
Remember me
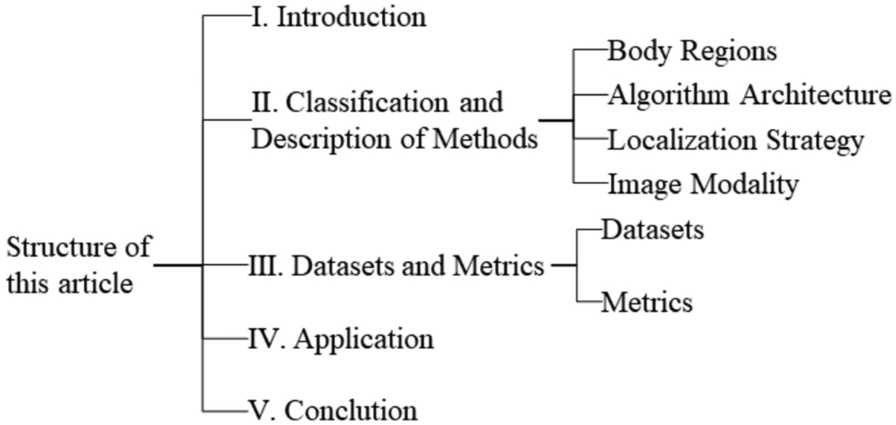
With the rapid development of deep learning, its application in acupoint localization has become increasingly diverse. This section categorizes and analyzes DL-based methods from multiple perspectives to provide a comprehensive overview of the research paths and technical strategies. First, we explore the unique methods used for acupoint localization in different body regions, highlighting their difference. Next, we discuss the principles, advantages, and limitations of various deep learning frameworks, offering a solid foundation for future improvements. And then, we analyze different localization strategies, including direct localization, indirect localization, coordinate regression, Gaussian heatmaps, top-down, and bottom-up approaches, clarifying their core concepts, applicable scenarios and performance. This provides researchers and practitioners with a reference for selecting the appropriate localization method. Finally, we introduce progress in automatic acupoint localization using other image modalities, an area with limited research but high potential value for various applications.
Localization in different body regionsThe distribution of acupoints varies in density across different body regions, with complex and diverse anatomical landmarks and tissue structures, posing varying challenges for acupoint localization. For example, facial acupoints are close to vital organs and easily obstructed by hair; limb acupoints are influenced by posture and angle; and the torso lacks prominent features due to its relatively flat surface. These differences place varying demands on deep learning models for feature extraction and localization. Therefore, it is necessary to develop deep learning algorithms tailored to each body part, utilizing key region features and suppressing interference from different tissue backgrounds to improve localization accuracy.
Facial acupoint localizationThe face is a crucial and intricate part of the body, with the eyes, ears, nose, mouth, and eyebrows, along with a complex network of nerves and blood vessels. It is densely populated with acupoints closely related to health, with special significance in TCM. Facial acupoint localization faces challenges such as facial expression changes, appearance differences, and lighting variations. Therefore, researching its localization methods requires considering multiple factors to build an accurate and adaptable model.
To improve accuracy and real-time performance in TCM facial acupoint augmented reality (AR) systems, Zheng et al. [35] enhanced the multi-task cascaded convolutional networks (MTCNN) face detection and practical facial landmark detector (PFLD) models. They developed three localization strategies: direct localization for coincident points (98.4% accuracy); proportional interpolation between landmarks (97.2%); polar coordinate-inspired positioning from single landmarks (96.8%). These methods enabled successful localization of 49 acupoints across 24 categories. The resultant mobile AR system provides real-time virtual acupoint visualization and information retrieval, offering public-friendly clinical assistance.
Chen et al. [36] applied transfer learning to overcome limited annotated data in facial acupoint localization. By transferring low-level features from a WFLW-pretrained facial landmark detection network (based on ResNet50), they developed an acupoint localization model using 1040 expert-annotated frontal grayscale images covering nine key acupoints. After data augmentation and fine-tuning with a newly initialized fully connected (FC) layer, transfer learning reduced the normalized mean error (NME) by 46.8%, and WingLoss optimization further reduced it by 16.7%. The model achieved an average NME of 2.5%, with minor accuracy variations in specific acupoints not affecting overall robustness.
Huang et al. [37] proposed a novel method for facial palsy diagnosis and quantitative analysis based on TCM acupoint recognition. The method first detects and crops faces using a model integrated in the Dlib library. After preprocessing, the cropped images are fed into a ResNet model pretrained on the ImageNet dataset for acupoint localization. The model then outputs 12-dimensional data corresponding to six acupoints. Finally, the degree of facial nerve damage is quantitatively analyzed and graded by measuring the angles between the lines connecting acupoints and the perpendiculars to the facial midline symmetry. Experimental results showed that the model performed well in acupoint recognition, with a NME of 0.0054 and an average angular error reduced to 4.5 degrees. However, the grading accuracy remained low for patients with significant facial expression changes.
