
Remember me
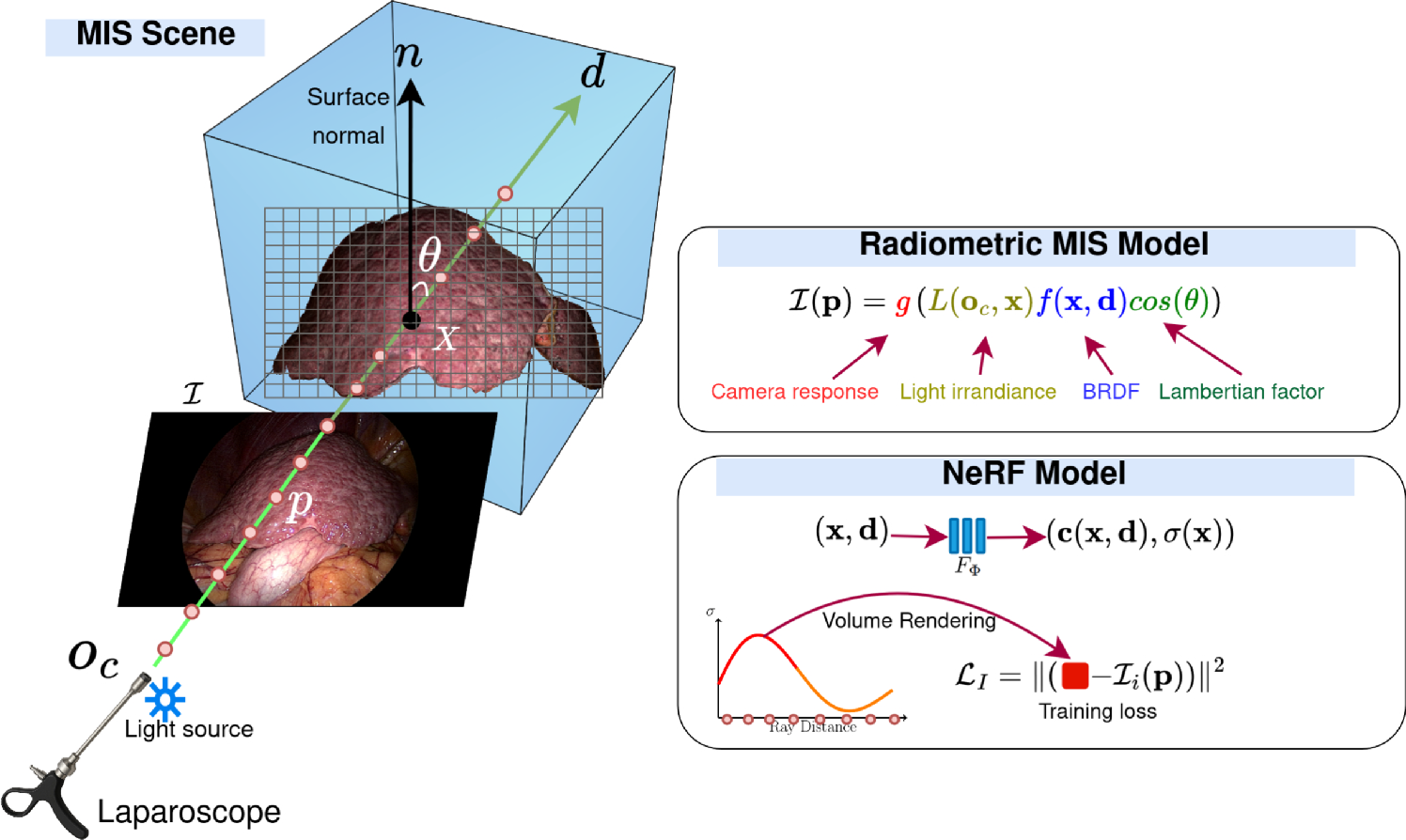
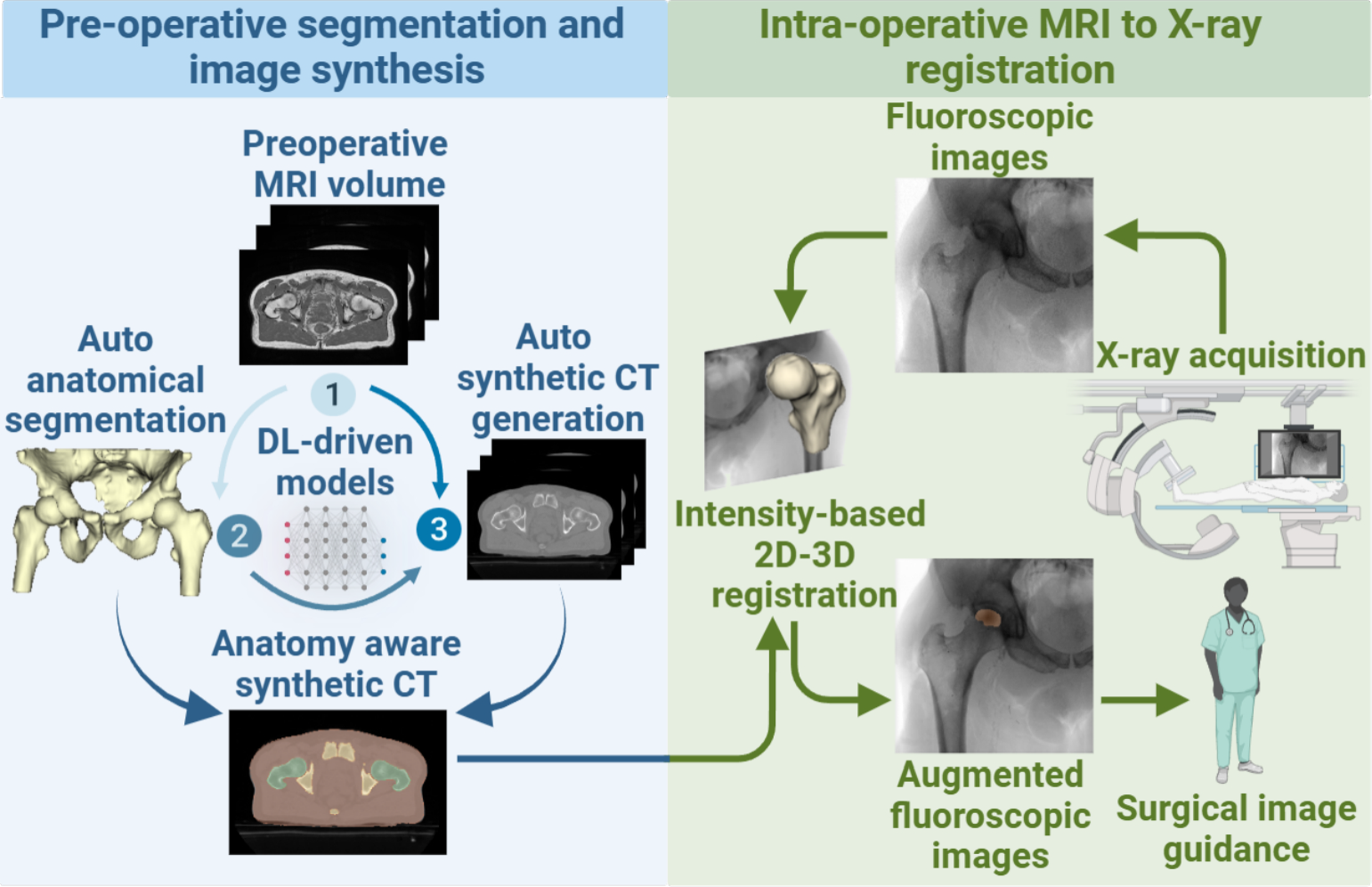
100 participants, including medical students, residents, fellows and consultants filled in the survey over a 6 month period. We merged 24 residents and 10 fellows into one single group labelled Surgical Trainees, given their similar levels of expertise. Moreover, their performance did not differ significantly from one another. We linked the profession of the participants (Fig. 1a ) with their level of expertise (Fig. 1b ). Finally, we related the expertise level to the number of urological cases actively assisted inside the operating room (Fig. 1c).
Fig. 1
Survey participants. a - M, medical students; ST, surgical trainees; C, consultants. b - V, viewers; B, bedside assistants; SCS, supervised console surgeons; ICS, independent console surgeons. c - Number of urology procedures in which B, SCS and ICS have been involved during their careers
Single frames versus video snippetsTo test the hypotheses that video snippets have an impact on SPR accuracy compared to single frames in RAPN procedures, we selected the Wilcoxon signed-rank test [16, 17] as a paired difference test between single frames and video snippets scores. The following hypothesis were formulated:
Null Hypothesis \(H_0\): There is no significant difference in SPR accuracy between single frames and video snippets. The median difference in accuracy between the two conditions is zero.
Alternative Hypothesis \(H_1\): There is a significant difference in SPR accuracy between single frames and video snippets.
We applied the Bonferroni correction to counteract the multiple comparisons problem [18]. Thus, we divided the \(\alpha =0.05\) threshold per the number of comparisons. Figure 2 summarises users’ scores (Fig. 2a ) and the p-values resulting from the Wilcoxon Signed-Rank test (Fig. 2b ) per profession. The Null Hypothesis was rejected for all groups and the profession significantly influenced the p-values. No significant relationship was observed between the time that participants spent answering the questions and their performance.
Fig. 2
Null Hypothesis \(H_0\) rejected for all groups professions
Table 2 lists the occurrences of clustered visual landmarks denoted by participants with free text to classify surgical phases in RAPN procedures, ranked in descending order. The high amount of Movements & Gestures attributions highlights the value of having temporal context.
