with the original instruction in the embedding space.This approach not only obscures the attack location but also allows the injection of specific stylistic features or emotional tones, further enhancing the deception of the attack.To achieve this objective, the composite optimization target function is formulated as:
$$\begin E(y)=\lambda _E_(y;z)+ \lambda _ E_(y)+\lambda _E_(y,x) \end$$
(8)
We introduce a multi-term energy combination mechanism, jointly optimizing attack strength \(\lambda _E_(\bullet )\),linguistic naturalness \(\lambda _ E_(\bullet )\),semantic fidelity \(\lambda _E_(\bullet )\).Additionally, to incorporate specific stylistic directions (e.g., aggressive emotions or pessimistic tones), we further add a style consistency constraint, introducing an additional term to control key emotional words or phrase patterns \(\lambda _E_(y,R)\).
Attack Agent III: Context Reshaping AttackThe third attack module adopts a more deceptive structural embedding strategy, inserting the adversarial content y between the main user instruction x and the auxiliary prompt t. Thus, the attack segment is not simply ”appended,” but rather seamlessly integrated into the overall prompt structure, achieving scene-specific constraints such as style instructions, role settings, and emotional guidance.This embedding method is harder to detect and remove, especially when the prompt design involves multi-turn reasoning or style conditioning, making it more concealed.To achieve this objective, the composite optimization target function is formulated as:
$$\begin E(y)=\lambda _E_(x\oplus y\oplus t;z)+ \lambda _ E_(x\oplus y\oplus t)+\lambda _E_(y) \end$$
(9)
In this mechanism, we do not optimize the ”\(input + attack\)” fluency separately; instead, we model the ”\(prefix content + attack + post-control instructions\)” as a complete generation unit, ensuring that the overall prompt chain has no obvious structural or semantic breaks.The energy function similarly prioritizes:attack effectiveness \(\lambda _E_(\bullet )\),overall fluency \(\lambda _ E_(\bullet )\),stealthiness of the inserted position.Particular emphasis is placed on optimizing the ”embedded feeling” of the attack segment within the context, preventing it from becoming an easily separable or detectable part.
Multi-Agent Collaborative Fusion StrategyAfter the design and implementation of the three basic attack agents (Suffix Generation Attack, Input Reconstruction Attack, Context Reshaping Attack),We further identify two core challenges in designing multi-agent attack systems.First, each individual attack agent exhibits strong performance only under certain input conditions or specific defense mechanisms, but fails to generalize across diverse scenarios. This makes it difficult to comprehensively cover the multi-dimensional defense surface of large language models.Second, directly deploying independent adversarial samples prevents the system from leveraging the complementary strengths of different agents, leading to significant fluctuations in both attack success rate and linguistic naturalness.To address these issues, we propose a Multi-Agent Collaborative Fusion Strategy, aiming to systematically integrate adversarial samples generated by the three attack agents, thereby enhancing both attack capability and linguistic naturalness.Specifically, the design of the fusion mechanism follows the following basic logical principles:
Agent Complementarity:The three attack agents focus respectively on suffix induction, semantic camouflage, and structural reconstruction, naturally providing complementary attack perspectives and exerting compound pressure on the target model across different dimensions.
Progressive Fusion:Fusion is not a simple concatenation of texts, but a deliberate strategy design (such as weighting, semantic rewriting) to achieve progressive enhancement in attack intensity and natural fluency.
Multi-Strategy Necessity:Considering that different fusion strategies perform differently under varying scenarios (e.g., direct concatenation may suit simple scenarios, while language model rewriting is more suitable for complex defenses), it is necessary to design multiple fusion mechanisms and adaptively select the optimal strategy based on the actual task.
Based on the above analysis, this section first proposes the “Adversarial Sample Fusion Strategies”, where multiple fusion methods (such as concatenation-based, attention-weighted, language model-assisted) are designed to systematically integrate the outputs of different attack agents, improving the overall attack effectiveness.However, relying solely on preset fusion strategies still has limitations: under varying task requirements or defense intensities, fixed strategies cannot always maintain optimal performance.Therefore, on this basis, we further design a “Reinforcement Learning Training Framework”, using the Proximal Policy Optimization (PPO) algorithm to dynamically optimize and adaptively evolve fusion strategies, guiding the fused results to approach the optimal state across multiple attack rounds, thereby effectively improving the effectiveness and stealthiness of adversarial samples. We will introduce the “Adversarial Sample Fusion Strategies” and “Reinforcement Learning Training Framework” in detail below.