Auricular acupoints differ from body acupoints as irregular segmented areas rather than point-like/circular regions, thus requiring segmentation algorithms supplemented by keypoint detection for precise delineation. Gao et al. [38] proposed a cascaded method. First, Faster-RCNN was used to detect the ear and crop the region. Then, the proposed K-YOLACT method simultaneously segmented auricular anatomical parts and detected keypoints. Finally, combining segmentation results, keypoints, and expert knowledge, OpenCV was used for image post-processing to achieve smoother and more refined auricular acupoint segmentation. Their approach achieved automatic segmentation of 66 regions with 83.2% segmentation mean average precision (mAP) and 98.1% keypoint mAP, demonstrating superior efficiency despite limitations in handling hair/earrings.
The above four methods focus on the localization of acupoints in specific regions. Zhang et al. [39] developed the E-FaceAtlasAR system in 2022, aimed at enabling non-experts to easily locate facial and ear acupoints. Leveraging the Mediapipe framework, the system overlays acupoint regions onto the user’s face in real time. For facial acupoint detection, it uses a pre-trained model for face alignment and hair segmentation, identifying 69 acupoints based on the B-cun method and facial landmarks. For ear acupoint localization, the system applies a standard template with ear detection, keypoint identification, triangulation, deformation, and fusion. Experiments show a facial acupoint NME of 3.9 and a failure rate of 5.13%. The system performs robustly under various angles and occlusions, while the ear segmentation method is sensitive to angle but resilient to lighting and occlusion, with higher error rates in complex ear structures, as indicated by the Dice coefficient.
Limbs acupoint localizationThe limbs, as key areas for movement perception, are densely packed with acupoints related to limb function and the circulation of qi and blood. They have thick muscles, are distant from internal organs, and are safe for acupuncture. As major junctions of meridians, stimulating them can precisely regulate qi and blood, making them ideal for self-care. However, acupoint localization on the limbs faces challenges due to changes with movement and significant individual differences in muscle and skeletal structure. Therefore, deep learning methods should be combined with traditional localization or proportional methods to address individual variations and improve robustness and generalization.
To address the limitations in automatic hand acupoint localization, Chen [40] categorized hand acupoints into four groups based on distribution and selection criteria, using the middle finger as the reference. For acupoints detectable via hand keypoints, the Mediapipe keypoint detection algorithm is combined with TCM knowledge. For acupoints requiring contour detection, edge detection is employed. For nail-based acupoint localization, YOLOv8 is trained for nail detection, followed by offset localization using the bounding box. For acupoints without distinct features, regression neural networks are used based on keypoint coordinates. To accommodate the hand's flexibility and complex structure, rotational and functional methods are also proposed. Experiments reveal average localization errors (AE) of 9.96 for the first three categories and 14.8 for the Hegu (LI4) acupoint in the fourth category, meeting clinical accuracy standards. While the method is highly accurate, further refinement is needed for handling complex backgrounds.
Although the hand acupoint classification method mentioned above is more accurate, it still has significant speed limitations. Wang et al. [41] addressed the issues of low accuracy in lightweight networks and deployment difficulties with high-precision models by proposing a hand acupoint localization method based on a lightweight and efficient channel attention (LECA) network. Using MobileNetV2 as the backbone, the network incorporates an efficient channel attention (ECA) module for improved feature extraction and uses the HuberLoss function to handle varying detection difficulties across acupoints. The method successfully localized 11 acupoints on the palm. Compared to several classic models, it achieved higher accuracy with fewer parameters (only 1.67 M). However, it has the drawback of localizing fewer acupoints.
Given the long training time and low repeatability in manual acupuncture, Chan et al. [42] proposed a robotic acupoint localization method combining deep learning with TCM anatomical measurement. The system uses SSD-MobileNetv1 to detect regions and combines bounding box with TCM anatomical measurement for grid-based acupoint localization. The method was tested on the forearm with a dataset of 278 images, localizing 5 acupoints. Results showed that the mean offset errors (MOE) were all less than 0.08, successfully achieving acupoint localization and robotic acupuncture simulation. While other forearm acupoints can be localized through grid segmentation, the method also suffers from a limited number of localized acupoints.
