
Remember me
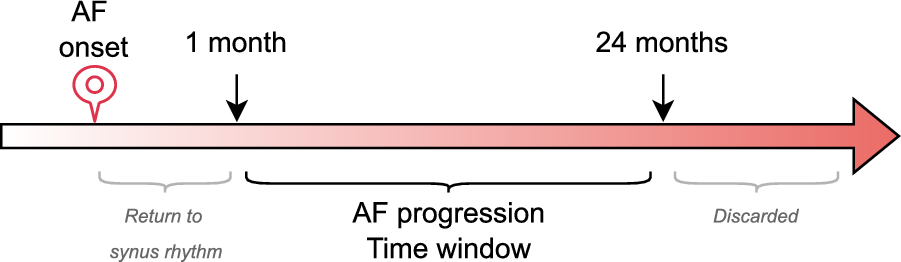
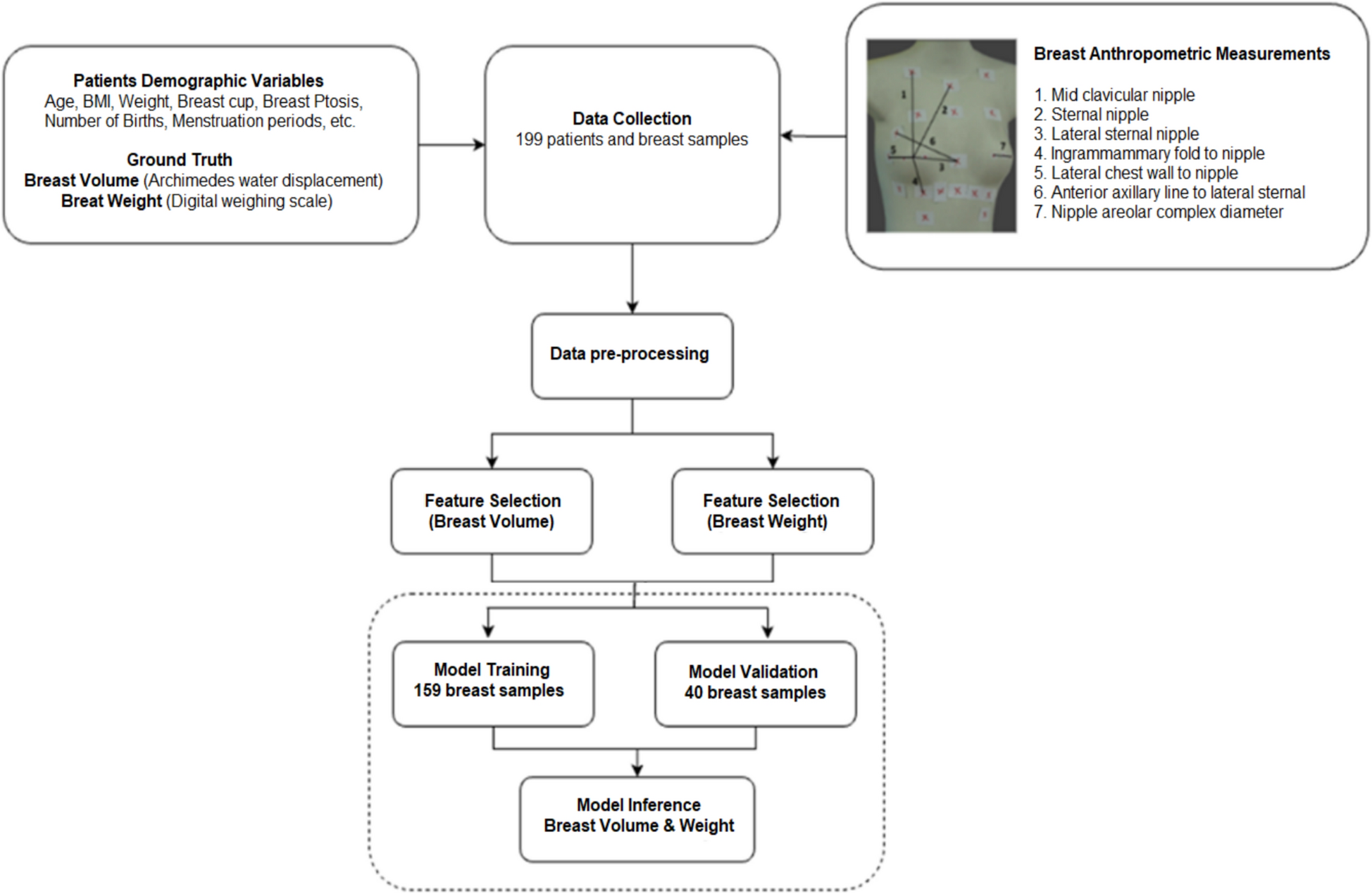
This section presents the main findings of the study. We first report the results of the AF progression detection task (see “Results for AF progression” section), analyzing the performance of both the rule-based and LLM-based strategies. Subsequently, we evaluate the generalizability of the proposed approach through its application to the HF decompensation detection task (see “Results for HF decompensation” section).
