
Remember me
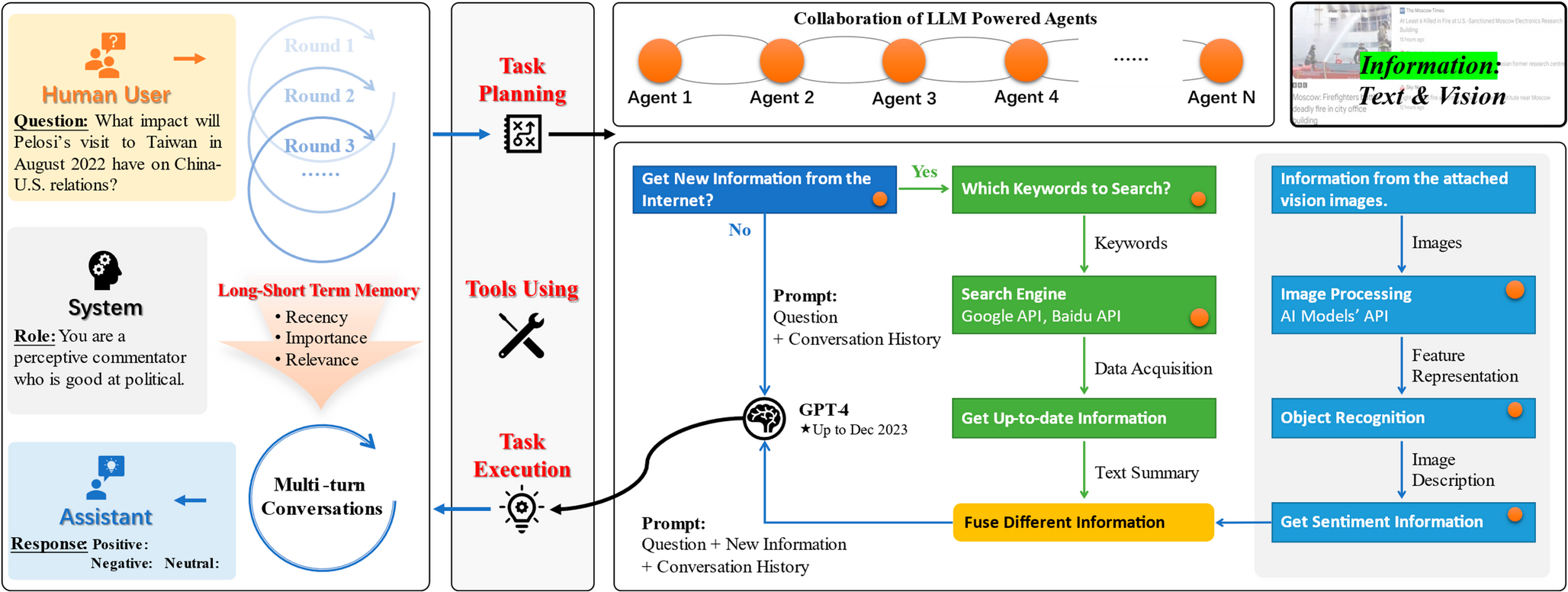

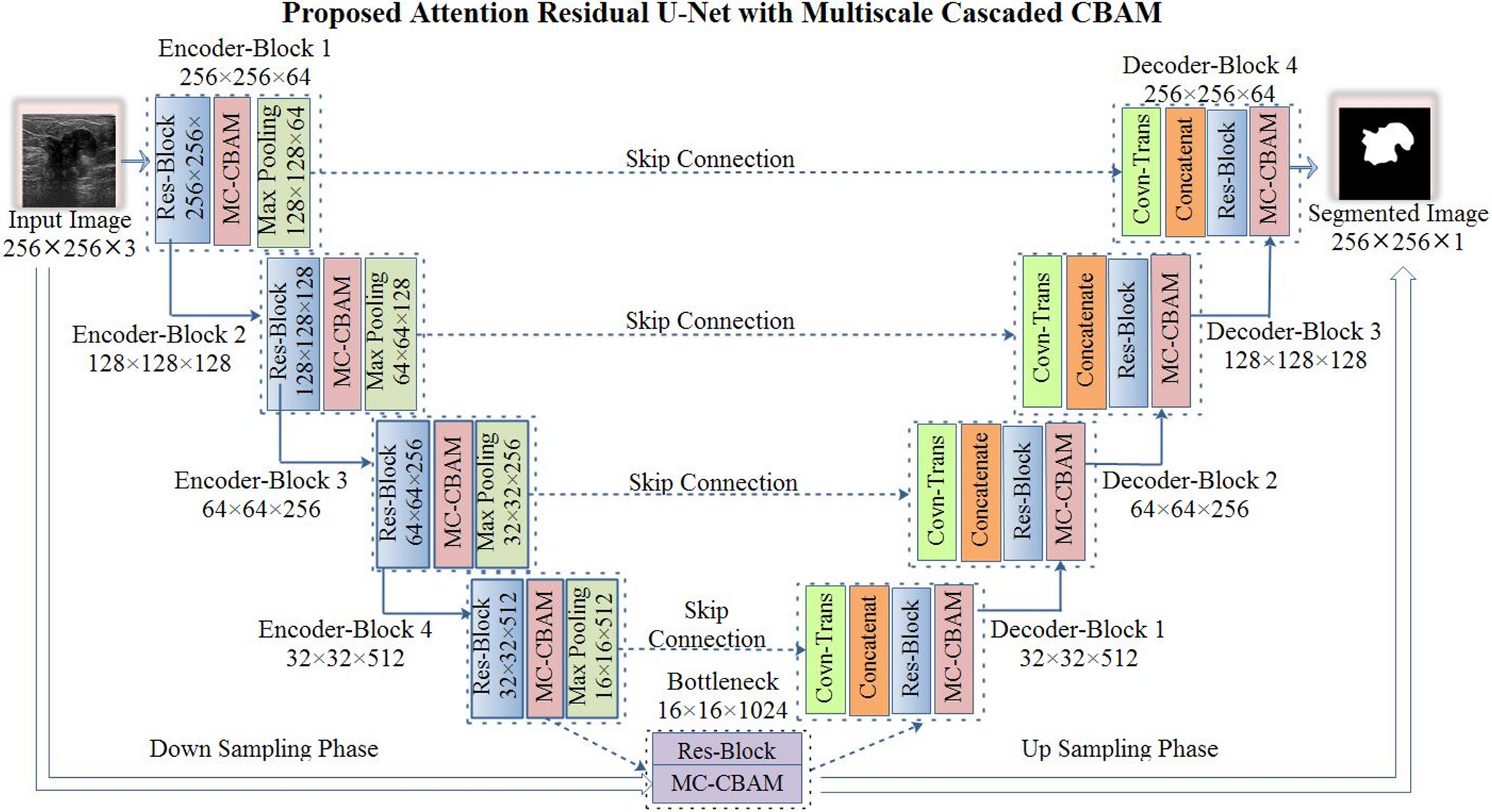
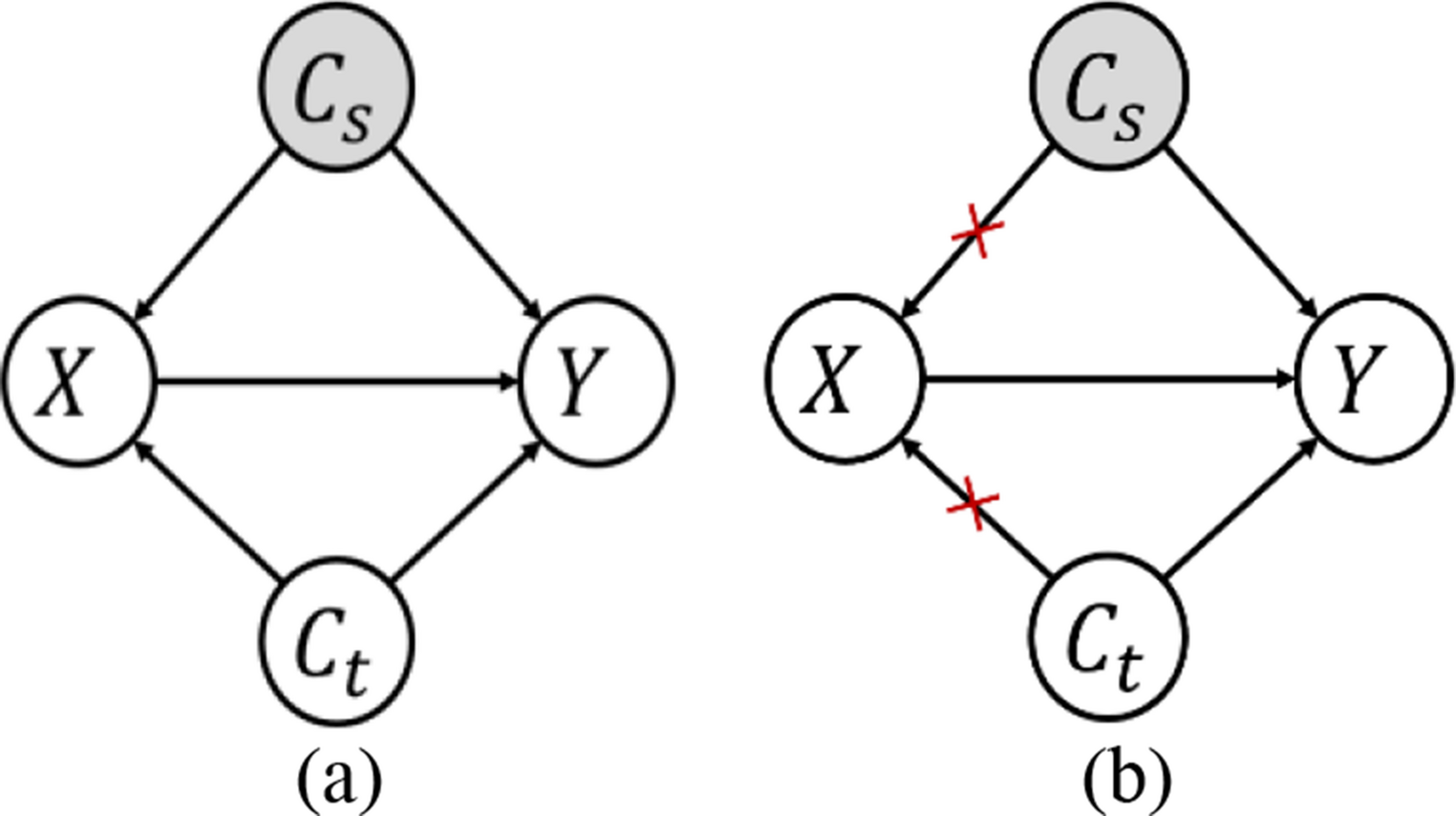

In this section, our experiments for the TTA-based approach (described in the “A TTA-Based Approach for Multi-Class Object Localization and Size Estimation” section) are presented. This evaluates the performance of our approach for extracting information on fruit/vegetable size and quantity from images in the OSR. The results prove that our approach can work as an enabling technology in Smart Agriculture. In the following, we first show the experiment of how we train a deep learning-based backbone model for multi-class object localization, size estimation, and counting problems. The optimal strategies and parameter settings of the proposed TTA-based approach are evaluated and discussed for tasks under different scenarios. Lastly, we test our proposed models, trained on the synthetic datasets, on the collected real image dataset. A comparative experiment is further conducted between our model and SAM on the real-image dataset. All experiments are implemented on an Nvidia Volta V100 GPU, and our source code and data are publicly available (link is provided in Appendix 1).
Table 2 Detail of six groups of images in the datasetFig. 4
Collected sources images (thumbnails)
Evaluation Metrics and Experiment DatasetWe describe the evaluation metrics and data used for the three tasks shown in Fig. 1 (object counting, position detection, and size estimation) in our experiment.
