In this feasibility study, we trained two deep learning networks using video data from robotic cardiac surgery wet lab simulation training, employing a novel AI algorithm. The AR network demonstrated reliable performance in accurately classifying surgical actions, even with a limited dataset. The SA network requires more data to become a useful model for performance evaluation. When combined, these deep learning models can facilitate automated post-procedural assessments in robotic cardiac surgery simulation. We are the first to present a deep learning-based approach for classifying surgical actions and skills in robotic cardiac surgery using only video data.
The overall accuracy of gesture recognition methods is reported to be approximately 80% in mixed datasets that use kinematic signals and video data [29]. Deep neural networks capable of automatically capturing complex temporal dependencies in surgical motion appear to perform better than traditional computer vision methods [30, 31]. State-of-the-art models that use video data for robotic action recognition, such as 3D ConvNet [22] and the unified Surgical AI System (SAIS) [23], have achieved high skill classification accuracies ranging from 95 to 100%. However, the 3D ConvNet model was trained and tested on the JIGSAWS [29] dataset collected from 8 right-handed subjects performing 39 suturing, 36 knot-tying, and 20 needle-passing in a dry lab. The SAIS dataset is not publicly available, and the model was specifically trained, validated, and tested on urological robotic procedures. Our AR network, trained on cardiac surgical tasks conducted by 19 subjects with varying hand dominance, demonstrated high performance based on comprehensive evaluation metrics, including recall, precision, F1 score, and confusion matrix, comparable to the aforementioned models. The K-fold cross-validation, which provides a more generalized estimate of how the model would perform on unseen data, revealed strong performance (a mean accuracy of 98%), demonstrating the feasibility of DL-based recognition of surgical actions. Unlike models trained on the JIGSAWS dataset, which focuses on generic dry lab tasks, our AR model trained on the procedure-specific cardiac surgical tasks, such as the internal thoracic artery dissection, making the network applicable to robotic cardiac surgery.
However, the skill assessment DL network did not achieve the desired characteristics, even after additional fine-tuning and the addition of an extra dense layer, which had proven effective in another study using the same algorithm [28]. One possible explanation for this underperformance may be the limited number of experienced robotic surgeons—only four, compared to 15 novices. This disparity may lead to skewness in the variation that the skill assessment model attempts to learn. This is evidenced by the higher standard deviation of cross-validation for skill assessment performance compared to that of the AR network across the folds (16.8 versus 1.5, respectively). This small, unbalanced dataset likely limits the SA model’s generalizability. A potential solution would be to record more exercises performed by expert robotic cardiac surgeons to gather additional data and retrain the SA network. However, several challenges complicate this approach. These include the limited number of expert surgeons available globally, their unavailability for training sessions, the absence of a standardized robotic cardiac training curriculum [25, 32], high costs, restricted access to animal models, and the availability of robotic platforms for training [26]. These factors make implementing this solution quite difficult. Prior studies in the field of surgical data science have produced varying dataset sizes. For example, Kiyasseh et al. [23] analyzed 78 robot-assisted radical prostatectomies performed by 19 surgeons. In contrast, large-scale image recognition datasets, such as the ImageNet [33], contain over 1 million labeled images across 1,000 object categories. Developing robust, scalable models will require large datasets, ideally drawn from multiple institutions, and procedure types. Key considerations include ensuring annotation consistency, addressing patient privacy, and developing shared platforms to enable widespread data sharing and model training [34, 35]. Another challenge in collecting data for SA is that labeling based solely on prior experience is a weak proxy for actual skill. As a result, out of a total of 435 videos used for AR, only 69 were selected for SA. These recordings were chosen because their scores on TBS and GEARS demonstrated sufficient validity evidence [25]. This approach ensured that only recordings with clearly differentiated performance levels were used for AI analysis. We did not include the ITA dissection for SA, as both TBS and GEARS metrics appeared to be unreliable in distinguishing between experienced and inexperienced robotic cardiac surgeons. Future research should focus on defining what constitutes an “expert” robotic cardiac surgeon whose performance is deemed “acceptable” for training AI models, as well as determining which authorities will make these assessments.
