Bray F, Laversanne M, Sung H, Ferlay J, Siegel RL, Soerjomataram I, et al. Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2024 May-Jun;74(3):229–63. PMID: 38572751. DOI: https://doi.org/10.3322/caac.21834
Jia X, Pang Y, Liu LS. Online Health Information Seeking Behavior: A Systematic Review. Healthcare (Basel). 2021;9(12):1740–54. PMID: 34946466. DOI: https://doi.org/10.3390/healthcare9121740
Article
PubMed
PubMed Central
Google Scholar
Davis SN, O’Malley DM, Bator A, Ohman-Strickland P, Hudson SV. Correlates of Information Seeking Behaviors and Experiences Among Adult Cancer Survivors in the USA. J Cancer Educ. 2021;36(6):1253–60. PMID: 32358717. DOI: https://doi.org/10.1007/s13187-020-01758-6
Article
PubMed
PubMed Central
Google Scholar
Jiang S, Liu PL. Digital divide and Internet health information seeking among cancer survivors: A trend analysis from 2011 to 2017. Psychooncology. 2020;29(1):61–7. PMID: 31652360. DOI: https://doi.org/10.1002/pon.5247
Article
PubMed
Google Scholar
Zheng S, Tong X, Wan D, Hu C, Hu Q, Ke Q. Quality and Reliability of Liver Cancer-Related Short Chinese Videos on TikTok and Bilibili: Cross-Sectional Content Analysis Study. J Med Internet Res. 2023;25:e47210. PMID: 37405825. DOI: https://doi.org/10.2196/47210
Kurtzman RT, Mikesell L, Crabtree BF. Evaluation of NCI-Designated Cancer Center and Comprehensive Cancer Center Survivorship-Focused Websites: Information Provided and Accessibility. J Natl Compr Canc Netw. 2024;22(7):475–81. PMID: 39151450. DOI: https://doi.org/10.6004/jnccn.2024.7017