From the aspect of localization and size estimation, we use root mean square error (RMSE) to evaluate the detected position and size estimation errors of each object. The reason for using the RMSE in our experiments is that the distance between the object’s ground-truth position and the predicted one is naturally calculated by the root mean square. The RMSE for object size estimation is calculated over all object instances in all the test images.
$$\begin RMSE_= & \sqrt^}n_i}\sum _^}\sum _^ (y_^s-\hat_^s)^2}\end$$
(7)
$$\begin RMSE_= & \sqrt^}n_i}\sum _^}\sum _^ ((x_^c-\hat^c_)^2+(y^c_-\hat^c_)^2)}\nonumber \\ \end$$
(8)
where \(y^s_\) and \(\hat^s_\) are the ground truth and predicted sizes; \(x^c_\) (\(y^c_\)) and \(\hat^c_\) (\(\hat^c_\)) are the ground truth and predicted position, in the x-axis (y-axis) of the j-th object instance in the i-th test image.
For object counting, we also use RMSE to evaluate the performance:
$$\begin RMSE_ = \sqrt}\sum _^} (y_i^-\hat_i^)^2} \end$$
(9)
where \(y_i^\) and \(\hat_i^\) are the ground truth and predicted peak map for the i-th test image respectively, \(N_\) is the number of test images.
The synthetic part of our E-MOCSE13 dataset for the unified problem of object counting and size estimation in OSR has the following settings:
390 images in total, and 30 images per class, with a resolution of 512*512. The ground truth information for each image is provided in a text file, which includes the total amount, label, relative size, and position of each object.
13 classes of fruits or vegetables: apple, artichoke, avocado, banana, carrot, courgette, garlic, melon, onion, orange, pear, tomato, and shallot. Based on the shapes of these objects, the banana, tomato, and garlic are selected as the OoD dataset used in the experiment. The rest of the classes are set as the in-distribution (ID) dataset.
Each class in our dataset contains 6 groups, which are combinations of counts and sizes in different ranges. Table 2 gives the details of all groups. Each group has 5 images, three of which are used as the training-set in the ID dataset, and the rest of the two images of each group are used as the validation-set. The OoD dataset is used as the test-dataset in our experiment. We also select two images from each group for each class in OoD to build a smaller-test-dataset. The mixture of ID and OoD can be seen as the noises added to create a joint distribution, so that it increases the complexity of the OSR to test the generalization performance.
Fig. 5
The example output results of banana (unseen class of data during the training) for one of its test images: input image (upper left), heatmap ground truth (upper right), output heatmap (lower left), output peak map (lower middle), and output size heatmap (lower right)
The real part of E-MOCSE13 dataset is created from Google Images and COCO dataset [49]. Figure 4 shows the thumbnails of them. They contain adjacent or non-adjacent or occluded apples, oranges, and tomatos of different sizes and numbers. The settings of this real image dataset are listed as follows:
It contains 3 classes (apple, orange, and tomato) and 11, 7, and 5 images for each class correspondingly, in which apple and orange are set as ID classes and tomato is set as OoD class in our synthetic dataset.
To increase the complexity of counting tasks, we duplicate and combine these source images to make each of our test images contain 15 to 30 objects. The labels and positions of all objects in our real image dataset are hand-annotated.
To get the relative size of each object, we first assume the parameters of the camera distance to the objects and camera focal lengths for all source images are the same as those in our synthetic dataset. Under this assumption, a ratio exists for each class that measures the number of pixels per given scale in the source images of this class [4]. This ratio is equivalent to the ratio of images of this class in our synthetic dataset. This ratio for each class can be calculated based on the average total pixel number and the average relative size of all objects in any image of this class within our synthetic dataset. Then, we preprocess each source image to count the total pixel number for each object within it (the details are shown in Appendix 2) and, based on the corresponding class ratio, determine its relative size.
The Experiment of Backbone Model TrainingIn this section, we depict our experiment on how to train a backbone model to output the three tasks (object counting, localization, and size estimation) simultaneously.
Experiment SettingThe experiment setting of the backbone model training is discussed. A pre-trained HRNet [29] is implemented in PyTorch [50] in this experiment. The Adam optimizer is employed for training. The initial learning rate (LR) is set to 1e-3, the minimum LR is set to 5e-7, and the cosine annealing schedule is employed during the training process. The learning rate in this schedule starts high and decreases rapidly to a minimum value near zero before increasing again to the maximum, which is a typical aggressive learning rate schedule [51]. The batch size is set to 16. Since the model can always converge after around 400 epochs, we set the total number of training epochs to 500. For every 10 epochs after 150 epochs, we set it as the checkpoint to save the trained model. In the experiment, we use the whole training set of the ID dataset described before to train a model to get more prior knowledge for different kinds of fruits/vegetables.
