
Remember me
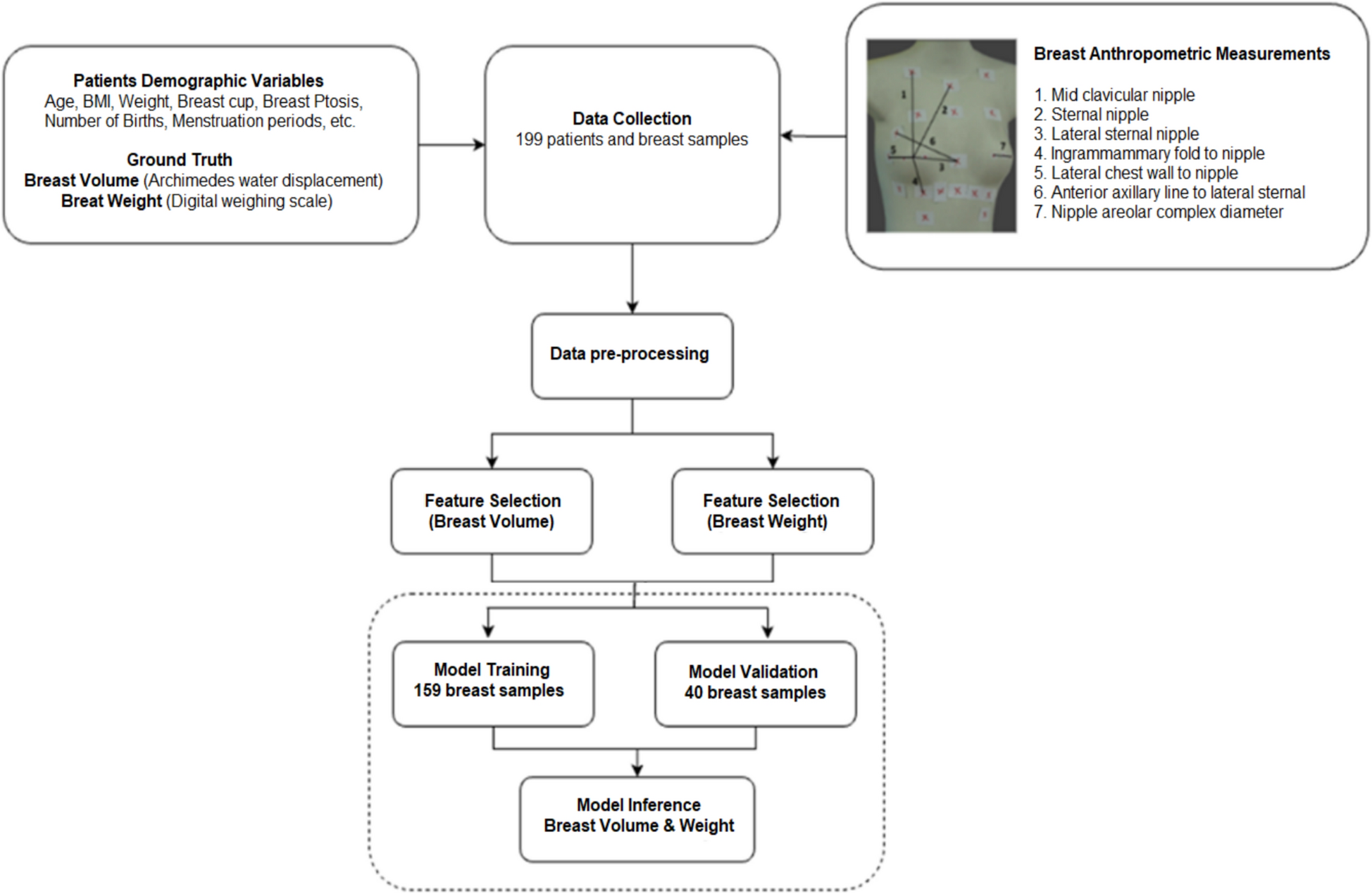
Due to the absence of a unified dataset covering both tasks, suitable benchmarks are selected independently for validation. To comprehensively evaluate the proposed Pose2Met framework, the two subtasks, namely 3D HPE and EEE, are assessed separately using widely adopted datasets in their respective domains. It should be noted that the energy prediction head is not used in the HPE mission because there is no energy tag.
Due to the absence of a unified dataset covering both tasks, suitable benchmarks are selected independently for validation. To comprehensively evaluate the proposed Pose2Met framework, the two subtasks, namely 3D HPE and EEE, are assessed separately using widely adopted datasets in their respective domains. It should be noted that the calorie head is not engaged during HPE evaluation due to the lack of corresponding energy labels.
