
Remember me
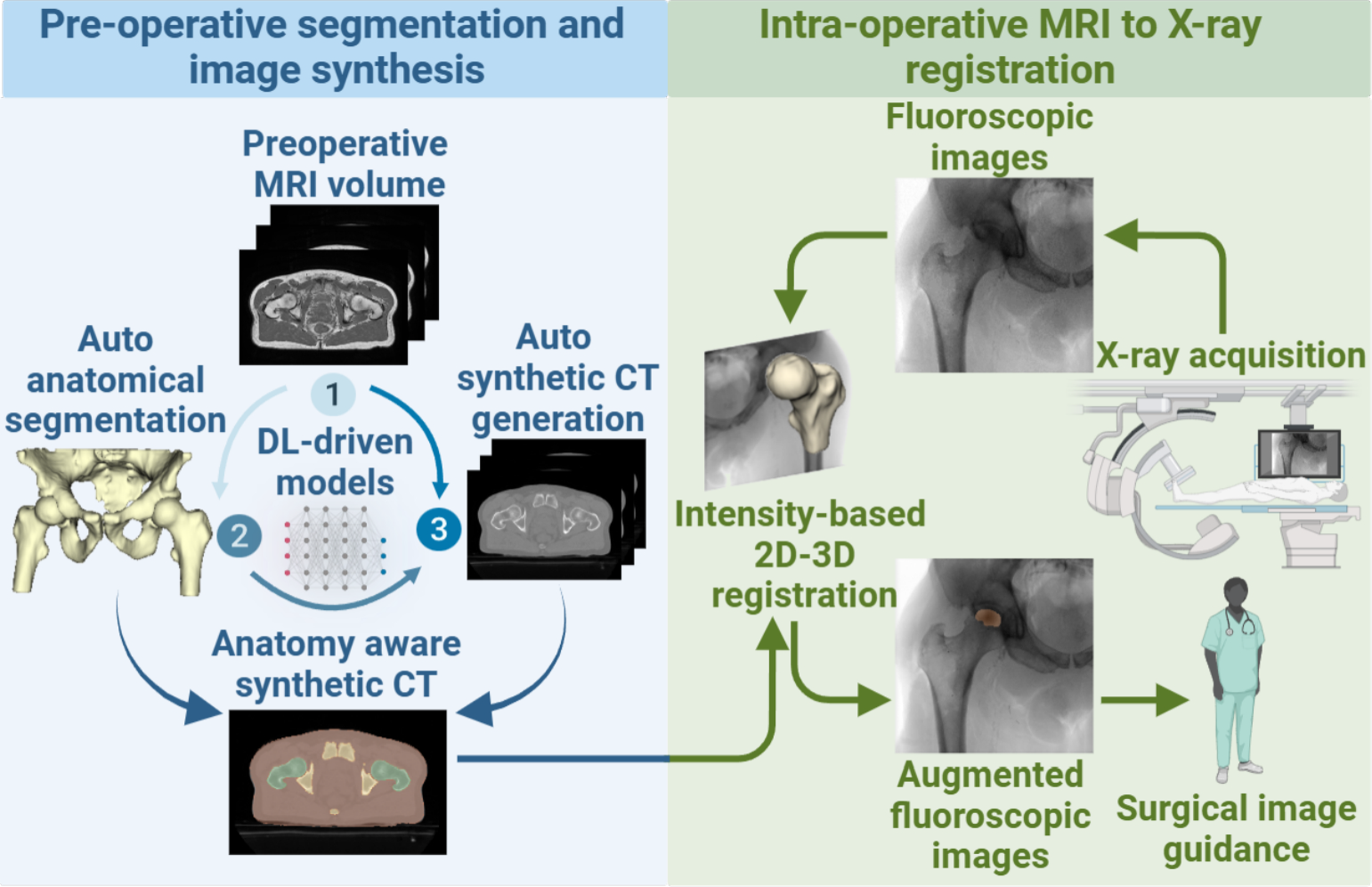
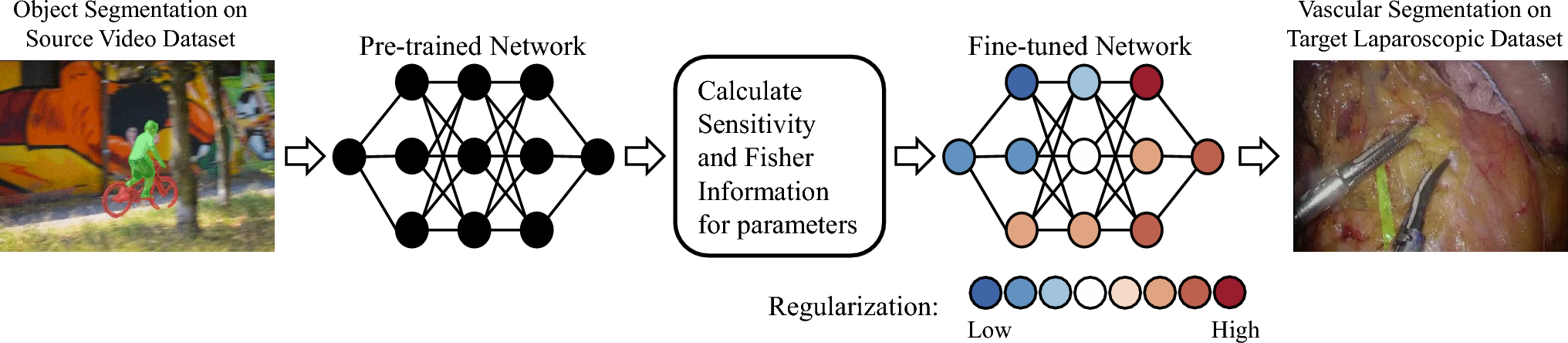
In this section, we delineate the experimental setup and methodology employed to assess the efficacy of our proposed ASFR method. We conduct both qualitative and quantitative comparisons between ASFR and established methods, including Elastic Weight Consolidation (EWC) [9], as well as advanced transfer learning techniques such as Structure Learning with Similarity Preserving (L2SP) [10] and Batch Spectral Shrinkage (BSS) [22].
DatasetFor the validation and training of our ASFR approach, we utilized an in-house dataset consisting of 22 laparoscopic gastrectomy videos from the Aichi Cancer Center, Japan. The dataset includes annotations for both visible and invisible LGV, with a total of 1,581 frames annotated for visible LGV and 3,444 frames for invisible LGV. To ensure robust evaluation, we partitioned the dataset into distinct sets: 1,225 frames from 4 videos were designated as the test set, 587 frames from 2 videos formed the validation set, and the remaining frames from 18 videos were allocated to the training set. This partitioning ensures comprehensive coverage of variations in LGV visibility and the complexity inherent in surgical procedures.
Experimental detailsThe experiments were implemented on the STCN [11] and XMem [12] networks, utilizing their pretrained weights to establish a strong foundational model. Fine-tuning was conducted on a single NVIDIA Tesla V100 GPU. The training protocol involved processing batches of randomly cropped images measuring \(320 \times 320\) pixels across 25,000 iterations, with each batch containing 4 images. The hyperparameter \(\lambda \) was strategically set to 0.5 to balance the dual objectives of minimizing the new task’s loss and preserving the fidelity of previously acquired knowledge.
Performance metricsSince our task involves segmenting the LGV as it transitions from invisible to visible states, we evaluate our method and existing methods using the Dice score in two parts: the segmentation of invisible LGV and the segmentation of visible LGV. To provide an overall measure of performance, we also compute the average of these two Dice scores.
It is important to note that accurately determining the boundaries of the LGV in laparoscopic images presents challenges, particularly when vessels are partially occluded. As such, the ground truth annotations may not be entirely precise. Therefore, while the Dice score provides a useful metric for comparing segmentation performance, it should be considered as a reference and may not precisely reflect the actual segmentation accuracy in numerical terms, especially for invisible vessels.
Quantitative comparisonWe evaluated our method and previous approaches using 4 lengthy laparoscopic videos, each averaging 6 min and 46 s (10,162.5 frames). The results, presented in Table 1. All methods exhibit relatively large standard deviations, which reflect the Dice score variability from frame to frame, due to the inherent ambiguity in vascular location. Our method outperformed others on two different network architectures, both in segments immediately following the labeled first frame (invisible vessels) and in later frames (visible vessels). This differentiation in performance underscores the pretrained network’s transferability in video segmentation and its adaptability to laparoscopic video.
