
Remember me
Cell lines acquired from ATCC (Manassas, VA, USA) were grown at 37 °C in a 5% CO2 incubator and tested routinely for mycoplasma contamination. MCF10A cells were cultured in DMEM/F12 (catalog 11320; ThermoFisher, Waltham, MA, USA) with 5% horse serum (catalog 16050, ThermoFisher), 20 ng/mL EGF, 0.5 mg/mL hydrocortisone, 100 ng/mL Cholera toxin, 10 \(\mu\)g/mL bovine insulin with 1x penicillin/streptomycin. T47D, MDA-MB-231, MDA-MB-436, and MDA-MB-468 cells were cultured in DMEM (catalog 11965-092, ThermoFisher) with 10% fetal bovine serum (FBS; catalog 30–2020, ATCC), 4 mM L-glutamine and 10 mM HEPES, pH 7.4. AU565 cells were cultured in RPMI-1640 Medium (catalog 22400-089; Gibco by Life Technologies) with 10% fetal bovine serum (FBS; catalog 30–2020, ATCC). Clear imaging media consisted of phenol-free DMEM with 0.5% Bovine Serum albumin (BSA; catalog A9085, Millipore-Sigma), 4 mM L-glutamine and 20 mM HEPES, pH 7.4. The characteristics of the breast cancer cell lines are as following: AU565 cells displays amplification and overexpression of epithelial growth factor receptor 2 (HER2), and expression of HER3, HER4 and p53 oncogenes. T47D cells are luminal A subtype expressing estrogen receptor (ER) and progesterone receptor (PR). MDA-MB-231 and MDA-MB-468 are basal triple negative breast cancer (TNBC) subtype, lacking expression of HER2, ER and PR. MDA-MB-231 shows lower EGFR expression, while MDA-MB-468 displays EGFR amplification. MDA-MB-436 are claudin-low TNBC subtype. MCF10A is an immortalized, non-tumorigenic human mammary epithelial cell line used as a model for normal breast epithelial cells.
Transferrin (Tf) internalization, cell fixation, immunofluorescence and airyscan microscopyCells were cultured overnight on an \(\mu\)-Slide 8 well glass bottom plate (Lot 171005/3, Ibidi), pre-incubated for 30 min with clear imaging media, incubated with AF568-transferrin (Tf) (catalog T-23365, Invitrogen) (25 \(\mu\)g/mL) for 10 min at 37oC to label recycling endosomes. and then washed and fixed with 4% paraformaldehyde (PFA) for 10 min. Tf-containing cells were permeabilized with 0.1% TritonX-100 in phosphate-buffered saline (ThermoFisher BP151) for 15 min at room temperature, blocked for 90 min on a gentle rocker-shaker in 2% fish skin gelatin (FGS, G7765, Millipore-Sigma, St. Louis, MO), 1% bovine serum albumin in PBS. Subsequent washing and antibody blocking were completed with 0.5% FSG, 0.05% TX-100 in PBS. Two primary antibodies were used per experiment. Primary antibodies included anti-EEA1 (catalog 610456, BD Bioscience), and Tom20 (FL-145) (catalog sc-11415, Santa Cruz Biotechnology, Inc.). EEA1 (early endosomal antigen 1) is a marker for early endosomes while Tom20 is a marker for the outer mitochondrial membrane.
Upon completion of both primary and secondary antibody staining using F(ab)’2 secondary antibodies labeled with AF488 or AF647 (catalog A11070, A21237, Life Technologies, respectively), cells underwent postfixation with 4% PFA for 5 min followed by nuclear labeling using DAPI counterstaining for 15 min (1:1). All solutions were 0.2 \(\mu\)m syringe filtered. 26 three-dimensional (z-stack image series), multichannel images were collected on a Zeiss LSM880 with Airyscan detector in SR mode under Nyquist sampling and subjected to Airyscan processing (pixel reassignment). Four channels allowed for the visualization of the following organelles: i) early endosomal compartments immunostained with anti-EEA1, ii) mitochondria immunostained with anti-Tom20, iii) recycling endosomes directly labeled with AF568-Tf and iv) the nucleus labeled with DAPI. Only EEA1, Tom20 and Tf -labeled images were used for further analysis.