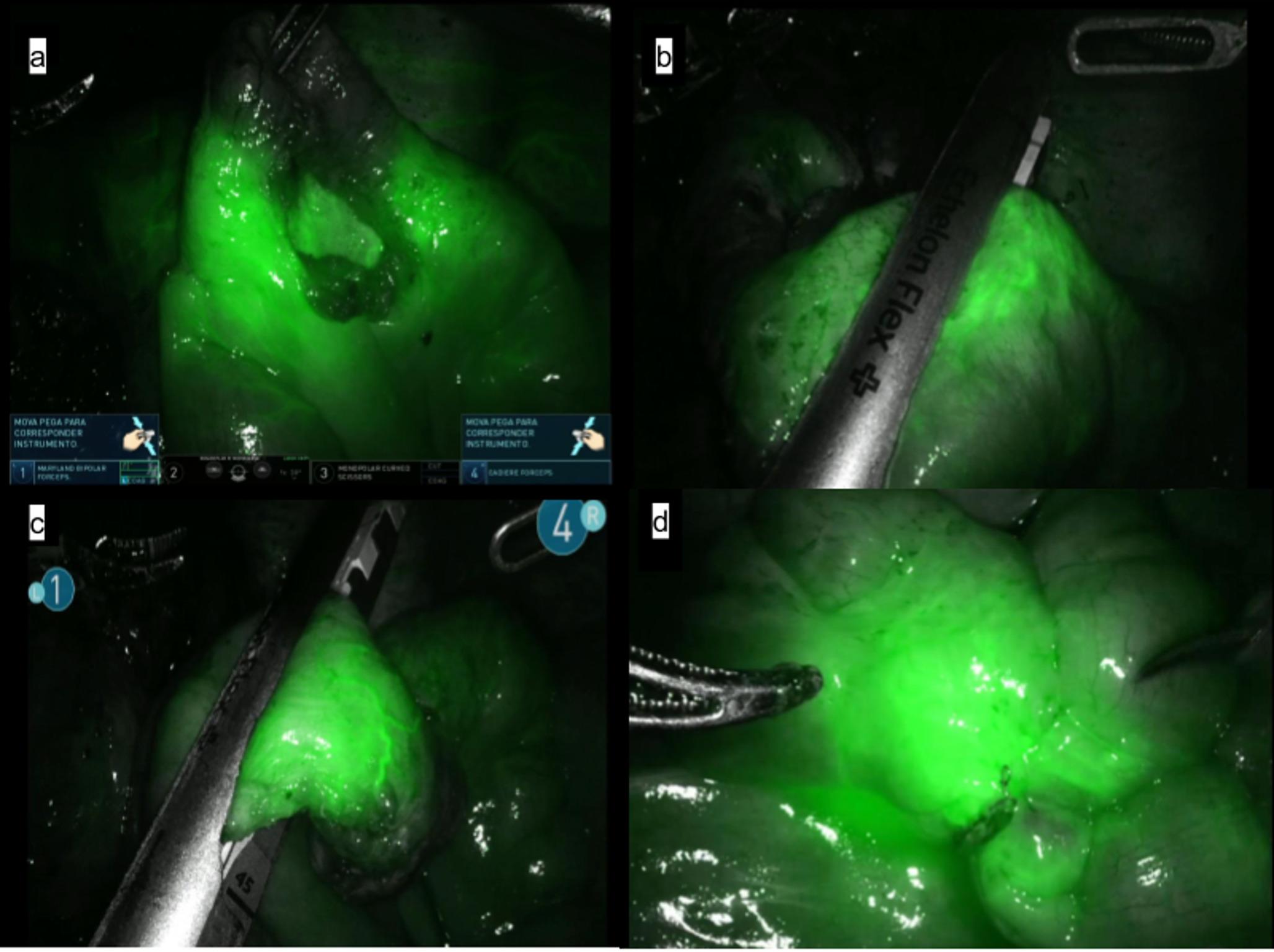
While RAS is performed by human surgeons, the development of AI technologies for surgical applications is usually carried out by biomedical engineers or computer scientists [31]. If the models are not presented in a way that surgeons as non-specialists can easily understand, they may struggle with the scientific terminology, leading to a reluctance to use these tools [24]. The Grad-CAM is used to highlight the areas the network focuses on during training (Fig. 4). It aims to enhance the interpretability of deep learning algorithms, as a lack of clear explanations for their functioning can hinder their adoption in healthcare [36, 37]. Another significant component in our network is LSTM layer, which enables the model to recognize patterns over time rather than just isolated frames [28]. When considering the temporal aspect of surgical videos, the model can analyze smaller, sequential segments of the procedure rather than relying on single-frame analysis. This allows for more granular assessments of surgical performance, enabling the evaluation of each moment during surgery. Recent studies have demonstrated the effectiveness of this temporal modeling, using LSTM method among others [23, 28]. As a result, visualizations like procedural plots or surgical skill profiles have emerged, illustrating both specific parts and entire procedures [23]. Importantly, this method moves us closer to real-time skill assessment, where the temporal aspect is needed for continuous feedback during an ongoing surgical procedure. By moving beyond static frame analysis and embracing the dynamic nature of surgical performance, LSTM-based models provide a more nuanced and clinically relevant understanding of technical skill.
In our study, shorter five-frame sequences were chosen for action recognition, in line with previous research indicating that surgical gestures can be reliably classified within 2–12 s of motion [31, 38]. These shorter clips are often sufficient for detecting specific motor patterns or transitions, while also reducing computational demands. In contrast, skill assessment is a more nuanced and temporally extended task. Prior studies have used sequences of 10 s, showing that skill levels can be differentiated within this timeframe [22, 39]. We, therefore, selected 10-s clips to strike a balance between capturing meaningful skill-related dynamics and maintaining manageable sequence lengths for training.
