
Remember me
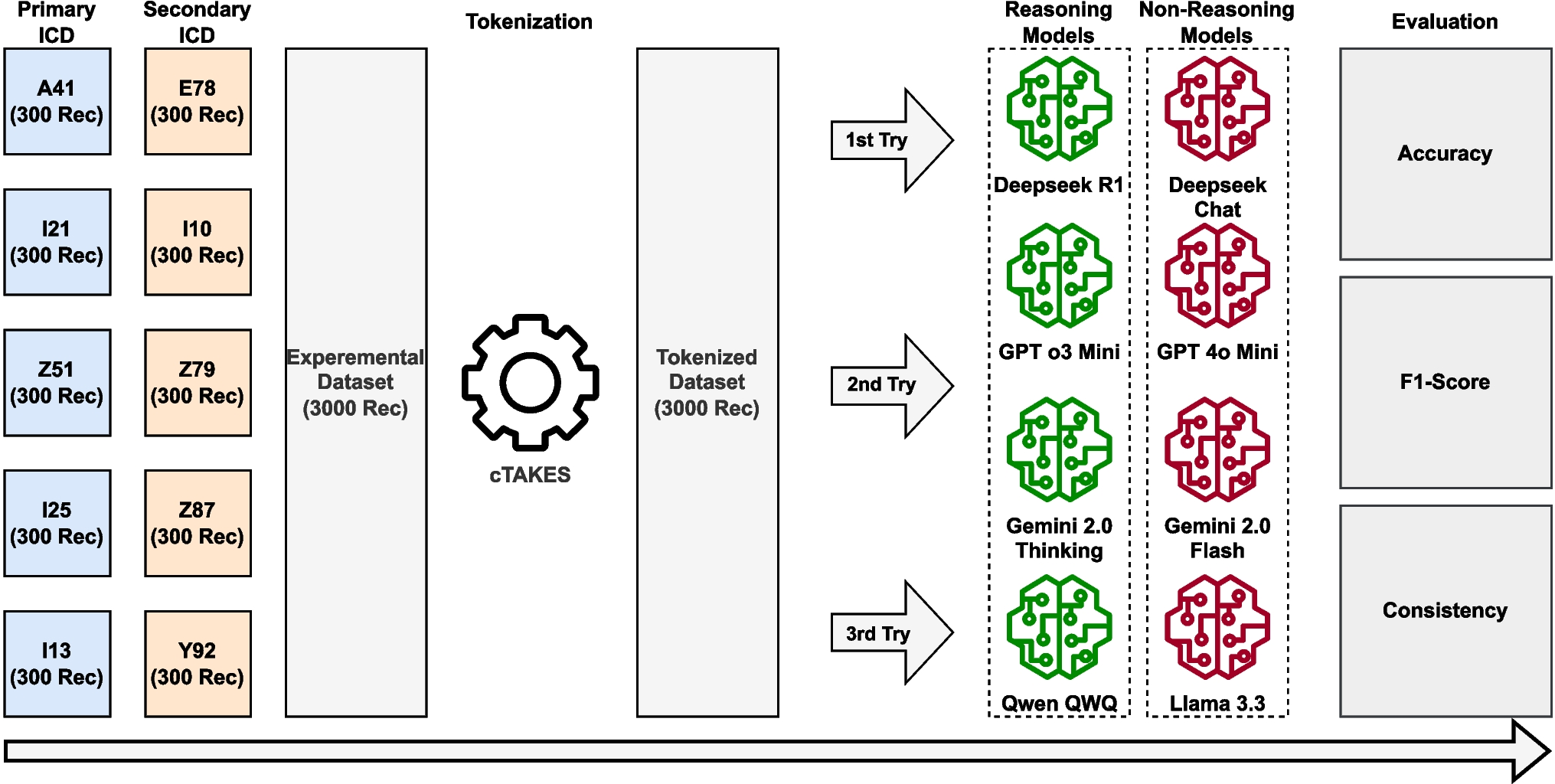

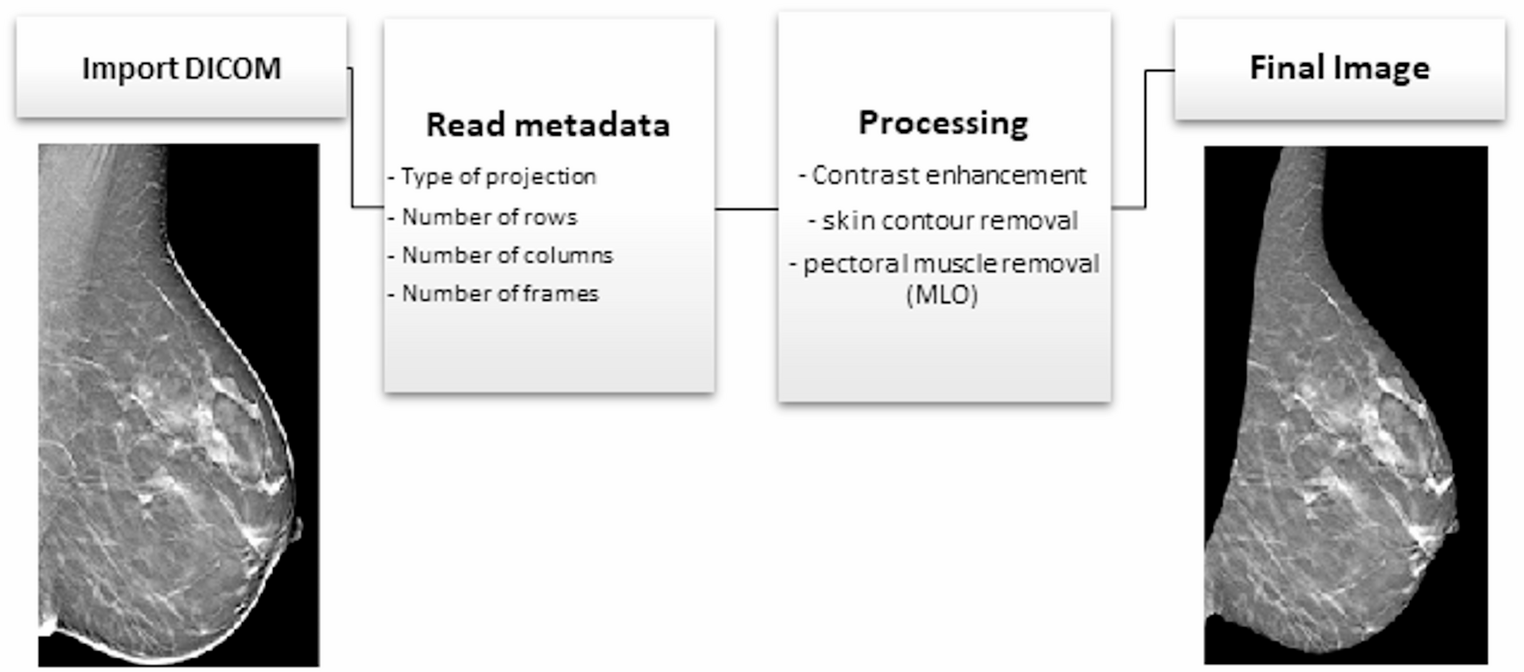
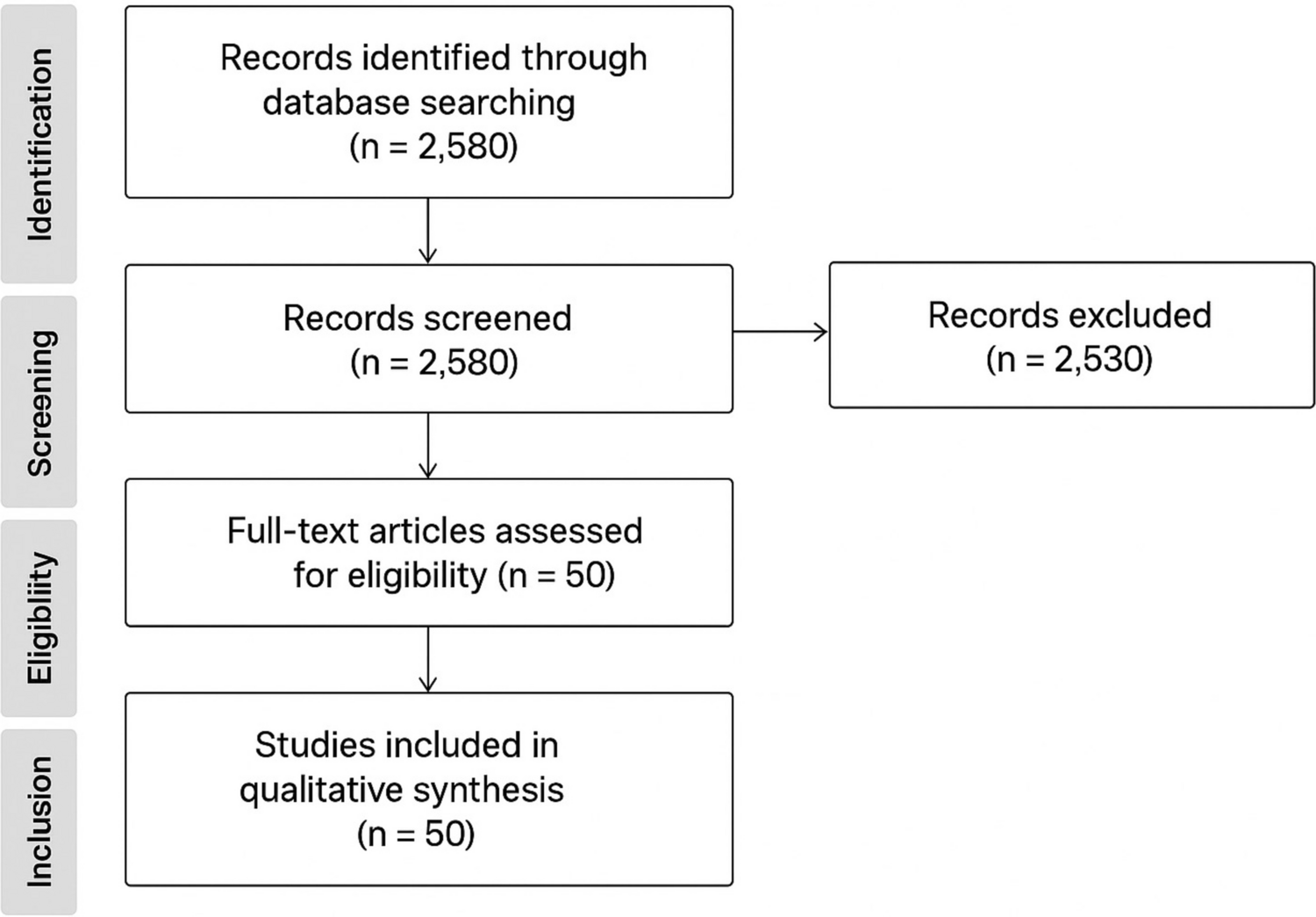
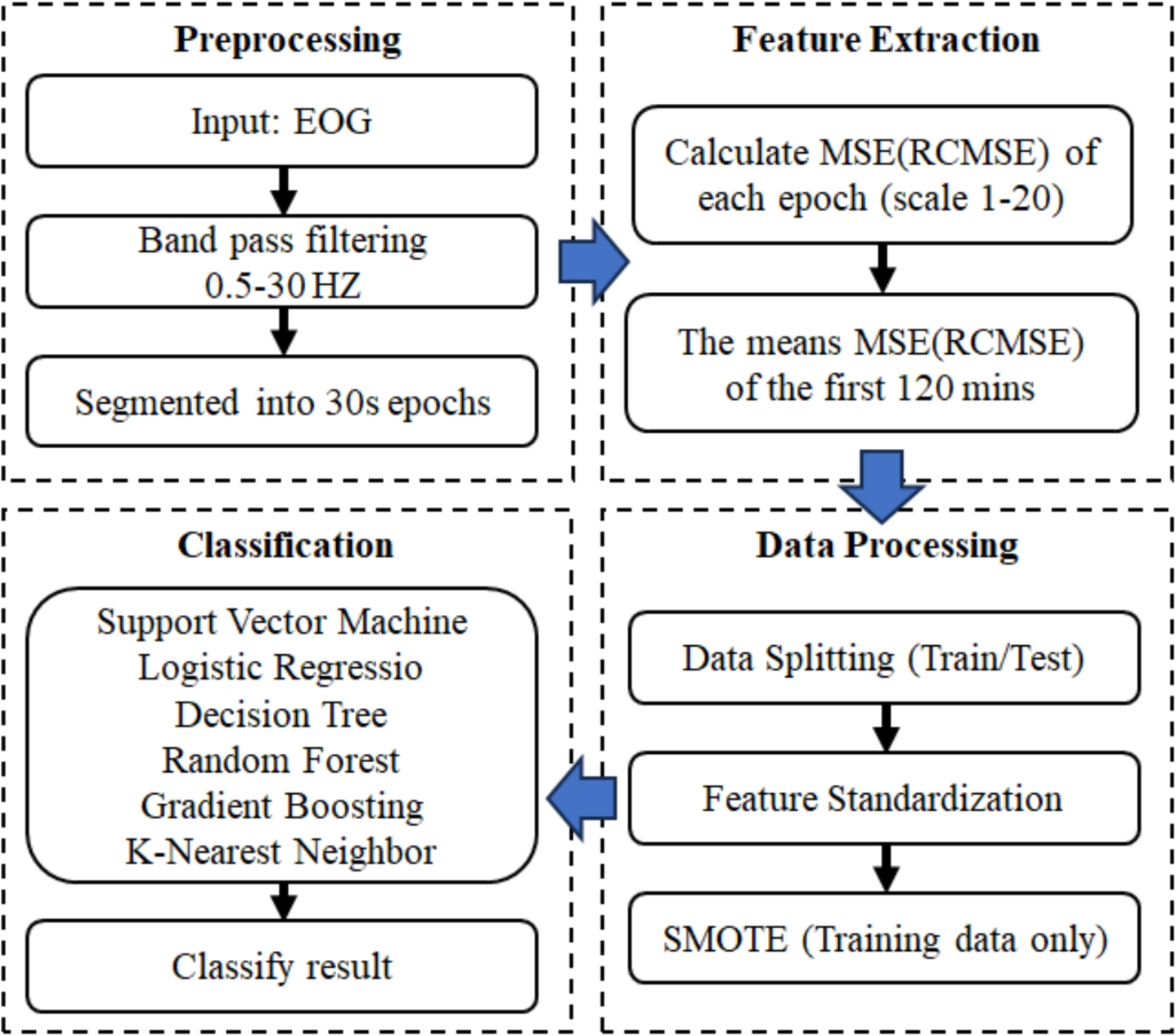

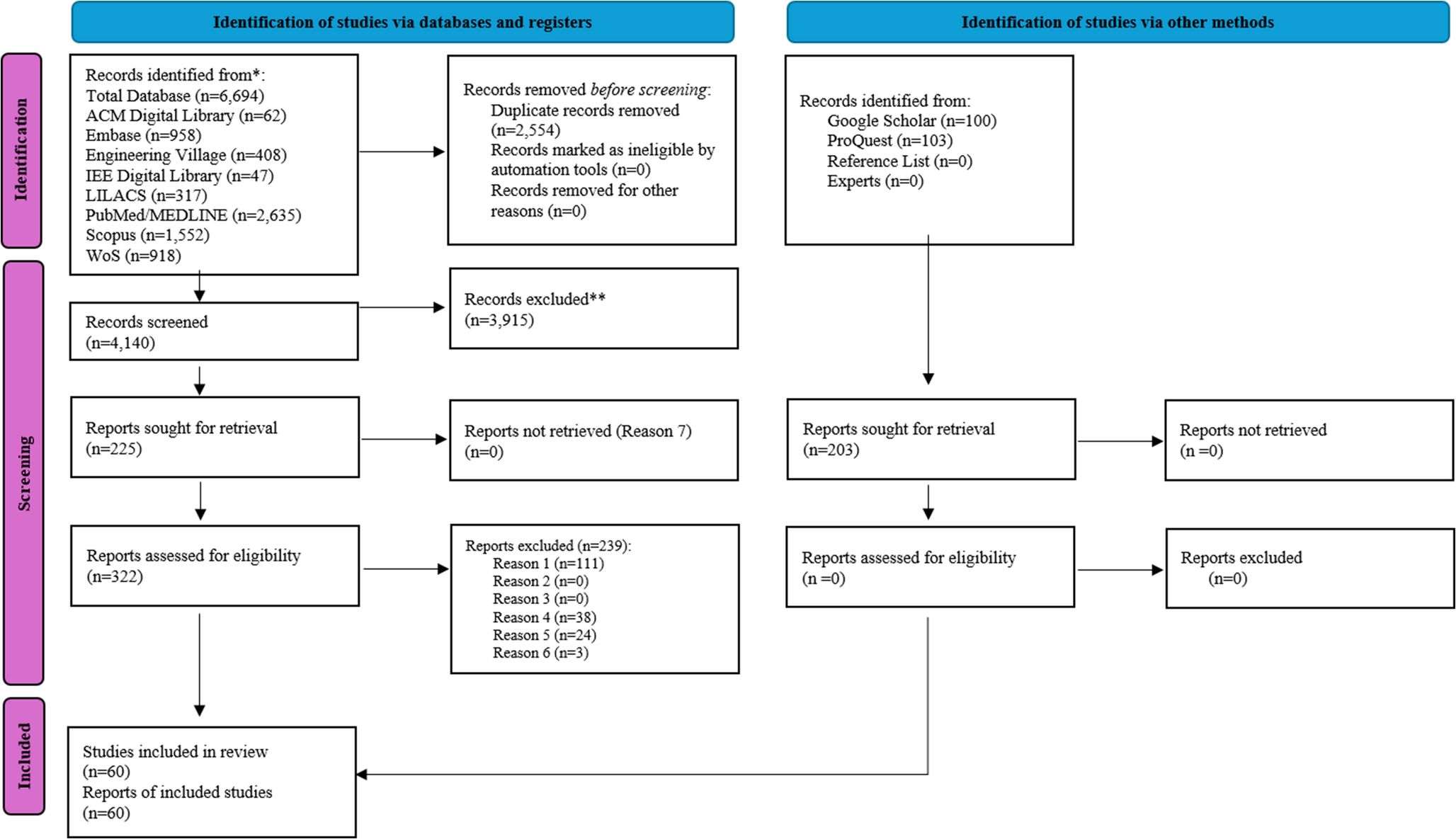
Among the eight LLMs evaluated, Gemini 2.0 Flash Thinking, a reasoning model, achieved the highest overall accuracy at 75% and the highest F1 score at 76%. In contrast, GPT 4o Mini, a non-reasoning model, had the lowest performance among all models, with an accuracy of 64% and an F1 score of 47%. Among the non-reasoning models, Gemini 2.0 Flash recorded the highest accuracy at 72% and the highest F1 score at 71%, while Qwen QWQ had the lowest accuracy and F1 score among reasoning models, with 65% accuracy and 55% F1 score. Table 3 presents the detailed accuracy and F1 scores for each model.
Table 3 Average performance of various LLMs over 3 runs in classifying 3000 clinical discharge summaries from the top 10 ICD-10 codes within the MIMIC IV datasetOverall, the reasoning models outperformed the non-reasoning models in terms of average accuracy and F1 scores. The reasoning models achieved an average accuracy of 71% compared to 68% for the non-reasoning models. Similarly, the reasoning models recorded an average macro F1 score of 67%, whereas the non-reasoning models achieved a lower average macro F1 score of 60%. Figure 2 shows the average performance of the four state-of-the-art reasoning versus four non-reasoning LLMs in classifying clinical documents. These results suggest that, in general, the reasoning models provided slightly better classification performance than the non-reasoning models.
