
Remember me
In the following sections, we first briefly describe the sibling comparisons design, and then outline the traditional models used in sibling analysis: conditional logistic regression for binary outcomes and stratified Cox regression for time-to-event outcomes. We then describe the between-within framework and the marginalization of such models, showcasing how one can reformulate conditional logistic regression and stratified Cox regression using the marginalized between-within framework. This reformulation eases the estimation of a baseline function, which in turn allows for the calculation of absolute risk and other clinically meaningful measures.
Sibling comparisons designSibling comparison designs, and family-based designs more broadly, exploit the fact that relatives tend to be more similar in both measured and unmeasured confounders than unrelated individuals [8]. By comparing siblings within families, these designs adjust for all confounders shared within families, including genetic and stable environmental factors. Under assumptions that there are no unmeasured non-shared confounders, no carry-over effects, no measurement error in the exposure, and other design-specific conditions, the within-family contrast can identify a causal effect of the exposure on the outcome. Generally, the causal effect is defined as the contrast in potential outcomes across exposure levels. The precise causal estimand depends further on whether one assumes that the effect seen in discordant sibling sets generalizes to the total population and the presence of carry-over effects (interference) between siblings [1, 9, 10].
In practice, the assumptions of sibling comparison designs require careful consideration and may not always hold. Consequently, estimates from sibling models are typically interpreted alongside population-wide analyses. Divergence between estimates can suggest shared familial confounding in the population estimates, provided the assumptions of the sibling design are plausible. For example, in analyses of maternal smoking and offspring outcomes, comparing siblings born to the same mother, one pregnancy in which she smokes and one pregnancy in which she does not, accounts for stable maternal and household factors. However, if maternal age influences smoking patterns and child outcomes, it acts as a non-shared confounder and must be actively accounted for because the design itself will not address it.
Details of assumptions, strengths, and limitations of sibling comparison designs have been discussed extensively elsewhere [1, 8]. Here, we focus instead on the statistical procedure to obtain absolute risks.
Traditional models for sibling analysisThe most widely used model for binary outcomes in epidemiology is logistic regression, which, in the context of sibling analysis, is typically implemented as conditional logistic regression:
$$\:P\left(_=1|_,_\right)=\frac\left(_+__+_Z}_\right)}\left(_+__+_Z}_\right)}$$
Here, \(\:P\left(_=1|_,_\right)\) is the probability that individual \(\:j\) in family \(\:i\) experiences the outcome conditional on their exposure \(\:_\) and a non-shared confounder \(\:_\); \(\:_\) is a family-specific intercept which absorbs all shared familial confounding; and \(\:exp\left(_\right)\) represents the conditional odds ratio associated with a one-unit increase in the exposure. Although conditional logistic regression is straightforward to implement in most software (e.g., clogit in Stata), a key limitation is that the cluster-specific intercept \(\:_\) is not estimated directly. This is a direct result of the use of the conditional likelihood wherein the \(\:_\) cancels out, making it difficult to compute absolute risk or derived clinical measures, such as the number needed to treat.
The most widely used survival model in epidemiology is the Cox proportional hazards model [11]. In sibling analyses, this model is typically implemented as a stratified Cox regression:
$$\:_\left(t\right|_,_)\:=_(t)_X}_+_Z}_)$$
where \(\:_(_,}_\text})\:\) is the individual-specific hazard function, and \(\:_\left(t\right)\) is a family-specific baseline hazard, which absorbs unmeasured confounding shared between siblings. The corresponding survival function is given by: \(\:_\left(t\right)=\text\text\text\left(-}_\left(t\right)\right)\), where \(\:}_\left(t\right)=_^_\left(u\right)du\). As with the conditional logistic model, the baseline hazard is not directly estimated when fitting a Cox model. Consequently, only relative effects—such as the hazard ratio \(\:_)\), which reflects the association between exposure and outcome conditional on shared family factors—are typically reported. This lack of a directly estimated baseline complicates the derivation of absolute risk measures, such as survival probabilities or risk differences, which are often of greater clinical relevance than the hazard ratio.