Results for AF progressionThe results presented in Table 5 are obtained using the test set while all the prompt engineering was performed using the development set. For the LLM-based models, the results count as errors all the answers where the instructions are not followed even when the correct answer might be inside the returned text, this decision aimed to evaluate the capacity of the models to follow instructions and format.
Table 5 Performance results for each strategyWhile our rule-based pipeline achieves the highest absolute accuracy (0.82), LLMs paired with task-division prompting deliver nearly equivalent results (0.79) with far less upfront investment. By decomposing the problem into subtasks these models avoid the laborious development of regular expressions and the application of section identification and entity recognition tools. This reduction in preprocessing and human engineering makes LLM-based methods considerably more scalable and adaptable to new datasets or clinical conditions.
Across all evaluated LLMs, the gemma-3-12B-it model emerged as the most effective LLM for AF progression cohort selection across all the prompt strategies. Its strong performance reflects a balanced capability to process clinical prompts and consistently produce the required classification labels. However, other models demonstrated difficulties in accurately following the prescribed instructions. Many models (including domain-adapted ones) tended to return explanations rather than a simple label, forcing extensive prompt engineering to constrain outputs. Consequently, gemma-3-12B-it stood out by faithfully following label-only instructions.
The results show that increasing the size of the model did not guarantee better results. The 27B-parameter gemma-3-27B underperformed relative to its 12B counterpart. It also required significantly greater compute resources. Therefore, in practical clinical settings, where efficiency, clarity, and resource constraints are paramount, the smaller gemma-3-12B-it offers the most realistic and reliable solution.
Regarding the clinical LLMs, although Aloe-Beta consistently outperforms its general-purpose counterpart Llama3.1, MedGemma shows clear limitations in adherence to instructions. Specifically, it frequently provides explanatory text alongside its predictions, rather than returning the required label only. This behavior poses a challenge for tasks where concise, standardized outputs are necessary–particularly in scenarios that involve automatic post-processing of model responses. However, even in cases where the output format was not a limitation, MedGemma did not outperform its generic counterpart, although it included clinical knowledge and being a larger model than the gemma-3-12B-it (12 Billion parameters versus 27 Billion parameters).
When presented with the full concatenated clinical history, all LLMs suffered from the classic “long-context” limitation. The Concatenation strategy, which simply merged every discharge report, saw performance drop substantially, confirming that unstructured, extensive inputs still overwhelm current architectures.
The format in which temporal information is provided also proved important. Models performed best when dates appeared in standardized numeric (yyyy-mm-dd) or written formats, but obtained worse results when asked to reason over relative durations in days. This suggests that, although LLMs can parse and compare explicit dates, their inherent arithmetic abilities are insufficient for reliable duration calculations.
Regarding prompt language, models based on the LLaMA architecture generally performed better with prompts written in English, largely due to difficulties in following instructions when prompted in Spanish (see Fig. 8). A similar issue was observed with the MedGemma model, which tended to include reasoning in its responses when prompted in Spanish, despite being explicitly instructed to return only the label. The Mistral models exhibited instruction-following issues in both languages, although the problem was more pronounced in Spanish. In contrast, the Gemma models did not exhibit a consistent preference for either prompt language when evaluating mean accuracy across strategies (see Fig. 9). However, when excluding the summarization-based experiments, the mid-sized model (gemma-3-12b-it) showed a clear preference for Spanish prompts. This suggests that for classification tasks, Spanish prompts may be more effective, while English appears to be favored in more complex text generation tasks such as summarization. Interestingly, this language preference shift was not observed in the larger gemma-3-27b model, which showed no significant language bias across tasks.
