
Remember me






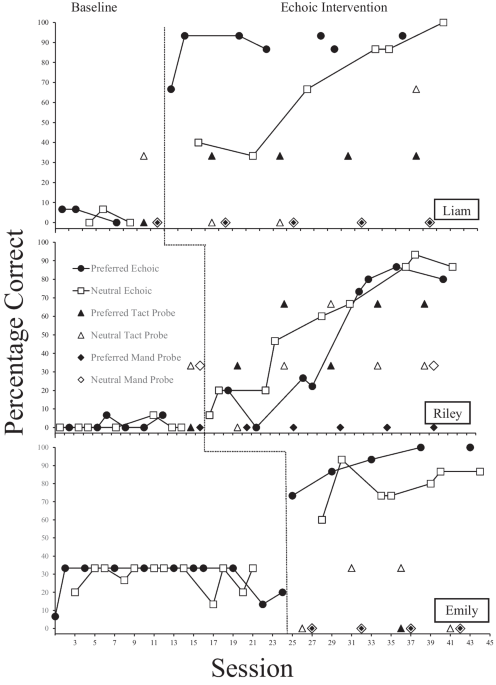

While some research has used animated videos to target attending, little has been completed for social skills (Kellems et al., 2020). We found that three participants met mastery criteria for both human and animated videos (i.e., Mark, Ray, and Kadeem). Two participants only met mastery criteria for the human video (i.e., Isaac and Maria), and one participant only met mastery criteria for the animated video (i.e., Leon). Gavin did not meet mastery criteria for either video modeling intervention.
Prerequisites for successful responding through video modeling involves attending to stimuli, engaging in immediate and delayed imitation, and overall interest in watching videos (MacDonald et al., 2015). Ho et al. (2019) identified a minimum score of 17 for motor imitation for targeting social skills with children with ASD using video modeling. All participants completed most of the assessment motor imitation items and exceeded this score (Table 1). Isaac and Mark were the only participants to obtain a score on the intraverbal assessment. Mark often engaged in echoics and motor imitation during the videos, which seemed to transfer to intraverbals (from echoics) when tested. His responding met mastery criteria for both types of video modeling interventions, while Isaac’s responding only met mastery criteria for the human video. Isaac responded with, “I don’t know,” which could be an intraverbally correct response outside the study but was an operationally incorrect response. Reinforcement history for responding “I don’t know” could have maintained Isaac’s responding, despite being put on extinction with no consequences for responding. Thus, participant learning histories that may affect acquisition should be considered when identifying target behaviors (Kay et al., 2020). While the video modeling literature cites baseline data, assessments for intraverbals prior to intervention has not been included. Consequently, identifying prerequisites for an intraverbal repertoire can be challenging. De Souza et al. (2018) selected a VB-MAPP intraverbal subtest (Sundberg & Sundberg, 2011) score between 50 and 70 for inclusion to teach advanced intraverbals. Future research could consider a more conservative score for inclusion to teach initial intraverbal acquisition.
Anesha and Maria occasionally engaged in echoics, while Mark routinely engaged in echoics and motor imitation during the videos. Unlike the cited research, some participants in this study who met the minimum score for inclusion did not demonstrate acquisition of motor imitation for FE and BE. While a 1-step motor-immediate imitation assessment was implemented for this study, an assessment for delayed imitation assessment was not and participants were required to first attend then later emit the intraverbal (i.e., VR) and two motor imitations, (i.e., FE and BE). Delayed responding during baseline could be investigated as a potential prerequisite for inclusion in future video modeling investigations during a motor imitation assessment. After demonstrating a motor imitation, for example walking a doll, and prompting the participant to do the same, allow 3 s to pass and prompt him/her to do the same with no modeling. One could assume that the higher the preassessment motor imitative score, the more likely the acquisition, but this was not apparent. Future research could consider other assessments for motor imitation, such as the VB-MAPP (Sundberg, 2008) and the ABLLS-R (Partington, 2006).
Some participants’ responding was visibly different from the first to second interventions, with much more responding occurring in the latter. These could have been examples of carryover effects (Barlow & Hayes, 1979), which is the effect of one intervention on another contiguous one. Since the order of the interventions was counterbalanced across participants, it may not have been that one intervention was more effective but carryover effects. The same could be possible for Isaac, who met mastery criteria only for the second. Future research could minimize carryover effects with a true alternating treatment design where interventions follow one another in an unpredictable fashion. One video could be implemented at a time but alternated randomly across sessions.