According to the proposed TTA strategy, the training process aims to generate a compatible model that can achieve strong OoD generalization, specifically for examples drawn from distributions that differ from the training set. The output position heatmap and size heatmap have a size of 128*128, which is 1/4 of the input image. The method we use to adapt the ground truth position heatmap and size heatmap with the prediction output during the training is the loss function we used “MSEloss”, they all have the same size. For testing, a position heatmap, a size heatmap, and a peak map of the test figure could be output by feeding the whole image to the trained model. The peak map is used to count the objects in the image by aggregating all the pixel values. We use the function “MaxPool2d” from PyTorch to get the peak map from the output heatmap. Through segmentation, the individual-identified object with its position and size can be obtained. Figure 5 shows an example of the output heatmap, size heatmap, and peak map.
Fig. 6
Validation is performed for trained models at different checkpoints, with a focus on changes in counting RMSE (upper left), distance RMSE (upper right), and size estimation RMSE (lower left and right)
Experiment Training ResultDuring the experiment, a training backbone model is saved as a checkpoint every 10 epochs. The aims of the experiment in this section are (1) validate these checkpoint models by using the validation-set; (2) examine the OoD generation on the unseen classes of data by using the smaller-test-dataset.
Figure 6 shows the experiment results of the training model from all checkpoints. The upper left subfigure demonstrates the change in the counting RMSE of the trained model with the increased number of epochs in the training process. Under two different inputs of the validation-set or the smaller-test-set, both the RMSE decrease with the increased number of epochs and finally converge after 400 epochs. The best RMSE under the validation-set and the smaller-test-set is 3.121 and 4.381 at 400 epochs, respectively. Since the range of object numbers in images of the dataset is 30 to 110 (listed in Table 2), 3.121 (4.381) is a relatively small number compared with numbers in this range, with the counting error at most 10.4% (14.6%) in this scenario. All these mean that the training model can get enough prior knowledge through feature representation learning, and proves it has good OoD generalizations on the object counting task.
The upper right subfigure in Fig. 6 shows the changes in distance RMSE for each object of the validation-set and the smaller-test-dataset with the increased number of epochs. Unlike the decreasing trend of the counting RMSE, the distance RMSE for each object fluctuated with values of 10 or 4 for both input datasets, respectively. Compared to the size of the heatmap 128*128, the distance error on the object detection task is relatively small, around 7.81% or 3.1%. The fluctuation of the distance RMSE suggests that the model has converged after 150 training epochs. Increasing the number of epochs does not have a positive effect on the results of the localization task. Furthermore, the distance RMSE in the OoD dataset is almost 2.5 times higher than in the ID dataset. All these mean the OoD generalizations of the trained model for the task of object detection are acceptable but could be further explored to improve.
The lower two subfigures in Fig. 6 depict the decreasing trend of size estimation RMSE for each object under the input of the validation-set or the smaller-test-dataset with the increasing number of epochs, which is similar to the results of the object counting task. From the figure, we can see that the test results converge after 450 epochs with values around 0.15 and 0.52. From Table 2, we observe that the objects in the test images have a size range of 1.8 to 3.6. The RMSE values of 0.15 and 0.52 (which denote prediction errors of at most 8.33% and 28.8%, respectively) are relatively small compared to this range. Therefore, we can conclude that the training model performs well in terms of size estimation tasks under the ID dataset. However, the RMSE value for size estimation in the OoD dataset is higher than that of the ID dataset, indicating the potential for improvement via the incorporation of the TTA strategy.
In this experiment, we test the performance of the trained backbone model under the validation-set and the smaller-test-dataset on tasks of object counting, localization, and size estimation. It performs well for all tasks under the ID dataset. However, the performance of the trained model on the tasks of object localization and size estimation under the OoD dataset could be further improved, which is implemented in the next section.