The between-within frameworkUnlike conditional logistic regression and stratified Cox regression, the between-within framework explicitly decomposes the total exposure–outcome association into a within-family (causal) effect and a between-family (shared confounding) effect. It can be viewed as a generalized linear mixed model with a random intercept and additional family-mean terms for each exposure/covariate. Importantly, these additional terms allow the model to accommodate correlation between family-level effects and covariates and thereby recover the within-family estimate, analogous to a fixed-effects model, while also estimating the between-family component. The conditional between-within model can be expressed as:
$$\:g\left[E(_\right|_,_,}_,}_\left)\right]=_+_X}_+_}_+_Z}_+_}_$$
Here, \(\:}_\) and \(\:}_\) denote the family means of the exposure and non-shared confounders, respectively. The family-specific intercept \(\:_\) is assumed to follow a normal distribution with constant mean µ and variance σ2. The function \(\:g(\cdot\:)\) represents a link function appropriate to the outcome (e.g., logit). Because the framework is generalizable to various outcome types, we express the inferential target as the expectation of \(\:Y\). Under this model, \(\:_\) captures the within-family effect of the exposure—the estimate of the causal effect of a 1-unit increase in the exposure on the outcome, controlling for observed non-shared confounders (\(\:Z\)) and all family-shared factors. This is often referred to as the within-effect. In contrast, \(\:_}_\) and \(\:_}}_\) absorb the family-level confounding, which is sometimes referred to as the between-effect(s). The coefficients of the between-components are difficult to interpret directly, as they generally do not correspond to well-defined causal effects but instead serve to account for between-family differences. Nevertheless, estimating the random intercept \(\:_\) (sometimes referred to as shared frailty) can be computationally intensive and may result in unstable estimates [1, 3]. As a practical alternative, one can instead use the marginal between-within model, [12] specified as:
$$\:g\left[E(_\right|_,_,}_,}_\left)\right]=\alpha\:+_X}_+_}_+_Z}_+_}_$$
In this specification, \(\:\alpha\:\) is a fixed intercept common to all families. The marginal between-within model can be viewed as an approximation to the conditional version, [3] although they are not strictly the same. One important difference between them is that the marginal between-within model also circumvents the assumption of no effect measure modification by family-shared confounders [12]. That is, unlike conditional fixed-effects approaches and the conditional between-within model, which assume that the exposure effect does not vary across levels of family-shared confounders, the marginal between–within model marginalizes over such factors and therefore does not require this assumption [12]. This property allows the marginal model to remain valid even in the presence of effect-measure modification by the family-shared confounders. However, the marginal between-within model will be similar to the conditional between-within model if the variance in \(\:_\) is small and there is no effect-modification by family-shared confounders [3, 12].
Marginal between-within logistic regressionInstead of using conditional logistic regression for binary sibling analysis, one can specify a marginal between-within logistic model as:
$$\:P\left(_=1|_,\:}_,_,\:}_\right)=\frac\left(\alpha\:+_X}_+_}_+_Z}_+_}_\right)}\left(\alpha\:+_X}_+_}_+_Z}_+_}_\right)}$$
Here, \(\:\alpha\:\:\)is a fixed intercept common to all families. The coefficients \(\:_\) and \(\:_\) capture within-family effects, while \(\:_\) and \(\:_\) account for between-family effects. Although the method is referred to as the marginal between-within approach, the term “marginal” here refers to the marginalization over families, and thus also over the unmeasured family-constant confounders. The model remains conditional on the measured confounders \(\:Z\). If one wants to further marginalize over the measured confounders, then this can be done with regression standardization [13]. A practical advantage of this approach lies in its implementation: by including both within- and between-family terms, a standard logistic regression model becomes a sibling model. Furthermore, the use of a global intercept reduces the computational complexity greatly and eases the estimation of clinically relevant absolute measures. For example, from this model it is possible to estimate the outcome risk under hypothetical scenarios—such as if all individuals were exposed versus if all were unexposed—while adjusting for both observed non-shared confounders and unmeasured shared familial factors (i.e., via standardization or the parametric g-formula with control for shared familial confounding). Assuming no other confounding beyond these factors, the contrast between the standardized risks represents the average treatment effect. Moreover, one can estimate the population attributable fraction (i.e., the proportion of cases in the population attributable to the exposure) and the number needed to harm (i.e., the number of ‘treatments’ required to cause one additional outcome in the population as a whole), all while accounting for shared family-level confounders (Online Appendix). Of course, these are only some of the large numbers of possible absolute clinical measures one could calculate given that a baseline risk has been estimated (e.g., the average treatment effect among the factually treated, number needed to treat among the factually untreated, the attributable fraction among the factually treated, etc.) [14].