Article
PubMed
Google Scholar
Gunduz ME, Matis GK, Ozduran E, Hanci V. Evaluating the Readability, Quality, and Reliability of Online Patient Education Materials on Spinal Cord Stimulation. Turk Neurosurg. 2024 Jun 26;34(4):588–99. PMID: 38874237. DOI: https://doi.org/10.5137/1019-5149.jtn.42973-22.3
Uprety D, Zhu D, West HJ. ChatGPT-A promising generative AI tool and its implications for cancer care. Cancer. 2023;129(15):2284–9. PMID: 37183438. DOI: https://doi.org/10.1002/cncr.34827
Article
PubMed
Google Scholar
Suárez A, Díaz-Flores García V, Algar J, Gómez Sánchez M, Llorente de Pedro M, Freire Y. Unveiling the ChatGPT phenomenon: Evaluating the consistency and accuracy of endodontic question answers. Int Endod J. 2024;57(1):108–13. PMID: 37814369. DOI: https://doi.org/10.1111/iej.13985
Article
PubMed
Google Scholar
Ozduran E, Hanci V, Erkin Y. Evaluating the readability, quality and reliability of online patient education materials on chronic low back pain. Natl Med J India. 2024 Oct 10;37(3):124 – 30. PMID: 39399994. DOI: https://doi.org/10.25259/nmji_327_2022
Sallam M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare (Basel). 2023;11(6):887–901. PMID: 36981544. DOI: https://doi.org/10.3390/healthcare11060887
Article
PubMed
PubMed Central
Google Scholar
Ruksakulpiwat S, Kumar A, Ajibade A. Using ChatGPT in Medical Research: Current Status and Future Directions. J Multidiscip Healthc. 2023 May 30;2023(16):1513-20. PMID: 37274428. DOI: https://doi.org/10.2147/jmdh.s413470