Wang [43] conducted a study that combines global and local approaches. By using human pose recognition algorithms to obtain human joint points, the study then identifies the target regions based on these joint points. For regular body parts such as the forearm, the study employs skin color segmentation, corner detection, and the bone measurement method to locate acupuncture points. For complex parts like the hand, it uses key point localization and transverse finger width method to calculate the acupuncture points, and estimates the depth of the points through coordinate system transformation. Additionally, the study integrates the Kalman filter and optical flow method to solve the problem of re-localizing acupuncture points after body movement. The experimental results show that the average accuracy rates for locating acupuncture points on the forearm and hand are 94.5% and 93.4%, respectively, and the depth estimation accuracy rate is 96.4%. The method is mature and highly accurate, and can also be applied to acupuncture point localization on the lateral back and face. However, the evaluation metrics are relatively limited.
Torso acupoint localizationThe torso, as a key region supporting the body's organs, contains numerous acupoints closely linked to organ function. Among them, Mu points regulate organ functions directly, the Ren and Du meridians gather qi and blood, and the Back Shu points help balance yin and yang, playing a crucial role in maintaining health. However, compared to the more three-dimensional face and limbs, the torso is relatively flat and lacks prominent features like facial landmarks or joint points. It is also significantly influenced by factors like breathing, posture, and body position, leading to considerable variability. Additionally, the dense distribution of acupoints on the torso increases the complexity of localization tasks.
Zhao [44] categorized back acupoints into obvious and fuzzy ones based on visual features, and proposed feature-assisted and segmentation-based localization methods respectively. The former used an improved ResNet50 to identify acupoint regions, located feature points with the Canny edge detection and corner detection algorithms, and obtained acupoint pixel coordinates via the finger-cun method. The latter segmented the back area with the SK-UNet semantic segmentation network, and located acupoints according to the intersection of segmented regions and the finger-cun method. Experiment results showed that this method had an average coordinate localization error of 4.68 mm and an average robotic arm localization error of 4.89 mm, meeting rehabilitation treatment requirements with high practicality and accuracy.
Fu et al. [45] used OpenPose to detect 18 human body keypoints and conducted bone proportional measurements. They extracted the mid-sagittal line and divided the distance from the shoulder keypoints to this line into six equal parts (each defined as GD). Based on GD, they calculated acupoint locations: for example, the Dazhui (GV14) point is located 3GD from the head keypoint along the mid-sagittal line; the bilateral Jianjing (GB21) points are the midpoints between the GV14 and the shoulder keypoints; and Shenshu (BL23) points are determined using TCM methods, based on the position of the fourth lumbar vertebra spinous process and a distance of 2GD. The acupoint coordinates were then converted from 2 to 3D and output to a robotic arm for back acupoint localization. Experiments demonstrated that the algorithm is accurate and practical for back acupoint localization under various camera conditions.
Liu et al. [46] proposed a method for acupuncture point localization based on prior information and deep learning, which localized 23 acupoints on the back. They first constructed an improved Keypoint RCNN network and embedded a convolutional block attention module (CBAM) to perform the initial localization of the acupoints on the back. Subsequently, based on the rules of acupoint distribution summarized from TCM theory and acupuncture experience, a posterior midline localization method was designed. This method involved image preprocessing, contour fitting, and centroid localization to determine the posterior midline, which was then used to correct the acupoints with larger initial localization deviations and to extend the localization of other acupoints. Experimental validation demonstrated that the improved model achieved an acupoint localization accuracy of 90.12%.
Feng et al. [47] proposed an abdominal acupoint detection and localization method based on meridian direction. They first used MediaPipe to extract key human posture points and combined YOLOv8 to detect the nipple and belly button, determining the main meridian directions based on these reference points. Then, using bone measurement methods and the established meridian coordinates, they localized 35 acupoints using geometric topology. Evaluation showed a mAP of 97.9% at IoU (intersection over union) = 0.5, and 87.1% for mAP@0.5:0.95, with an average distance error (MDE) of less than 3 mm, making it suitable for smart moxibustion and massage robots.
Multi-region acupoint localizationDue to the significant differences in characteristics among various body regions and the distinct methods for calculating acupoint coordinates, a localization method that reflects regional features is required for cross-regional acupoint positioning. Additionally, since multiple body regions need to be captured, the resolution is relatively low, and higher accuracy is demanded from the model.
Hu et al. [48] proposed a real-time acupoint localization method targeting the neck, back, buttocks and leg regions. The method first detects the human body using Faster R-CNN and then employs a Symmetric Spatial Transformer Network (SSTN) to estimate the human pose and obtain the coordinates of key skeletal joints. Subsequently, based on the skeletal node positions and joint vectors, the two-dimensional coordinates of the acupoints are determined using the bone measurement method. These 2D coordinates are then transformed into 3D coordinates. Experiments demonstrated that this method achieves a frame rate of 14 frames per second (FPS) and exhibits good robustness against various clothing colors and body postures. The average localization error for four commonly used acupoints is 2.36 cm. Although this error is relatively large for acupuncture robots, it is sufficient for massage robots.
