
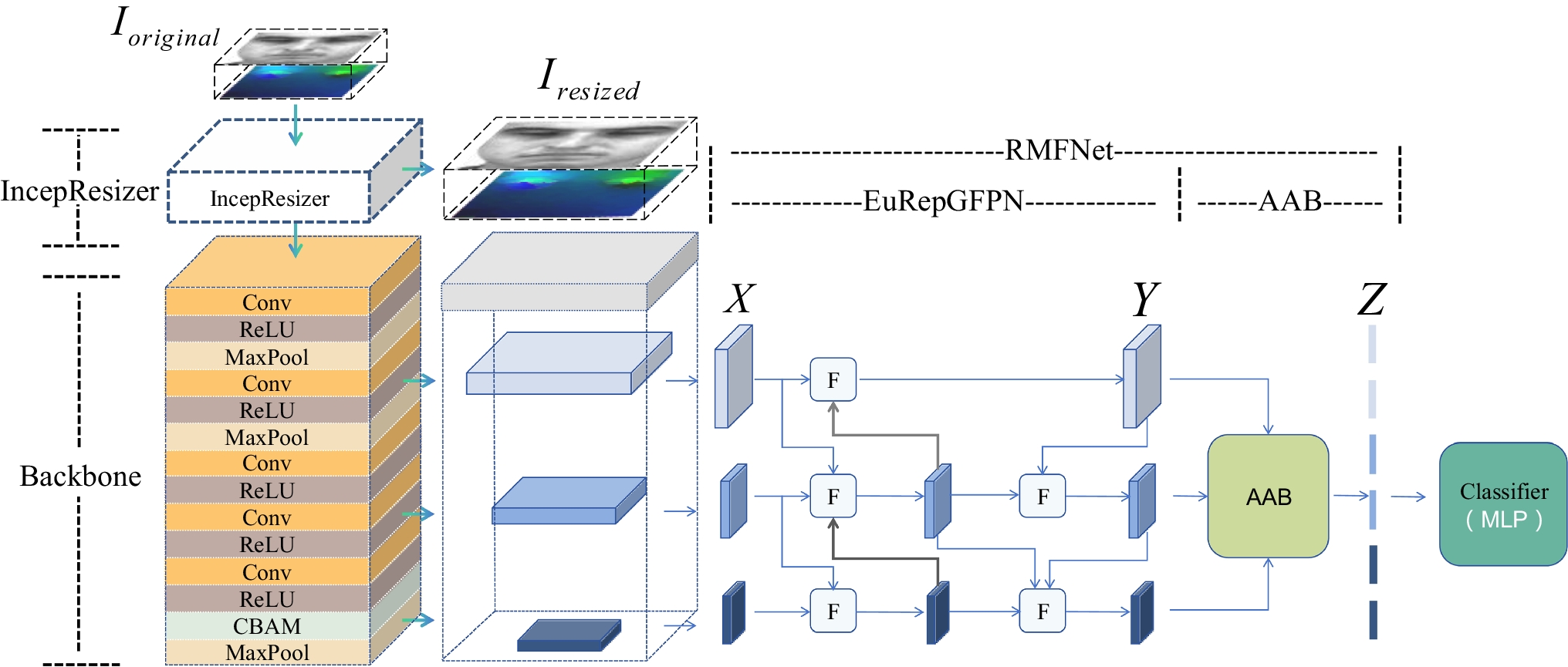
Remember me


In Fig. 2(a), a one-dimensional diagram is shown in the x position. To provide a more intuitive representation, we observe that the two curves (black and blue) are approximately symmetrical about the orange central axis. Here, the space above the central axis is encoded as 1, and the space below it is encoded as 0. Therefore, the encoding of the black curve is the true external feedback of 0s or 1s, while the encoding of the blue curve is the uncertainty of the unsupervised predictions (0/1). With respect to decoding neural data using an unsupervised algorithm, the blue curve decoded through an unsupervised method has uncertain positional variables.
