In recent years, the field of personalized oncology has seen significant advancements, opening new opportunities for patients who previously had limited options [1]. Advances in sequencing technologies, along with progress in bioinformatics, cancer immunology, and molecular biology, have significantly reduced the time and cost associated with targeted therapies, which is especially relevant given the traditionally labor-intensive process of collecting detailed family histories in clinical practice [2]. Currently, the cost of long-read sequencing technologies (e.g., PacBio, 10X Genomics) is declining, offering improved insights into the structure and order of genomic rearrangements, features often missed by next-generation sequencing (NGS). Broader clinical adoption of these technologies could enhance diagnostic yield for genetic diseases. Continued progress toward pan-ethnic reference genomes, large-scale public variant databases [3], and richer clinical genetic repositories [4, 5] will help overcome remaining technical barriers. Moreover, early sequencing of many cancers, as recommended by guidelines, enables earlier targeted treatment and improved care. As an example, NGS accelerates diagnosis by analyzing multiple genes simultaneously in a single assay. Thus, costs for sequencing technologies have been falling over the last decades and consequently, therapies are no longer exclusive to a small subset of patients but are accessible to a broader patient base [6].
The now possible process of interpreting genetic variants, assessing druggability, and evaluating patient status is inherently complex and time-consuming. It necessitates the expertise of a multidisciplinary team, including, among others, oncologists, pathologists, and bioinformaticians [7]. The multidisciplinary molecular tumor board (MTB) process, therefore, involves multiple steps, diverse expertise, and various data types from different departments at different time points [8]. Identifying personalized treatment options based on solid evidence remains challenging given the rarity of identical genomic alterations and clinical conditions among patients.
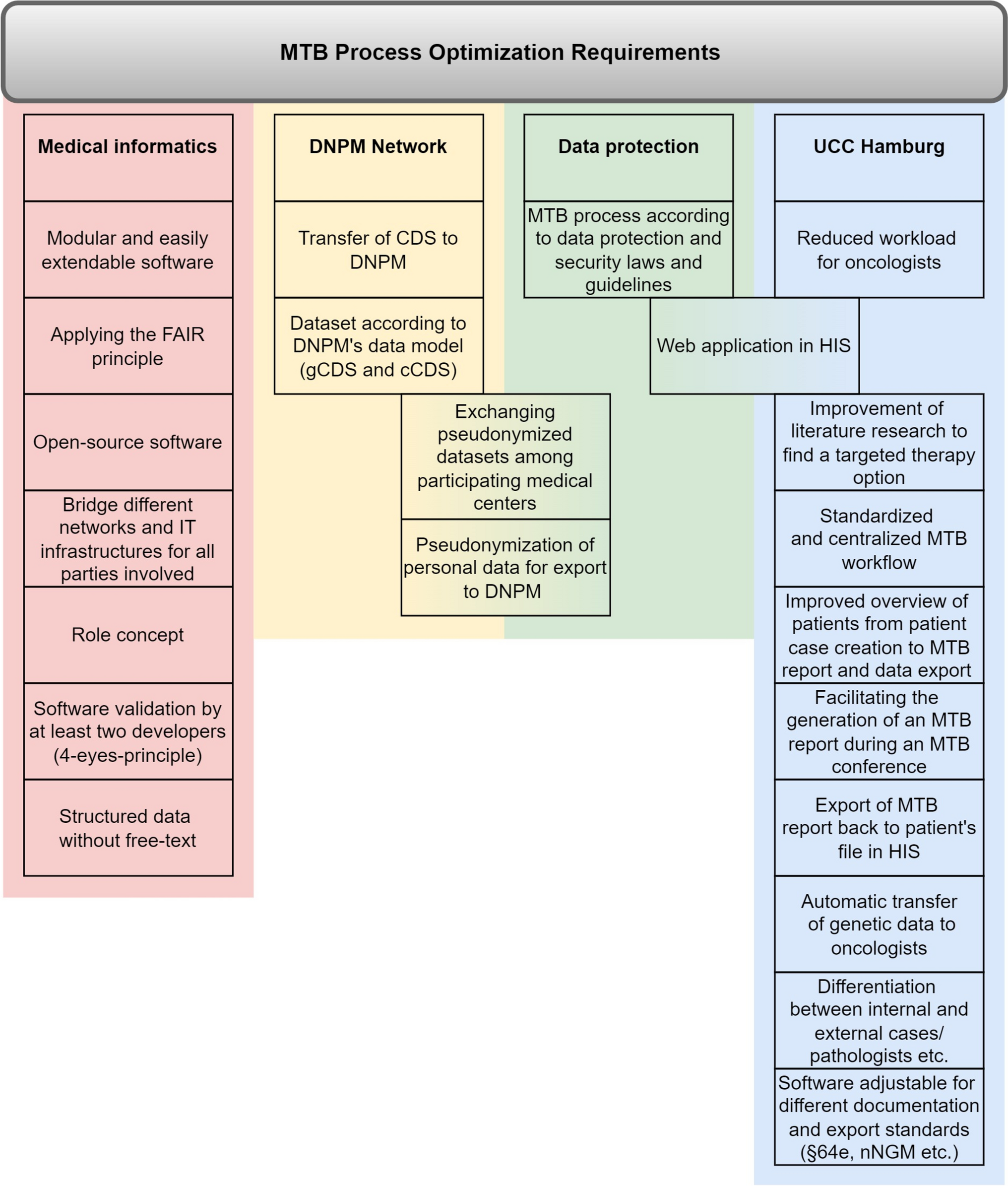
The complexity of MTBs extends beyond individual institutions and reflects broader challenges at the European level. The EU’s flagship initiative, 1+ Million Genomes (1+MG), exemplifies this by aiming to enable secure, cross-border access to genomic and clinical data across Europe. This initiative supports cutting-edge research, evidence-based health policy, and the development of personalized treatments, with the overarching goal of improving disease prevention and patient outcomes. As one of the world’s largest genomics projects, 1+MG is instrumental in establishing global standards in precision medicine [9]. At the national level, Germany is actively contributing to this landscape through initiatives such as the Modellvorhaben after §64e SGB V [10], aiming to make molecular diagnostics and treatment billable by health insurance companies, and the German Network for Personalized Medicine (Deutsches Netzwerk für Personalisierte Medizin, DNPM). The DNPM, comprising 28 university medical centers, seeks to enhance the diagnosis and treatment of complex or rare cancers and improve patients’ access to personalized medicine. These national efforts are closely aligned with European goals and help translate large-scale genomic initiatives into improved clinical practice and patient care. The DNPM collaborates with European networks such as Genomic Medicine Sweden (GMS) and ICPerMed to share data and conduct cross-border research and clinical trials. These efforts align with the European Health Data Space (EHDS) initiative, which promotes the exchange of medical data across Europe [11].
