
Remember me
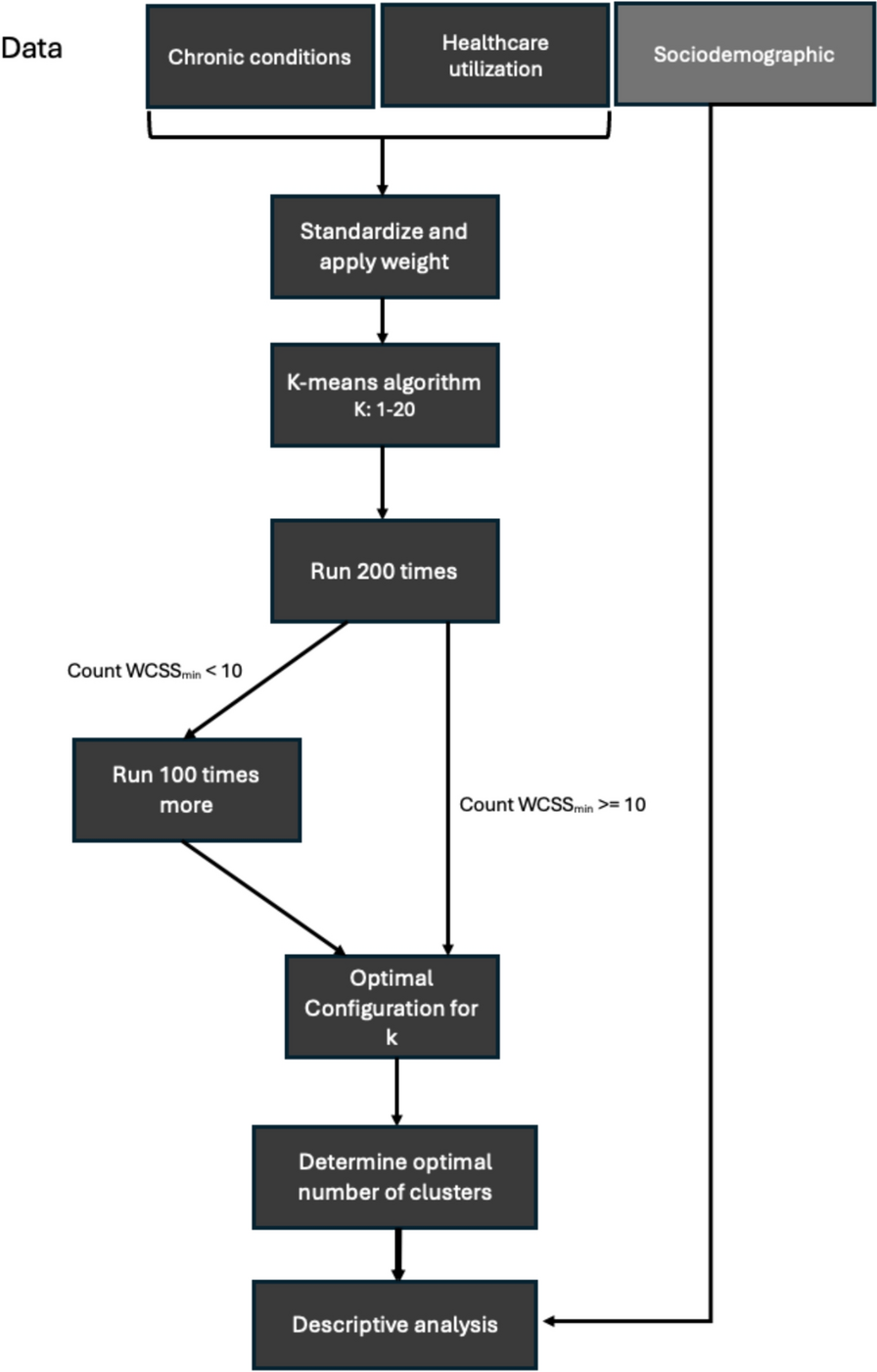
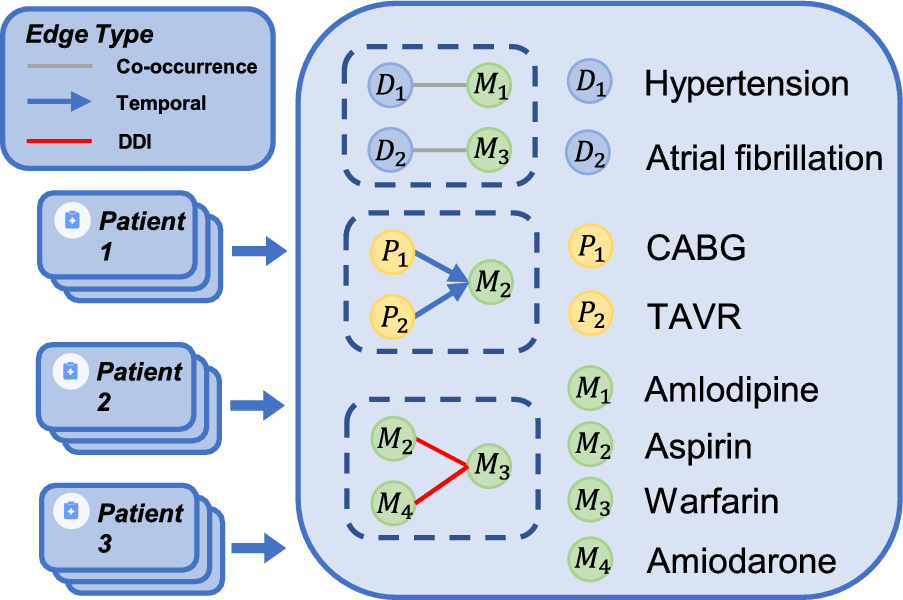
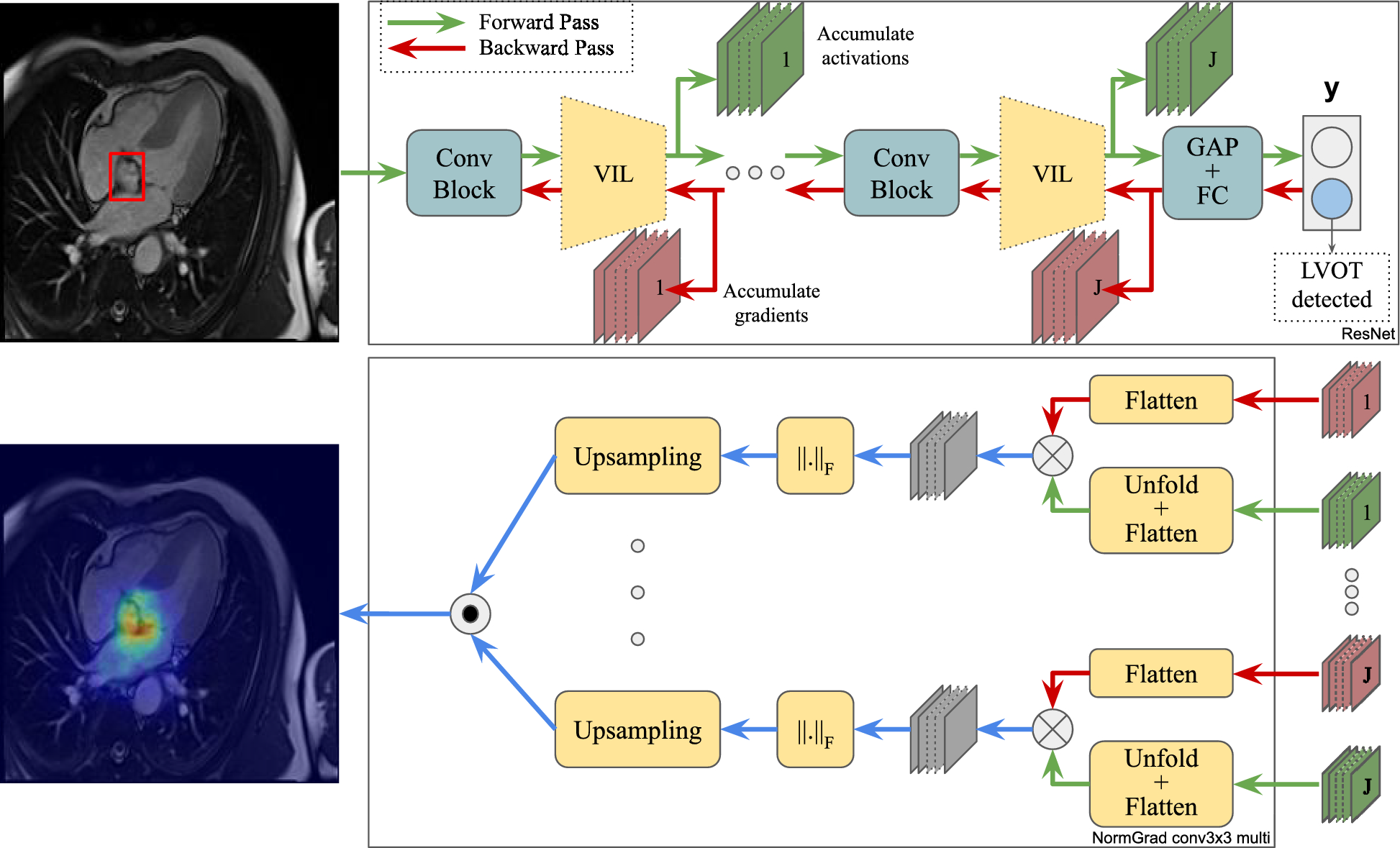
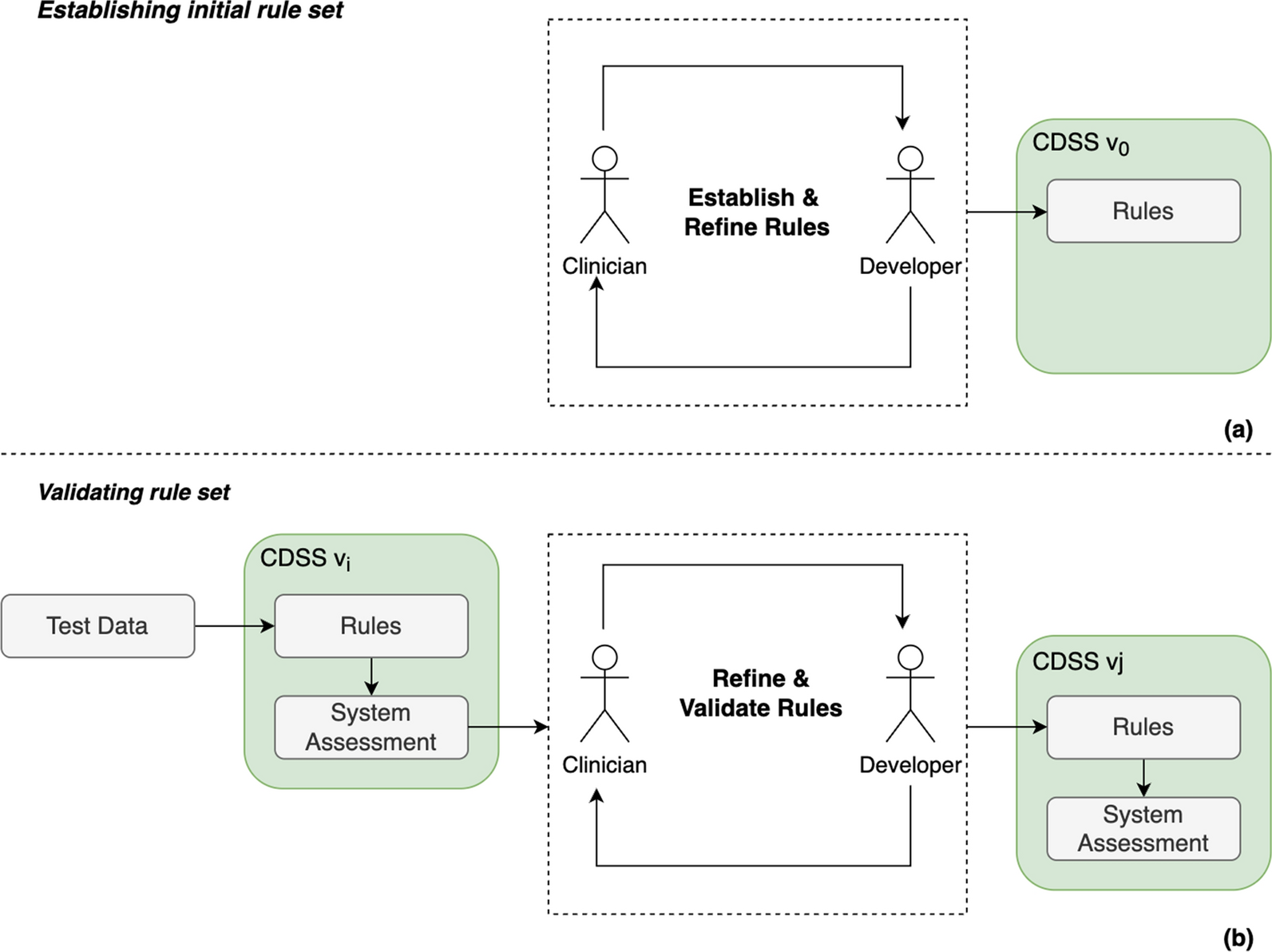
Table 2 presents the accuracy of LLM assessments for the experimental iterations of the various LLMs that generated rule sets that included variables comparable to our PiMS rule set. We limited our evaluation to few-shot prompting in Part A given that the variables in the generated rule sets were comparable to PiMS. Other prompting techniques specified rules using variables which were not included in our PiMS rule set. From the 20 experimental iterations (10 iterations from GPT-3.5 and 10 iterations from GPT-4 using few-shot prompting), only 6 iterations included rule sets with variables comparable to the PiMS rule set variables. The remaining 14 iterations included variables that were not defined in the PiMS rule set. When executing the LLM rule set on the PiMS patient data and comparing system assessments of the LLM generated rules and PiMS rules, we received an accuracy varying between 1.7 and 26.4%. The former was achieved by GPT-3.5 in iteration 10 whilst the latter was achieved by GPT-3.5 in iteration 6. GPT-4 reported accuracy of 17.5% and GPT-3.5 reported accuracies of 18.1, 17.2, 26.4, 23.5, and 1.7%.
Table 2 Accuracy of LLM assessments for the experimental iterations whereby the variables included in the generated rules were comparable to the PiMS variablesTable 3 compares the domain-specific variables from the rule sets generated by GPT-3.5 and GPT-4 across 10 experimental iterations to those found in the PiMS rule set. GPT-3.5 and GPT 4 generated rule sets that included only 33% and 47% of the variables used in our PiMS rule set, respectively. Both GPT-3.5 and GPT-4 failed to include two common COVID-19 symptoms, sore throat and runny nose. Despite GPT-4 including comorbidities such as hypertension, chronic respiratory disease and diabetes, it did not include cardiac disease and immunosuppressed. Thus, comorbidity was not included in the variable count as we cannot conduct a comparison.
Table 3 Comparison of domain-specific variables on LLM generated rule sets and PiMS rule set without defining variables in our few-shot promptsAssessing the interpretability, PiMS had a rule set of 41 whereby GPT-3.5 and GPT-4 scored low ranging between 3–4 and 2–4, respectively, across the 10 experimental iterations. This shows that LLMs generate fewer rule sets compared to PiMS that provides comprehensive and detailed rule sets.