Although wet lab training is an essential component of robotic cardiac surgical education [40], and since there are currently no virtual reality simulators that encompass cardiac surgeries [41], we selected a cardiac wet lab simulation model [25] for our study. We recorded surgical performance data from the da Vinci Xi (Intuitive Surgical) robotic console. However, the method [27] we used for video data extraction and preparation can easily be applied to any other robotic system. This makes the data collection independent of the specific surgical system, especially since more surgical robots have emerged recently [42].
Currently, there is no standardized curriculum for robotic cardiac surgery training in either Europe or North America [10, 32, 43]. However, there is widespread agreement that wet lab simulation is a crucial component of this training [40]. Training needs assessment. The previously discussed challenge of the availability of experienced robotic cardiac surgeons for assessment drives the search for robust and reliable alternatives. While AI-based models have been rigorously investigated in other surgical specialties to address this issue, the optimal solution has yet to be determined [19]. An ideal AI-based system could automatically identify different stages of surgical performance from videos by analyzing surgical activities, gestures, and skill levels, providing real-time feedback to trainees and reducing their reliance on expert surgeons [20, 23]. Our feasibility study introduces a new DL model trained on robotic cardiac surgery simulation data, which could potentially be used for post-procedure feedback analysis. While the AR network demonstrated its feasibility, further testing is necessary to determine whether these findings are generalizable to unseen videos from different surgeons. A more comprehensive effort, including stronger annotation criteria, richer task diversity, and more rigorous evaluation would be necessary to enhance the model performance. Future research would benefit from a multicenter approach to gathering more data, addressing the challenge of having a limited number of experienced robotic cardiac surgeons at a single center.


Comments (0)