To tackle key challenges in personalized medicine—particularly dealing with small, non-standardized datasets—the DNPM aims to expand collective knowledge. This includes collaboration with international cancer centers and the integration of the following steps:
1.
Establishment of a standardized clinical and genetic core dataset (cCDS and gCDS, respectively) to be used by all participating university medical centers in Germany that conduct MTBs [12].
2.
Combination of the pseudonymized datasets from all participating medical centers into a single node to facilitate collaborative research and registry efforts [13].
Participation in the DNPM network will enable access to pseudonymized patient data across multiple medical centers, significantly expanding the available patient cohort for research. Since MTB data from other medical centers adhere to the same standardized core data structure, with minimal use of free-text fields, the quality and quantity of data available for retrospective research will be greatly enhanced compared with previous MTB datasets.
While the benefits of participating in DNPM are clear, the integration of patient data from diverse clinical domains, such as genomic and clinical data, presents several challenges:
1.
Disparate internal clinical IT structures and varying data collection and documentation systems make it more difficult to collect and standardize the data at one central point.
2.
A cascading process to obtain genomic data, including several internal and external institutions at a medical center [14].
3.
Iterative procedures from patient admission to MTB, involving multiple potential clinical pathways [15].
4.
Organizational and data protection challenges that are especially complex within the German law context.
Although software solutions for structured MTB documentation, such as Onkostar [16], are available, they are not suitable for our university medical center owing to infrastructure mismatches. In particular, the pathology and oncology departments operate independently, each using distinct data structures and software systems. In addition, Onkostar is a proprietary solution, while our center advocates for flexible open-source options to support a sustainable research environment.
In addition to the complex data collection and integration process for MTB, which includes many different institutions and previously used data collection systems, finding suitable treatment options can be challenging. Conducting literature research for such multifaceted problems with limited patient data is extensive and time-consuming. To streamline this process, our collaboration partner, the German Cancer Research Center (Deutsches Krebsforschungszentrum, DKFZ), and the National Center for Tumor Diseases Heidelberg (NCT) [17] has developed the Knowledge Connector (KC) [18,19,20], a tool designed to expedite literature research by integrating genetic knowledge with patient data and relevant literature based on genetic alterations. This tool aims to significantly reduce the time required for literature research, which is a major bottleneck in providing personalized treatment options to more patients [21]. In contrast to cBioPortal [22, 23], which is mainly used to explore patient-unspecific genomic profiles, the KC tailors its genomic information to the given patient-specific molecular data [20].
To solve the above-mentioned pressing issues, this paper presents our own open-source web application, Molecular ONcology Optimized CLinical Evaluation (MONOCLE), developed at the University Medical Center Hamburg-Eppendorf (UKE), Germany, in the Institute for Applied Medical Informatics (IAM). MONOCLE, in conjunction with the KC, enhances the workflow and documentation of MTBs, enabling high-quality treatment for more patients. We detail MONOCLE’s structure and software components and evaluate its performance through dedicated user tasks and an updated version of the system usability scale (SUS) [24].


Comments (0)