While Anesha did not meet the minimum 6/9 responses for any session, she responded during more sessions in her first intervention than second, thus discounting carryover effects. It is possible that the first animated video served as an abolishing operation for the second human intervention due to lack of consequences. Perhaps the videos were not reinforcing enough and the lack of consequences put the responses on extinction. Thus, Anesha’s first video had an abative effect for the second. Weyman and Sy (2018) used a praise preference assessment and cited faster acquisition during enthusiastic praise conditions, relative to neutral and no praise conditions. A similar reinforcer preassessment could be used to evaluate the reinforcing effects of physical expressions and voice fluctuations (as implemented in the videos) over attending and could be employed to bolster control through providing secondary measures.
In addition to the intraverbal and motor imitation, an echoic assessment was conducted prior to intervention but mand and tact repertoires were not assessed. Emergent intraverbal behavior typically begins following the acquisition of mand and tact repertoires for neurotypical children (Sundberg, 2008). Thus, established mand and tact repertoires could make the emergence of intraverbals more likely. Future research could identify potential prerequisites for these operants and use the VB-MAPP (Sundberg, 2008) to identify baseline levels for intervention inclusion.
As previously noted, two participants appeared to have higher VR responding compared to FE and BE, four responded the same comparatively, one responded less with VR, and one only responded once. Considering that intraverbals (VR) are typically acquired later than echoics and motor imitation (i.e., FE, BE; Sundberg & Sundberg, 2011), future research could consider using a denser schedule of reinforcement or more salient consequences for correct VR. A differential outcome procedure could be applied where a successful VR response could be paired with a specific and not a generalizable reinforcer (Trapold, 1970). Whereas FE and BE responses could be paired with praise, VR could result in a specific edible, tangible, etc. Furthermore, depicting the dependent variables being reinforced in the video could aid in acquisition.
Some of the operationally defined correct responses may have been incompatible with behaviors in the participants’ repertoire. For example, some FE responses were defined as baring teeth, scrunching his face, etc. Kadeem smiled during every trial. Thus, those facial expressions required him to discontinue smiling and engage in the operationally defined FE. Although he may have been capable of imitating the FE prompts of the model, his continued smiling made it difficult. Future research could identify target behaviors (both FE and BE) that are not incompatible with a participant’s current behavioral repertoire.
This study did not present consequences for correct responses but did present differential reinforcement in the form of praise for compliance. Although video modeling can be effective without the consequential presentation of reinforcement (Lee et al., 2020), reinforcement (by definition) makes behavior more likely to occur. No programmed consequences were presented during baseline in this study, which differs from the cited research in that they provided reinforcement during baseline to avoid inhibition of correct responding. Although watching videos could be a reinforcing activity, it may not be for children with ASD (Ho et al., 2019). Thus, future research could include reinforcement for correct responding during baseline. Additionally, as each of the three presented discriminative stimuli had nine possible correct responses, future investigations could provide specific-praise for correct responses (i.e., “good job touching your head, closing your eyes,” etc.). In specifically reinforcing an intraverbal, a participant would receive additional instruction relative to facial and body expression behaviors, which would not receive behavior-specific consequences. This could increase the acquisition of intraverbals in future studies quicker than facial and/or body expressions but bias the acquisition because of the specific-praise, which could serve as discriminative stimuli for further trials. Although presenting reinforcement for correct intraverbal responses could be a confound because all correct responses after the initial response that contacted reinforcement could be considered as due to reinforcement rather than the video model, the very first occurrence of the imitative response would be attributed to the video model and not reinforcement.
The participants may have not experienced consistent exposure to the independent variables, as some watched a portion rather than the entire video. Thus, differences in results could be due to a participant experiencing a larger dose of one intervention over another. Ensuring that participants experience an equal dose of both interventions should have been done to rule out discrepancies as plausible interpretation of treatment effects (Blowers et al., 2021). Future research could include procedures that ensure participants watch all of the behaviors in both videos. For example, if a participant looked away from the video, the clinician could prompt him/her to attend (Charlop et al., 2010) and/or reinforce attending by presenting reinforcement at the end of an attended video.