Table 2 Occurrences of landmarks denoted by participants to classify surgical phases in RAPN procedures, ranked in descending orderTable 3 Participants performanceFig. 3
Confidence level during the survey across professions. Densities are proportional to the number of samples
To assess the appropriateness of video snippets length, participants were asked whether 10 s were sufficient to classify phases or not. While 79 preferred longer snippets and 21 found 10 s adequate, performance did not differ significantly between the groups, though consultants who favoured shorter snippets exhibited higher confidence. However, feedback from participants who preferred longer snippets highlighted two key points. First, one participant noted that ‘some videos don’t represent certain phases and they should last several seconds’. While the ideal snippet length was not specified, incorporating long-term temporal context might help resolve ambiguities in the complex surgical workflow of RAPN surgeries, which result from varying visual patterns in patient anatomy, diverse surgical techniques, and phase sequences broken into smaller actions. Second, another participant commented that ‘videos should not be longer but should capture more relevant moments of the phases’. Although no specific criteria to select informative frames was suggested, the feedback indicates that identifying key moments that summarise phases may be a valuable research direction to improve classification while minimising video snippets length.
Novices versus expertsTo measure the spread of participants’ answers, we computed the \(L_}\) norm for each row of the confusion matrix, which yields values in the range [1, k] (with k=15 as the total number of RAPN phases), where 1 indicates a one-hot distribution, whereas 15 denotes a uniform distribution, implying maximal spread across all phases. Next, we averaged the rows outcomes and normalised the final score to lie within [0, 1], with the goal of providing a quantitative measure that summarises the uncertainty in decision-making during phase classification.
Table 3 summarises the average Accuracy, weighted F1-Score and \(L_}\) norm for all categories. Medical Students were most confused, as compared to Surgical Trainees and Consultants. The phases ‘Hilar Control’, ‘Tumour Excision’, and ‘Hilar Clamping’ benefited most from video snippets, as we believe the temporal context clarified the sequence of actions. Notably, all groups generally struggled with the classification of short duration phases.
Figure 3 provides additional insights by illustrating the average confidence level in answers per profession. Consultants exhibited the highest confidence. Confidence is a subjective metric, and we computed the Spearman’s rank correlation coefficient [17, 19] between the accuracy and the confidence for each group. The results showed no significant correlation, indicating that subjective confidence has minimal influence on objective classification task performance.
Figure 4 shows the average perceived task complexity across professions per section. Similar to the confidence findings, Consultants generally found the task to be simpler when working with video snippets. Participants had mixed opinions regarding the difficulty of the task with single frames, especially when compared to the average confidence reported for each individual question. We also calculated Spearman’s rank correlation coefficient between the accuracy and the perceived task complexity per group, finding no significant correlation.
Fig. 4
Perception of survey sections difficulty across professions. Densities are proportional to the number of samples
Table 4 RAPN fivefold cross-validation under different data scarcity scenariosAI performanceWe validated ResNet50-LSTM and TeCNO on Cholec80, achieving average accuracies of 82.4% and 84.9% respectively, which is comparable to the literature [7, 15].
Table 4 summarise the performance of ResNet50, ResNet-50-LSTM and TeCNO for the complex RAPN data set. The addition of more RAPN labelled data improves classification performance, but the gains decrease as more videos are incorporated. Notably, a longer-temporal context of 60 seconds for ResNet50-LSTM only enhances performance when the full data set is available, indicating that lengthy buffers require a larger volume of labelled data. Long duration phases benefitted most from 60 seconds buffers, contrarily to short phases who suffered the strategy of training without overlapping clips. Interestingly, the \(L\frac\) norm decreased with the extension of the temporal context, suggesting a reduced spread across all phases during classification.
The AI models trained on the complete labelled data set outperformed consultants on single frames and video snippets classification. However, the generally higher confusion level of AI models may stem from the significantly larger volume of samples they processed compared to participants. In contrast, while consultants experienced a significant 12% accuracy boost with video snippets, AI models showed a more modest improvement, suggesting the human advantage in precisely localising surgical phases by leveraging prior knowledge.
In addition, when trained with 25% of the data, the AI models surpassed medical students in classifying frames and videos, demonstrating comparable confusion levels with 10-second clips. Their accuracy also aligned closely with that of Surgical Trainees, though the models exhibited a higher confusion level for single frames.
TeCNO outperformed the ResNet50-LSTM model by extending its field of view to analyse the entire surgical workflow. To maintain a fair comparison with human raters, we deliberately avoided propagating the LSTM state across consecutive N-second buffers. Instead, state propagation was restricted to within individual buffers.
Both human raters and AI models struggled with ‘Hilar Control,’ ‘Specimen Retrieval,’ ‘Hilar Unclamping,’ ‘Specimen Removal,’ and ‘Instrument Removal’ phases.
Comments (0)