Our PiMS rule set had a rule complexity of 44. The rule complexity of rule sets generated using few-shot prompting technique by GPT-3.5 varied between 5 and 7 with a median of 7. The rule complexity of rules generated using few-shot prompting technique by GPT-4 varied between 3 and 14 with a median value of 8. The low rule complexity of our LLM generated rule set indicates the LLM missed rules. Given the rule complexity is a measure of linear paths through the rule set, a lower value indicates fewer paths compared to the PiMS rule set. Thus, the LLM generated rule set has less complexity compared to the PiMS rule set.
Part BTable 4 presents the average accuracy and standard deviation from the ten iterations when we included the PiMS variables in our prompts, the highest accuracies are in bold. The highest accuracies for GPT-3.5, GPT-4, GPT-4o, Gemini, and Claude 3.5 Sonnet were 86.42, 74.21, 84.83, 76.99, and 84.86%, respectively. The lowest accuracies for GPT-3.5, GPT-4, GPT-4o, Gemini, and Claude 3.5 Sonnet were 11.20, 19.22, 1.80, 1.30, and 21.85%, respectively. Overall, GPT-3.5 resulted in the highest accuracy when using the sequential prompting technique, scoring 86.42% The highest accuracy for GPT-4o and Claude 3.5 Sonnet was through chain of thought prompting, scoring 84.83% and 84.86% respectively. The accuracies for Claude 3.5 Sonnet across all prompts were above 20%. GPT-4o and Gemini resulted in accuracies below 10%, with some as low as 1–3%. Table 5 presents the average accuracy and standard deviation from the ten iterations when including the PiMS variables in our prompts, the highest accuracies are in bold. The highest accuracies for GPT-o1-mini, Grok-4, and Claude 4 Sonnet were 86.57, 89.47, and 88.07%, respectively. The lowest accuracies for GPT-o1-mini, Grok-4 and Claude 4 Sonnet were 4.49, 11.90, and 2.30%, respectively.
Table 4 Average accuracy and standard deviation of LLM system assessments to PiMS system assessmentsTable 5 Average accuracy and standard deviation of LRM system assessments to PiMS system assessmentsFor a comprehensive analysis, Figs. 4, 5, 6, 7, 8 highlight the varying levels of accuracy across different prompting techniques on LLMs. For GPT-3.5 generated rules, few-shot + CoT and role-play had minimal impact on the accuracy resulting in low variability (58.04– 59.93%), refer to Fig. 4 In contrast, sequential and few-shot demonstrated significant impact in accuracies compared to other techniques, resulting in high variability (15.17– 86.42% for sequential and 11.20– 70.03% for few-shot). This was evident in GPT3-5 having the highest accuracy (86.42%) through sequential prompting technique. For GPT-4, instruction following showed less variability (36.77–46.14%) compared to chain of thought and few-shot + CoT prompting techniques that demonstrated noticeable variability (27.19–70.22%, 27.95– 68.66%, respectively), refer to Fig. 5 For GPT-4o, instruction following showed less variability (1.8–46.69%) compared to chain of thought (25.82–84.83%) and few-shot (12.4–54.26%) prompting techniques that showed considerable variability in accuracies, refer to Fig. 6 Gemini showed minimal variability in accuracies for few-shot prompting technique (69.30–73.57%) contrary to instruction following demonstrating noticeable variability (5.16–75.04%), refer to Fig. 7 Claude 3.5 Sonnet showed minimal variability in accuracies for few-shot (36.37– 62.47%) and few-shot + CoT prompting techniques (41.96– 59.32%) compared to high variability demonstrated by instruction following (36.59–77.48%), refer to Fig. 8 Data files that include numerical values relating to Figs. 4, 5, 6, 7, 8 can be found at https://doi.org/10.26187/deakin.30123043.v1, refer to the supplementary appendix as a guide to the files.