For the HPE task, we evaluated the proposed STAPFormer model on two large-scale 3D pose datasets: Human3.6M and MPI-INF-3DHP. Human3.6M serves as the most widely adopted benchmark for indoor 3D pose estimation, containing approximately 3.6 million annotated poses and corresponding video frames collected from 11 subjects performing 15 daily activities. Following standard practice, data from subjects 1, 5, 6, 7, and 8 are used for training, while subjects 9 and 11 are reserved for evaluation. Performance is assessed using two metrics: the Mean Per Joint Position Error (MPJPE), which quantifies the Euclidean distance between the predicted and ground-truth poses after aligning the root joints, and the Procrustes-MPJPE, which computes the error after further applying a rigid alignment between the estimated and ground-truth poses.
MPI-INF-3DHP, another large-scale dataset, captures 3D pose sequences both indoors and outdoors, recording 8 participants performing 8 activities for training and 7 activities for evaluation. Consistent with previous works [31, 36, 50], the evaluation metrics used include MPJPE, the Percentage of Correct Keypoints (PCK) within a 150 mm threshold, and the Area Under the Curve (AUC) derived from the PCK curve.
For the EEE task, we validated the model on Vid2Burn-ADL. The Vid2Burn-ADL dataset extends energy expenditure annotations to NTU RGB+D, covering 39 types of daily activities, of which 33 are utilized for training and validation, and the remaining 6 are reserved for evaluating novel activities. Following the experimental settings of [15], we report performance using MAE, Spearmann Rank Correlation (SPC), and Negative Log Likelihood (NLL).
Implementation detailsWe implemented our methods in the PyTorch framework and executed on a server with two NVIDIA RTX 3090 GPUs. For the HPE task, the 2D pose sequences as input, which can either be detected by 2D pose estimator or ground-truth annotations. Similarly, for the EEE task, 3D poses, either predicted or ground-truth.
We designed two configurations with different numbers of STAP blocks. The base configuration employs L=16, achieving a balance between estimation accuracy and computational cost, while the lightweight configuration uses L=6 to further reduce resource requirements at the expense of a minor performance drop. Other hyperparameters are kept consistent across configurations: the feature dimension \(d=128\), the motion representation dimension \(d_e=512\), the expansion ratio of each MLP block to \(\alpha =4\), and the number of attention heads to h=8. During training, each mini-batch consists of 16 sequences. We adopt the AdamW optimizer with an initial learning rate of 5e-4, decayed by a factor of 0.99 after each epoch. Training is performed over 100 epochs to ensure sufficient convergence.
Comparison with state-of-the-art 3D HPE methodsResults on human3.6MWe conducted a comprehensive evaluation of STAPFormer on the Human3.6M dataset and compared its performance against state-of-the-art methods. Table 1 summarizes the detailed performance, highlighting the MPJPE and the P-MPJPE. All models were evaluated using 2D pose inputs detected by SH, CPN, or HR-Net, and the number of video frames T processed by each method is also reported. Overall, STAPFormer achieves superior performance compared to other non-diffusion-based methods, with an MPJPE of 38.2 mm and a P-MPJPE of 32.1 mm. Specifically, STAPFormer reduces the MPJPE by 1.0 mm (2.5%) compared to the best competitor, MotionBERT. These results validate the effectiveness of our proposed spatio-temporal pose aggregation representation. Unlike existing methods that separately model spatial and temporal information, STAPFormer jointly aggregates spatio-temporal features from neighboring keypoints, effectively suppressing input noise and enhancing feature stability and discriminability, leading to lower estimation errors even when using noisy 2D inputs.
Table 1 Quantitative comparisons of MPJPE in Protocol 1 (no rigid alignment) and Protocol 2 (rigid alignment) with the state-of-the-art methods on Human3.6M datasetWe further evaluated the models using ground-truth 2D poses to eliminate input noise and examine their theoretical upper-bound performance. Table 1 presents the results under this setting, where all methods show a noticeable reduction in MPJPE. STAPFormer achieves an MPJPE of 17.2 mm under Protocol 1 (P1), outperforming MotionBERT by 0.6 mm (a 3.3% relative decrease), demonstrating its superior potential. This performance gain stems from two key factors: (1) the entire sequence spatio-temporal attention mechanism in the aggregation module, which enhances global motion pattern extraction; (2) the GCN in Joint Brach incorporates skeletal structure priors to improve local positional modeling. In this evaluation, we focus on comparing STAPFormer with non-diffusion-based methods to emphasize its efficiency and suitability for real-time applications. Although diffusion-based approaches may offer higher accuracy, they often incur significant computational overhead and longer inference times, making them less practical for real-time scenarios. By distinguishing between diffusion and non-diffusion methods, we aim to highlight STAPFormer’s practical advantages, particularly its strong balance between accuracy and computational efficiency, positioning it as a more viable solution for applications requiring both real-time processing and high precision.
