
Remember me
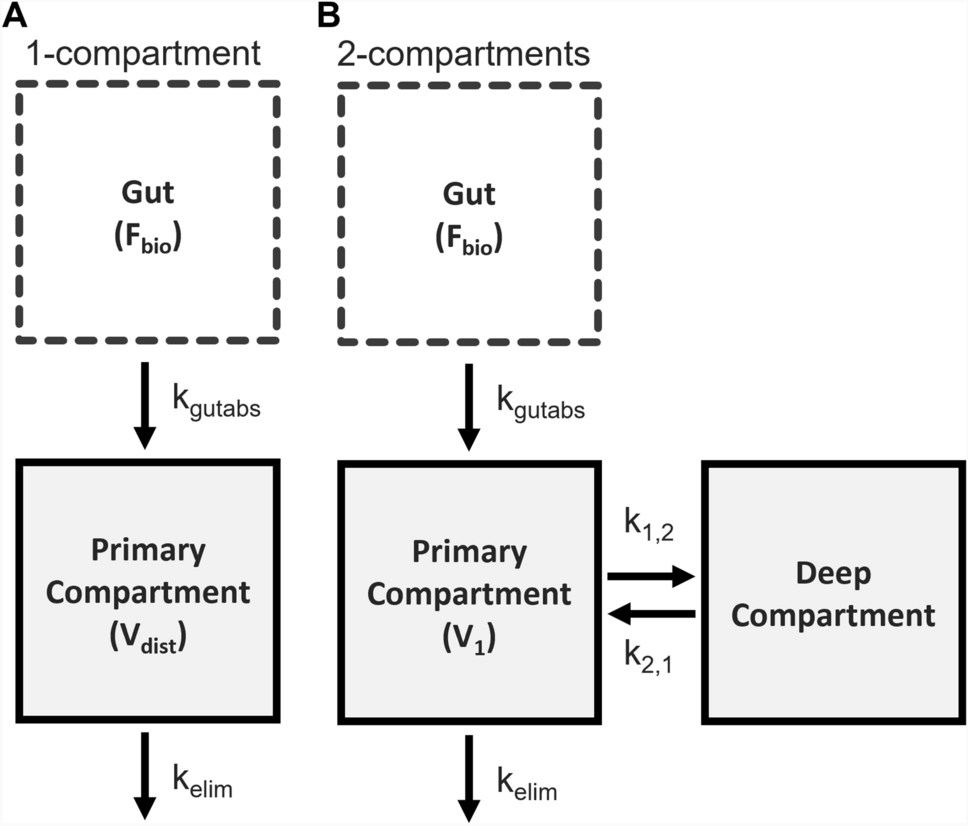
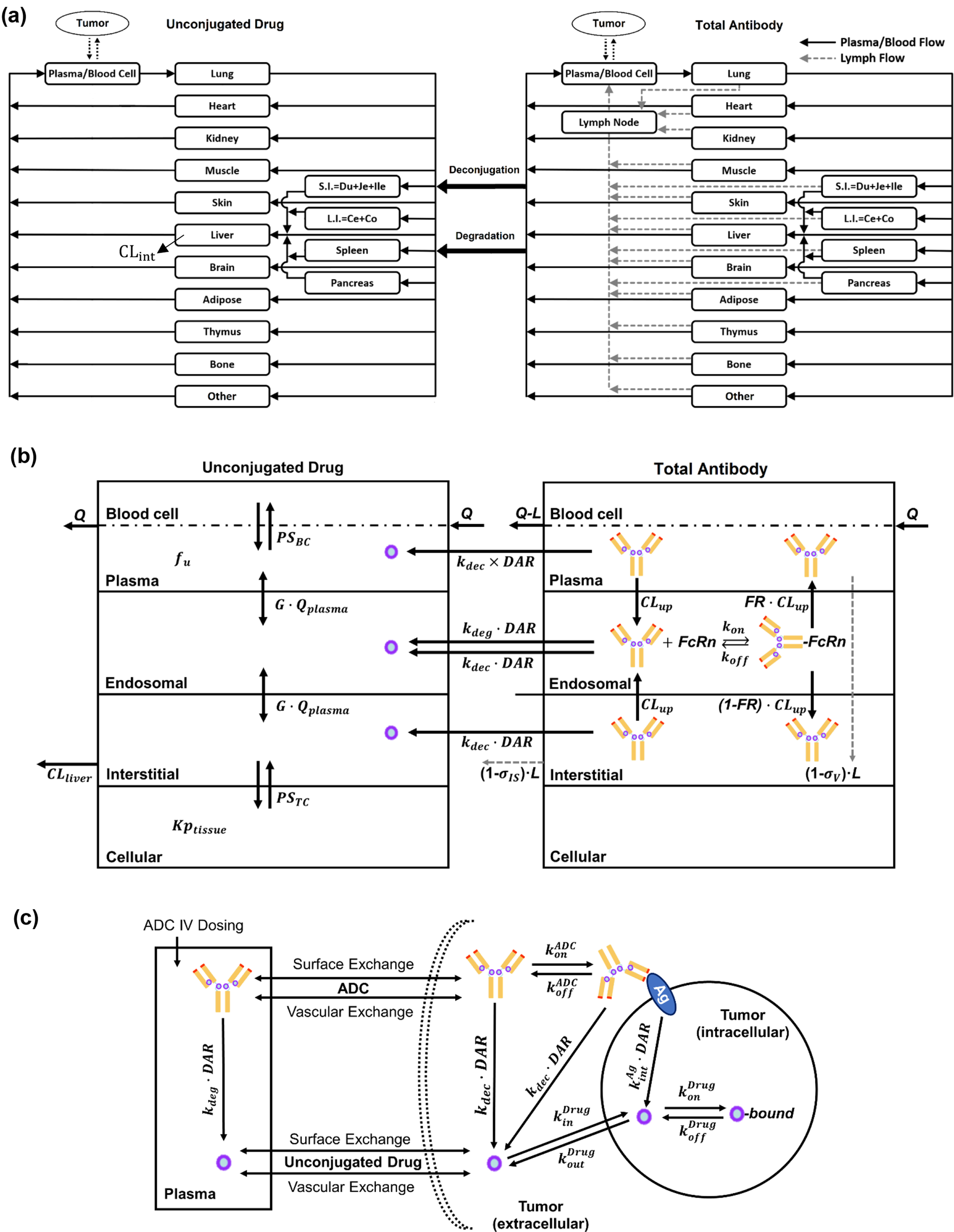
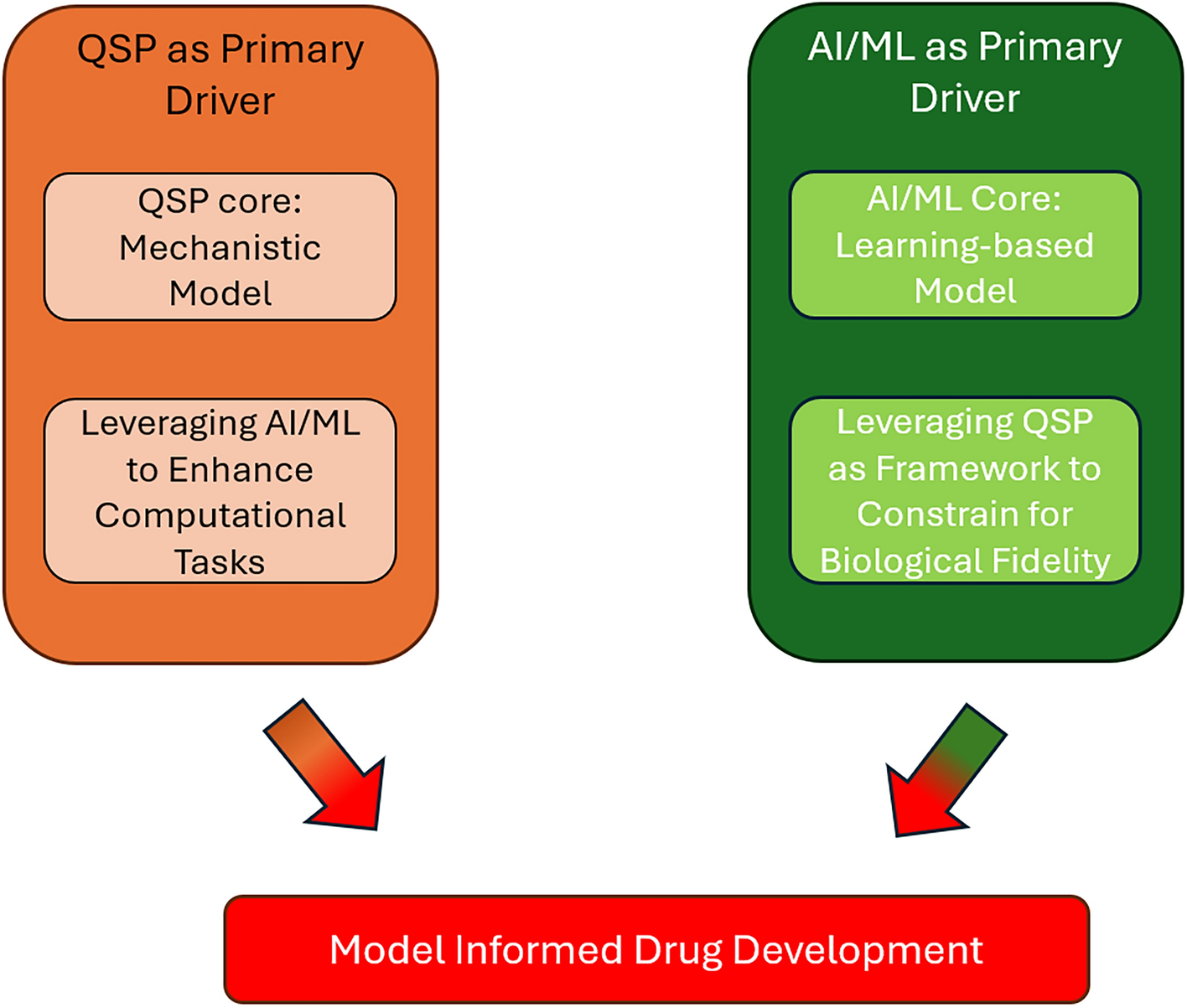
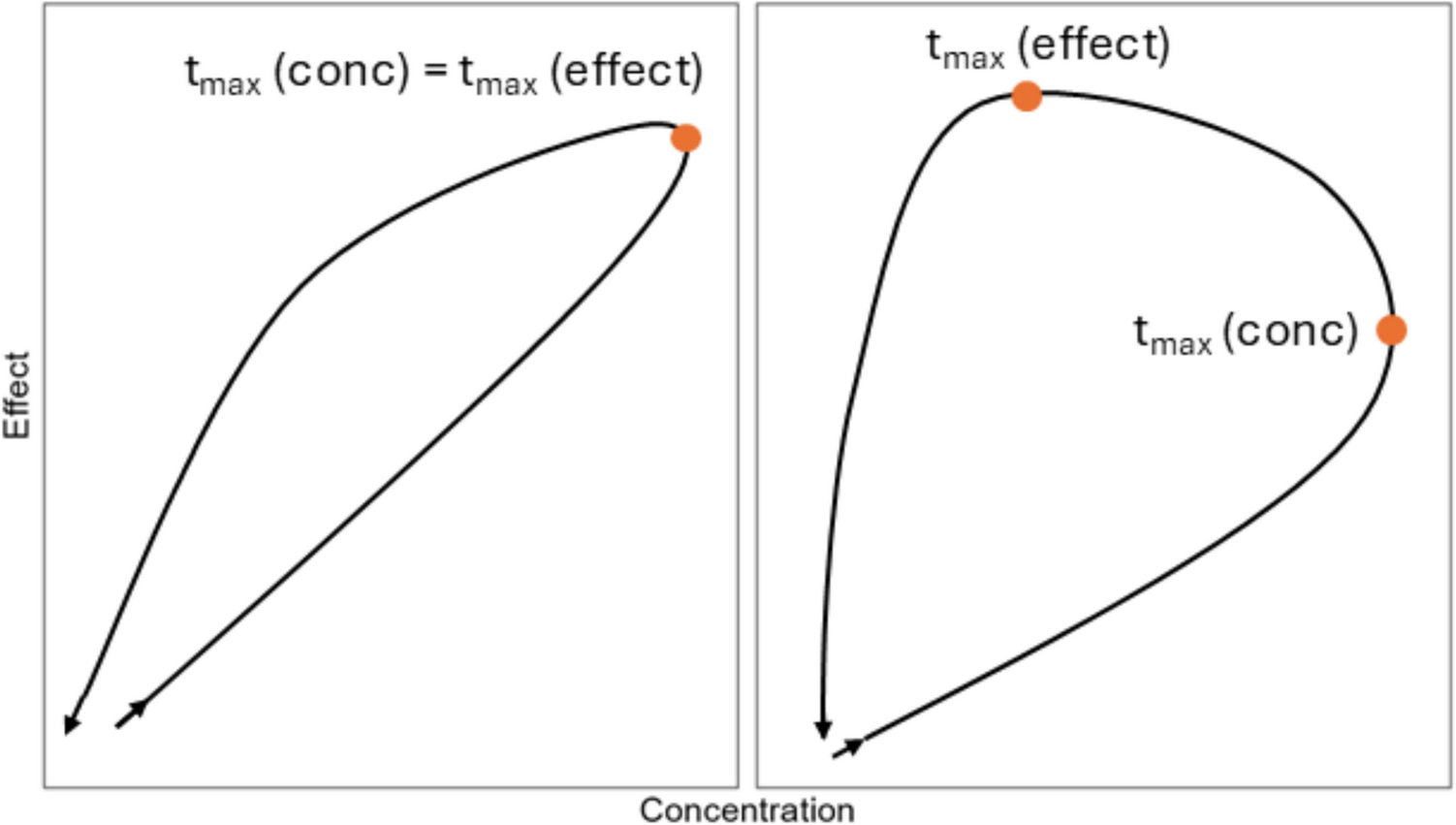

Due to the non-linearity of the structural model f with respect to \(\theta \), there is no analytical expression for \(l(y_i; \Psi , z_i, \xi _i)\). The expression for \(M_(\xi _i, \Psi , z_i)\) are usually developed using a first-order Taylor expansion of the structural model around \(\phi _ = h(\mu _0, \beta _0, z_i)\), a guess value of the fixed effects associated with covariates \(z_i\), and a zero-order expansion of g [8] as given in Eq. A1, where \(\textbf_\theta f\) and \(\textbf_\phi h^\) respectively denote the Jacobian matrix of f and \(h^\).
$$\begin \begin y_i&\approx f(\xi _, h^(\phi _)) \\&\quad + \textbf_\theta f \left( \xi _, h^(\phi _)\right) \textbf_\phi h^(\phi _) (h(\mu , \beta , z_i) - \phi _) \\&\quad + \textbf_\theta f \left( \xi _, h^(\phi _)\right) \textbf_\phi h^(\phi _) \eta _i \\&\quad + diag\Big (g(\xi _, h^(\phi _), \sigma )\Big ) \varepsilon _i \end \end$$
(A1)
Observations are thus approximated to normal variables, with mean \(E_i\left( \xi _, \phi _, \nu , z_i\right) \) and variance-covariance matrix \(V_i\left( \xi _, \phi _, \Omega , \sigma \right) \) given in Eq. A2.
$$\begin \begin&E_i\left( \xi _, \phi _, \nu , z_i\right) = f(\xi _, h^(\phi _)) \\&+ \textbf_\theta f \left( \xi _, h^(\phi _)\right) \textbf_\phi h^(\phi _) (h(\mu , \beta , z_i) - \phi _) \\&V_i\left( \xi _, \phi _, \Omega , \sigma \right) = \big ( \textbf_\theta f \left( \xi _, h^(\phi _)\right) \\&\times \textbf_\phi h^(\phi _) \big )^T \Omega \big ( \textbf_\theta f \left( \xi _, h^(\phi _)\right) \textbf_\phi h^(\phi _) \big ) \\&+ diag\Big (g(\xi _, h^(\phi _), \sigma )\Big ) ^2 \end \end$$
(A2)
From this, the FIM is calculated as the FIM of the Gaussian vector obtained by approximation (see for example [18]).
