Database
The analysis is based on anonymized, routinely collected claims data from the German SHI, a system which insures 88% or around 74 million of the population living in Germany [16]. Civil servants, judges, and temporary soldiers are not subject to SHI. People who are self-employed or whose income is above a threshold can have voluntary SHI. The dataset provided by GWQ ServicePlus AG (“Gesellschaft für Wirtschaftlichkeit und Qualität bei Krankenkassen”) comprises information on over 6.3 million people insured at 19 SHI funds between 2010 and 2022, representing approximately 8% of the total SHI population in Germany.
The dataset encompasses patient-level information on all costs borne by the SHI. Data include all diagnoses from outpatient contacts and inpatient hospital stays. The inpatient, procedural outpatient, and prescription data are available on a day-to-day basis. Outpatient diagnosis data are generally available on a quarterly basis.
German claims data do not include laboratory results, anthropometric data, magnetic resonance imaging (MRI) findings, or detailed information on medical specialists involved during inpatient treatment. While prescription data is available, they are not linked to respective indications. A general description of the content of claims data in the German setting is available from Swart et al. [17].
Study Design and Population
Our study used a retrospective cohort design and was conducted following applicable subject privacy requirements and the guiding principles of the Declaration of Helsinki. Analyses were based on claims data covering the period 2010–2022. As the study did not gather patient or individual-level data or involve any interventions, formal ethical approval was not sought, and informed consent was not applicable.
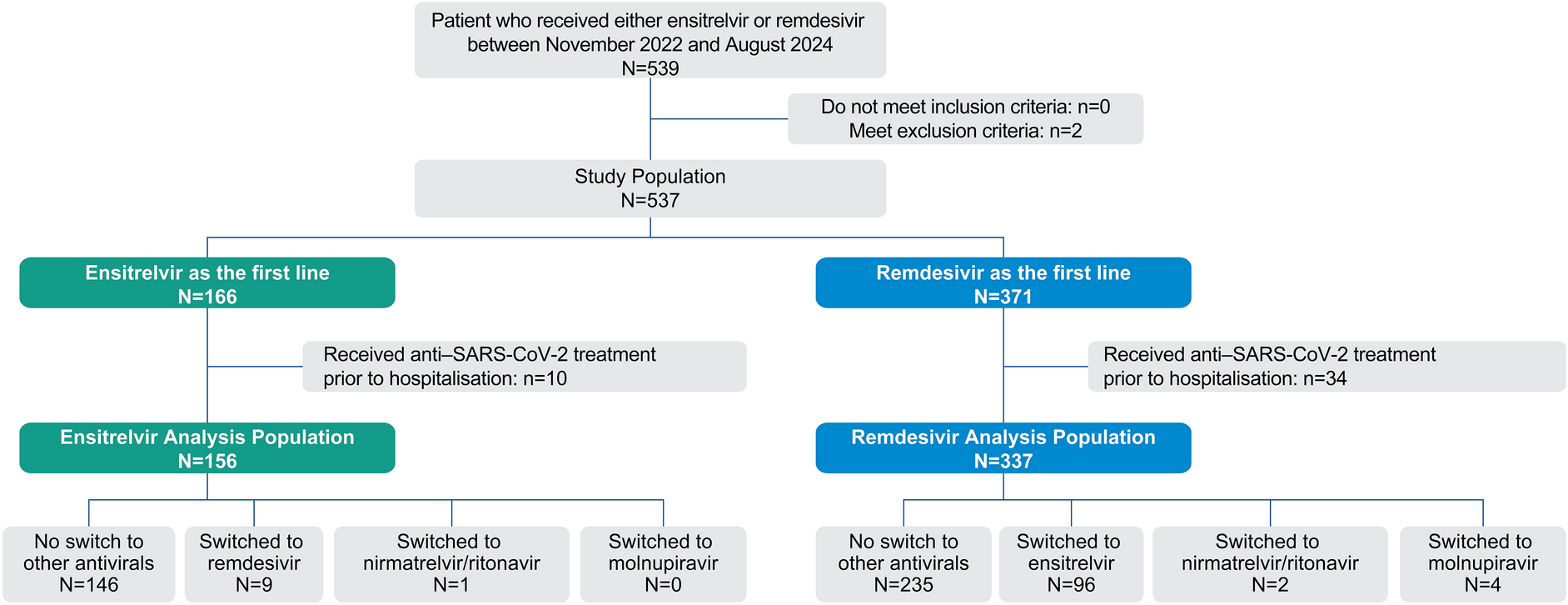
The analysis was performed pooled across seasons, where a season begins on 1 July of a particular year and ends on 30 June of the following year. The study design included a 30-day washout window and 90-day postobservational period. The study population included hospitalized individuals over 18 years of age. The study included individuals who were continuously enrolled with the SHI for at least four quarters before hospitalization (index event) and during the entire follow-up period. The first possible cohort entry date is defined as 1 July 2011, and the last possible cohort entry date is 30 June 2022.