Table 3 The combinations of parameter settingsNote: For the scenario of multiple classes of objects that exist in the same figure, we slightly modify the framework by adding a classification head in Fig. 3 to output multiple heatmaps/size heatmaps (each for one class), while keeping our backbone of the deep model backbone for feature representation learning. A similar approach has been achieved and implemented in our previous work [13]. Since our experiments mainly focus on object counting, localization, and size estimation for OoD Generalization issues, and the application scenario is smart agriculture (normally one type of fruit/vegetable exists in one crop/tree), we will not present or discuss the corresponding experiment results for this scenario.
The Experiment of Fine-Tuning the Backbone ModelsIn this section, we experiment with different strategies and parameter settings under TTA-primal and TTA-ft strategies to improve our backbone predictive model when training and test data with different distributions.
Experiment SettingWe use the trained models from the “The Experiment of Backbone Model Training” section under checkpoints of epochs 350 and 380 as the backbone model to test TTA-primal and TTA-ft domain adaptation strategies. TTA-primal calibrates the statistics \((\mu _t^, \sigma _t^)\) for all BN layers, utilizing test data. Notably, it does not update any of the affine parameters in the BN layers, thereby negating the need to fine-tune the model. However, the use of Pseudo-label sampling can be toggled to update these statistics for data exhibiting ‘Top k minimum’ entropy. In TTA-ft, the aim is to optimize the affine parameters \(\gamma ^\) and \(\beta ^\) in BN layers with a loss function by fine-tuning the model. The statistics calibration feature is an optional choice, as is the option to incorporate Pseudo-label sampling for selecting Top k minimum or Top k maximum entropy data for fine-tuning.
The testing OoD datasets are the smaller-test-dataset and test-dataset described in the “Evaluation Metrics and Experiment Dataset” section. To adapt different domains or distributions during testing, entropy loss is used to minimize the entropy of model predictions. To minimize entropy, our approach normalizes and transforms inference on target data by estimating statistics and optimizing affine parameters batch-by-batch. The times of affine transformation for both TTA-primal and TTA-ft during the testing can be set as 1 or 2. Specifically, TTA-ft will update the affine parameters during the testing with a learning rate. The optimal learning rate needs to be tested, and the batch size is set to 16 (the same as the backbone model training). During testing, we select the top k percentage of samples with the maximum or minimum entropy loss values to do the adaptation for the model. The possible value of k could be 10, 20, 50, and 100. The combinations of the parameter settings mentioned above are listed in Table 3, where BS is short for batch size and ‘-’ means the parameter is not available in this setting. The test results of trained models from epochs 350 and 380 on two test datasets under these parameter settings are shown in the “Experiment Result” section. All the results shown in the following section are the mean values of experimental results from multiple runs (2–3 times). The reason for this is to avoid possible bias. The results from the different runs are quite close, and the variance in the results is small. The potential reason is that the DL-based models and TTA we implemented are well-designed, robust, and confident enough to make similar decisions in every run.
Experiment ResultThe experiment results of the fine-tuned models under different combinations of settings are shown and discussed. Due to the space limitation, Tables 4, 5, 6, and 7 show the results fine-tuned on the checkpoint 380 backbone model. The parameter setting with the best \(RMSE_\), \(RMSE_\) or \(RMSE_\) in each block of the table is in bold, and the second best is underscored italic.
Table 4 lists the detailed results of different LR settings for adopting the TTA strategy on two different testing datasets under sample selection ratio 1 and batch size 16. The test results on two datasets from the original backbone model (from checkpoint epochs 380) are also listed in the first row for each block as a comparison. From the table, we can see the best \(RMSE_\) on the smaller-test-dataset is lower from 10.3 to 6.0 under the TTA-ft approach with setting LR to 5e-3 and switching off statistics calibration, which is quite close to 4.90 - \(RMSE_\) of the original backbone model testing on ID dataset (validation-set). The results \(RMSE_\) of different settings are quite close to the original backbone model, around 0.51. It may suggest further testing in a larger range of parameter settings. This similar result of size may indicate that our synthetic images may lack the reflection towards the real-world heterogeneity of the fruit size. The best \(RMSE_\) from the table is 3.29, which is improved compared with the \(RMSE_\) of the original backbone model testing on the same OoD dataset 5.48. Except for the best values, from Table 4, we can find that different setting strategies may bring better performance for the different tasks under this groups of parameter settings: i.e., switching on the statistics calibration can improve models’ performance on the task of position detection, but switching off it can get better counting results. Moreover, the results indicate that fine-tuning all BN layers of the model with testing data is advantageous in achieving domain generalization.