Shao X, Ruan T, Ju X, Sun Y, Cui J. Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency. Digit Health. 2025;2025(11): 847 – 61. PMID: 40881062. DOI: https://doi.org/10.1177/20552076251367645
Ruan T, Shao X, Sun Y, Ju X, Cui J. Evaluation of accuracy, quality, and readability of information on hypothyroidism provided by different artificial intelligence chatbot models. Front Public Health. 2025 Dec 10;2025(13): 1253–70. DOI: https://doi.org/10.1177/20552076251367645
Scaff SPS, Reis FJJ, Ferreira GE, Jacob MF, Saragiotto BT. Assessing the performance of AI chatbots in answering patients’ common questions about low back pain. Ann Rheum Dis. 2025;84(1):143–9. PMID: 39874229. DOI: https://doi.org/10.1136/ard-2024-226202
Article
PubMed
Google Scholar
Kayra MV, Anil H, Ozdogan I, Baradia SMA, Toksoz S. Evaluating AI chatbots in penis enhancement information: a comparative analysis of readability, reliability and quality. Int J Impot Res. 2025;37(7):558–63. PMID: 40461830. DOI: https://doi.org/10.1038/s41443-025-01098-3
Article
PubMed
PubMed Central
Google Scholar
Erden Y, Temel MH, Bağcıer F. Artificial intelligence insights into osteoporosis: assessing ChatGPT’s information quality and readability. Arch Osteoporos. 2024;19(1):17–28. PMID: 38499716. DOI: https://doi.org/10.1007/s11657-024-01376-5
Article
PubMed
Google Scholar