Some of the procedural selections may have affected results. The mastery criteria selected for the current study may have affected overall maintenance of acquired skills (Fuller & Fienup, 2018). We selected mastery criteria of at least 6/9 correct responses for three consecutive sessions; However, related literature has identified criteria of 7/9 or higher for 2–3 consecutive sessions (Charlop et al., 2010; Charlton et al., 2020; Ledoux Galligan et al., 2020).
In addition to noting the occurrences of echoics and motor imitations across participants, future research could collect data on tacts for identifying the stimuli in the video and the (self) echoics for continuing to repeat the target responses until the relevant discriminative stimulus is presented. These data could provide additional context for evaluating their performance during the assessment. By collecting data on these behaviors during sessions (i.e., occurrence or nonoccurrence of tacts and echoics), one may be able to identify if there is a barrier to learning present (i.e., the lack of these behaviors may suggest lack of attending) that is confounding the assessment. Future research could additionally conduct a barriers assessment to identify variables that can affect learning prior to intervention (Sundberg, 2008). The potential presence of these barriers presents a difficulty with interpreting the current results because it is unclear if the lack of reaching the mastery criteria for each type of intervention was related to the properties of the video itself (i.e., the stimuli of either the human or animated video) or due to a deficit of a skill such as attending that may be a prerequisite skill in order to benefit from video model-based instruction.
Potential discrepancies in the difficulty of acquiring the imitative responses modeled is an additional area that warrants control techniques to ensure that difficulty in acquiring responses is equivalent across targets from the same dependent variable class (i.e., VR, FE, and BE behaviors). The difficulty of acquiring targets could be influenced by the similarity of antecedents across VR, FE, and BE, with more similar antecedents, potentially increasing the possibility of commission errors (i.e., emitting a response that was modeled but to the wrong antecedent [e.g., Isaac saying “moon” in response to the antecedent “four laps around a track is a…”]). The difficulty of acquiring responses may also be increased by the similarity of responses across targets (e.g., two BE targets for Gavin comprised pointing down or pointing at his ears). Length of antecedents and number of behaviors modeled for each dependent variable class could also increase the difficulty of acquisition. Differences in length of the speech-verbal responses across targets could also increase difficulty of learning one target over another. Identifying target behaviors from the same level from the VB-MAPP (Sundberg & Sundberg, 2011) could address this. These behaviors are sequenced and balanced over three developmental levels (0–18, 18–30, and 30–48 months). VR targets could be clustered on the same level for intraverbals and FE and BE could be clustered on the same level for motor imitation.
Targets were identified with the likelihood that they would not be occasioned in their natural settings. In other words, they were not likely to be taught or reinforced outside of the study, so as to maximize experimental control (Fahmie et al., 2023). While these novel targets were identified to minimize the likelihood of type 1 error, they may not have been socially or ecologically valid. Future research could identify targets that have utility across participant settings and assess ecological validity using Fahmie et al.’s (2023) Ecological Validity Research Planning and Evaluation Tool. Additionally, it is possible that the two videos were not distinct enough for participants to distinguish between. Future efforts could exaggerate the differences between videos.
In conclusion, it appears that both interventions have utility for clinicians targeting intraverbals and motor imitation used for conversation and social skills with participants with ASD. Additionally, videos can be used both in a telehealth model and through AI. De Knocker and Toolan (2023) found that ASD interventions implemented through telehealth can be beneficial for both caregivers and children. Furthermore, augmentative communication through AI has potential to increase communication and social skills for people with ASD (Wankhede et al., 2024). Both types of videos, once created, could be used countless times for students with similar learning targets. Additionally, scenarios could be cut and pasted to create individualized videos. Video libraries of myriad scenarios could be generated and shown as human or animated videos for different learners Figs. 1, 2 and 3.
Fig. 1 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Image stills of video interventions. Note. Comparison of actual (human) video modeling stills (left two figures) versus animated video (right two).
Fig. 2 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Animated then Human Video Responding for Issac, Mark, Anesha, and Maria. Note. Diamonds represent generalization probes; squares represent maintenance probes
Fig. 3 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Human then Animated Video Responding for Kadeem, Gavin, Ray, and Leon. Note. Diamonds represent generalization probes; squares represent maintenance probes
Comments (0)