Table 1 Comparison of Dice scores of different transfer learning methods on STCN [11] and XMem [12]. P indicates the use of pretrained weights, and R indicates the use of regularization. EWC [9] uses only Fisher Information (Sect. 3.2.1) and serves as an ablation study. Highest and second highest results are highlighted in bold and underlinedAmong the comparison methods, Baseline initializes the network without pretrained weights and, while capable in visible segments, struggles with occluding vessels. Fine-tune modifies the entire network based on pretrained weights, showing proficiency in detecting visible vessels but faltering with occluded ones. EWC and L2SP apply regularization to protect certain pretrained weights, enhancing the network’s segmentation ability for occluded vessels at the expense of reduced adaptability. BSS, a simpler classification network-based method, underperforms in the complexity of video segmentation tasks.
Our proposed ASFR method achieves an optimal balance, maintaining valuable information from the pretrained model while effectively adapting to the new task. Notably, for the XMem network, ASFR demonstrates superior localization of both visible and occluded vessels, evidenced by its higher average Dice scores.
Qualitative evaluationThe qualitative outcomes of different methods are illustrated in Fig. 3. Our task involves predicting the positions of both invisible and visible LGV in subsequent frames, given annotations in the first frame. Among the provided examples, the most significant differences in predictions across methods occur during the crucial transition when the invisible vessels become visible. Compared to other methods, our proposed ASFR method consistently and accurately tracks the position of invisible vascular segments. This precision delivers superior segmentation results precisely at the critical juncture when the invisible vessels becomes visible.
Fig. 3
Comparison of qualitative segmentation results using different methods. Red indicates the annotated position of the LGV, green represents the network-predicted position of the LGV, and areas where both overlap appear in yellow. For invisible vessels, the ground truth annotations are based on estimations, therefore the boundaries of the ground truth may not be accurate
Specifically, methods like Fine-tune and BSS struggle to effectively track the position of invisible vessels. EWC and L2SP manage to track vascular positions only over short durations. As the invisible vascular becomes discernible, the accuracy of predictions from these comparative methods markedly deteriorates, leading to subpar performance in the initial stages of visibility. However, once the vessel is clearly visible, all methods achieve intuitively acceptable prediction results.
Experiments in the absence of initial frame annotationsFig. 4
Predictions by the XMem network, fine-tuned with ASFR, without initial frame annotations, across two examples. The annotated LGV positions are marked in red, network predictions in green, and overlapping areas in yellow. The network fails to predict invisible vessel when obscured by dense adipose tissue. However, as the obscuring tissue becomes thinner, the network successfully detects the vessel, even when it remains not distinctly visible
Table 2 Comparison of Dice scores for transfer learning methods on the XMem network, evaluated without initial frame annotations. P indicates the use of pretrained weights, and R indicates the use of regularization. Highest and second highest results are highlighted in bold and underlinedAlthough surgeons can utilize ICG [3] or Doppler ultrasound [4] to locate vessels obscured by adipose tissue, these techniques are not universally available in all laparoscopic surgeries. Additionally, in some cases, it is not feasible to provide initial annotations of invisible vessel in the first frame of the video. To evaluate our method’s performance under these conditions, we conducted a series of experiments.
The results are presented in Table 2 and Fig. 4. The XMem network, pretrained on large datasets and fine-tuned on the LGV dataset using our ASFR method, effectively identifies both visible and partially obscured LGV, even without initial frame annotations. Quantitatively, the accuracy in localizing visible vascular structures showed only minimal reduction compared to scenarios with annotated initial frames. In contrast, while the Fine-tune and BSS methods maintained consistent performance in segmenting obscured vessels, the EWC and L2SP methods exhibited significant performance declines.
Figure 4 notably demonstrates that certain methods can still identify sections of obscured vessels even without initial annotations, especially when the obstructive adipose tissue is relatively thin. These results highlight the capabilities of fine-tuned networks to effectively identify vascular structures during surgical procedures, emphasizing the robustness and adaptability of our proposed ASFR method in real clinical settings.
Comments (0)