In Fig. 2(b), (c), (d) and (e), several two-dimensional diagrams are derived from a one-dimensional diagram. If the N value is larger, the resolution of a certain position in the space is also larger; if the N value is smaller, the positioning resolution is smaller. Notably, in Grid-SD2E, unsupervised position decoding calculations and analyses are conducted separately within each subspace of each layer. When the analysis results acquired from all the subspaces in all layers are subsequently integrated (i.e., the intuitive diagram of the spatial division process is referenced from a previous work: ViF-SD2E), the frequency of correction (or firing) generates a pattern resembling that of grid cell formation, as shown in Fig. 2. It is important to note that this is not a statistical measurement of firing rates at the single-neuron level in the medial entorhinal cortex (MEC), but rather a systematic statistical measure derived (or inferred) from the population level in the hippocampus via decoding and correction. Additionally, the grid module — a “general computational technique” self-organized from population neural data — merely suggests that grid cell firing may arise from similar position-correction processes (i.e., correction hypothesis). However, Grid-SD2E is an abstract framework and the current version cannot directly “count single-cell level firing” in the MEC. Therefore, correction frequency in this work can only be interpreted as population correction frequency, triggered by noise at nodes (as formally analysed in Section “Formula Derivation for the Interaction Between the SD Module with the Grid Module”). Additionally, a gap or ’hole’ (indicated by a question mark) is present, and the reason for this result is currently unclear.
Finally, in the Grid-SD2E framework, the grid computing module is derived from the ViF (vision feedback) mechanism, which represents a broad and non-computable concept in ViF-SD2E. This analytical process extends from the ViF concept to grid computing, ultimately enabling the grid module to evolve into a general computational technique. On the basis of our theoretical analysis, derivation, and observations, the grid computing module can also form a similar pattern to that of grid cells [17], as shown in Fig. 2. However, whether the similarity between them has a scientific basis still requires further neuro-physiological experimental research.
The Encoding Mechanism in the Grid/SD Module and Formula DerivationsFig. 3 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.(a) Suppose that the deflection angle of the x-axis is \(\alpha\) and that of the y-axis is \(\beta\) (mimicking the tilt shown by the grid cell map in Fig. 2b). (b) and (c) are two schemes given under condition (a), whose purpose is to keep the predicted values and the true labels in the same subspace. Here, the red line is only used as an auxiliary line for reference, and the blue area is an active space. (b) When the x- and y-axes are deflected to become the \(x'\)- and \(y'\)-axes, the lines between the true position and the corrected position are still perpendicular to the \(x'\)- or \(y'\)-axes. In addition, given the true coordinate label \(A\bullet\), the possible predicted values \(A'_0\bullet\), \(A'_1\bullet\), \(A'_2\bullet\) or \(A'_3\bullet\) are symmetrically flipped due to being perpendicular to the deflected \(x'\)- and \(y'\)-axes, and \(\bullet A''_0\), \(\bullet A'''_1\), \(\bullet A''_2\) and \(\bullet A'_3\) are the values obtained after the possible predicted values symmetrically flipped, respectively. (c) When the x- and y-axes are deflected to become the \(x'\)- and \(y'\)-axes, the lines between the true position and the correction position are parallel to the \(x'\)- or \(y'\)-axes. Notably, all the values are equal on either line parallel to the \(x'\)- or \(y'\)-axes. (d) Finally, the diagram illustrates the step of correcting the pseudolabels by drawing an analogy between the bit (0/1) labels generated from the unsupervised predictions and the bit (0/1) labels of the true position.
Spatial Encoding in the Grid Computing ModuleSpatial encoding (or distributed hash encoding) mainly includes both distributed and hash encoding processes. Distributed encoding means that data \(A\bullet\) coordinates can be represented by combinations of 0s and 1s in an active space. The advantage of this strategy is that the representation vector is a low-dimensional and dense vector, different from that produced by high-dimensional sparse one-hot encoding (indicating that the vector must include 0s or 1s to refer to certain data). Hash encoding refers to the assumption that \(A\bullet\) coordinate data (or binary-coded data) with any length are input, and after these data are processed by a hash function, a fixed-length hash value key (a combination of 0s and 1s) is output; that is, \(Hash(A\bullet )= key\). This process is irreversible; that is, the \(A\bullet\) coordinate cannot be reversed by the key. Specifically, one can refer to Fig. 3 and the movement encoder [8]. Here, \(\mathbb \) represents the movement space. When \(N=0\), this means that \(\mathbb \): \(\mathbb ^(0/1, 0/1)\). When \(N>0\), subspace \(\mathbb ^_(x_}, y_})\) is the ith quadrant of the nth subspace of the Nth divided space, where N denotes the Nth division of the space, n is the nth subspace, i is the ith quadrant, and \(x_}\) and \(y_}\) are the encoded x- and y-positions in the xy-plane, respectively. To provide further clarification, the intuitive diagram of the spatial division scheme is referenced from a previous method, ViF-SD2E, which illustrates that when \(N>0\), the original space R is divided into multiple subspaces \(\mathbb ^_(x_}, y_})\) (a total of \(2^\)) in each layer, and these multiple subspaces are independent of each other.