Gupta S, Haislup BD, Tyagi A, Sudah SY, Hoffman RA, Murthi AM. Assessment and comparison of artificial intelligence-generated information regarding shoulder arthroplasty from multiple interfaces. J Shoulder Elbow Surg. 2025 Sep 18;34(9):2216-23. PMID: 39971091. DOI: https://doi.org/10.1016/j.jse.2024.12.048
Şahin MF, Keleş A, Özcan R, Doğan Ç, Topkaç EC, Akgül M, et al. Evaluation of information accuracy and clarity: ChatGPT responses to the most frequently asked questions about premature ejaculation. Sex Med. 2024 Jun 24;12(3):563 – 76. PMID: 38832125. DOI: https://doi.org/10.1093/sexmed/qfae036
Gunesli I, Aksun S, Fathelbab J, Yildiz BO. Comparative evaluation of ChatGPT-4, ChatGPT-3.5 and Google Gemini on PCOS assessment and management based on recommendations from the 2023 guideline. Endocrine. 2025 Apr 12;88(1):315 – 22. PMID: 39623241. DOI: https://doi.org/10.1007/s12020-024-04121-7
Cao H, Hao C, Zhang T, Zheng X, Gao Z, Wu J, et al. Battle of the artificial intelligence: a comprehensive comparative analysis of DeepSeek and ChatGPT for urinary incontinence-related questions. Front Public Health. 2025 Jul 23;2025(13): 342 – 57. PMID: 40771241. DOI: https://doi.org/10.3389/fpubh.2025.1605908
Agha RA MG, Rashid R, Kerwan A, Al-Jabir A, Sohrabi C, Franchi T, Nicola M, Agha M. Revised Strengthening the reporting of cohort, cross-sectional and case-control studies in surgery (STROCSS) Guideline: An update for the age of Artificial Intelligence. Int J Surg. 2024;110(6):3151–3165. DOI: https://doi.org/10.1097/js9.0000000000001268