SummaryThe human body’s anatomical regions have distinct structural features. Based on their distribution characteristics and surface traits, this paper categorizes them into three groups: head, limbs, and torso, as shown in Table 1. Figure 2 illustrates the general localization methods for each region. The face and hands, with rich surface features and easily recognizable landmarks, can be accurately localized using common keypoint detection algorithms combined with traditional methods. In contrast, the back, forearm, and chest/abdomen regions are relatively flat and have fewer distinctive features, so direct localization methods or special points combined with traditional measurements are typically used. While public keypoint detection datasets for the face and hands are abundant, the back has a dense distribution of acupoints, making it highly valuable for research in TCM meridians and acupuncture. Consequently, these three regions have been widely studied, generating a significant amount of related literature. However, research literature on automated acupoint localization across multiple body regions is relatively limited. The existing studies tend to focus on single or limited regions, and no method has yet been proposed that integrates the localization of acupoints on the face, back, and legs. Given the significant differences in characteristics among various body regions and the diverse localization requirements for each, it is imperative to develop a novel localization method that can accurately accommodate the unique features of each region.
Table 1 Summary of acupoint localization methods across different body regionsFig. 2
The general process for locating acupoints in different body regions
Overall, DL-based localization methods are numerous and mainly rely on techniques like GANs, object detection, and keypoint detection. Due to the unique shape of acupoints, the most commonly used methods are direct or indirect localization based on keypoint detection. However, despite advancements in keypoint detection and related technologies, automatic acupoint localization still faces several challenges that need improvement. First, datasets for acupoint localization are extremely scarce, and most are not publicly available, limiting data support and hindering progress in expansion and validation. Second, existing studies have issues with incomplete coverage and insufficient numbers of acupoints, which cannot meet the needs for in-depth research and practical applications. Third, some evaluation metrics are flawed, as they cannot comprehensively and accurately assess localization accuracy, and the lack of standardized criteria makes it difficult to objectively evaluate the effectiveness of various methods, impeding the optimization of research.
Although existing studies on acupoint localization methods have been able to adapt to factors such as angles, postures, and environmental changes, and have integrated TCM's cun measurement and surface landmarks, for acupoints that require precise localization dependent on specific postures (such as facial acupoints like Tinggong (SI19), Tinghui (GB2), and Ermen (TE21) with the mouth open, or limb acupoints like Hegu (LI4) and Quze (PC3) when joints are flexed), clear postural requirements for practitioners have not been specified. Although the targeted use of specific postures to localize individual or partial acupoints increases the workload of the dataset and the complexity of algorithm, this approach can effectively utilize the knowledge from traditional simple acupoint location methods, enhance the localization features, thereby improving the localization accuracy. In application scenarios with high requirements for localization accuracy of specific acupoints, such as VR-based teaching, this method not only improves the localization accuracy but also prompts the required auxiliary postures, thus optimizing the teaching quality.
Localization using diverse algorithmic architecturesWith the rapid development of deep learning technologies, many algorithms have emerged, each with unique advantages. In practical applications, we need to consider the specific situation and requirements to select the appropriate algorithm for optimization. For example, HRNet [50] excels at capturing high-resolution features, even with low-resolution input; GANs, with their strong generative ability, can enrich datasets while directly localizing acupoints; Transformers, utilizing self-attention mechanisms, can be more accurate and efficient in localization tasks; YOLOv8-Pose [56] meets the needs for real-time fast localization, making it suitable for quick-response scenarios; and the MediaPipe framework [59] and OpenPose library [61] provide rich models and tools for developers to deploy and develop applications. Furthermore, combining multiple models can effectively overcome the limitations of a single algorithm, improving accuracy and offering stronger support for intelligent applications in TCM. Below, we will explore the specific applications, advantages and disadvantages of these algorithms.
Acupoint localization based on GANsGANs are a groundbreaking architecture in deep learning, consisting of a generator and a discriminator. The generator takes random noise as input and simulates the distribution of real data, generating realistic images. The discriminator, similar to a classifier, is responsible for distinguishing between real and generated images. Both networks continuously compete to optimize the generated data. GANs can uncover data features through unsupervised learning, generating data that closely approximates real samples, eliminating the need for manual feature extraction and enhancing modeling efficiency. They also expand datasets, helping train other models.