Finally, the inspiration provided by the grid module in this work is that in a complete space, any position can be encoded as a 0/1 string in a distributed form; additionally, this encoding mode satisfies the characteristics of hash encoding.
Formula Derivation for the Interaction Between the SD Module with the Grid ModuleFigure 3 shows two alternatives, (b) and (c), under condition (a), where the x- and y-axes are deflected. The diagram in Fig. 3(d) illustrates the step of correcting pseudo-labels by drawing an analogy between the bit labels generated from unsupervised predictions and the bit labels of the true position. First, if we pursue simplicity, efficiency, and low power consumption in the brain, we believe that the theoretical derivation of (b) is more complicated than that of (c) and is less likely to form the analysed grid nodes, similar to grid cell formation, as shown in Fig. 2. The formula derivation of (b) is presented in ’Appendix A’. The main text presents a derivation of (c). These formulas are mainly based on the following aspects. (1) The deflection angles of the x- and y-axes change, and the origin of the self-built coordinate system is the centre of the motion space; then, \(\eta _1 = \eta _2 =1\) in ’Appendix A’. (2) The deflection angles of the x- and y-axes change, and the origin of the self-built coordinate system is any position of the motion space; then, \(\eta _1\) and \(\eta _2\) in ’Appendix A’. (3) The deflection angles of the x- and y-axes change; the origin of the self-built coordinate system is any position of the motion space, and all the values are equal on either line parallel to the \(x'\)- or \(y'\)-axis. These factors have a progressive relationship in our theoretical analysis and derivation, and the formula in ’Appendix A’ satisfies factors (1) and (2). Finally, it is worth noting that all the values are equal on either line parallel to the \(x'\)- or \(y'\)-axis in the self-built coordinate system of factor (3). Additionally, under the low-complexity conditions of factor (3), grid nodes that are more easily generated form a coupling analogy with grid cell formation.
Therefore, we empirically provide the formula for factor (3) in space \(\mathbb \). That is, the calculation formulas for the movement encoder and corrector [8] are rewritten as follows:
$$\begin }: N\rightarrow +\infty }} F^_, \text}=\left\ 1\; ; \quad \text \; N=j, \; \text, \; \overline_k \;\text\; z_k \ge f_}(\bullet ) \\ 0\; ; \quad \text \; N=j, \; \text, \; \overline_k \;\text\; z_k < f_}(\bullet ) \end \right. \end$$
(1)
$$\begin }: N\rightarrow +\infty }} F^_, \text}=\\\left\ 1\; ; & \text \; N=j, \; \text, \; \overline_k \;\text\; z_k> f_}(\bullet ) + \epsilon \;\\ 0\; ; & \text \; N=j, \; \text, \; \overline_k \;\text\; z_k < f_}(\bullet ) - \epsilon \\ dropout \; \text \; F^_, \text}\; ; & \text \\ \end \right. \end$$
(2)
$$\begin }: N\rightarrow +\infty }} F^_}=\left\ \overline_\; ; & \text \; N=j, \; \text, \; \overline_}=z_} \\ F^_}\; ; & \text \; N=j, \; \text, \; \overline_} \ne z_} \end \right. \end$$
(3)
where formula (1) is used to encode the external world during interactions. \(}: N\rightarrow +\infty }} F^_, \text}\) indicates that as the N value increases in space \(\mathbb \), any encoded position can approach the subspace where the true label is located. Here, \(F^_, \text}\) is the encoded 0/1 string. For example, the predicted \(\bar_\) and true label \(z_\) are encoded as \(\bar_}\) with 0/1 strings and \(z_}\) with 0/1 strings, respectively. In addition, \(j=0, 1, 2,..., N\), and \(f_}(\bullet )\) is the central axis (or reference line) of the spatial symmetry. If \(\overline_k \;\text\; z_k \ge f_}(\bullet )\), the movement is encoded as 1; otherwise, the movement is encoded as 0.
