
Remember me
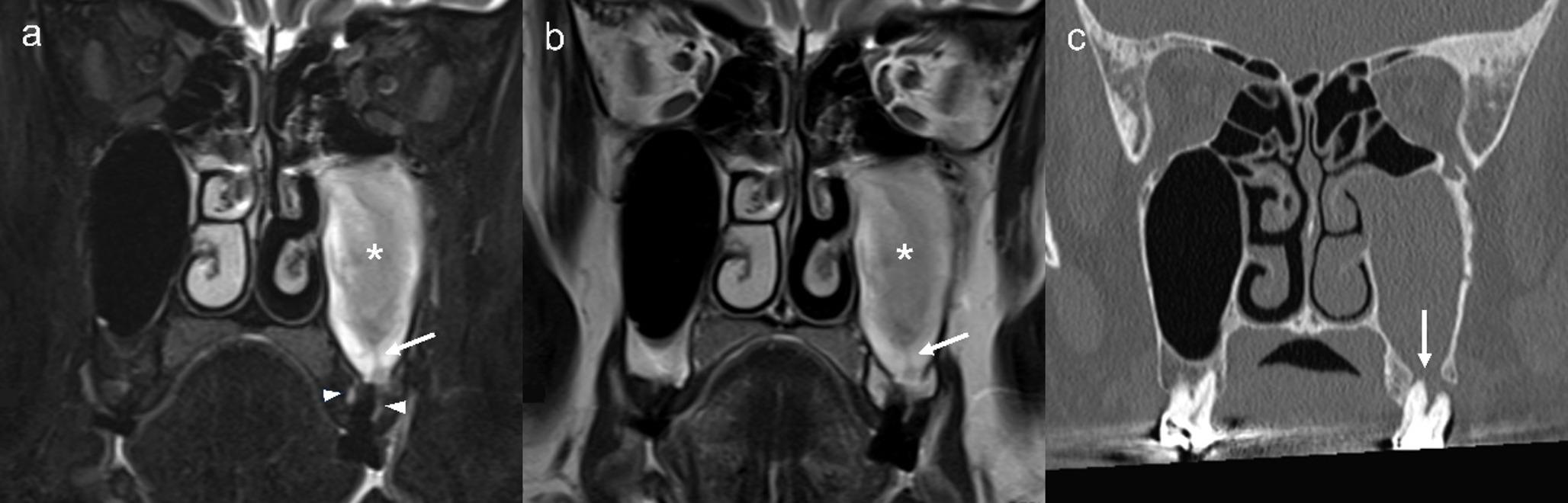
This study was approved by the institutional ethics committee (protocol No. 23036; clinical trial number: not applicable) and conducted as a retrospective diagnostic accuracy study in accordance with institutional guidelines. CBCT scans were anonymised prior to analysis. Owing to the retrospective design and de-identified data, informed consent was waived.
Inclusion criteriaCBCT images of posterior mandibular edentulous sites, including both single-tooth and multiple-tooth edentulous regions.
Small, medium, and large field-of-view (FOV) scans, reconstructed with standardized voxel sizes (0.2–0.3 mm) and uniform reconstruction parameters.
High-resolution, clear cross-sectional images suitable for segmentation and measurement.
Exclusion criteriaNon-edentulous or fully dentate mandibular regions.
Images with artefacts, poor resolution, or inadequate anatomical clarity.
Incomplete or misaligned CBCT scans excluding bucco-lingual measurement sites.
Pathological sites affecting measurement accuracy or segmentation.
CBCT scans were obtained for implant planning using a Planmeca ProMax 3D CBCT unit (Planmeca Oy, Helsinki, Finland). The scans included small, medium, and large fields of view (FOVs), selected according to the clinical indication. In the present study, small FOV corresponded approximately to volumes of 40 × 50 mm to 50 × 50 mm, medium FOV to approximately 80 × 80 mm to 100 × 100 mm, and large FOV to volumes ≥ 160 × 100 mm, consistent with the acquisition presets available in the Planmeca ProMax 3D system.
Exposure parameters varied within the manufacturer’s preset range (approximately 84–90 kV, 6–10 mA, and 12–14 s exposure time) depending on the chosen FOV and patient size. Images were reconstructed with a voxel size of 0.2–0.3 mm and analyzed in cross-sectional slices perpendicular to the alveolar ridge using Romexis software version 4.6.2.
To minimise variability related to FOV differences, all scans were reconstructed using standardized voxel sizes, uniform reconstruction algorithms, and consistent cross-sectional orientation perpendicular to the alveolar ridge, ensuring comparable spatial resolution and measurement geometry across datasets.