Gao [49] proposed a GAN-based localization method for acupoints near the eyes. First, a dataset of 600 images from 300 individuals, annotated by TCM experts with 18 acupoints near the eyes, was established. All images were resized to 512 × 512 via bilinear interpolation and aligned using Dlib facial landmarks, and an evaluation system consisting of outpoint rate (OAR) and Average coordinate error (ACE) was proposed for network training and objective assessment. To improve the efficiency, accuracy, and generalization of acupoint localization, the researcher introduced three GAN models. First, an improved Pix2pix network was used to propose a supervised learning acupoint estimation network, where the generator adopted a 16-layer U-Net structure and used the Adam optimizer, and only produced acupoint estimation maps. The discriminator was constrained with multiple precision conditions, leading to better localization speed and accuracy than the original network. Second, a supervised cyclic GAN was improved by adding a pyramid sub-attention module to the 8-layer U-Net generator to capture distant feature correlations, and a multi-scale attention module with several loss functions was integrated into the Patch discriminator. Although slower, this model achieved higher accuracy than the acupoint estimation network. Lastly, to address the lack of paired data, an unsupervised learning-based eye acupoint information separation and fusion network was proposed, with three generators designed to remove, extract, and fuse acupoint information with clean facial images. Experimental results showed that this network outperformed many traditional networks. The ACE for the 18 eye acupoints met clinical standards, although the Outpoint Rate for some acupoints was still low.
Acupoint localization based on HRNetHRNet, introduced in 2019 by the University of Science and Technology of China and Microsoft Research Asia, is a groundbreaking approach to human pose estimation. It overcomes the limitations of traditional network architectures in handling multi-scale features by innovatively proposing a high-resolution network structure. Through parallel connections of multi-resolution branches and frequent information interaction, it enables complementary features from different resolutions, effectively improving pose estimation accuracy.
Zhang et al. [51] developed a human acupoint detection framework to address issues such as low detection efficiency, poor accuracy, and large errors in acupoint recognition across different body types in current intelligent moxibustion systems. They first applied the Faster R-CNN algorithm to detect the human body and then used HRNet for keypoint detection. By converting the “cun” value relationships based on TCM meridian theory, they computed acupoint coordinates using keypoints and acupoint data. The HRNet algorithm, with its unique parallel multi-resolution convolution structure, maintains high resolution throughout, avoiding the loss of feature information typical in traditional networks that downsample and then upsample. This enabled more accurate keypoint detection. The framework successfully detected 21 acupoints along the foot taiyang bladder meridian (mainly on the back), with errors not affecting the moxibustion treatment’s effectiveness, showing clear advantages in acupoint detection efficiency and accuracy compared to other methods.
Zhang et al. [52] improved the HRNet architecture by introducing a Resolution, Channel, and Spatial Attention Fusion (RCSAF) module before the head network. Using a dataset of 654 facial images (600 training/54 test samples resized to 256 × 256) annotated for 43 acupoints by licensed physicians, the RCSAF module leverages attention mechanisms (4-scale pyramid, 8 attention heads) to learn feature weights from different resolution paths and spatial locations, thereby effectively integrating features to produce more discriminative representations. The improved model was evaluated using Normalized Mean Error (NME) with normalization factor d set as inter-canthi distance (clinical standard for eye-related acupoints), Failure Rate (FR), and Area Under the Curve (AUC). When the model was trained with Adam optimizer and MSE heatmap loss, results indicated that the modified HRNet achieved the best performance, with an NME as low as 2.42%. Additionally, the study found that acupoints near facial landmarks (e.g., eyes, nose, and mouth) were localized more accurately, validating the effectiveness of using facial features to guide acupoint detection.
Seo et al. [53] evaluated HRNet and ResNet for acupoint localization on the hand and forearm, demonstrating HRNet's precision. Compared to ResNet, HRNet, with its high-resolution architecture, captured the fine details of acupoint positions more accurately. On a dataset with annotated arithmetic mean values by technicians, HRNet showed clear advantages. Even with low-resolution images (256 × 256), HRNet maintained a low average distance error. The HRNet-w48 model outperformed ResNet not only in various metrics but also in comparison with expert annotations, exhibiting superior localization accuracy.
Acupoint localization based on transformerTransformer is a highly influential deep learning architecture that has gained significant attention in recent years. It consists of modules like multi-head attention, feedforward neural networks, normalization, and residual connections. Widely used in sequential tasks like natural language processing, it has also expanded to visual tasks and more. Transformer relies on the attention mechanism, which assigns attention weights based on the correlation between elements in the input sequence. Unlike RNNs and CNNs, it allows for direct parallel computation and excels at capturing global features. In handling long sequences, Transformer captures long-range dependencies via attention, avoiding gradient issues, and significantly reducing training time through parallel computation. Its strong versatility and scalability make it suitable for a variety of tasks.