Marginal between-within Cox regressionThe main strength of stratified Cox regression is that it does not require direct estimation of the baseline hazard. However, this also becomes a limitation when one is interested in absolute risks or survival probabilities, as the baseline hazard is necessary to compute such measures. One alternative is to introduce a cluster-specific frailty term and assume a parametric form for the baseline hazard (as Dahlqwist et al. [4] do for the conditional between-within model). However, this approach can be computationally intensive and potentially unstable. Instead, we can define a marginal between-within Cox model:
$$\:\lambda \:_} \left( } ,Z_} ,\mathop }\limits^ ,\mathop }\limits^ } \right) = \lambda \:_ \left( t \right)\exp \left( X_} + \theta \:_ \mathop X\limits^ _ + \beta \:_ Z_} + \theta \:_ \mathop Z\limits^ _ } \right)$$
Here, \(\:_\left(t\right)\) is a shared baseline hazard across all families. The coefficients \(\:_\) and \(\:_\) represent within-family effects, while \(\:_\) and \(\:_\) capture between-family effects (note: as with the logistic regression, these are conditional log(hazard ratios) even if the model is referred to as “marginal”). Rather than estimating a separate frailty term per family [4], we can use Breslow’s estimator [13] to derive a cumulative baseline hazard function: \(\:}_\left(t\right)=_^_\left(u\right)\textu\). Alternatively, one may flexibly model \(\:_\left(t\right)\) or \(\:}_\left(t\right)\) using restricted cubic splines (see Online Appendix).
Regardless of how we go about estimating the baseline common to all families, the advantages of the marginal between-within Cox model compared to the stratified Cox regression become especially clear when estimating clinically relevant measures. With a common baseline hazard estimated across all families, we can standardize survival functions to compare counterfactual risks through time — e.g., estimating the cumulative incidence of the outcome at time \(\:t\) under a scenario where everyone is exposed compared to a scenario where no one is exposed, adjusting for both observed non-shared and shared familial confounding (i.e., G-computation based on a sibling model). The contrast between these corresponds to the average treatment effect by time\(\:\:t\), assuming no other confounders. In addition, access to the baseline hazard enables estimation of policy-relevant quantities such as the population attributable fraction and number needed to treat or harm, either at specific time points (e.g., 10 years post baseline) or over the entire follow-up period (see Online Appendix).
Applied example: maternal smoking and infant mortalityTo illustrate the utility of the marginal between-within framework, we examined the association between maternal smoking during pregnancy and infant mortality. Although the harms of maternal smoking are well established, confounding shared between siblings—such as maternal health and socioeconomic status—may influence both smoking behaviors and infant mortality risk. Sibling analysis offers a way to adjust for these shared familial confounders. Because non-twin siblings differ in maternal age, and because maternal age may affect both smoking behavior and infant outcomes, we additionally adjust for maternal age as a non-shared confounder. For pedagogical purposes, we analyzed this example using both binary and time-to-event outcome models. Specifically, we applied the marginal between-within analogs of logistic regression and Cox regression, which allow us to estimate both relative and absolute measures of association. These included the odds ratio, hazard ratio, absolute risk difference, attributable fraction, and number needed to treat. For comparison, we also fit the conventional sibling models—conditional logistic regression and stratified Cox regression—albeit these only estimate relative measures (i.e., odds and hazard ratios). To account for within-family correlation, we used cluster-robust standard errors. We estimated standard errors for absolute measures using the delta method.