Fig. 2
Average performance of 4 reasoning vs 4 non-reasoning LLMs in classifying clinical documents
4.2 Consistency analysisThe consistency of model performance across the three experiments reveals a varied level of reliability among the different LLMs. Results are shown in Table 3. Models such as GPT o3 Mini and Deepseek Chat at 95%, and Gemini 2 Flash at 91% demonstrate high consistency, with performance largely stable across all three trials. This suggests that these models are robust in classifying discharge summaries, maintaining similar results across multiple runs. On the other hand, models like Qwen QWQ and Gemini 2 Flash Thinking, with a consistency rate of 78%, show significantly lower consistency, indicating greater variability in their performance across the experiments. This variability could potentially indicate issues with stability or sensitivity to different input data or model configurations. Other models such as Deepseek Reasoner at 83%, Llama 3.3 at 88%, and GPT 4o Mini at 89% fall in between, suggesting a moderate level of consistency. Overall, the high consistency observed in certain models like Deepseek Chat and GPT o3 Mini suggests they are more reliable for repeated use in clinical document classification tasks. An analysis of the average consistency based on model reasoning, reveals that non-reasoning models exhibit a higher average consistency of 91% compared to reasoning models, which show an average consistency of 84%. Figure 2 illustrates these findings in detail.
4.3 Detailed performance analysis of various LLMsThe performance analysis of the eight investigated LLMs in classifying ICD-10 codes is presented in two different ways. Tables 4 to 13 list the accuracy, F1 score, and consistency of all LLMs on each specific code. Additionally, Figs. 3 to 12 demonstrate the F1 score of all LLMs vs their consistency, for each code. These results assist in classifying the codes into three categories.
The first category includes codes for which all models demonstrate strong performance in both consistency and F1 scores, as shown in Figs. 3, 5, 7, and 8, exhibiting similar trends and levels of accuracy. This category comprises ICD-10 codes A41, I10, I21, and I25. For these codes, consistency ranges from 67% to 100%, while F1 scores range from 63% to 96%, as shown in Tables 4, 6, 8, and 9. Reasoning models, particularly GPT 3o Mini, stood out in terms of consistency, achieving the highest levels for 3 out of the 4 codes. In terms of F1 scores, both reasoning and non-reasoning models led, depending on the specific ICD code. Notably, GPT 4o Mini achieved the highest F1 score of 96%.
The second category includes codes where consistency remained high and stable across all models, but F1 scores varied significantly, as shown in Figs. 4, 6, 9, and 10. This suggests that while the models consistently made similar predictions, their accuracy in identifying true positive cases varied widely. ICD-10 codes in this category include E78, I13, Y92, and Z51. Consistency scores ranged from 64% to 100%, while F1 scores showed a much wider spread—ranging from 23% to 79% for E78, 30% to 86% for I13, 0% to 20% for Y92, and 4% to 87% for Z51, as shown in Tables 5, 7, 10, and 11. GPT 4o Mini showed notably poor performance in this category, recording the lowest F1 scores for E78, I13, and Y92 at 23%, 30%, and 0%, respectively.
The third category includes codes Z79 and Z87, where both consistency and F1 scores varied greatly across models, indicating inconsistent performance in identifying positive discharge summaries, as shown in Figures as shown in Figs. 11, 12. For Z79, consistency ranged from 33% to 100%, while F1 scores ranged from 0% to 57%. For Z87, consistency ranged from 36% to 100%, and F1 scores ranged from 0% to 62%, as detailed in Tables 12 and 13. GPT 3o Mini demonstrated 100% consistency for both codes but scored 0% on F1, indicating that it consistently misclassified all records as negative. Similarly, Deepseek Chat and GPT 4o Mini also failed to identify any positive cases for Z87, both recording an F1 score of 0%, although their consistency levels were slightly lower.
Comments (0)