Li et al. [54] proposed AIR-Net, a Transformer-based acupoint image registration network for automatic acupoint recognition and localization of 10 acupoints on the back of the hand. The network combines CNN and Transformer, using ResNet-50 for feature extraction and Transformer to learn the relationship between image pairs and acupoint positions. To ensure independent handling of acupoints and coordinate acquisition, the Transformer decoder removes the self-attention mechanism to prevent mutual interference, and the coordinates are then predicted through a fully connected layer. The self-attention mechanism in the Transformer encoder learns dependencies at different positions, compensating for CNN’s locality issues, thus capturing global features more effectively and improving localization accuracy. The experimental results showed an accuracy rate of over 90%, outperforming methods like T2RN and ResNet-101. It demonstrated good generalizability for images with different skin tones, orientations, and nails painted. However, the complexity of the Transformer structure makes the model large, and less robust in challenging conditions like cluttered backgrounds or poor lighting.
Yang et al. [55] proposed a keypoint detection network, AL-WFBS, for the localization of 84 acupoints on the human back with weak surface features. The architecture is based on the Detection Transformer (DETR) and mainly improves its Transformer module. A CNN is used to extract multi-scale features, which are then fused through a mixed encoder. The network employs an IOU-aware query selection mechanism to provide initial queries to the Transformer decoder. The decoder and auxiliary prediction head iteratively optimize the model, and the multilayer perceptron (MLP) and multi-head heatmap module perform acupoint classification and position regression to mitigate quantization errors. The method achieved an average precision error (AAPE) of 9.29 pixels (equivalent to < 1 cm physical distance) and PCK@0.05 (Percentage of Correct Keypoints at threshold 0.05) of 0.93, outperforming PVT/Swin-pose methods in accuracy. However, with an input resolution of 192 × 256 and GFLOPs of 151.8, the inference speed reached 13 FPS (72.7 ms per frame), barely meeting real-time requirements. This latency is attributed to the computational overhead of the hybrid encoder-decoder structure and the computational demands of heatmap regression. Future work should focus on optimizing lightweight deployment for clinical robotics applications.
Acupoint localization based on YOLOv8-PoseYOLOv8-Pose is the most frequently used version in the YOLO series for keypoint detection. It inherits the high efficiency and accuracy of the YOLO family. The model uses a single-stage detection approach, combining object detection and keypoint detection tasks, simplifying the detection process and improving detection speed. This allows for rapid keypoint localization in real-time applications. Additionally, YOLOv8-Pose offers excellent scalability and adaptability. By improving modules such as backbone, neck, and head, it can flexibly handle keypoint detection tasks in various scales and complex backgrounds. It is widely used in fields like human pose estimation, facial expression analysis, and more.
Malekroodi et al. [57] applied YOLOv8-Pose to hand and arm acupoint localization, successfully identifying 5 acupoints using a data-driven method. As data-driven methods are direct localization and end-to-end, they built a dataset of 5997 annotated arm acupoint images from 194 participants. Various data augmentation techniques were applied to enrich the dataset, and the weights of the original YOLOv8-Pose model were fine-tuned using transfer learning, which enhanced the model's generalization and robustness. Under a 640 × 640 resolution, the average distance error for the 5 acupoints was less than 5 mm. They also developed an app that shows real-time acupoint locations, proving the method’s accuracy and real-time capability.
Yuan et al. [58] proposed the YOLOv8-ACU model for facial acupoint detection, which addresses the differences in facial acupoint features and human pose detection, as well as the high accuracy required for facial acupoint detection. The model mainly improves three parts: firstly, it adds the efficient channel attention (ECA) mechanism to the backbone network, enhancing the model's ability to extract global acupoint features. Secondly, it uses the Slim-neck module in the neck part, improving the detection of acupoints at different scales while reducing computational complexity. Finally, the loss function in the detection head is changed to generalized intersection over union GIoU to further improve detection accuracy. The experimental results show that YOLOv8-ACU outperforms models like YOLO-pose, YOLOv7-pose, and YOLOv8-pose in terms of accuracy, while also reducing model parameters and computational complexity. It demonstrates better performance and real-time capability in facial acupoint detection tasks.