Formula (2) is used to encode the internal world during self-reinforcements. \(}: N\rightarrow +\infty }} F^_, \text}\) indicates that as the N value increases in space \(\mathbb \), any encoded position can also approach the subspace where the true label is located. Among them, \(F^_, \text}\) denotes the encoded 0/1 strings as \(\bar_}\) and \(z_}\). If \(\overline_k \;\text\; z_k> f_}(\bullet ) + \epsilon\), the movement is encoded as 1; if \(\overline_k \;\text\; z_k < f_}(\bullet ) + \epsilon\), the movement is encoded as 0; otherwise, the movement is dropped out or enters the interaction \(F^_, \text}\). \(\epsilon\) is a cognitive or uncertainty bias. That is, the probability of obtaining incorrect predictions at the edge of the divided boundary line (or reference line) is greater or uncertain during self-reinforcement because of factors such as noise interference; thus, dropout and \(F^_, \text}\) need to be introduced, similar to forgetting (or human forgetfulness) and avoiding forgetting (or human interactions with the outside world that enhance memory).
Formula (3) is used to correct incorrect predictions during interactions and self-reinforcements. \(}: N\rightarrow +\infty }} F^_}\) indicates that as the N value increases in space \(\mathbb \), any corrected position can approach the true label. Among them, \(F^_}\) and \(F^_}\) are updated (or corrected) values. In addition, for ease of representation in Fig. 4, we define the function \(Z(\bullet )\) to represent the role of \(F^_, \text}\) and \(F^_}\) (or \(F^_, \text}\) and \(F^_}\)), without any additional implications.
Next, under the condition of factor (3), the formula for \(F^_}\) is given as follows. In addition, because the reference centres on the \(x'\)- and \(y'\)-axes of a space have different calculation modes, the values predicted on the x- and y-axes have different correction formulas.
$$\begin F^_}=\left\ \overline_ + 2\lambda _1 * f_x(\eta _1, x_, x_, \overline_)\; ; & \text \; N=j, \; \overline_ = \overline_ \\ \overline_ + 2\lambda _2 * f_y(\eta _2, y_, y_, \overline_)\; ; & \text \; N=j, \; \overline_ = \overline_ \end \right. \end$$
(4)
When \(\overline_ = \overline_\), \(f_}(\bullet ) = \frac + x_)}\eta _1\); when \(\overline_ = \overline_\), \(f_}(\bullet ) = \frac + y_)}\eta _2\). \(z_\) and \(z_\) are the maximum and minimum boundaries of movement, respectively, during the Nth division step. \(\lambda _1\) and \(\lambda _2\) are the offset rates of the symmetric distances along the \(x'\)- and \(y'\)-axes, respectively. \(\eta _1\) and \(\eta _2\) are the offset rates of the reference centre along the \(x'\)- and \(y'\)-axes, respectively. \(f_x(\eta _1, x_, x_, \overline_) = \frac + x_)}\eta _1 - \overline_\) is the deviation of the predicted \(\overline_\) from the tilted centre on the \(x'\)-axis of the moving space. Similarly, \(f_y(\eta _2, y_, y_, \overline_) = (\frac + y_)}\eta _2 - \overline_\) is the deviation of the predicted \(\overline_\) from the tilted centre on the \(y'\)-axis of the moving space.