To ensure proper case distinctions, we included individuals who had RSV (as defined in Table 1) as a secondary diagnosis. Cases with RSV as a primary diagnosis were excluded. Individuals with any-cause hospitalization during the washout period (30 days before index event) were excluded. The washout window ensured that included hospitalizations were initial hospitalizations.
Table 1 Cohort ICD-10 codesThe study used outpatient data to assess comorbidities. Since outpatient diagnosis data are available on a quarterly basis, it remains unclear whether comorbidities in the cohort entry quarter occurred before or after the index event. Therefore, the assessment window for comorbidities consisted of the four quarters preceding the index event. For all other covariates (e.g., age, sex, season of admission, and main diagnosis), the covariate assessment window was the quarter in which the index event occurred.
See Supplemental Material Figure S1 for a depiction of the study design according to Schneeweiss et al. [18].
Patient Identification and Patient Cohorts
In German hospitals, testing for RSV is not mandatory. Furthermore, even when testing is performed, an ICD‐10 diagnosis might not be documented if laboratory results are delayed. This results in uncertainty in identifying patients with RSV in German claims data. To reduce this uncertainty, Cai et al. evaluated different ICD-10 codes for identifying RSV in a setting where laboratory test results are available, finding that RSV-specific ICD-10 codes underidentify cases [19]. The authors recommend combining RSV codes with more general acute lower respiratory infection codes to overcome this problem [19].
On the basis of these findings, we used both a narrow and a broad definition to identify patients with RSV as a secondary diagnosis. In general, a narrowly defined cohort results in a relatively high risk of false-negative results, while a broadly defined cohort results in a higher risk of false positive results. Comparing these two cohorts can provide a reasonable estimate of upper and lower bounds. On the basis of these considerations and additional clinical expert opinion, we defined two cohorts: a narrow RSV cohort with RSV-specific ICD-10 codes, and a broad RSV cohort with ICD-10 codes for diagnoses with similar symptoms or characteristics to RSV. Both cohorts were matched (see details in the statics section). See Table 1 for cohort definitions and ICD-10 codes.
According to Cai et al., the narrow RSV cohort (without B97.4, which is usually used for RSV as secondary diagnosis) shows a specificity (true negative rate) of 99.8% (95% confidence intervals, CI 99.6–99.9%). However, the sensitivity (true positive rate) was estimated at 6% (95% CI 3–12%) [19]. Consequently, the cases identified in our narrow RSV cohort are almost certainly true RSV cases, but many true RSV cases were likely left out. The broad RSV cohort complements the narrow approach by increasing sensitivity at the cost of specificity. Other studies in Canada [20], Australia [21], and Spain [22] have results similar to those of Cai et al. [19] and support this approach.
Outcome Measures
The outcomes of interest included mortality, lengths of stay (LOS), costs (from the payer perspective, as billed in euros (EUR), not adjusted for inflation), and special fees (in EUR). Additional outcomes also included rehospitalization rate, intensive care unit (ICU) admission rate, ventilation rate, and high-flow oxygen rate. Detailed information of interest for this study is summarized in Table 2.
Table 2 Summary of outcomes and statistical methodsStatistical Analysis
Cohorts were matched with controls using a 1:1 exact matching approach. The balancing of comorbidities was checked via standardized mean differences (SMD), with SMDs less than 0.1 indicating a good balance. Table 3 summarizes the matching variables.
Table 3 Matching variablesDescriptive statistics are used to characterize the study population and to give a broad overview of the frequencies of the outcomes. Regression results are presented as estimated coefficients of statistical models. The regression approach was tailored to each outcome variable (see Table 2).
Reporting of study results followed STROBE criteria [23]. We performed analyses with R (Version 4.1.3).

Comments (0)