Article
PubMed
PubMed Central
Google Scholar
Pan A, Musheyev D, Bockelman D, Loeb S, Kabarriti AE. Assessment of Artificial Intelligence Chatbot Responses to Top Searched Queries About Cancer. JAMA Oncol. 2023;9(10):1437–40. PMID: 37615960. DOI: https://doi.org/10.1001/jamaoncol.2023.2947
Article
PubMed
PubMed Central
Google Scholar
Campbell DJ, Estephan LE, Sina EM, Mastrolonardo EV, Alapati R, Amin DR, et al. Evaluating ChatGPT Responses on Thyroid Nodules for Patient Education. Thyroid. 2024 Mar 26;34(3):371-7. PMID: 38010917. DOI: https://doi.org/10.1089/thy.2023.0491
Momenaei B, Wakabayashi T, Shahlaee A, Durrani AF, Pandit SA, Wang K, et al. Appropriateness and Readability of ChatGPT-4-Generated Responses for Surgical Treatment of Retinal Diseases. Ophthalmol Retina. 2023 Oct 3;7(10):862-8. PMID: 37277096. DOI: https://doi.org/10.1016/j.oret.2023.05.022
Gibson D, Jackson S, Shanmugasundaram R, Seth I, Siu A, Ahmadi N, et al. Evaluating the Efficacy of ChatGPT as a Patient Education Tool in Prostate Cancer: Multimetric Assessment. J Med Internet Res. 2024;2024(26):e55939. PMID: 39141904. DOI: https://doi.org/10.2196/55939
Xu Q, Wang J, Chen X, Wang J, Li H, Wang Z, et al. Assessing the Efficacy of ChatGPT Prompting Strategies in Enhancing Thyroid Cancer Patient Education: A Prospective Study. J Med Syst. 2025;49(1):11–23. PMID: 39820814. DOI: https://doi.org/10.1007/s10916-024-02129-0
Article
PubMed
Google Scholar