Acupoint localization based on the MediaPipe frameworkMediaPipe is an open-source multimedia processing framework developed by Google, which is highly versatile and adaptable for tasks involving images, videos, and audio. It offers developers a wealth of pre-trained models and reusable components, enabling rapid prototyping of applications. MediaPipe contains many efficient combination modules for applications such as object detection and facial landmark detection, and it also provides trackers and visualization tools for performance analysis and troubleshooting. Furthermore, it supports cross-platform deployment, allowing developers to test on desktop environments and then deploy to mobile devices, with easy component replacement for performance optimization.
Malekroodi et al. [57] not only proposed an acupoint localization method based on YOLOv8 but also developed an approach based on the MediaPipe framework, combining keypoint detection with proportional mapping for acupoint localization. They selected 20 commonly used facial acupoints and 18 hand acupoints. By utilizing MediaPipe’s FaceMesh and Handpipelines, they obtained keypoint coordinates for the face and hands. To address differences in acupoint visibility and localization accuracy from different poses or perspectives, they applied different indirect localization methods. For the hands, they divided the views into front, inner, outer, and rear, while for the face, they used central, left, and right perspectives. Using the detected keypoints as the foundation, they calculated acupoint positions based on traditional acupuncture literature's dimensional measurements. The final predicted acupoint average error was 5.58 pixels, approximately 0.3 cm, and the results could be displayed in real-time using an app.
Wei et al. [60] developed an AR interactive system for acupoint analysis, which provides users with an intuitive display of acupoint positions, helps them learn and understand acupoint knowledge, and offers diagnostic support through large language models and online doctors. The system leveraged the edge computing capabilities of the Jetson Nano J1010 development board, combined with a custom hand recognition model and MediaPipe technology to achieve acupoint localization and interaction. Similar to Malekroodi et al., the system relied on MediaPipe’s provision of 21 hand keypoints and 468 facial keypoints in 3D. Using a custom acupoint mapping algorithm, the system calculated acupoint positions based on these keypoints’ coordinates, relative distances, and mathematical functions like cross products and dot products. This allowed for accurate acupoint display on AR devices, with scaling based on distance. In situations where the hand rotated or stretched, the acupoint display accuracy reached 95.7%, providing users with an intuitive visualization of acupoint locations and assisting them in learning and understanding acupoint knowledge.
Acupoint localization based on the OpenPose libraryOpenPose is an open-source real-time multi-person 2D pose detection library developed by the University of California, Berkeley (CMU). Compared to the MediaPipe framework, OpenPose uses non-parametric Part Affinity Fields (PAFs) to learn the associations between body parts and individuals in an image. This allows for more accurate multi-person pose detection in complex scenes, handling issues such as occlusion and body intersections. However, OpenPose tends to be slower in processing compared to other frameworks.
To address the needs of TCM massage, Lee et al. [62] developed a hand acupoint massage guidance method based on OpenPose keypoint detection and the proportional method. They also developed a corresponding app that can indicate acupoints and massage techniques based on the user’s condition. Using the OpenPose library, they first identified 20 keypoints on the back of the hand, then calculated acupoint positions based on the relative position of these keypoints according to TCM theory. While there was some error, it remained within an acceptable range considering the scope of the acupoint massage. The app, deployable on mobile phones, provides convenience for patients who can use hand acupoint massage to alleviate pain or treat diseases, offering personalized guidance for acupoint massage.
Wang [63] addressed the problem of automatic acupoint localization for intelligent moxibustion by designing a hand and arm acupoint detection method based on Lightweight-OpenPose and bone measurement methods. Lightweight-OpenPose is a lightweight model derived from OpenPose, with 85% fewer parameters but comparable performance. The researcher chose the arm as the measurement region for bone dimension and first segmented the arm area by converting the color space. Then, the minimum-area bounding box was used to obtain and correct the arm’s offset angle. Using hand width and gradient features, along with corner detection, the wrist and elbow crease positions were determined, with the distance set at 12 cun. The Lightweight-OpenPose model was used to locate baseline acupoints on the hand, and bone measurement methods were applied to calculate the coordinates of target acupoints. Ultimately, 6 acupoints were localized with an average accuracy of 95.8%, and the image processing speed was approximately 27 FPS, satisfying real-time requirements.
Multi-algorithm integration for acupoint localizationDifferent algorithms excel in their respective domains: YOLO is renowned for object detection, HRNet is proficient in keypoint detection, and U-Net excels in image segmentation. Leveraging these strengths, researchers have developed multi-stage integrated approaches to achieve more accurate acupoint localization. Typically, these methods first use object detection or image segmentation to obtain local images of interest, followed by keypoint detection on these local images. Finally, based on the detected key points, the bone measurement or finger cun measurement is used to precisely locate acupoints.