Table 4 Experiment results of different LR under batch size 16Based on the number of images in two test datasets and the results from Table 4, for the following experiments, we set the LRs used to update the affine under the TTA-FT approach as \(1e-3\) when testing the smaller-test-dataset and \(5e-4\) when testing the test-dataset. Table 5 lists the results of different parameter combinations of maximum or minimum loss value, different sample selection ratios, and affine transformation times under the TTA-ft approach. In this experiment, we set the statistics calibration to false for all runs. Based on the best and second-best values of each metric from the table, the best strategies under this group can be found: select the top \(50\%\) (\(10\%\)) of samples with the maximum (minimum) entropy loss values to do the adaptation for the task of object position detection (object counting). Compared with the results in Table 4, we can conduct the following truths: (1) both of the best values of \(RMSE_\) and \(RMSE_\) in this table are lower than the best values in Table 4 respectively; (2) same with the previous group of parameter settings, the performance of the fine-tuned backbone model under this group of parameters is also not improved on the task of object size estimation.
Table 5 Testing results of different parameter combinations of maximum or minimum loss value, different sample selection ratios, and affine transformation times on the TTA-ft approach(1)Upon enabling statistics calibration, we conducted the same experiment for the aforementioned parameter combinations as listed in Table 5, and recorded their respective results in Table 6. Interestingly, the best strategies within this group are reversed compared to the previous group: select the top \(50\%\) (\(50\%\)) of samples with the minimum (maximum) entropy loss values to do the adaptation for the task of object position detection (object counting). The best results on metrics \(RMSE_\) are lower than the best values in Table 4 when using the full test dataset, which indicates that the confidence level of pseudo-labels decreases with an increasing number of test samples. In this scenario, enabling statistics calibration would be beneficial. However, concerning the optimal result for the \(RMSE_\) metric, it is noted that while the predicted coordinates may experience some deviation, the counting threshold is relatively lenient. Thus, incorporating more test data would have a positive effect on its performance, as demonstrated by the discrepancy compared to the optimal values shown in Table 4.
Table 6 Testing results of different parameter combinations of maximum or minimum loss value, different sample selection ratios, and affine transformation times on the TTA-ft approach(2)Table 7 lists the testing results from the TTA-primal approach with different combinations of sample selection ratios and affine transformation times. The best strategies for the object position detection and counting tasks are the same: select the top \(10\%\) of samples with the minimum entropy loss values for adaptation. But still, the best results on metrics \(RMSE_\) and \(RMSE_\) are lower than the best values in Table 4 on these two metrics, respectively. This outcome aligns with our expectations.
In this section, we extensively evaluated the performance of fine-tuned models using varied parameter settings. When using OoD data, our TTA-based approach demonstrated noteworthy enhancement in both object localization and counting tasks. The metric of \(RMSE_\) remained relatively constant, potentially attributed to the greater complexity involved in assessing size features of novel fruits and vegetables, particularly under limited testing data. Our way of finding the best strategy on the TTA approach to fine-tune the model for domain adaptation under different target tasks can be a reference for future similar work. It is concluded as follows.
Parameter Tuning ApproachIn scenarios with a smaller dataset (such as smaller-test-dataset in this paper), we prefer to use a batch size of 16, updating only the affine parameters with a learning rate between 5e-3 and 5e-4. This approach ensures more accurate localization estimation on OoD data. This preference is due to the limited testing data, which results in a relatively minor covariance shift caused by the unseen set. Conversely, with a relatively larger dataset (like the full test dataset we used), selecting the maximum top samples yields better localization accuracy compared to the minimum top samples. Since maximum top samples bring significant covariance shifts, it is necessary to update both the statistics calibration and affine parameters. Regardless of the testing set size, the optimal counting performance is achieved when the batch size is set to 16 and only affine parameters are updated. This is because statistics calibration does not influence the counting process. Furthermore, since size regression is less dependent on the shape of the detected objects, the backbone model demonstrates the best generalizability for this task. Consequently, it is also less likely to be affected by statistics calibration.