Results on MPI-INF-3DHPFor the evaluation on the MPI-INF-3DHP dataset, we followed the standard protocol used in prior works [12, 20, 23, 33], taking ground-truth 2D poses as the model input. Considering the shorter video sequences in this dataset, we set the number of input frames to 81. Table 2 reports the detailed comparative results.
Table 2 Quantitative comparisons on MPI-INF-3DHPOur model achieves state-of-the-art performance, surpassing all existing methods. Specifically, STAPFormer obtains a PCK of 98.8%, an AUC of 83.9%, and a P1 error of 20.5 mm. The experimental results demonstrate that STAPFormer consistently delivers outstanding performance even in challenging outdoor environments, validating the proposed method’s strong scene adaptability and generalization ability. These findings further highlight the practical value and broad applicability of STAPFormer in real-world scenarios.
Comparison with state-of-the-art EEE methodsResults based on Vid2Burn-ADLWe evaluated the performance of STAPFormer on the Vid2Burn-ADL dataset to assess its generalization capability across different activity categories. Following the settings of Vid2Burn-ADL, the evaluation was divided into two subsets: known activities, which appeared during training, and unknown activities, which were unseen during training. Table 3 presents the detailed comparison results. The experiments demonstrate that STAPFormer, using only pose inputs, achieved performance comparable to image-based methods.
Table 3 Results on Vid2Burn-ADL benchmarkFor known activities, the 2D pose-based STAPFormer-S initially achieved a mean absolute error (MAE) of 25.9 kcal under standard training. When the unified training framework was applied, the MAE decreased to 24.5 kcal, accompanied by improved correlation and reduced RMSE, demonstrating that jointly learning pose dynamics and metabolic responses enhances 2D-based energy prediction performance.
For unknown activities, the 2D model achieved a MAE of 44.5 kcal, which improved to 36.4 kcal under the unified training paradigm, indicating better generalization to unseen activities. This result addresses the issue reported in the Vid2Burn study [19], where pose-based models struggled with accurate energy expenditure prediction.
In comparison, the 3D-input STAPFormer-S model attained 22.8 kcal and 43.8 kcal for known and unknown activities under standard training, respectively, and fine-tuning further reduced the MAE to 22.3 kcal and 42.3 kcal. Overall, the results indicate that unified training significantly narrows the performance gap between 2D- and 3D-based energy predictions, while 3D fine-tuning provides additional gains, highlighting the complementary roles of unified learning and higher-dimensional pose input in robust EEE estimation.
Ablation studyEffect of different T on HPEThe initial set of experiments focus on examining the impact of varying the different number of input frames on the performance of STAPFormer model. Table 4 shows the detailed comparison in terms of P1 error. The performance of the model improves with an increase in the number of frames. In comparison with several methods, our STAPFormer demonstrates progressively superior performance in tests with 27, 81, and 243 frames, suggesting its enhanced suitability for longer sequences.
Table 4 The P1 error comparisons with different number of input frames(T) on Human3.6M datasetTable 5 Inference time and FPS performance of STAPFormer for different number of input frames (T)In addition, Table 5 demonstrates the real-time capability of STAPFormer. We evaluated the inference time across different number of input frames, revealing that shorted sequence yield faster persequence inference time, while longer sequence achieve higher FPS. Overall, with appropriate GPU acceleration, STAPFormer meets real-time requirements effectively. Experiments were conducted on a single NVIDIA RTX 3090 GPU, and the recorded inference times do not include the post-processing of model output. Despite increased computational complexity with longer sequences due to spatio-temporal attention mechanisms, STAPFormer demonstrates adaptability to real-time applications in sports and health analysis.
Effect of different STAP settings on HPEThe second ablation study examines the impact of varying kernel size k and stride s settings on model performance. Using SH-estimated poses of 27 frames as input, different aggregation settings influence the quantity of STAP tokens, which in turn affects model parameters, computational cost, and performance. Within the model architecture, k and s denote the convolution kernel size and stride used for feature aggregation in the STAP-mixer module.
Table 6 The P1 error comparisons with different aggregation settings (k, s) on Human3.6M datasetTable 6 compares P1 error across different settings. In summary, the k affects model parameters, while the s influences computational costs. A larger k and a smaller s tend to increase parameters and computational costs, but do not necessarily result in superior model performance. Experimental results revealed that the model performance varied across different aggregation settings, with \(k=5\) outperforming \(k=3\), \(s=2\) outperforming \(s= 1\) and \(s = 3\). The kernel size determines the scope of each aggregation operation (the number of adjacent joints and frames considered), with larger values providing a broader receptive field. Additionally, the stride parameter dictates how often aggregation occurs, striking a balance between maintaining connectivity between aggregated results and reducing information redundancy and computational load. These findings indicate that the choice of aggregation settings significantly influences the model’s ability to effectively capture temporal and spatial dependencies.