Fig. 8
Total format errors across experiments by prompt language in Llama models. Each bar shows the total number of format errors made by the Llama 3.1 (left) and Aloe-Beta (right) models across all strategies, with blue (scratched) representing English prompts and red (dotted) representing Spanish prompts
Fig. 9
Mean accuracy across experiments for each prompt language in Gemma models. Each bar represents the average accuracy achieved by the Gemma-12B (left) and Gemma-27B (right) models across all strategies, with blue (scratched) indicating English prompts and red (dotted) indicating Spanish prompts
The fine-tuned version of gemma3-12b-it with the Onset-Guided strategy yielded poorer results compared to the zero-shot approach. A possible explanation is that fine-tuning may reduce the model’s ability to generalize, particularly in long-context tasks, which are known to present significant limitations. However a further analysis of the results and the optimization parameters of the fine-tuned version could be explored in the future.
Further analysis of the best LLM strategyTo further analyze the performance and robustness of the proposed solution, the best pair of LLM and strategy was selected (gemma-3-12b-it and Onset-Guided + Num with Spanish prompts) and will be discussed in the following subsections.
Error analysis
Firstly, a manual revision of each prediction and error was performed. Figure 10 presents the outcomes of a step-by-step analysis of model predictions across patient clinical histories. The categories are as follows:
Correct Whole History (53 cases) these are cases in which the model made accurate predictions at every relevant step across the full clinical timeline.
Correct Final Decision (22 cases) these cases include intermediate errors during the analysis of the patient’s clinical history, but the final classification was still correct.
Incorrect (23 cases) in these cases, the final prediction was incorrect, which could be due to one or more critical errors made during intermediate steps.
The combined total of fully and partially correct predictions indicates that the model is often able to reach the correct conclusion, even when not all intermediate predictions are perfect. This supports the idea that task decomposition can be an effective strategy, provided that key decision points are handled accurately.
Fig. 10
Prediction outcomes analysis. Red (dotted) indicates incorrect final predictions, blue (scratched) represents correct final predictions with intermediate errors, and green (crossed) denotes fully correct predictions at every decision point
A more detailed analysis of the errors made in both the incorrect cases (see Fig. 11) and the partially correct cases (see Fig. 12) reveals key patterns in the model’s behavior. The majority of the errors stem from the second step of the classification process, where AF progression is identified. In particular, many of these misclassifications are linked to difficulties in detecting sinus rhythm (SR), with frequent occurrences of false negatives and confusion between SR and AF within the same clinical episode.
This pattern may help explain the relatively lower performance observed in the Chronology-Guided approach, as even small inaccuracies in sinus rhythm identification can propagate and affect the final progression classification. The presence of errors like SR + AF same episode and False Negative SR highlights the ambiguity the model faces in differentiating between arrhythmia progression and recovery within overlapping or sequential events.
While some of these errors could potentially be addressed through further prompt refinement, we argue that continuously adjusting the prompt based on error analysis closely resembles a rule-based approach—where all possible scenarios are manually accounted for. This contradicts the intended flexibility and adaptability that LLMs are designed to offer. In our case, prompt engineering was already carried out during development, and overly tailoring the prompt to specific patterns observed in the results may not only reduce generalizability but also introduce new types of errors.
Fig. 11
Error analysis for the Incorrect category. Each bar represents a specific type of error and the number of times it was made by the model. More detailed description of the errors available in “Appendix 3”
Fig. 12
Error analysis for the Correct Final Decision category. Each bar represents a specific type of error and the number of times it was made by the model. A more detailed description of the errors is available in “Appendix 3”
Furthermore, the incorrect cases reveal additional, less frequent errors such as temporality issues, formatting inconsistencies, and misinterpretations of terms like ‘permanent’ or clinical events such as ablation. However, these appear to be isolated instances rather than systematic failures, and therefore do not represent significant limitations of the overall approach.
Temporality analysis
A closer examination of the cases in which temporal relationships influenced the final decision—such as electrocardiogram findings indicating AF episode either before 1 month or after 2 years from the debut—revealed that, in most instances, the model handled these scenarios correctly (see Fig. 13). This suggests that, when temporal constraints are clearly defined and explicitly presented, the model is generally capable of applying them appropriately, reinforcing the idea that temporality is not a fundamental limitation in this task.