Finally, when \(N \rightarrow +\infty\), Grid-SD2E is equivalent to a supervised mode, and when \(N=0\), it is an unsupervised mode. Notably, in (4), the deflection angles \(\) and \(\) are eliminated under the conditions shown in Fig. 3(c). For example, the angle between the \(x'\)-axis and the \(y'\)-axis can be any value (e.g., 60). In addition, when we consider only the reference centre as symmetric, the predictions obtained on the x- and y-axes are directly independent, as shown in Fig. 3(c) and (4), respectively. On the basis of our analysis, the similarity between the grid module and grid cell formation processes is demonstrated in the idea that corrective (or firing) behaviour is more likely to occur at nodes in theory. This is because incorrect location predictions are more likely to occur at the node (reference centre) on the edge of the reference line because of factors such as noise interference. If this derivation is reasonable, then the brain may have developed a self-built coordinate system (including corrective firing) that is functionally equivalent to the Cartesian system but in a different form that better aligns with the external world.
Spatiotemporal Mining of Grid-SD2E Within the Learning SystemFig. 4 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.(a) Steps of the local method used in Grid-SD2E [8]. The red box represents the smallest processing unit, which is called a local unit in a learning system. The local method is concerned about whether the neural data \(}^_}\) corresponding to \(\overline^_}\) is reused in the local unit to obtain \(\overline'^_}\), instead of the source \(\overline^_}\). Furthermore, the inputs of the local method are \(\overline^_\) and \(\overline^_\) predicted by the unsupervised exploration, which are then also applied in (1) and (2) for encoding and correction. The output of the local method is the corrected \(\tilde^_\) and \(\tilde^_\), which, along with the corresponding neural data, are also sent to the supervised exploitation for training. (b) The processing unit of the local method [8]. Here, \(\overline'^_}\) instead of \(\overline^_}\) are encoded as 0/1 signals in the subspace, and are then compared with the given external 0/1 signals to obtain the corrected \(\overline^_}\)
Fig. 5 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.The smallest computing unit from Fig. 4, which can be compared to a single neuron
An Introduction to the Functionality of Grid-SD2EAs the main feature of Grid-SD2E in Fig. 1, the Grid/SD module utilizes robust 0/1 signals within the activity space/subspace to judge and process the values predicted through unsupervised exploration and then sends them to the supervised exploration mechanism for training. During Bayesian inference, exploitation with embodied memory is used to evaluate the adaptive N confidence level and to carry out interactions and self-reinforcement. Please refer to Figs. 1 and 4 for the details of the system. Here, Fig. 4(a) shows the local approach employed by Grid-SD2E in a space and a subspace. The term “local” indicates that the decoded values of the neural data reused in each subspace replace the predicted values entering this subspace rather than processing only the predicted values entering the space. Refer specifically to the local unit in Fig. 4(b). When a local method is applied, Grid-SD2E is composed of more extended local units. Here, \(k_1 \times nT\) has \(k_1\) rows and nT columns, where \(k_1\) is the number of samples contained in this subspace, n is the number of features possessed by each sample, and T denotes the previous T moments from the current state of each sample. Finally, when \(N = 0\), Grid-SD2E is an unsupervised exploration strategy without interactions. When \(N = 1\), we consider the predicted values to be satisfactory if the encoded 0/1 signals in Grid-SD2E match the given external 0/1 values; if not, we flip the predicted values symmetrically to keep them both in the same subspace (see Fig. 4). When \(N = 2\), the operation is similar to that of \(N = 1\), and so forth. In our view, as infants grow and face new experiences, they need to increase their N values to increase their self-attention or supervision capabilities; however, when they learn knowledge and reasoning skills, they are more inclined towards the unsupervised level under prior experience; i.e., N is small. For details, please refer to [8].
In addition, as shown in Figs. 2 and 4, as the N value increases, the resolution of the positioning process continually increases. However, the number of subspaces increases exponentially, resulting in an exponential increase in the number of computations. On the basis of the power consumed by the brain, the N value should be as small as possible, indicating that the prediction of the internal system is more closely matched with that of the external world. Here, if N is larger, it indicates that the neural data generated by the brain are more chaotic and cannot be effectively used to make predictions; that is, they are disordered. Notably, if N is smaller, the neural data generated by the brain are more accurate and orderly. Therefore, we believe that when the brain minimizes N in Grid-SD2E, the neural data generated by the brain should transition from disorder to order. Next, we analyse “how a group of neurons forms a behaviour”. When the brain interacts with the external world, neural data are generated by a group of neurons, which are then decoded into predicted values and encoded as 0/1 signals. A 0/1 signal encoded from the brain is analogized with the encoded 0/1 signal derived from the outside world; here, the analogy results in a population of neural data being assigned to different subspaces. Finally, the self-organized neural data are separately predicted, encoded, and analogized in their respective subspaces from \(N = 1\) to \(N = n\). From the above, in Grid-SD2E, we believe that a group of neural data go through the self-organization process of the brain to complete the behavioural output. In addition, from the perspective of Grid-SD2E, expanding from a 2-D space to a d-D space in the self-organizing system is simple and convenient (assuming that the prediction in each dimension is independent, as shown in the conclusion of Fig. 3c; see Fig. 4.
