Shao M, Basit A, Karri R, Shafique M. Survey of different large language model architectures: trends, benchmarks, and challenges. IEEE Access. 2024;12:188664–706.
Article
Google Scholar
Hadi MU, Al Tashi Q, Shah A, Qureshi R, Muneer A, Irfan M, Zafar A, Shaikh MB, Akhtar N, Wu J, et al. Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects. Authorea Preprints. 2024.
Karabacak M, Margetis K. Embracing large language models for medical applications: opportunities and challenges. Cureus. 2023;15(5):e39305.
Google Scholar
Ellahham S, Ellahham N, Simsekler MCE. Application of artificial intelligence in the health care safety context: opportunities and challenges. Am J Med Qual. 2020;35(4):341–8.
Article
Google Scholar
Lewis P, Perez E, Piktus A, Petroni F, Karpukhin V, Goyal N, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. Adv Neural Inf Process Syst. 2020;33:9459–74.
Google Scholar
Di Palma D. Retrieval-augmented recommender system: enhancing recommender systems with large language models. In: Proceedings of the 17th ACM conference on recommender systems, 2023, pp. 1369–73 (2023).
Miao J, Thongprayoon C, Suppadungsuk S, Garcia Valencia OA, Cheung-Pasitporn W. Integrating retrieval-augmented generation with large language models in nephrology: advancing practical applications. Medicina. 2024;60(3):445.
Article
Google Scholar
Hsu JC, Lu CY. Evidence on the utility and limitations to using AI for personalized drug safety prediction. In: Encyclopedia of evidence in pharmaceutical public health and health services research in pharmacy. Berlin: Springer; 2023, p. 693–8.
Weber DJ, Talbot TR, Weinmann A, Mathew T, Heil E, Stenehjem E, et al. Policy statement from the Society for Healthcare Epidemiology of America (SHEA): only medical contraindications should be accepted as a reason for not receiving all routine immunizations as recommended by the Centers for Disease Control and Prevention. Infect Control Hosp Epidemiol. 2021;42(1):1–5.
Article
Google Scholar
Jin Q, Dhingra B, Liu Z, Cohen WW, Lu X. PubMedQA: a dataset for biomedical research question answering. arXiv preprint; 2019. arXiv:1909.06146.
Lee J, Yoon W, Kim S, Kim D, Kim S, So CH, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics. 2020;36(4):1234–40.
Article
Google Scholar
Jin D, Pan E, Oufattole N, Weng W-H, Fang H, Szolovits P. What disease does this patient have? A large-scale open domain question answering dataset from medical exams. Appl Sci. 2021;11(14):6421.
Article
Google Scholar
Singhal K, Tu T, Gottweis J, Sayres R, Wulczyn E, Amin M, et al. Toward expert-level medical question answering with large language models. Nat Med. 2025;21(3):943–50.
Article
Google Scholar
Yagnik N, Jhaveri J, Sharma V, Pila G. MedLM: exploring language models for medical question answering systems. arXiv preprint; 2024. arXiv:2401.11389.
Yang H, Chen H, Guo H, Chen Y, Lin C-S, Hu S, Hu J, Wu X, Wang X. LLM-MedQA: enhancing medical question answering through case studies in large language models. arXiv preprint; 2024. arXiv:2501.05464.
Ministry of Food and Drug Safety (MFDS). Drug Utilization Review (DUR) Open API. Accessed via data.go.kr, the Korean public data portal. MFDS. https://www.data.go.kr/data/15059486/openapi.do. Accessed 1 July 2025.
Kapoor DU, Garg R, Gaur M, Patel MB, Minglani VV, Prajapati BG, et al. Pediatric drug delivery challenges: enhancing compliance through age-appropriate formulations and safety measures. J Drug Deliv Sci Technol. 2024;96:105720.
Article
Google Scholar
Borda LA, Nagard M, Boulton DW, Venkataramanan R, Coppola P. A systematic review of pregnancy-related clinical intervention of drug regimens due to pharmacokinetic reasons. Front Med. 2023;10:1241456.
Article
Google Scholar
Kucukosmanoglu A, Scoarta S, Houweling M, Spinu N, Wijnands T, Geerdink N, et al. A real-world toxicity atlas shows that adverse events of combination therapies commonly result in additive interactions. Clin Cancer Res. 2024;30(8):1685–95.
Article
Google Scholar
OpenAI: text-embedding-3-small model. 2023. https://platform.openai.com/docs/guides/embeddings. Accessed 4 July 2025.
Han Y, Liu C, Wang P. A comprehensive survey on vector database: storage and retrieval technique, challenge. arXiv preprint; 2023. arXiv:2310.11703.
Choi J, Palumbo N, Chalasani P, Engelhard MM, Jha S, Kumar A, Page D. MALADE: orchestration of LLM-powered agents with retrieval augmented generation for pharmacovigilance. arXiv preprint; 2024. arXiv:2408.01869.