Patch sampling and sparsity filteringIn the OTCCP workflow, three-dimensional rendering of organelle objects and extraction of organelle topology and morphology handcrafted features for incorporation into the OTCCP framework are performed using Imaris image analysis software, as described in our previous work [14]. This object-based preprocessing results in many individual organelle objects being analyzed per image, thereby augmenting the dataset to focus specifically on organelles of interest. These handcrafted organelle-level features were subsequently used as inputs to a deep neural network (DNN) classifier, and the resulting performance is reported in Table 1. The new proposed framework performs direct classification on microscopy images instead of relying on 3D object rendering. Microscopy images are spatial arrays in which fluorescently labeled cellular markers produce structured signals against a predominantly black background. Thus, the image consists of sparse, structured signals corresponding to cells and organelles embedded in a predominantly dark field, where pixel intensities directly reflect the presence and abundance of biological targets. Therefore, our end-to-end deep learning pipeline integrates a sparsity-filtered image patch preprocessing approach to form a larger imaging dataset for deep learning. First, raw 3D fluorescent confocal microscopy images were partitioned by z-stacks to form 2D images of each XY plane in the image. Patches from each slice are then extracted at specified pixel sizes, resulting in a dataset of patches derived from the original microscopy images. Each patch was subsequently assigned a class label based on the corresponding cell line for the original image, as confocal images in this experiment were taken on monocultures.
Table 1 Classification performance metrics for all evaluated classifiersSecond, to facilitate classification based on subcellular features and avoid the misinterpretation of sparse backgrounds as informative features, a threshold filtering-based approach is conducted after the initial patch generation. Global Otsu Thresholding is applied on the entire 3D confocal image, thus determining a threshold value to separate cell material from the background. This threshold is applied to each patch, thus resulting in cellular organelle masks for each patch. Subsequently, a foreground ratio is calculated for each patch, and sparse patches below a certain value are discarded from the dataset. Figure 1 illustrates this patch preprocessing pipeline.
Fig. 1
Dataset preprocessing pipeline via patch extraction and threshold-based sparsity detection. 3D confocal microscopy images are sectioned into different z-stacks and patches are extracted in a grid-like sequence. To avoid the inclusion of sparse portions of the image, global Otsu thresholding is applied to separate the cell from the background, and the patch is either accepted or rejected depending on the resulting calculated foreground ratio. The result is a dataset of non-sparse 2D image patches derived from the original microscopy images