$$\begin \mathbb \xrightarrow \mathbb ^d \end$$
(5)
where the space \(\mathbb \) can be denoted as \(\mathbb ^d\), and d represents the dimensionality of the space. In our view, compared with the 2D biological navigation system using grid cell formation, the advantage of extending this scheme to multidimensional biological systems is that on the one hand, these systems seem to be beneficial for our navigation activities in the three-dimensional world; on the other hand, for cognitive tasks other than spatial navigation, multidimensional systems may be more conducive to the execution of distributed parallel computing. In addition, since each dimension is assumed to be independent, this strategy further reduces the complexity of the system when performing spatial navigation and other cognitive tasks.
In summary, in Grid-SD2E, grid feedback can be regarded as a partition or channel that separates the internal world of the brain from its external environment. The exchange of information between the internal and external worlds is entirely transformed into 0s or 1s within the grid for communication and feedback. In the internal world of the brain, \(\overline^_\) and \(\overline^_\) are predicted via unsupervised exploration. They enter the grid and are encoded as 0s or 1s (with uncertainty in these predictions). However, 0s or 1s can also be received from the external world (which is the actual external feedback) to determine whether the unsupervised predictions are correct or incorrect.
Self-organizing Properties of Grid-SD2E in the Learning SystemFinally, to draw an analogy with a single neuron in the brain, the smallest computing unit is shown in Fig. 5, which is derived from Fig. 4. This is a computing unit that can implementing a self-correction function by inputting 0/1 feedback signals. \([s_1, s_2,..., s_n]\) are the neural firing signals corresponding to location \(\overline_n\), and \(F_\mathrm\) refers to an unsupervised algorithm (Un-al). \(\overline'_n\) is the predicted position obtained by \(F_\mathrm\) from the neural data \([s_1, s_2,..., s_n]\). \(\overline'_\) is the corrected predicted position. The computing unit has two outputs. The first output includes the neural data (or 0/1) corresponding to the corrected prediction value, which is then sent to the next computing unit, and the second output contains the corrected prediction value or 0/1 symbols, which are used to determine prediction errors on the basis of the exploitation mechanism or output in the last layer.
From Figs. 4 and 5, it can be concluded that the self-organization characteristics of the neural data in Grid-SD2E are manifested mainly in the following case. When moving from \(N=n\) to \(N=n+1\), the neural data follow the decoding position of a certain subspace while the prediction target is adjusted. The decoding position is corrected via an analogy between the encoded 0/1 signals and the external feedback 0/1 signals. Notably, it is uncertain whether the neural data corresponding to the decoding position would undergo repeated neural encoding or changes in each subspace. It seems that a validation is required from the computational neuroscience and neurophysiology perspectives.
Correlation Between Grid-SD2E and the Free Energy PrincipleFurthermore, if we focus on the number of subspaces or bins (which increase exponentially with N) that support distributed hash encoding, some fundamental principles suggest that an optimum value for N can be obtained. These principles underwrite the self-reinforcement or self-evidencing process that is inherent in the free energy principle [26]. Self-evidencing corresponds to self-reinforcement by maximising the “marginal likelihood” of predicted sensory inputs. This marginal likelihood is also known as “model evidence” and can always be expressed as accuracy minus complexity. The complexity term is important because it means that self-evidencing (i.e., self-reinforcing exploitation) requires an accurate explanation that is as minimally complex or parsimonious as possible.