Delsoz M, Hassan A, Nabavi A, Rahdar A, Fowler B, Kerr NC, et al. Large Language Models: Pioneering New Educational Frontiers in Childhood Myopia. Ophthalmol Ther. 2025;14(6):1281–95. PMID: 40257570. DOI: https://doi.org/10.1007/s40123-025-01142-x
Article
PubMed
PubMed Central
Google Scholar
Wu H, Su Z, Pan X, Shao A, Xu Y, Wang Y, et al. Enhancing diabetic retinopathy query responses: assessing large language model in ophthalmology. Br J Ophthalmol. 2025;109(11):1272–1278. PMID: 40588331. DOI: https://doi.org/10.1136/bjo-2024-325861
Article
PubMed
PubMed Central
Google Scholar
Akkan H, Seyyar GK. Improving readability in AI-generated medical information on fragility fractures: the role of prompt wording on ChatGPT’s responses. Osteoporos Int. 2025;36(3):403–10. PMID: 39777491. DOI: https://doi.org/10.1007/s00198-024-07358-0
Article
PubMed
Google Scholar
Köksaldı S, Kayabaşı M, Durmaz Engin C, Grzybowski A. Accuracy of ChatGPT, Gemini, Copilot, and Claude to Blepharoplasty-Related Questions. Aesthetic Plast Surg. 2025;49(17):4775–4785. PMID: 40691658. DOI: https://doi.org/10.1007/s00266-025-05071-9
Article
PubMed
Google Scholar
Meskó B. Prompt Engineering as an Important Emerging Skill for Medical Professionals: Tutorial. J Med Internet Res. 2023;2023(25):e50638. PMID: 37792434. DOI: https://doi.org/10.2196/50638
Article
Google Scholar
Wu Q, Wu Q, Li H, Wang Y, Bai Y, Wu Y, et al. Evaluating Large Language Models for Automated Reporting and Data Systems Categorization: Cross-Sectional Study. JMIR Med Inform. 2024;2024(12):e55799. PMID: 39018102. DOI: https://doi.org/10.2196/55799