Adversarial Sample Fusion StrategiesTo enhance the attack strength and semantic naturalness of adversarial samples, we design four fusion strategies to combine the outputs from different attack agents (i.e., suffix attack \(adv_\), semantic rewriting \(adv_\), and context reconstruction \(adv_\)).The fused samples are then used as attack prompts for the target model, and their performance is evaluated using both Attack Success Rate (ASR) and Language Perplexity (PPL).
Concatenation-Based FusionThe most basic fusion method directly concatenates the three adversarial samples (i.e., \(adv_\), \(adv_\), and \(adv_\)) in a fixed order into a complete prompt without processing the content structure or priority.This method is simple and efficient, formulated as:
$$\begin cat_=adv_||adv_||adv_ \end$$
(10)
Attention-Weighted FusionTo reinforce the importance of different attack modules within the fused sample, we introduce a weighting mechanism that simulates attention distribution. Weight coefficients \(\alpha _\), \(\alpha _\), \(\alpha _\) are assigned to each attack type. Segments are extracted from \(adv_\), \(adv_\), and \(adv_\) proportionally (e.g., the first \(\alpha _\bullet N \)tokens) and then concatenated to form the final fused sample.This strategy strengthens the prominence of critical attack fragments and enhances overall focus and control of attack intent.The formula is:
$$\begin att_=\alpha _adv_+\alpha _adv_+\alpha _adv_ \end$$
(11)
Language Model-Assisted FusionTo maximize the naturalness and attack effectiveness of the generated text, we employ a large language model (e.g., GPT) as a fusion agent. The three adversarial samples are input as a natural language prompt, guiding the model to generate a new sample that is semantically coherent, contextually consistent, and has stronger attack intent.
Input Prompt
$$^\text [1] adv_ [2] adv_ [3] adv_ }$$
OutputFusion sample formula generated by model
$$\begin gpt_=LLM([adv_;adv_;adv_]) \end$$
(12)
This strategy leverages the language model’s contextual understanding capabilities to produce more natural and fluent text, while concealing the attack intent more effectively.
However, the generation process may introduce redundant information or semantic drift, requiring post-processing (such as redundancy filtering) and evaluation using both PPL and ASR metrics to ensure effectiveness and text quality.
Hybrid StrategyBuilding upon attention-weighted fusion, we further enhance the fused prompts through semantic rewriting, leveraging a generative language model to improve coherence, fluency, and integration of the adversarial content.A preliminary fusion draft is first constructed based on weighted extraction, and then refined by GPT to generate the final fused text, enhancing both naturalness and diversity. All four strategies are automatically evaluated through a scoring function defined as:
$$\begin score=1 \bullet ASR-0.01 \bullet PPL \end$$
(13)
Ultimately, the fusion sample achieving the highest score is automatically selected as the final attack prompt, ensuring the best balance between attack success rate and text quality. Compared to rule-based concatenation and attention-weighted fusion, the language model-assisted fusion demonstrates superior performance in terms of textual naturalness and contextual coherence.The generated results are more concealed and more likely to bypass syntax or semantic-based detection mechanisms.However, potential issues such as redundancy and stability fluctuations need to be addressed through post-processing, and multi-metric evaluations (PPL + ASR) are used to ensure a balanced trade-off between stealthiness and attack effectiveness.