Patch dataset specificationsTo avoid potential deep learning bias, the image channel relating to the nucleus was excluded to limit the analysis toward organelle features. Consequently, the resulting image sizes featured XY plane dimensions of 1248x1248 or 1364x1364 pixels, z-stack depths ranging from 43 to 207 slices, and 3 channels. To further improve network robustness, on-the-fly data augmentation was applied during training, including random horizontal and vertical flips, 90-degree rotations, cropping, and small-angle rotation.
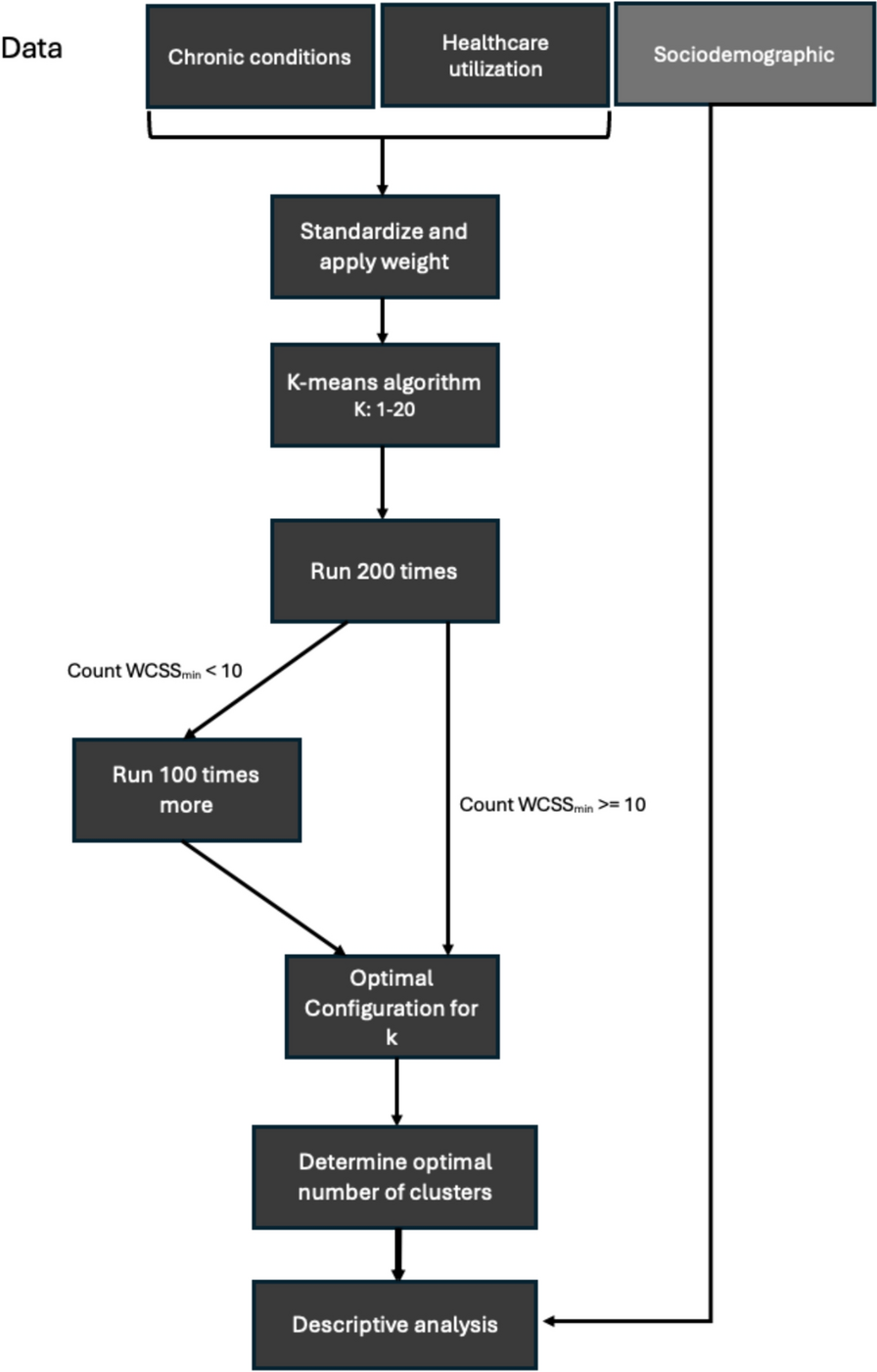
Network architecture, training, and validationWe implemented several homogenous data fusion strategies, all implemented within a standardized pipeline that maintained identical preprocessing, encoder architecture, and hyperparameter tuning to enable fair comparison. Each network used a ResNet50 backbone in which image patches were processed through convolutional layers for feature extraction, initialized with ImageNet pretraining for improved performance and generalization [23,24,25]. The resulting features were passed to fully connected layers that assigned a cell line label to each patch. Hyperparmeter tuning, implemented through Keras hyperband tuner, was used to determine optimal hyperparameters for the network. This resulted in a batch size of 32, an Adam optimizer with an initial learning rate of 3 \(\times 10^\) under exponential decay of 0.95 every 175 steps, dropout layers set to 0.4, batch normalization applied after each convolutional block, L2 regularization for fully connected layers, and categorical cross-entropy as the loss function. Early stopping based upon validation accuracy with a maximum of 100 epochs and a patience of 15 epochs was used to further prevent overfitting. Training employed stratified 5-fold cross-validation at the patch level, ensuring each fold contained a balanced distribution of patches from all cell lines. Furthermore, patches derived from the same original microscopy image were kept within the same fold to avoid data leakage and artificially inflated performance. The dataset was split into 80% training and 20% validation within each fold, with the final evaluation performed on a held-out test set. To address class imbalance in the number of patches per cell line, class weighting was applied to the loss function, where each class weight was inversely proportional to its relative frequency in the training set. This weighting ensured that minority classes contributed proportionally more to the loss, reducing bias toward more represented cell lines. The early fusion architecture contained approximately 26 million trainable parameters, whereas the intermediate and late fusion networks each contained approximately 72 million parameters. All network training was performed in TensorFlow and Keras on an NVIDIA RTX A6000 GPU.
Comments (0)