Cross-sectional slices were generated using standardized reconstruction protocols, with slice orientation aligned perpendicular to the long axis of the alveolar ridge and referenced to consistent anatomical landmarks. Slice selection was based on ridge morphology at posterior mandibular edentulous sites, ensuring uniform angulation and spatial orientation across cases. For each eligible edentulous site, cross-sectional images were extracted at standardized positions along the ridge, with consistent slice thickness and spacing to minimise geometric variation.
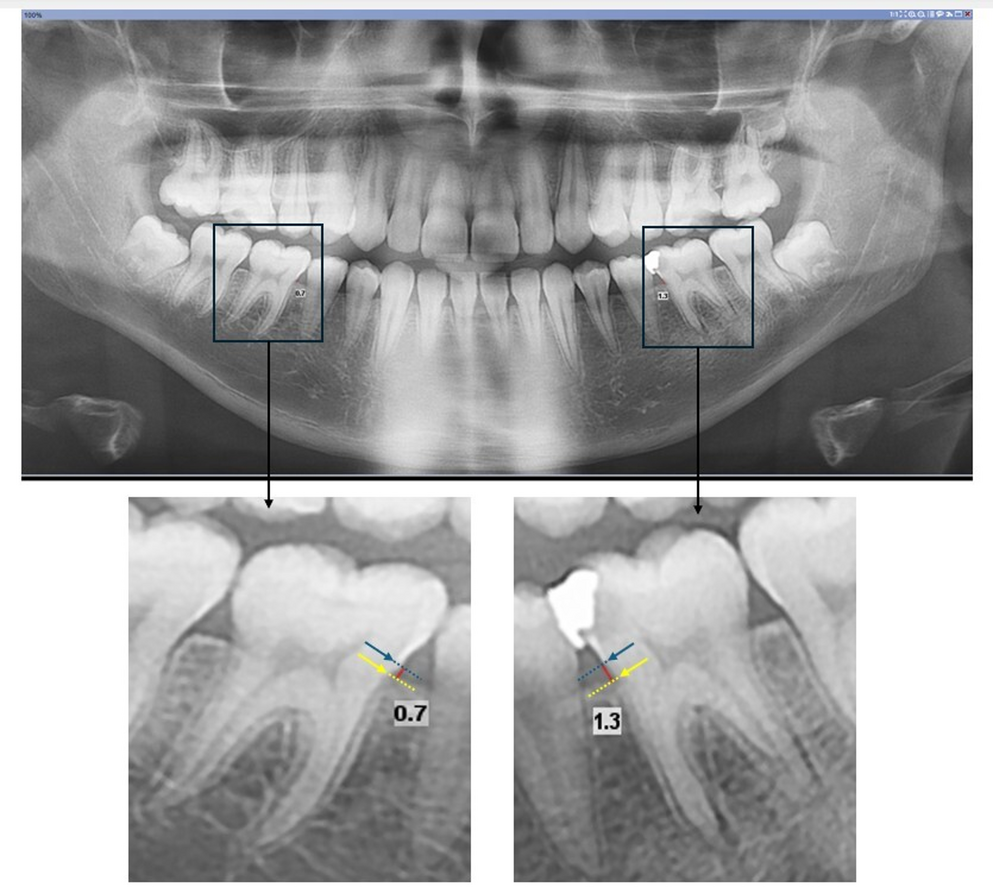
Manual measurementsCross-sectional slices were evaluated by a radiologist (H.N.). The number of cross-sectional slices per CBCT corresponded to the number of posterior mandibular edentulous sites meeting inclusion criteria. For each site, measurements were obtained from standardized cross-sectional views positioned through the center of the edentulous ridge span, ensuring consistent anatomical location and measurement geometry. Bucco-lingual width was defined as the distance between the external buccal and lingual cortical plates, measured perpendicular to the ridge axis. Measurements were recorded at the alveolar crest and at 2-mm intervals apically until 2 mm superior to the mandibular canal. Each site was measured twice at separate time points by a single trained radiologist (H.N.), and the mean values were recorded. To ensure intra-operator reliability and measurement reproducibility, standardized anatomical landmarks, fixed measurement definitions, and consistent slice orientation criteria were applied across all cases. The use of uniform measurement protocols and repeated measurements minimized operator-dependent variability. All measurements were performed perpendicular to the ridge axis to maintain geometric consistency and reduce variability related to ridge morphology and edentulous span length.
SampleA total of 300 CBCT scans meeting the inclusion criteria were retrospectively retrieved and included for analysis. Axial sections of posterior mandibular edentulous sites were extracted from all scans. The entire dataset (n = 300) was utilized for analysis, with 80% allocated for model training and 20% for validation. The sample size was determined in consultation with a statistician based on feasibility and comparability with similar AI imaging studies.