This means, that for any interaction or world there will be an N (at each level of a hierarchical model) that maintains accuracy, which is as small as possible. This tendency to optimally coarse-grain or tile state spaces can be seen from several perspectives. From the perspective of the free energy principle, it inherits from Jaynes maximum entropy principle [28]; in the sense that free energy approximates marginal likelihood and comprises an entropy term (which has to be maximised) and some constraints (supplied by the generative model). An alternative rearrangement of entropy and constraints is in terms of accuracy and complexity, as above. Here, complexity corresponds to the KL-divergence between priors and posteriors. In other words, complexity scores the degrees of freedom used to provide an accurate account of sensory data. It is this that we associate with the number of subspaces that should be kept as small as possible to minimise complexity cost. This is also known as Occam’s principle and is closely related to formulations of universal computation in terms of Solomonov induction and Kolmogorov complexity [46, 47, 49]. This leads to alternative formulations of variational free energy in terms of minimum description and message length [34, 54]. These are interesting perspectives because again, they speak to minimising N under constraints. In short, the current formalism we are proposing speaks in a natural way to information theoretic treatments of optimal learning and inference. Furthermore, the Grid-SD2E system still requires a similar theoretical treatment formula as follows.
$$\begin ^d}: N\rightarrow +\infty }} F^_} \xrightarrow \; N} ^d}: N\rightarrow 0}} F^_} \end$$
(6)
where, the operation of minimising N (thus maximising N-confidence) is equivalent to reducing the length of the hash encoding at a specific position in space to decrease the complexity and enhance the accuracy of the prediction process. In addition, minimising N equates high-resolution (fine-grained, potentially high-confidence) performance to low-resolution (coarse-grained, low-complexity) states under maximum entropy constraints. If errors persist, \(\epsilon\) (uncertainty bias in (2)) triggers dropout, reverting to interaction for belief revision.
In this work, N-confidence ties to priors becoming posteriors via 0/1 evidence. N-confidence, denoted as \(C^\), can be formalized as the posterior precision (inverse variance) of the model’s beliefs at resolution N, updated Bayesianally to minimize free energy \(FE = \text - \text \). The update rule emerges from comparing predicted bits \(\bar_}\) with evidence bits \(z_}\) and correcting via the spatial division (SD) module, as per (3) and (6). Therefore, formal update rule for N-confidence is defined as follows:
$$\begin C^_ = C^_ \cdot \exp \left( -\gamma \cdot \left| F^_}(z_}, \bar_}) - z_k \right| \right) + \beta \cdot \left( 1 - \frac}\right) \end$$
(7)
where, \(C^_\) is the prior N-confidence at time/step t (initially set to a small value, representing initial uncertainty). \(\left| F^_} - z_k \right|\) is the absolute prediction error, penalizing mismatches (lowers confidence exponentially). \(\gamma> 0\) is a decay rate (e.g., for entropy resistance, per free-energy principle). \(\beta> 0\) is a boost factor for parsimony, rewarding lower N (coarser resolution with stable accuracy). \(N_\) is the maximum resolution (system hyperparameter; as \(N \rightarrow N_\), finer grids allow higher potential confidence but risk overfitting/complexity). This rule increases \(C^\) when errors are low (consistent bits, exploitation reinforced) and decreases it otherwise (triggering exploration or N adjustment). It aligns with Bayesian updating: the exponential term weights evidence likelihood, and the parsimony term acts as a prior favoring minimal N.
In 1944, Schrodinger proposed the concept that “life exists with negative entropy” [48]. Friston’s free-energy principle is based on Bayesian reasoning (the prior becomes a posterior, which becomes a prior again); in addition to the “free-energy minimization” (i.e., the difference between the expected state of the internal world and the measured state of the external world) induced while interacting with the environment, the free-energy principle introduces an “information theory isomorphism of the thermodynamic free-energy” to explain the existence of life as negative entropy [9, 45]. If Grid-SD2E is correct regarding the information processing scheme, we believe that it is in line with the perspectives of Schrödinger and Friston. That is, the neural data generated from disorder to order are resistant to an “entropy increase” in terms of making optimal predictions and reducing cognitive errors. When neural data are transmitted in a system, they can be self-organized into group signals of different subspaces for prediction purposes.
Comments (0)