Robertson S, Zaragoza H. The probabilistic relevance framework: BM25 and beyond. Found Trend Inf Retr. 2009;3(4):333–89.
Article
Google Scholar
Chase H. LangChain: building applications with LLMs through composability. 2023. https://www.langchain.com. Accessed 1 July 2025.
Workum JD, Volkers BW, Sande D, Arora S, Goeijenbier M, Gommers D, et al. Comparative evaluation and performance of large language models on expert level critical care questions: a benchmark study. Crit Care. 2025;29(1):72.
Article
Google Scholar
OpenAI: GPT-4o mini: advancing cost-efficient intelligence. 2024. https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/. Accessed 1 July 2025.
Anthropic: the Claude 3 model family: Opus, Sonnet, Haiku. 2024. https://assets.anthropic.com/m/61e7d27f8c8f5919/original/Claude-3-Model-Card.pdf. Accessed 1 July 2025.
Meta AI: introducing LLaMa 3.1: our most capable models to date. 2024. https://ai.meta.com/blog/meta-llama-3-1/. Accessed 1 July 2025.
Sellergren A, Kazemzadeh S, Jaroensri T, Kiraly A, Traverse M, Kohlberger T, Xu S, Jamil F, Hughes C, Lau C, et al. MedGemma technical report. arXiv preprint; 2025. arXiv:2507.05201.