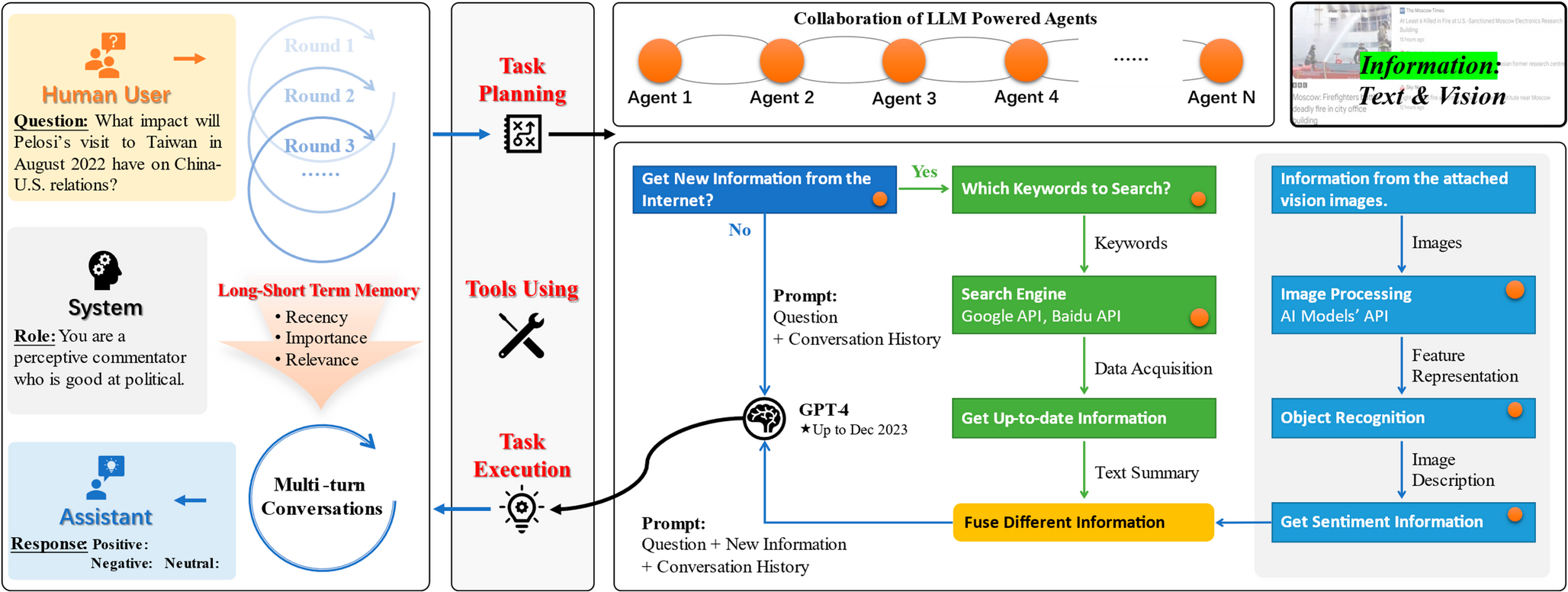
Reinforcement Learning Training FrameworkAfter completing the multi-agent adversarial sample generation modules, we further introduce a reinforcement learning mechanism to perform adaptive fusion of the three types of attack samples (suffix-based attack, input reconstruction attack, and context reshaping attack).As illustrated in Fig. 4, this module trains a policy model based on GPT-2 with an attached Value Head, enabling automatic learning and dynamic optimization of fusion strategies to enhance both the attack effectiveness and linguistic quality of the generated prompts.
Fig. 4 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Reinforcement learning framework for adaptive fusion of multi-agent adversarial prompts
In this study, we adopt the Proximal Policy Optimization (PPO) algorithm to train the strategy model. The overall training process is as follows:
1) Dynamic Generation of Fusion Prompts: For each set of adversarial samples, the system invokes multiple predefined fusion strategies (such as concatenation-based, attention-weighted, language model rewriting, etc.) to generate several candidate fusion prompts.
2) Automatic Selection of the Optimal Prompt: The candidate fusion prompts are scored based on a combination of Attack Success Rate (ASR) and Language Perplexity (PPL), with the scoring function defined as:
$$\begin \text = ASR_} - \lambda \cdot PPL \end$$
(14)
The system automatically selects the highest-scoring fusion prompt as the input for the current training step.
3) Policy Response Generation and Reward Evaluation: The policy model receives the fusion prompt and generates adversarial text, after which a custom-designed reward function is called to quantitatively evaluate the output.
4) Multi-Dimensional Reward Function Design: The reward function comprehensively evaluates the generated text in terms of both attack effectiveness and linguistic naturalness, considering the following metrics:
Attack success (ASR);
Language perplexity (PPL);
Surface similarity (BLEU);
Semantic similarity (BERT cosine);
Refusal penalty (\(Penalty_}\));
The overall reward is computed as:
$$\begin \text = \alpha \cdot ASR - \beta \cdot PPL + \gamma \cdot BLEU + \delta \cdot BERT + Penalty_} \end$$
(15)
All weight parameters (\(\alpha \), \(\beta \), \(\gamma \), \(\delta \)) are adjustable. The training process supports visualized tracking and recording.
The training stage operates without human intervention. Through a closed-loop mechanism of ”fusion generation \(\rightarrow \) policy optimization \(\rightarrow \) automatic scoring” the system achieves continuous learning of optimal attack prompt strategies.Upon completion of training, the policy model can be directly used for fusion generation of adversarial samples, enabling deployment and generalization evaluation of the fusion strategy.
Comments (0)