A.2: Power computation for significance testThe null hypothesis for the Wald test of comparison is \(H_0: \beta = 0\) and the alternative hypothesis is \(H_1: \beta \ne 0\). The test statistics is given by Eq. A3.
$$\begin W = \dfrac})} \sim \mathcal \left( \dfrac} , 1 \right) \end$$
(A3)
Under \(H_0\), \(W \sim \mathcal \left( 0, 1 \right) \), therefore \(H_0\) is rejected if \(\vert W \vert \ge q_\), where \(q_\) denotes the \(1-\alpha /2\)-quantile of the normal distribution
Under \(H_1\), \(\beta \ne 0\), \(W \sim \mathcal \left( \dfrac}, 1 \right) \).
The power is computed for a given \(\beta \) as the probability to reject \(H_0\) under \(\beta \in H_1\):
$$\begin P_&= \mathbb _\left( \vert W \vert \ge q_ \right) = \mathbb _\left( W \ge q_ \right) \nonumber \\&\quad + \mathbb _\left( W \le - q_ \right) \nonumber \\&= \mathbb \left( X + \dfrac} \ge q_ \right) + \mathbb \left( X + \dfrac}\le - q_ \right) \nonumber \\&\quad \text X \sim \mathcal \left( 0, 1 \right) \nonumber \\&= \mathbb \left( X \ge q_ - \dfrac} \right) + \mathbb \left( X \le - q_ - \dfrac} \right) \nonumber \\&\boxed - \dfrac}) + \Phi ( - q_ - \dfrac}) } \end$$
(A4)
\(\beta > 0\): Because \(\mathbb \left( X \le - q_ \right) = \alpha /2\) and \(\dfrac} > 0\), we have that \(\mathbb _\left( W \le - q_ \right) < \alpha /2\) Therefore, the second term can be neglected and
$$\begin \begin P_&\approx \mathbb _\left( W \ge q_ \right) \\&\approx 1 - \Phi ( q_ - \dfrac}) \end \end$$
(A5)
\(\beta < 0\): On the contrary,
$$\begin \begin P_&\approx \mathbb _\left( W \le - q_ \right) \\&\approx \Phi ( - q_ - \dfrac}) \end \end$$
(A6)
A.3: Power computation for relevance testThe null hypothesis is \(H_0\): ”the covariate effect is not relevant”, i.e. \(r_ \in [R_\; R_]\) while the alternative hypothesis is \(H_1\): ”the covariate is relevant”, i.e. \(r_ \notin [R_\; R_]\). This two-sided null hypothesis can be split into two, respectively \(H_\) and \(H_\) :
$$\begin & \!\! H_ : r_ \ge R_ \quad \text \quad H_ : r_ \le R_\\ & \!\! H_ : r_ < R_ \quad \text \quad r_ > R_ \end\right. } \end$$
Thus \(H_0\) is not rejected unless neither \(H_\) nor \(H_\) is rejected.
For \(r_ = e^ \ \left( z - z_ \right) }\),the hypothesis write: \(H_0: \beta _ \in [B_; B_]\), where depending on the sign of \(\left( z - z_ \right) \), \(B_\) and \(B_\) equals \(\frac}}\) or \( \frac}}\).