Yu et al. [64] proposed a hand acupoint localization method that combines YOLOv3 object detection and MediaPipe keypoint detection technology, specifically for difficulties in Mongolian acupuncture localization and its inheritance. They successfully localized 5 hand acupoints. The procedure involved the following steps: first, the YOLOv3 algorithm was used to identify the regions of the palm and back of the hand; then, the MediaPipe framework was employed to obtain the coordinates of 21 keypoints on the hand; next, the average method and polynomial fitting method were used to determine the distance and angular relationships between the hand keypoints and acupoints; finally, the specific coordinates of the acupoints were computed based on these relationships. Experimental results showed that the errors in the localization of the 5 acupoints were all within 1 cm, proving the efficiency and accuracy of this method.
Wang et al. [65] introduced a hand acupuncture point localization method based on a dual-attention mechanism (SE and CA) and a cascaded network model to improve the accuracy and robustness of acupuncture point localization. The method first used an improved SC-YOLOv5 model with dual attention mechanisms (SE and CA) to detect hand regions and generate bounding boxes. These bounding boxes were then input into a heatmap regression algorithm using HRNet as the backbone network to detect 21 hand keypoints. Finally, based on the TCM “MF-cun” (middle-finger width) measurement method, OpenCV was employed to calculate the coordinate relationships between keypoints and acupuncture points, achieving precise localization. Experimental results indicated that the method exhibited strong robustness in complex scenarios, with a mean offset error (MOE) of only 0.0269, a reduction of over 40% compared to other methods, while maintaining real-time performance (35 FPS).
SummaryAs shown in Table 2, acupoint localization algorithms mainly cover three categories: generative adversarial networks (GAN), key point detection, and image registration. Among them, key point detection methods are the most widely applied, with a typical workflow involving the identification of key points first, followed by localization through traditional techniques such as the bone proportional measurement. In key point detection algorithms, HRNet stands out for its high precision in complex regions and low-resolution images, being widely used in multiple parts such as the face, back, and hands. Transformer can utilize global context to construct stable spatial relationships, making it particularly suitable for the back area with dense acupoints and also applicable to meridian construction. YOLOv8-Pose, MediaPipe, and OpenPose excel in fast computation and convenient deployment, fitting mobile device scenarios. Specifically, YOLOv8-Pose strikes a good balance between speed and accuracy, often used for distinct features like the face and hands. OpenPose specializes in full-body and hand key point detection, commonly seen in back and hand acupoint localization. Although MediaPipe can detect facial, hand, and full-body key points, its limited number of full-body key points and less-than-ideal positioning accuracy make it more applied to facial and hand acupoint localization. While GAN can be used for acupoint localization due to its image generation capability, its core value lies in data augmentation, effectively addressing the challenge of insufficient training data. Image registration-based methods, similar to template matching, show good adaptability to different postures and skin tones, but insufficient data training easily causes positioning deviations, leading to relatively fewer studies in this field. Since each algorithm has its own advantages, rational selection, combination, and optimization according to specific application requirements are particularly important.
Table 2 Summary of acupoint localization algorithmsIt is also important to note that keypoint detection-based algorithms include methods based on the Dlib library [66] and 3D Morphable Models (3DMM) [67]. However, in the field of acupoint localization, these two methods still rely heavily on machine learning components. Dlib excels in facial keypoint detection, while 3DMM offers strong representational power by simulating parameters such as shape, reflectance, and lighting, making it highly valuable for further research. Therefore, the deep learning components of these two technologies are worth exploring and expanding upon for more advanced acupoint localization methods.
Localization with various strategiesTo enhance DL-based acupoint localization accuracy, researchers have proposed various approaches with distinct strategies, each emphasizing different aspects of localization precision, real-time performance, and robustness. This paper categorizes these methods into six types based on three criteria: whether reference points are used (direct vs. indirect methods), regression formats (coordinate regression vs. Gaussian heatmap-based methods), and algorithm structures (top-down vs. bottom-up approaches). Analyzing these strategies provides better understanding of their principles and applicable scenarios, facilitating optimal method selection.
Acupoint localization based on direct methodThe direct localization method leverages the powerful feature extraction and pattern recognition capabilities of deep learning, enabling acupoint localization directly from images without complex intermediate processes. The accuracy of this method primarily depends on three key factors: firstly, the expertise of the acupoint annotators; secondly, the diversity of the acupoint dataset; and lastly, the learning capability of the model. Currently, the model’s learning ability largely follows the scaling laws, meaning that within the limited scope of acupoint localization models, the quality and diversity of the data are especially crucial.
Compared to indirect methods, the direct localization method has the advantage of being simple, direct, and efficient, making it suitable for fast and automated acupoint detection tasks. Moreover, the acupoints in th
Comments (0)