Table 7 Testing results of different parameter combinations of different sample selection ratios and affine transformation times on the TTA-primal approachThe Experiment on the Real Image DatasetIn this section, we evaluate the performance of our model (trained from the synthetic dataset) and TTA fine-tuning strategies by using the collected real image dataset from the E-MOCSE13. The feasibility of our approach to real-world application scenarios is validated.
Experiment ResultsWe first test the trained backbone model obtained from the “The Experiment of Backbone Model Training” section by using the two sets of images: apple+orange (ID) and tomato (OoD), respectively. In this experiment, we compare our models to the segment anything (SAM) [25]. A bounding box has to be offered to generate the segmentation mask from SAM. We include rough- and fine-bounding boxes to test the result, shown in Fig. 7. Specifically, the rough-bounding box covers a pile or a gathering of fruits, while the fine-bounding box is generated by each fruit’s location to cover a single fruit. Therefore, we do not measure the distance for SAM as the location information is already used in the bounding box. Moreover, as we use the pre-trained SAM model in this comparison, we do not label the “ID” or “OoD” in the table.
Fig. 7
SAM segmentation results on apple+orange and tomato dataset
For the results of all checkpoints, we only show the best results in the first two rows in Table 8 due to space limitations. For the ID test, our model achieves the best \(RMSE_\) and \(RMSE_\) values: 5.22 and 0.17, respectively, at epoch 300. Our model with the checkpoint from epoch 350 gets the best \(RMSE_\) of 7.06 and \(RMSE_\) of 0.43 on the OoD test. All these results are compatible with the best ones on the synthetic dataset. According to Fig. 6, the best \(RMSE_\) scores for synthetic ID and OoD are 3.68 and 6.62, and the best \(RMSE_\) for ID and OoD are 0.14 and 0.47, respectively. In Table 8, the \(RMSE_\) scores of 0 on OoD test data are obtained due to the relatively small number of objects contained in each image (15–30) of this dataset, compared to the synthetic dataset (30–110). The images of ID test data contain more objects (15–50) and have a large number of adjacent/partly-covered objects, the \(RMSE_\) shows as 2.57 is still much better than the best test corresponding results of the synthetic dataset in Fig. 6: 3.12. Another reason to affect the \(RMSE_\) of ID test data is that the range of object relative scales in it is 1.4–9.4, which was much wider than the range of object relative scales in the synthetic dataset 1.8–3.6 (shown in Table 2). The aforementioned results prove the capability for good generalization of our backbone model. The results of SAM show that the fine-bounding box offers a significantly advanced result compared to the rough-bounding box. The \(RMSE_\) of the fine-bounding box SAM remains inferior to that of our proposed models for both datasets. The \(RMSE_\) of the fine-bounding box SAM for the apple+orange dataset leads the backbone model by 0.64. On the other hand, the result of SAM for the tomato dataset is behind both the backbone model and the one with TTA-ft. The SAM model is designed as a generalized solution approach to segmentation. When handling images in our scenario, it may lack the capability of precise segmentation due to the fine-bounding box SAM. It requires a specific design of the neural networks to obtain precise information on the number, size, and location.
Table 8 Experiment results on real image datasetSimilar to the “The Experiment of Fine-Tuning the Backbone Models” section, we further experiment with different strategies and parameter settings under TTA-primal and TTA-ft for improving our backbone predictive model when tested on tomato. The best results, along with corresponding strategies and parameter settings, are listed in the third row in Table 8. The \(RMSE_\) and \(RMSE_\) are improved by 0.16 and 0.02, respectively, which are improved compared with before. It is noticed that the \(RMSE_\) for the ID classes is 2.57 compared to the rest OoD results. The backbone model may fail to separate the pile fruit cases in the real image dataset, as shown in the apple and orange images in Fig. 7. It is a limitation that we can add the occlusion cases to further improve the E-MOSE13 dataset in the future. All these results show that useful prior knowledge can be gained when using our synthetic data in the experiment, since our dataset simulates the real-world scenario to keep the problem domain the same as the real application problem. This demonstrates the feasibility and high prediction accuracy of our approach, which is trained and tested using a synthetic dataset for real-world application scenarios without requiring further training.
Comments (0)