The null hypothesis is rejected if \(H_\) is rejected, i.e. \( \widehat} -B_ < s_1 \), or if \(H_\) is rejected, i.e. \(\widehat} - B_ > s_2 \); where \(s_1\) and \(s_2\) are chosen to reach an \(\alpha \) type one error. Because these two events are incompatible the following holds:
$$\begin & \max _ \mathbb \left( \widehat} -B_ < s_1 \right) = \alpha \\ & \max _ \mathbb \left( \widehat} - B_ > s_2 \right) = \alpha \\ \end\right. } \end$$
(A7)
Recalling that \(\frac} - \beta _}}} \sim \mathcal \left( 0, 1 \right) \), the system writes:
$$\begin & \max _ \mathbb \left( \beta _ -B_ < s_1 \right) = \max _ \Phi \left( \dfrac - \beta _}}}\right) = \alpha \\ & \max _ \mathbb \left( \beta _ - B_ > s_2 \right) = \max _ 1 -\Phi \left( \dfrac - \beta _}}}\right) = \alpha \\ \end\right. } \implies & s_1 = q_ SE_} = - q_ SE_} \\ & s_2 = q_ SE_} \end\right. } \end$$
(A8)
Finally, at level \(1-\alpha \), the null hypothesis is rejected if \( \widehat} -B_ < - q_ SE_} \) or if \(\widehat} - B_ > q_ SE_} \); equivalently, the null hypothesis is rejected if \( \widehat} + q_ SE_} < B_ \) or if \(\widehat} - q_ SE_} > B_ \). The first inequality involves the upper bound of the \(1-2\alpha \) CI on the ratio, while the second inequality involves the lower bound.
The power is the probability under \(H_1\) to reject \(H_0\):
$$\begin P_ = \Phi \left( - q_ + \dfrac - \beta _}}}\right) + 1 -\Phi \left( q_ + \dfrac - \beta _}}}\right) \end$$
(A9)
On one hand, if \( B_< \beta _, \Phi \left( - q_ + \dfrac - \beta _}}}\right) < \Phi \left( - q_ \right) = \alpha \), therefore this term is negligible in power computation. On the other hand, if \(B_ > \beta _, 1 -\Phi \left( q_ + \dfrac - \beta _}}}\right) < 1 -\Phi \left( q_ \right) = \alpha \), therefore this term is negligible in power computation. Consequently, to compute the number of subjects needed to achieve, a given power let us distinguish two cases:
If \( B_ < \beta _: P_ \approx 1 -\Phi \left( q_ + \dfrac - \beta _}}}\right) \) \(\implies SE_} = \dfrac - \beta _}\left( 1 - P_ \right) - q_ } \)
If \(B_ > \beta _: P_ \approx \Phi \left( - q_ + \dfrac - \beta _}}}\right) \) \(\implies SE_} = \dfrac - \beta _}\left( P_ \right) + q_ }\)
Appendix B: Addition details on the evaluation by simulationFig. 4
Evaluation - Covariate distributions for Male on the left and Female on the right: Data boxplots, fitted Copulas boxplots and fitted independent Gaussian densities
Fig. 5
Evaluation - Boxplots of Relative Estimation Error across 200 datasets for the 6 scenarios. The boxplot displays the median, the 25th and 75th percentiles, while the whiskers are 5th and 95th percentiles. The red diamond corresponds to the mean
Fig. 6
Evaluation - Normalized and Relative Standard Error for the 6 scenarios: FIM predictions using the three methods for handling covariates and simulation results across 200 datasets. The boxplot displays the median, the 25th and 75th percentiles, while the whiskers are 5th and 95th percentiles
Appendix C: Addition details on PK example simulationTable 8 Application - Theoretical Sampling DesignFig. 7
Application - Boxplots of Relative Estimation Error across 200 datasets - Base parameters. The boxplot displays the median, the 25th and 75th percentiles, while the whiskers are 5th and 95th percentiles. The red diamond corresponds to the mean
Fig. 8
Application - Boxplots of Relative Estimation Error across 200 datasets - Covariate effects parameters. The boxplot displays the median, the 25th and 75th percentiles, while the whiskers are 5th and 95th percentiles. The red diamond corresponds to the mean
Table 9 Application - RB and RRMSE across 200 datasets - Base parametersTable 10 Application - Simulation Value, Estimate, RB and RRMSE across 200 datasets - Covariate effects parametersFig. 9
Application - Normalized and Relative Standard Error - Base parameters: FIM predictions using the Data method for handling covariates and simulation results across 200 datasets. The boxplot displays the median, the 25th and 75th percentiles, while the whiskers are 5th and 95th percentiles
Fig. 10
Application - Normalized and Relative Standard Error - Covariate effects: FIM predictions using the Data method for handling covariates and simulation results across 200 datasets. The boxplot displays the median, the 25th and 75th percentiles, while the whiskers are 5th and 95th percentiles
Comments (0)