Fig. 13
Error analysis in temporal reasoning tasks. Red (dotted) bars indicate cases where the temporal relation (between disease debut and current report) was ignored, while blue (scratched) bars represent correct handling of these temporal dependencies
Uncertainty analysis
We performed an uncertainty analysis to assess model confidence. Incorporating this type of analysis is essential, as it goes beyond standard accuracy metrics by providing insight into the confidence structure of the model, highlighting systematic sources of uncertainty, and helping to identify borderline cases.
Since greedy decoding only returns the most likely prediction without information about alternatives, we estimated the conditional log-likelihood of all possible labels. This allowed us to quantify uncertainty in the model’s decisions. Our working hypothesis was that incorrect predictions would exhibit smaller probability differences between classes (indicating greater ambiguity) whereas correct predictions would display clearer separation.
To test this, we calculated the log-likelihood difference between the predicted label and the second most probable label. The mean difference was 3.98 (±0.95) for correctly classified patients and 3.73 (±1.00) for misclassified patients, supporting our hypothesis that correct predictions are generally associated with higher confidence and clearer separation.
Because the final decision is composed of multiple steps, a single misclassification can lead to an overall incorrect outcome even if all other steps are correct. To account for this, we computed the confidence difference specifically for the misclassified steps, obtaining a mean value of 3.64.
Interestingly, the misclassifications with the highest confidence were primarily related to temporality issues. These cases can often be identified when both the debut and progression dates are extracted within less than 1 month of each other. We therefore recommend a manual review of such cases, as well as of instances where the log-likelihood difference is particularly small (e.g., below 3), since these reflect low-confidence model decisions.
To further assess robustness, we designed a set of adversarial examples intended to mislead the model:
Negations the presence of negative clauses in AF mentions can mislead the model, particularly when it relies on keyword detection rather than interpreting the full semantic meaning of the sentence. These adversarial cases were manually constructed to assess this vulnerability.
Other arrhythmias mentions of arrhythmias other than AF and its synonyms may confuse the model if it lacks the medical knowledge required to distinguish between different conditions. These examples were extracted from real clinical reports.
Two contrary ECGs in the same report the presence of two ECGs within the same report (one indicating a new episode of AF and another reporting a return to sinus rhythm) may mislead the model, as shown in the error analysis in Figs. 11 and 12. These adversarial cases were also sourced from real reports.
The adversarial experiments yielded the following results:
For the 10 negation examples, the model correctly classified 8. The 2 misclassified cases had mean log-likelihood differences of 1.15 and 0.23, reflecting very low confidence.
For the 20 examples of other arrhythmias, the model achieved an accuracy of 70%, with the most frequent error being a prediction of \(-1\) (Unknown) instead of 0 (Non-Progression). Notably, this type of error is less critical than confusing 1 with 0 or vice versa.
The 24 two contrary ECG cases were the most challenging, with only 50% accuracy. This appears to stem from the prompt not explicitly requiring that a return to sinus rhythm must occur without any AF episode in the same report. Refining the prompt design for such cases could help mitigate these errors.
Results for HF decompensationThe gemma-3-12b-it model, using the adapted Onset-Guided strategy for the HF decompensation task, achieved an accuracy of 0.72 with the Spanish prompt and 0.74 with the English prompt.
Although the results obtained for the HF decompensation task are slightly lower than those reported for AF progression, they remain positive. This modest decrease in performance may be related to the greater number of reports per patient in the HF dataset (mean of 7.07 reports), compared to the AF dataset (mean of 5.07 reports). As a result, the likelihood of encountering ambiguous or borderline cases increases. In particular, the Non-Decompensation (0) class—already the most challenging to predict—is more prone to misclassification. This is because a correct prediction of this class requires that all intermediate steps confirm the absence of any new decompensation episode, making it more sensitive to errors at any stage of the process.
These results confirmed the strong performance of the stepwise strategy and demonstrate the generalizability of the approach to other diseases where inclusion criteria depend on distinct clinical episodes documented across multiple reports within specific temporal ranges (for instance, Relapsing-Remitting Multiple Sclerosis or Chronic Obstructive Pulmonary Disease).
Comments (0)