Effect of STAP block on HPEThe third series of experiments is designed to assess the effectiveness of integrating STAP block with various joint-mixers. This investigation will include the evaluation of three distinct types of joint-mixers: spatial-temporal convolution, mixed spatial-temporal attention, and STC attention. Spatial-temporal convolution serves as the basic mixer for constructing a baseline model, which employing two parallel convolution operations conducted separately in spatial and temporal dimension. Mixed spatial-temporal is the core of the MixSTE [33], comprising stacked transformer blocks alternately built using the MHSA-S and MHSA T mechanisms. STC refers to the core of the STCFormer [23], employing transformer blocks constructed based on STC, which is also the approach adopted in previous experiments.
Table 7 The P1 error comparisons with different joint-mixers on Human3.6M datasetAs depicted in Table 7, the experimental results demonstrate the performance of the models with different joint-mixers. Notably, the results demonstrate that the integration of STAP block with various joint-mixers leads to improvement in the performance of the models on MPJPE. This highlights the efficacy of incorporating STAP block in conjunction with different types of attention mechanisms to enhance the accuracy of 3D human pose estimation.
Effect of STAP block on EEETo assess the effectiveness of integrating STAP block on energy expenditure estimation (EEE), we conducted ablation experiments using the Vid2Burn-ADL dataset.
Table 8 Impact of STAP Block on EEE on the Vid2Burn-ADL DatasetThe results, summarized in Table 8, illustrate the effect of the STAP block on energy expenditure estimation. For 2D pose inputs under the unified training framework, incorporating the STAP block reduces the MAE from 29.2 kcal to 24.5 kcal for known activities, and from 36.7 kcal to 36.4 kcal for new activity types, while also improving SPC and NLL metrics. Similarly, for 3D pose inputs wit fine-tuning, adding the STAP block decreases the MAE from 23.0 kcal to 22.3 kcal for known activities and from 46.7 kcal to 42.3 kcal for new activities, confirming that the STAP block enhances the capture of spatiotemporal motion patterns. Overall, the performance gains are positively correlated with both the dimensional richness of the input and the inclusion of the STAP block, demonstrating its effectiveness in modeling detailed human motion for more accurate energy expenditure prediction.
Qualitative analysisIn this section, we validate our model through attention visualization and visualization of the 3D HPE results. The examples are randomly selected from the evaluation set of Human3.6M.
Attention visualizationFigure 4 visualizes the attention maps of the Joint-Branch and STAP-Branch from the final STAP block of the proposed STAPFormer. The spatial attention maps based on joints and STAP structures demonstrate the model’s ability to capture distinctive motion patterns associated with various actions, reflecting effective modeling of spatial characteristics. The temporal attention map of the Joint-Branch highlights strong correlations between adjacent frames, consistent with the inherent temporal continuity of human motion. In contrast, the STAP-Branch’s temporal attention map emphasizes the significance of multiple segments throughout the entire sequence, revealing characteristic patterns of human behavior under specific temporal contexts. Notably, the two branches exhibit distinct attention distributions: the STAP-Branch tends to allocate higher attention scores across a broader range of elements within the input sequence, thereby enhancing the model’s capacity to capture global information. This divergence further validates the complementary role of the dual-branch design in capturing both local dynamic details and global behavioral patterns, supporting the enhanced expressiveness of the learned pose representations.
Visualization comparisonThe qualitative analysis of the pose estimation results is depicted in Fig. 5, which showcases our proposed STAPFormer alongside recent transformer-besed methods, including MixSTE, STCFormer and MotionBERT. The examples are randomly selected from the Human3.6M dataset, covering the actions “Sitting Down” (Figure 5a), “Photo Taking” (Figure 5b), and “Walking Together” (Figure 5c). For each method, the estimated poses and ground-truth poses are plotted within the same figure to enable direct visual comparison. The visualizations demonstrate that STAPFormer consistently outperforms the competing approaches across various action types, achieving lower estimation errors and more structurally coherent 3D reconstructions. In particular, for challenging scenarios such as “Sitting Down,” where complex body configurations and joint deformations occur, STAPFormer exhibits superior accuracy in predicting 3D joint positions and reconstructing anatomically plausible poses, highlighting its strength in capturing intricate motion details.
Fig. 4
Visualization of attention maps from the Joint-Branch and STAP-Branch in STAPFormer. (a) Spatial attention maps for four actions: WalkTogether, Sitting, Photo, and Phone. (b) Temporal attention maps for WalkTwo. Each pair shows the STAP-Branch (left) and Joint-Branch (right). Axes represent query and predicted frames
Fig. 5
Examples of 3D pose estimation by our STAPFormer, MotionBERT, STCFormer and MixSTE. The gray skeleton is the ground-truth 3D pose. Blue, orange and red skeletons represent the left part, right part and torso of the estimated human pose, respectively
Comments (0)