Zhou M, Pan Y, Zhang Y, Song X, Zhou Y. Evaluating AI-generated patient education materials for spinal surgeries: Comparative analysis of readability and DISCERN quality across ChatGPT and deepseek models. Int J Med Inform. 2025 Jun 13;2025(198):105871-83. PMID: 40107040. DOI: https://doi.org/10.1016/j.ijmedinf.2025.105871
Alassaf MS, Abu Aof MM, Alharbi OA, Turkustani A, Karbouji MI, Althagafi N, et al. A qualitative analysis of Arabic language websites about extraction of third molars. Digit Health. 2025 Feb 10:2025(11):20552076251321053. PMID: 39935425. DOI: https://doi.org/10.1177/20552076251321053
Ozduran E, Akkoc I, Büyükçoban S, Erkin Y, Hanci V. Readability, reliability and quality of responses generated by ChatGPT, gemini, and perplexity for the most frequently asked questions about pain. Medicine (Baltimore). 2025;104(11):e41780. PMID: 40101096. DOI: https://doi.org/10.1097/md.0000000000041780
Kara M, Ozduran E, Kara MM, Özbek İ C, Hancı V. Evaluating the readability, quality, and reliability of responses generated by ChatGPT, Gemini, and Perplexity on the most commonly asked questions about Ankylosing spondylitis. PLoS One. 2025;20(6):e0326351. PMID: 40531978. DOI: https://doi.org/10.1371/journal.pone.0326351
Article
PubMed
PubMed Central
CAS
Google Scholar