We identified all live-born children in the Swedish Medical Birth Register between 1980 and 2020 with maternal smoking status recorded at the first antenatal visit (self-reported). From this cohort, we selected 2,818,660 children who had at least one full sibling born during the same period, yielding a total of 1,214,946 families. These individuals were linked to the Swedish Cause of Death Register to ascertain any recorded death. Follow-up was defined as the period from birth until one year of age, death, or December 31, 2021, whichever came first. Between 1980 and 2020, we observed 9,565 infant deaths (0.34%). Of the 2,818,660 children, 3,225 were exposure and outcome discordant.
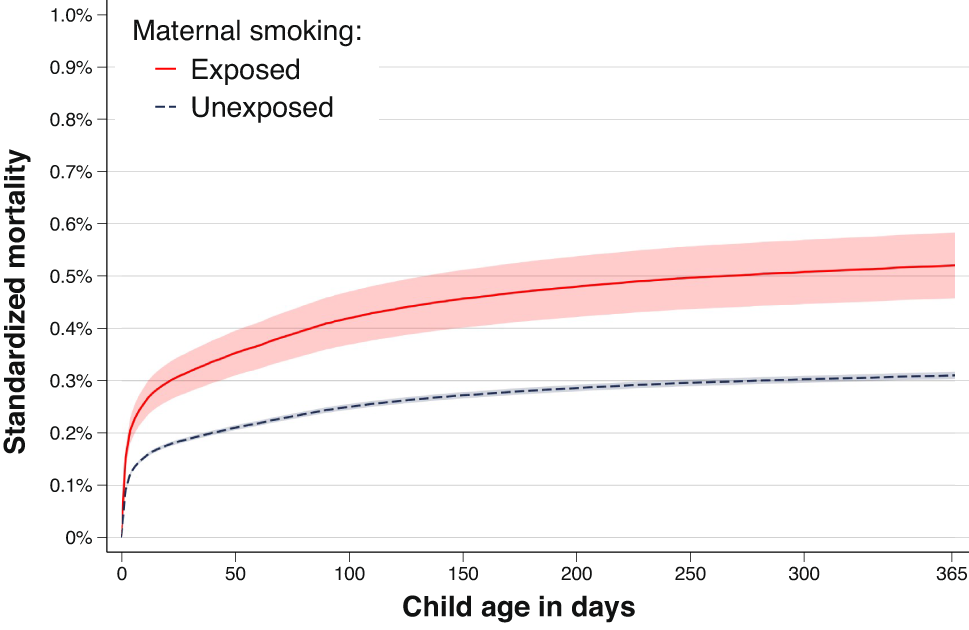
Example of result description based on time-to-event analysisThe odds ratios and hazard ratios were similar between the conventional sibling models and the marginal between-within models (Table 1). When using the marginal between-within Cox regression, which adjusts for all unmeasured factors shared between siblings and the observed non-shared covariate of maternal age, we found that maternal smoking during pregnancy was associated with an increased rate of infant mortality. The estimated hazard ratio was 1.68 (95% CI: 1.46–1.93) (Table 1). In terms of absolute risk, we observed a mortality difference of 0.21% points (95% CI: 0.14–0.28) by day 365 of follow-up (Fig. 1; Table 1). This corresponds to an attributable fraction of 8.62% (95% CI: 6.68–10.56), and a number needed to harm of 476 (95% CI: 320–632).
However, it should be noted that a causal interpretation rests on the assumption—common to all sibling designs—that non-shared confounders are adequately controlled. This assumption is unlikely to be true, considering we have not accounted for any non-shared confounders except maternal age. Furthermore, in this illustrative example, the binary/cross-sectional and hazard/time-to-event analyses produce nearly identical estimates; however, this concordance should not be expected in other settings, particularly when follow-up is longer or censoring is more complex. The choice of modelling strategy should be driven by the specific research question and the nature of the outcome. The code to perform the analyses, including estimation of both relative and absolute effects, is provided in the Online Appendix.
Table 1 Association between maternal smoking and infant mortalitya estimated using conventional (conditional logistic and stratified Cox) and marginal between-withinb (Cox and logistic) sibling-analysisFig. 1
The standardized child mortality across child age according to exposure to maternal smoking, as obtained from the marginal between-within Cox analysis, controlling for all sibling shared factors and observed maternal age. Shaded area represents 95% confidence intervals
Comments (0)