The dataset included both single-tooth and multiple-tooth posterior mandibular edentulous sites. To control for morphological variability associated with differing resorption patterns, all measurements were performed using standardized anatomical reference points (alveolar crest and mandibular canal) and fixed vertical intervals (2-mm increments), ensuring consistent measurement geometry across all edentulous configurations.
Rationale for posterior mandibleThis region was selected to maintain dataset consistency and because anatomical features such as lingual concavities and canal proximity render precise bucco-lingual measurements clinically significant.
AI frameworkData were blinded prior to processing. Multiple CNN architectures (U-Net, Double U-Net, U-Net++, DeepLab) were tested, with U-Net + + selected for segmentation tasks. We selected the U-Net + + architecture after conducting an ablation study with all the aforementioned architectures. All these models were trained from the scratch. The models differ primarily in how they learn and combine features at different levels of detail. DeepLab V3 + focuses on capturing the overall shape of large regions but may miss very thin structures. The Double U-Net adds a second refinement stage to improve detail, although it becomes more complex and sensitive to noise. U-Net with EfficientNet improves feature learning but still has limited detail merging. U-Net + + utilizes more connected pathways to gradually refine features, resulting in clearer boundaries and more accurate overall results. In this experiment, U-Net + + with a depth of 5 was used for both alveolar ridge (AOI) and mandibular canal segmentation. The architecture consisted of four encoder levels, a bottleneck layer, and the corresponding decoder levels. Data augmentation included horizontal and vertical flips, shift–scale–rotate transformations, elastic deformation, and random brightness adjustment. Model training was performed using the Adam optimizer with a learning rate of 0.001 and binary cross-entropy as the loss function. The model was trained for 100 epochs, and the best-performing checkpoint was retained for inference. The proposed model segmented the alveolar ridge and inferior alveolar nerve. Ground truth segmentation masks were generated using a semi-automated annotation pipeline to reduce subjective variability. CBCT cross-sectional images containing color-coded anatomical annotations were converted to HSV color space to enable robust threshold-based segmentation. Contour detection was subsequently applied, and the largest connected component was selected as the anatomical region of interest. Minor manual refinements were performed only when image artefacts disrupted contour continuity. This approach ensured annotation consistency across the dataset while minimizing manual bias. Automated bucco-lingual width was then measured at 2-mm intervals from the alveolar crest to the canal. All bucco-lingual width measurements were computed fully automatically from predicted segmentation masks. Measurements were extracted at fixed 2-mm intervals using geometric distance calculations between buccal and lingual cortical boundaries. No post-segmentation manual correction or operator interaction was performed, ensuring reproducibility and eliminating user-dependent variability. Figures 1a, b and 2 illustrate the segmentation and measurement process.
Fig. 1
Illustrations of the input images and segmented regions. a area of interest (AOI) segmented region; b nerve segmented region
Fig. 2
Demonstration of width calculation in the segmented canal region. Annotated measurements are shown at regular intervals to provide precise and interpretable data
AI-generated measurements were compared with manual measurements to evaluate accuracy. Statistical analyses were conducted to assess agreement between the methods and to determine the significance of observed differences.
Statistical analysisAI-generated measurements were compared with manual measurements to evaluate accuracy and correspondence between the two methods.
Quantitative segmentation performance was evaluated using Dice score, IoU, precision, and recall. Dice and IoU describe how well the segmented regions produced by the model overlap with the expert-annotated regions. Precision reflects how accurately the model identifies the area of interest without including extra regions, while recall indicates how completely the model captures the true region without missing parts. Together, these measures provide an overall understanding of both the correctness and completeness of the segmentation and offer a comprehensive assessment of the model’s ability to delineate the area of interest (AOI) and the mandibular nerve regions.
To assess the model’s accuracy in bone width measurement, we used regression-based metrics including MSE (mm²), MAE (mm), RMSE (mm), and R². These metrics compare the model’s predicted measurements with manual clinical measurements obtained at 2 mm vertical intervals from the alveolar crest toward the mandibular canal. Lower values of MSE, MAE, and RMSE indicate smaller measurement errors and quantify the magnitude of error in clinically interpretable units, while a higher R² value reflects stronger agreement between the AI predictions and the manual reference measurements. R² was additionally used to assess the linear correlation between the two methods.
A paired t-test was also performed to compare AI-derived bucco-lingual width measurements with the corresponding manual measurements in order to assess whether a statistically significant difference existed between the two methods. However, more detailed agreement analyses, such as Bland–Altman evaluation, were not performed and are identified as an important direction for future validation in larger, prospectively designed datasets.
All evaluations were conducted on the independent test dataset. Descriptive statistics were reported to summarise performance across test cases. Given the exploratory and pilot nature of this study, primary emphasis was placed on quantitative error metrics to characterize measurement performance. All computations were performed using Python-based libraries, including NumPy, SciPy, and scikit-learn.
Comments (0)