Tam TYC, Sivarajkumar S, Kapoor S, Stolyar AV, Polanska K, McCarthy KR, et al. A framework for human evaluation of large language models in healthcare derived from literature review. NPJ Digit Med. 2024;7(1):258–65. PMID: 39333376. DOI: https://doi.org/10.1038/s41746-024-01258-7
Article
PubMed
PubMed Central
Google Scholar
Chen J, Ge X, Yuan C, Chen Y, Li X, Zhang X, et al. Comparing orthodontic pre-treatment information provided by large language models. BMC Oral Health. 2025;25(1):838–46. PMID: 40437500. DOI: https://doi.org/10.1186/s12903-025-06246-1
Article
PubMed
PubMed Central
Google Scholar
Wang L, Chen X, Deng X, Wen H, You M, Liu W, et al. Prompt engineering in consistency and reliability with the evidence-based guideline for LLMs. NPJ Digit Med. 2024;7(1):41–9. PMID: 38378899. DOI: https://doi.org/10.1038/s41746-024-01029-4
Article
PubMed
PubMed Central
Google Scholar
Nguyen D, Swanson D, Newbury A, Kim YH. Evaluation of ChatGPT and Google Bard Using Prompt Engineering in Cancer Screening Algorithms. Acad Radiol. 2024;31(5):1799–804. PMID: 38103973. DOI: https://doi.org/10.1016/j.acra.2023.11.002
Article
PubMed
Google Scholar
Dihan Q, Chauhan MZ, Eleiwa TK, Brown AD, Hassan AK, Khodeiry MM, et al. Large language models: a new frontier in paediatric cataract patient education. Br J Ophthalmol. 2024;108(10):1470-6. PMID: 3917

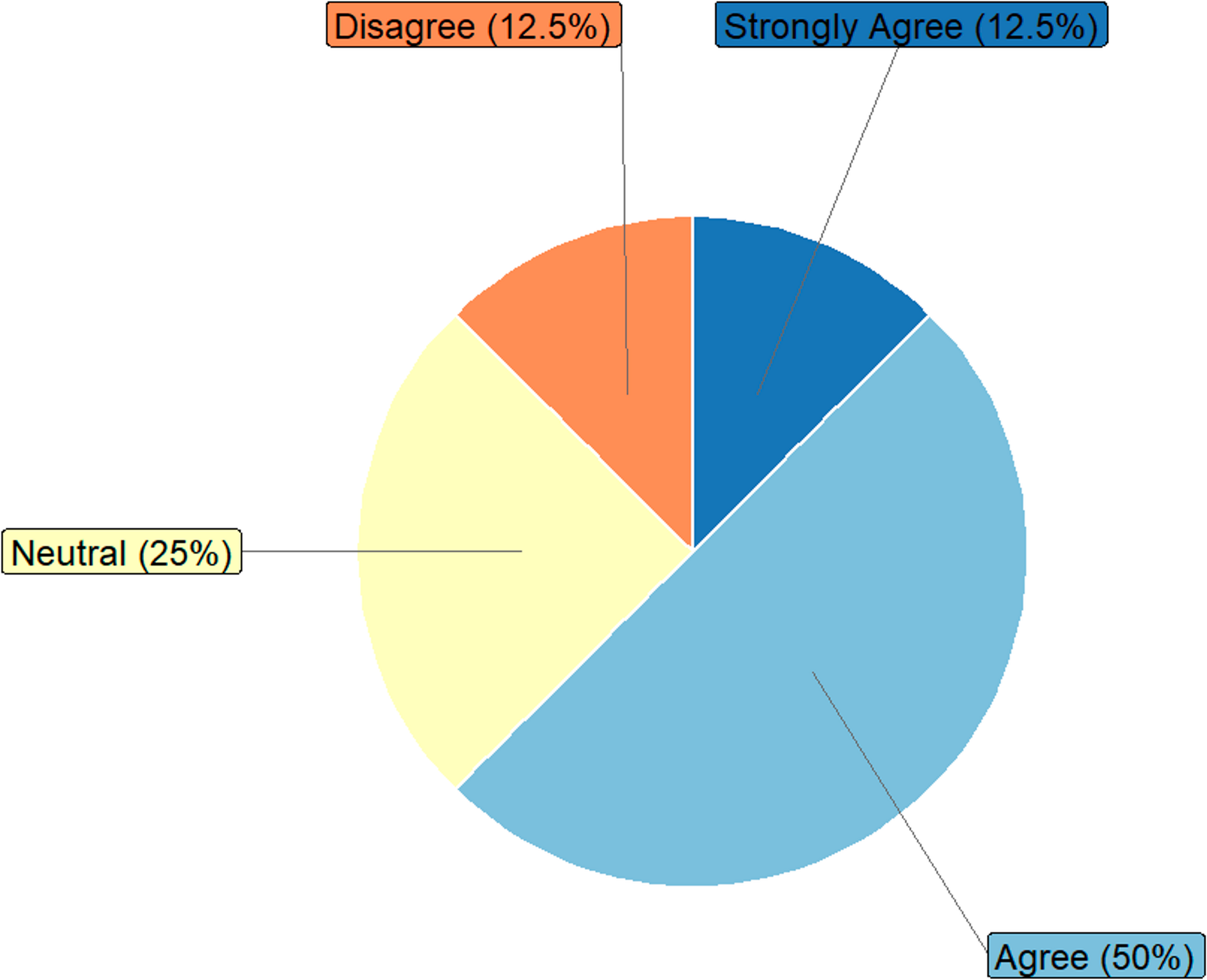
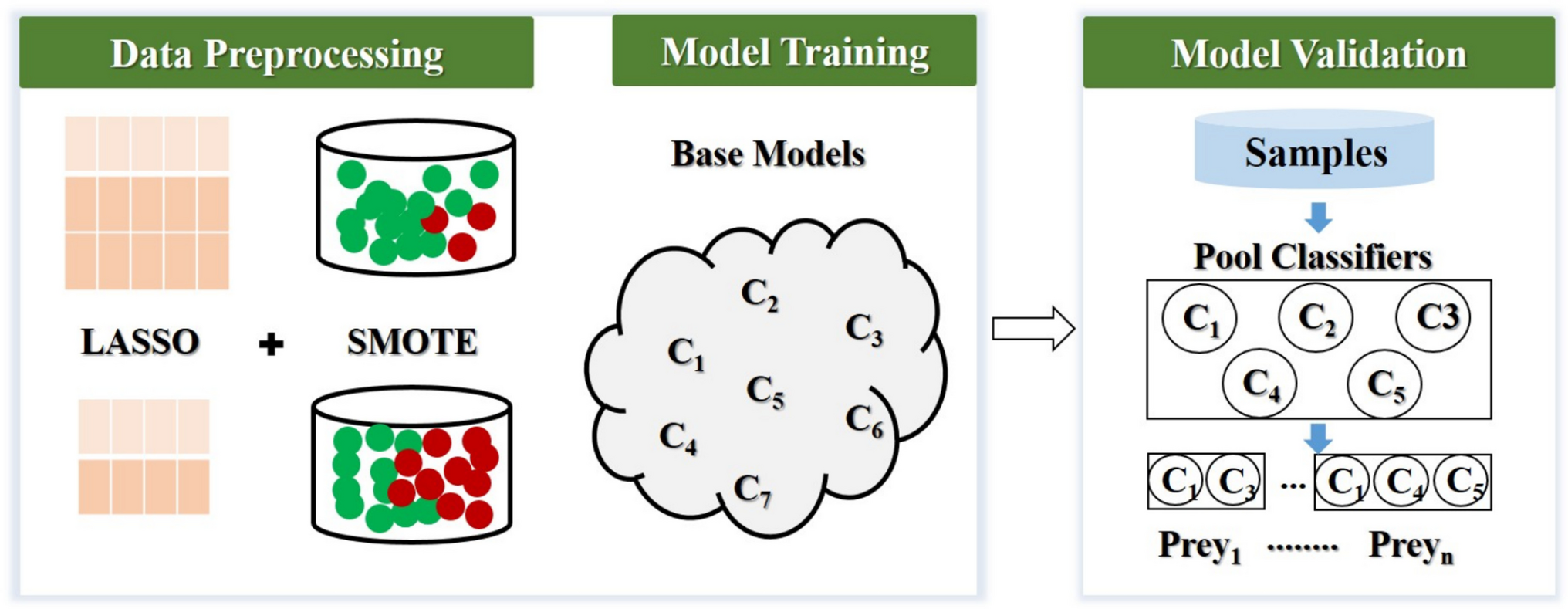
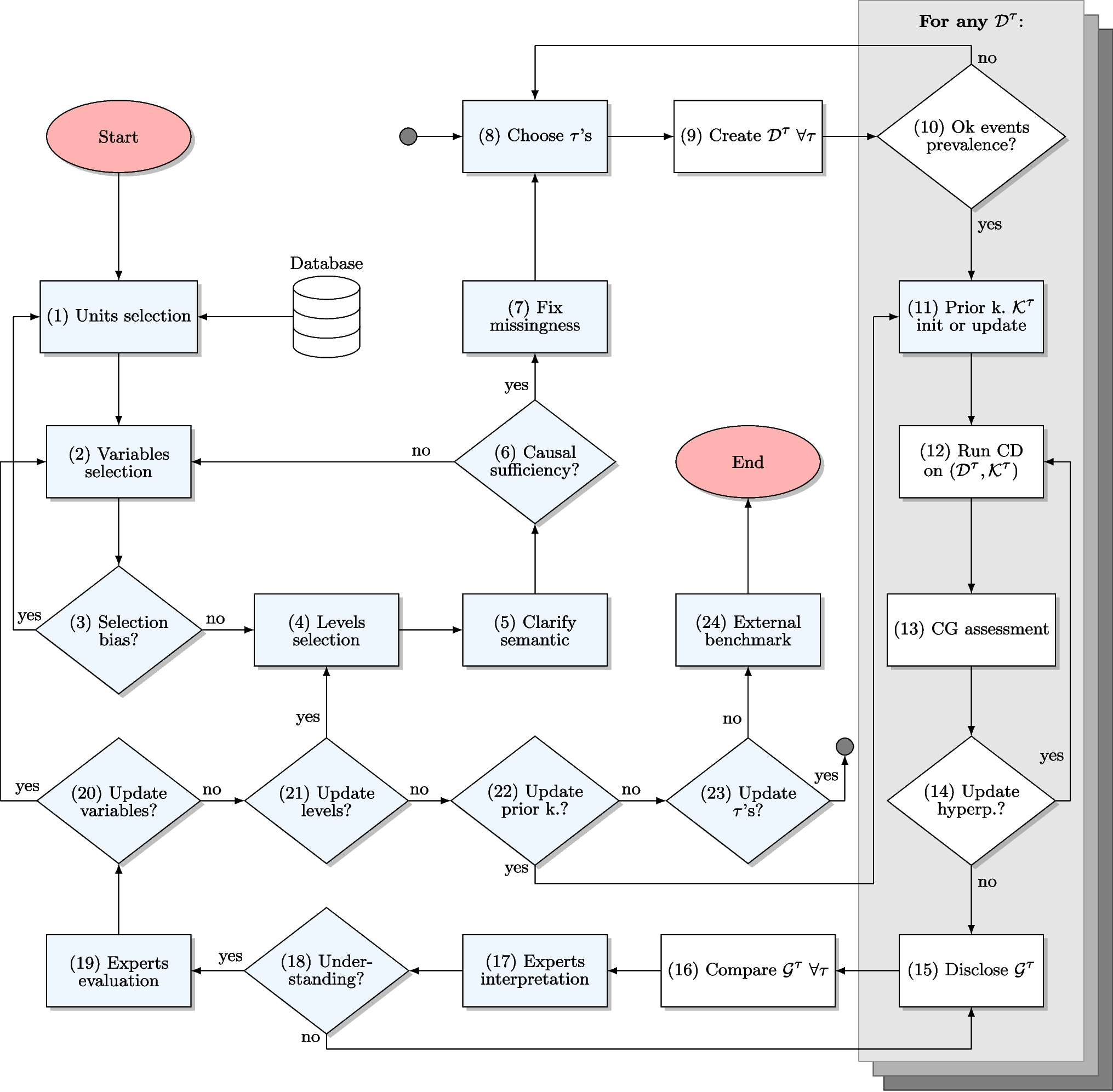
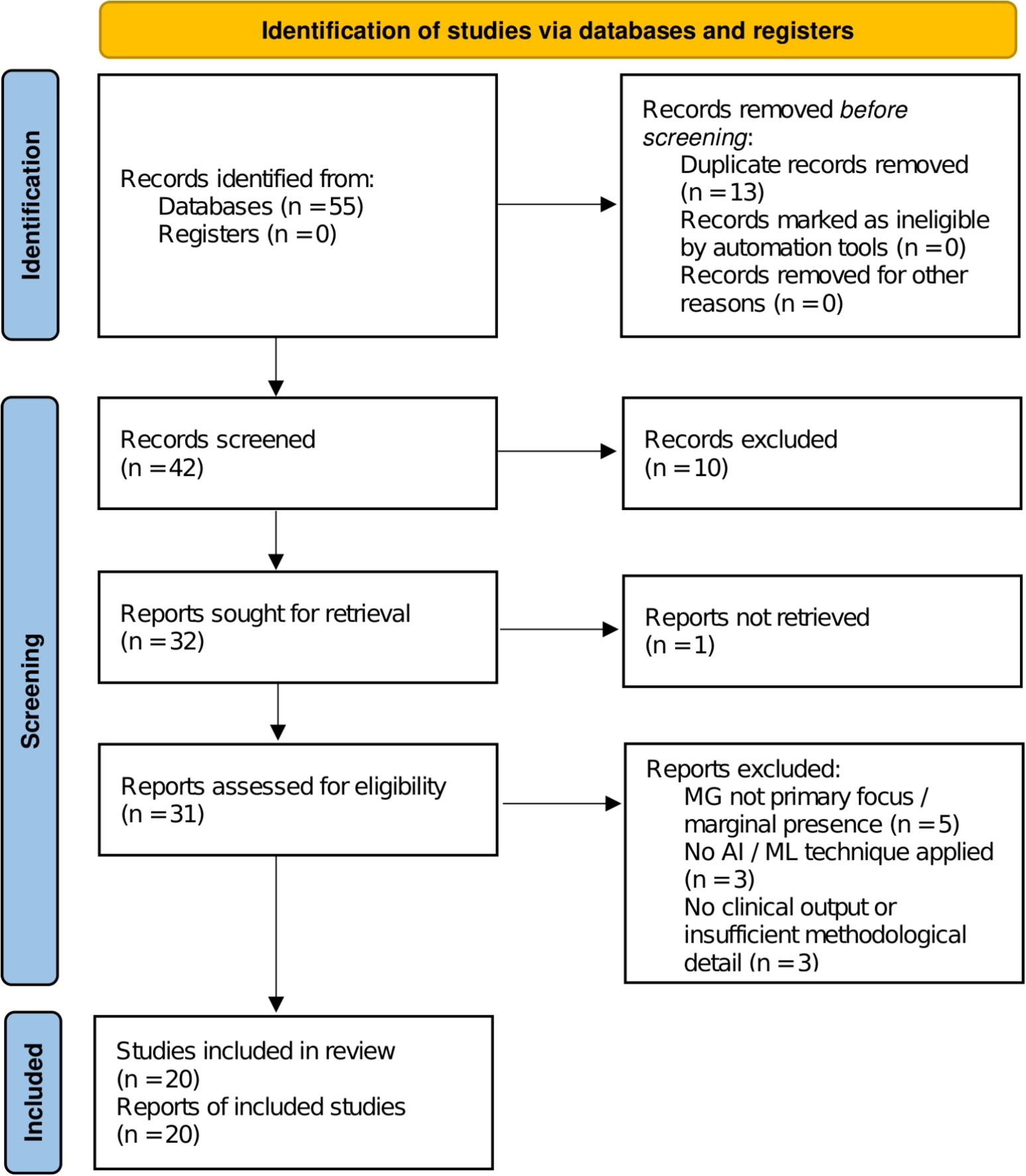
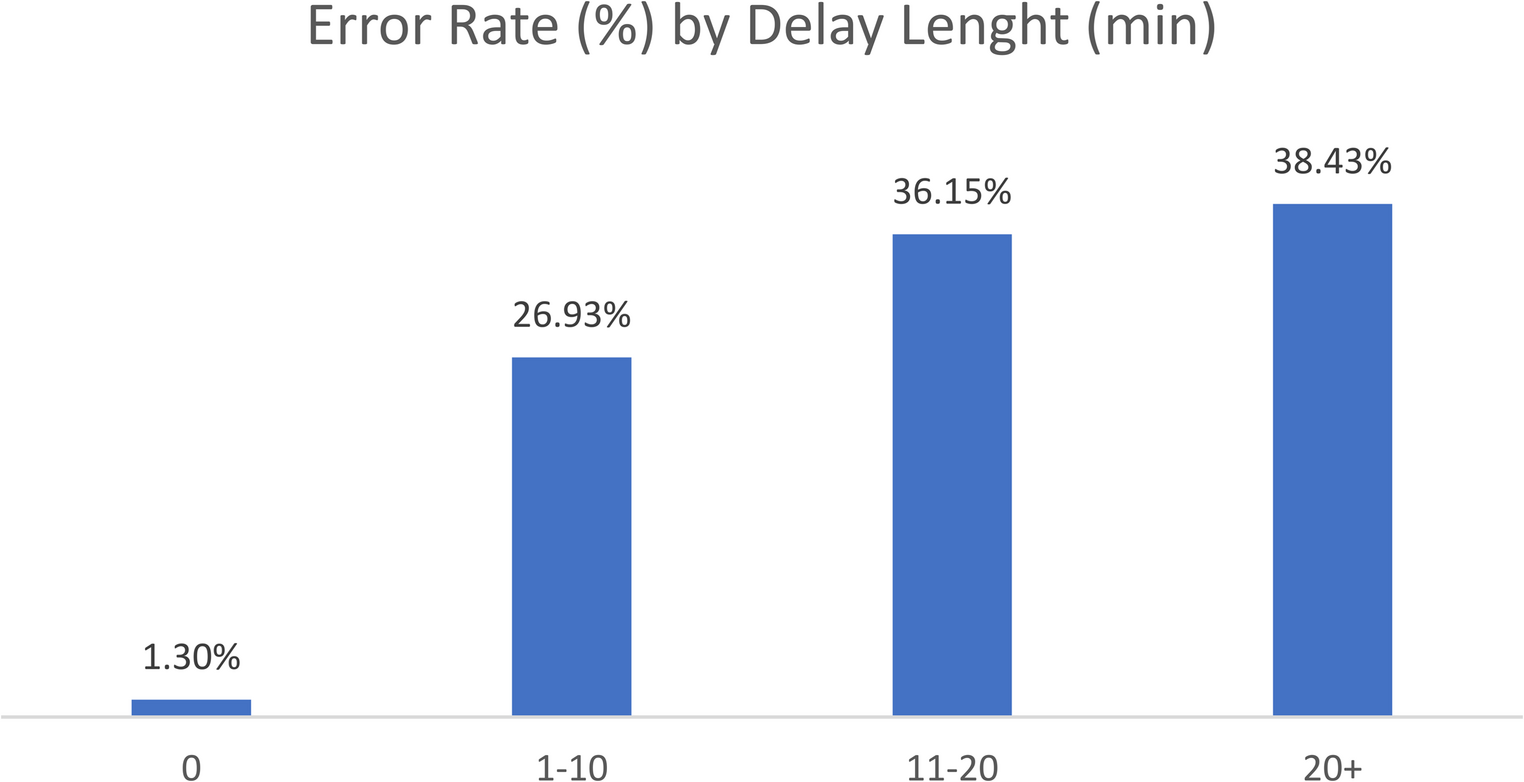
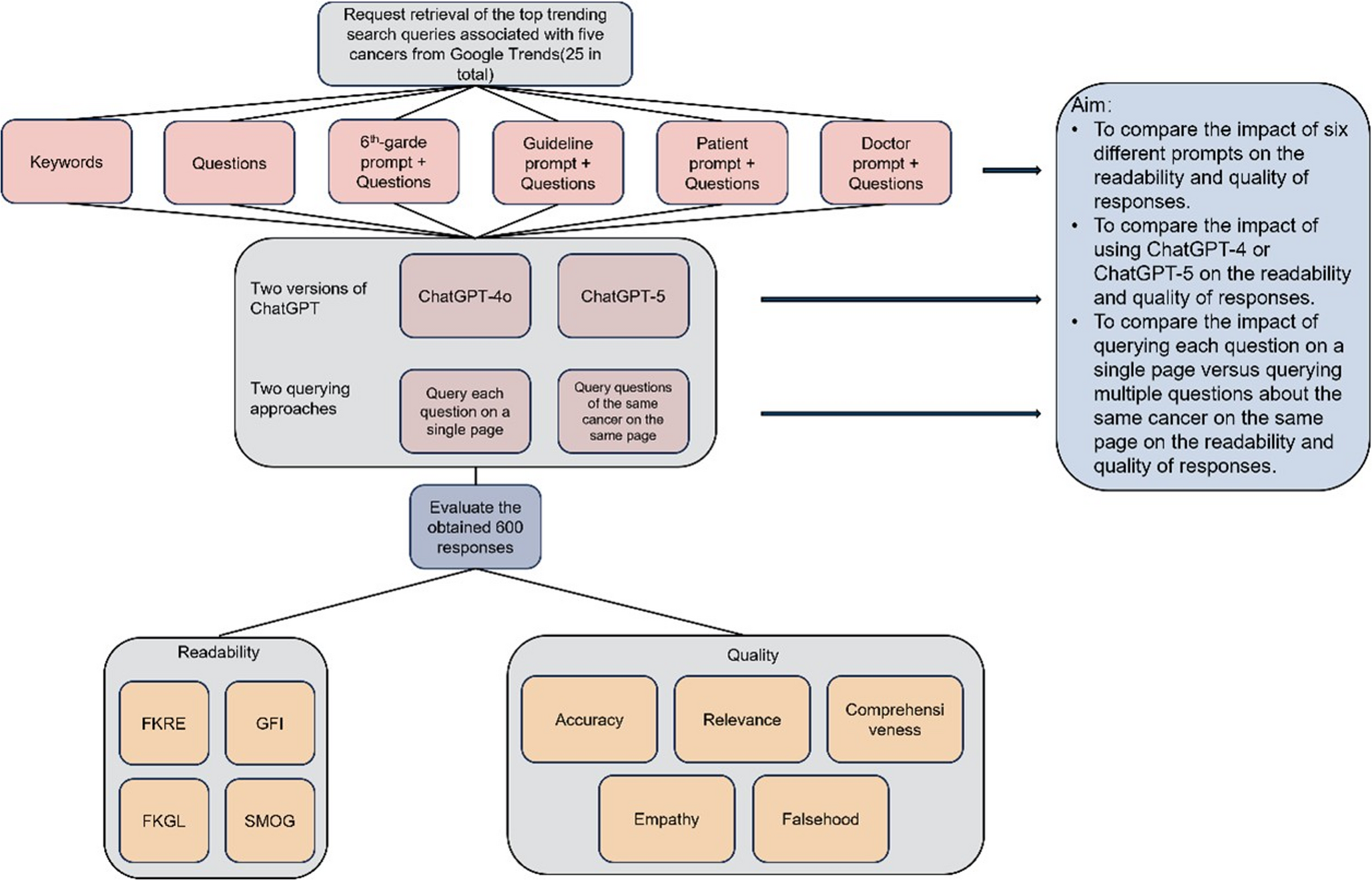
Comments (0)