Corbeil J-P, Dada A, Attendu J-M, Abacha AB, Sordoni A, Caccia L, Beaulieu F, Lin T, Kleesiek J, Vozila P. A modular approach for clinical SLMs driven by synthetic data with pre-instruction tuning, model merging, and clinical-tasks alignment. arXiv preprint; 2025. arXiv:2505.10717.

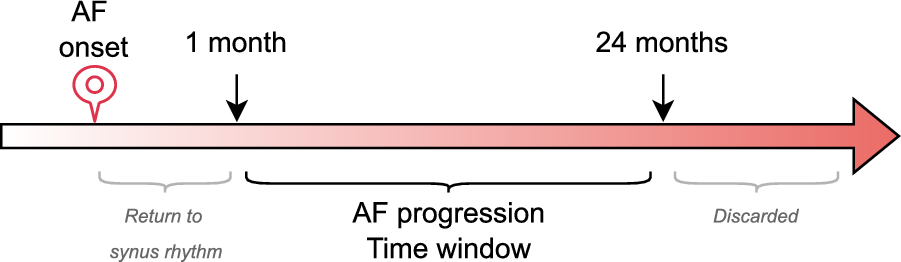
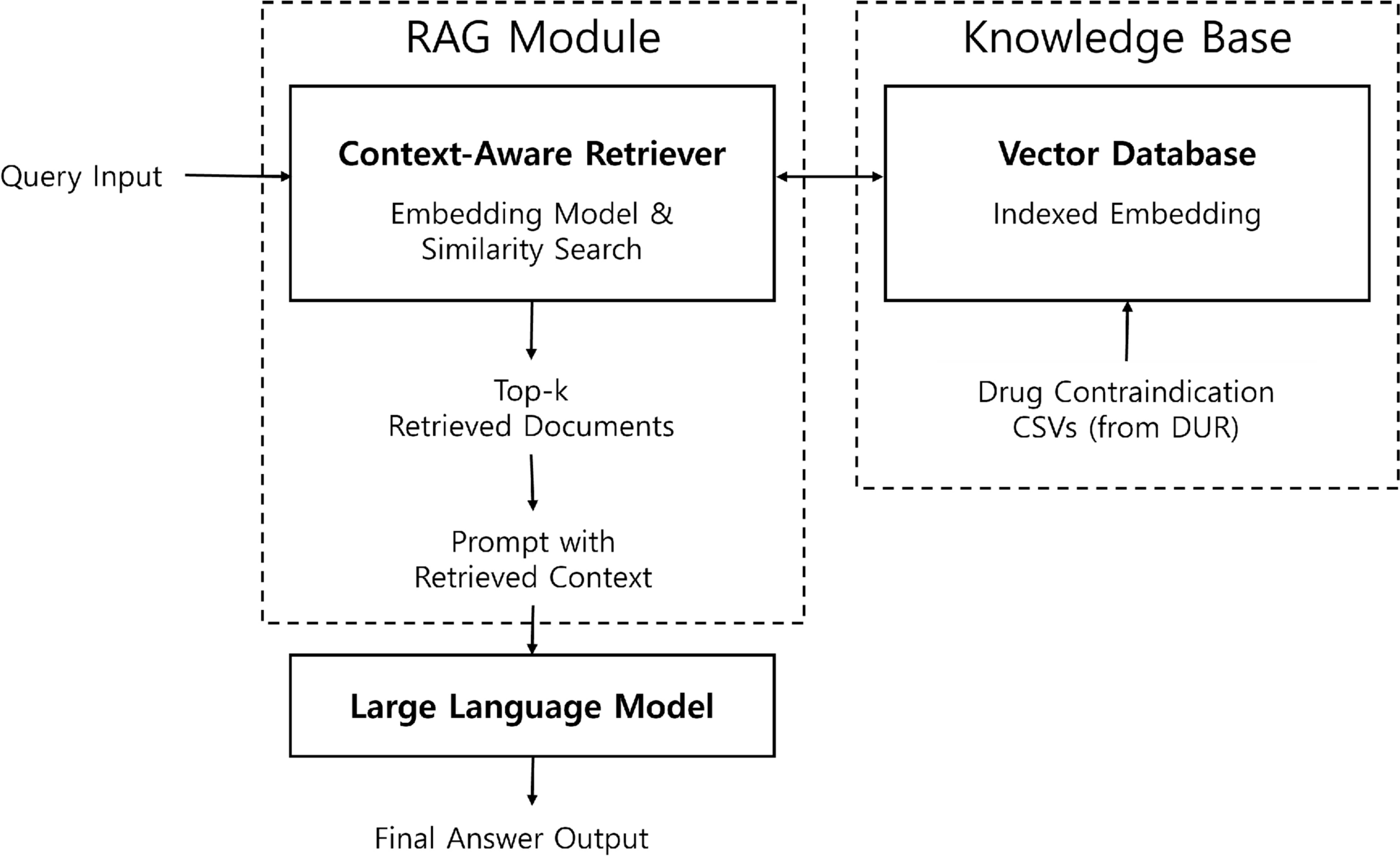
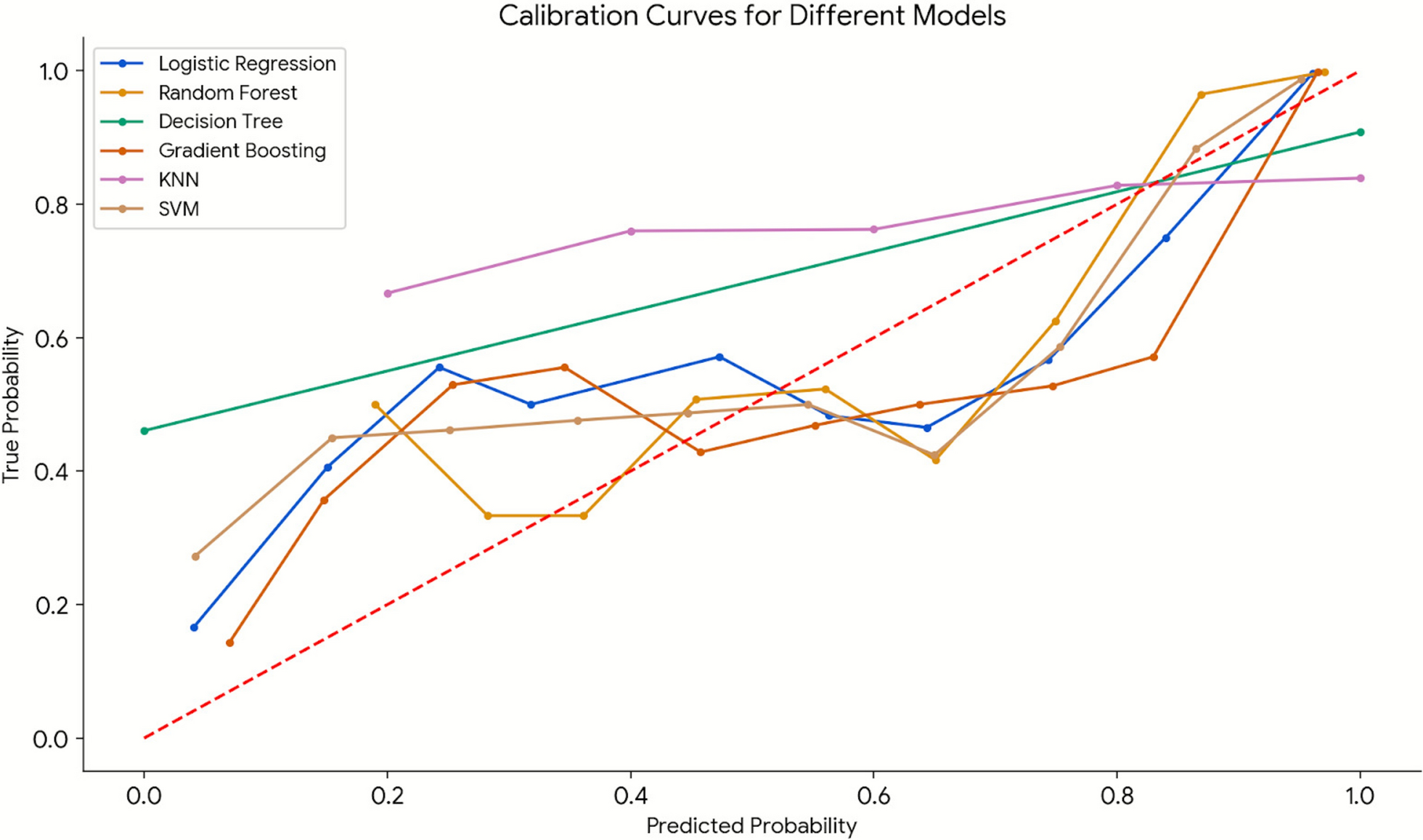
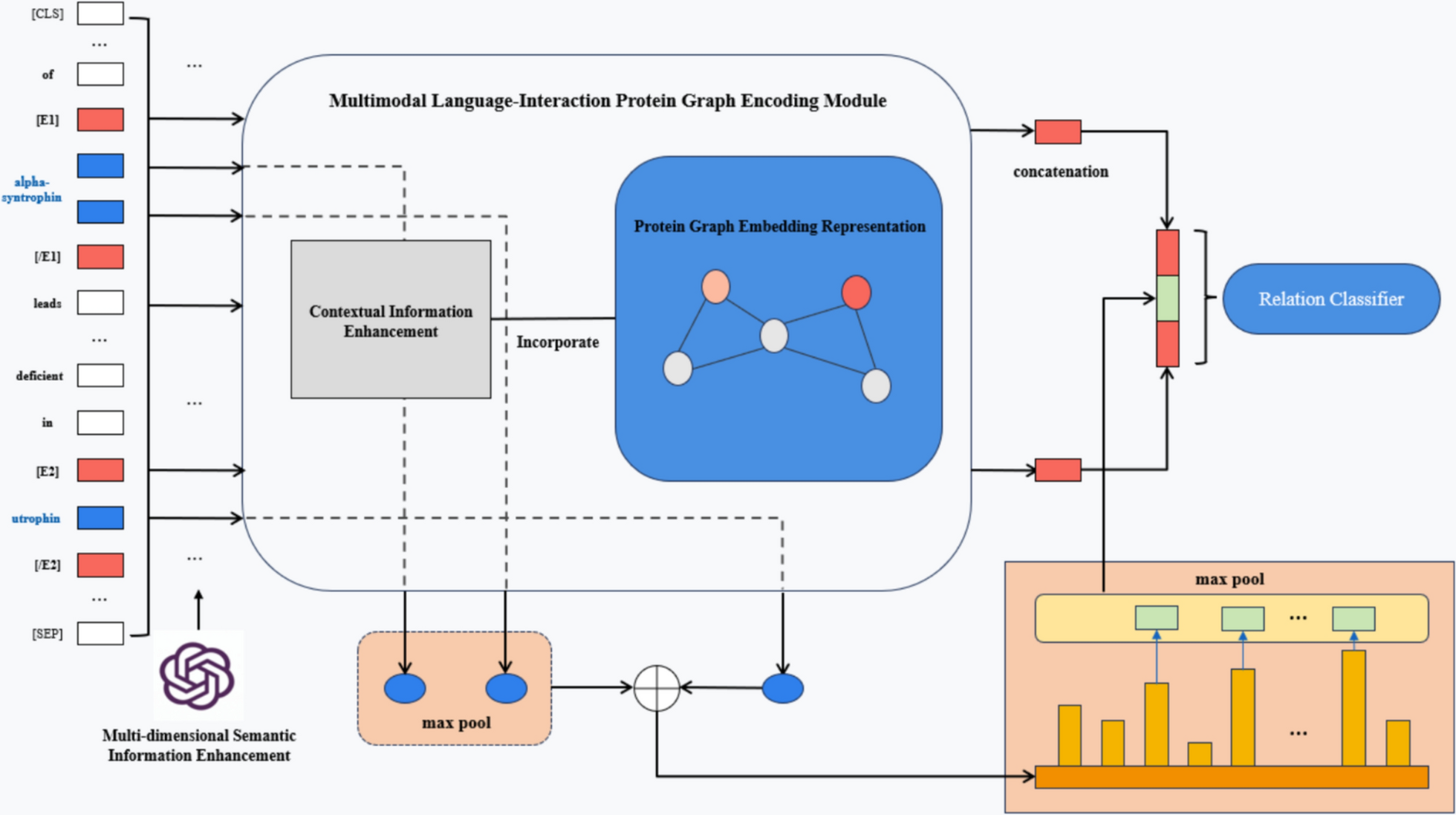
Comments (0)