Fig. 4
Boxplot showing accuracies when six different prompting techniques were executed on GPT-3.5 model
Fig. 5
Box plot showing accuracies when six different prompting techniques were executed on GPT-4 model
Fig. 6
Box plot showing accuracies when six different prompting techniques were executed on GPT-4o model
Fig. 7
Box plot showing accuracies when six different prompting techniques were executed on Gemini model
Fig. 8
Box plot showing accuracies when six different prompting techniques were executed on Claude 3.5 Sonnet model
For a comprehensive analysis, Figs. 9–11 highlight the varying levels of accuracy across different prompting techniques on LRMs. For GPT-o1-mini generated rules, sequential with clinical context had minimal impact on the accuracy resulting in low variability (52.55– 81.75%), refer to Fig. 9. In contrast, chain of thought resulted in high variability (4.49–86.57%). For Grok-4, sequential prompting with clinical context showed less variability (74.92–89.47%), compared to instruction following (31.64–85.99%) and chain of thought (11.90–76.26%) prompting techniques that showed considerable variability in accuracies, refer to Fig. 10 Claude 4 Sonnet showed minimal variability in accuracies for few-shot (49.34–87.49%) compared to high variability demonstrated by role-play (11.90–88.07%) and chain of thought (2.30–85.26%) prompting techniques, refer to Fig. 11 Data files that include numerical values relating to Figs. 9–11 can be found at https://doi.org/10.26187/deakin.30123043.v1, refer to the supplementary appendix as a guide to the files.
Fig. 9
Box plot showing accuracies when six different prompting techniques were executed on GPT-o1-mini model
Fig. 10
Box plot showing accuracies when six different prompting techniques were executed on Grok-4 model
Fig. 11
Box plot showing accuracies when six different prompting techniques were executed on Claude 4 Sonnet model
The interpretability for the LLMs varied between 2 and 25 compared to 41 identified in our PiMS rule set while the interpretability for the LRMs varied between 3 and 94. Tables 6 and 7 summarises the interpretability presenting minimum, maximum, and median values for the LLMs and LRMs respectively when prompted with variables. As shown in Table 6, the distribution of interpretability of LLMs is highly skewed towards low and closer to zero than 41. Additionally, Table 6 shows that while most LLMs had similar median interpretability scores, they were closer to zero than 41 as per the PiMS rule set. However, the distribution of interpretability of LRMs varies across models whereby GPT-o1-mini and Grok-4 is highly skewed towards low compared to 41. Contrary, Claude 4 Sonnet improved interpretability with a median of 27. Our results indicate that the manually created PiMS rule set is more extensive and detailed compared to the LLM and LRM generated rules.
Table 6 The minimum, maximum, and median interpretability for the rule sets generated by different large language models compared to an interpretability of 41 for PiMSTable 7 The minimum, maximum, and median interpretability for the rule sets generated by different large reasoning models compared to an interpretability of 41 for PiMSOur PiMS rule set had a rule complexity of 44. The rule complexity of rules generated by the LLM and LRM varied significantly. The rule complexity of LLMs demonstrated minimum values ranging from 4 to 10 and maximum values spanning from 26 to 71, refer to Table 8 Median rule complexity scores indicate that GPT-4o had the highest value of 25, while Gemini had the lowest value of 14. LRMs resulted in minimum values ranging from 4 to 16 and maximum values ranging from 52 to 183, refer to Table 9 Median rule complexity scores indicate that Claude 4 Sonnet had the highest value of 46, while GPT-o1-mini had the lowest value of 19.
Table 8 The minimum, maximum, and median rule complexity for the rule sets generated by different large language models compared to a rule complexity of 44 for PiMSTable 9 The minimum, maximum, and median rule complexity for the rule sets generated by different large reasoning models compared to a rule complexity of 44 for PiMSOur manual inspection for Part B revealed logical errors. These logical errors included (1) overriding an amber status with a red status and (2) the failure of generated rules assigning uncertain as a system assessment to patient data. This indicates the logical complexity of rule sets, specifically with edge cases. It is evident that a green status (healthy) can be clearly identified; however, for a moderate or severe risk assessment the boundaries are not clearly defined. In addition, it is evident that LLMs do not consider uncertainty. This is evident as it fails to assign uncertainty data that is incomplete (missing data). Our manual inspection of logical errors against the rule complexity of the LLM and LRM generated rule sets is available at https://doi.org/10.26187/deakin.30123043.v1, refer to the supplementary appendix as a guide to the files.
Comments (0)