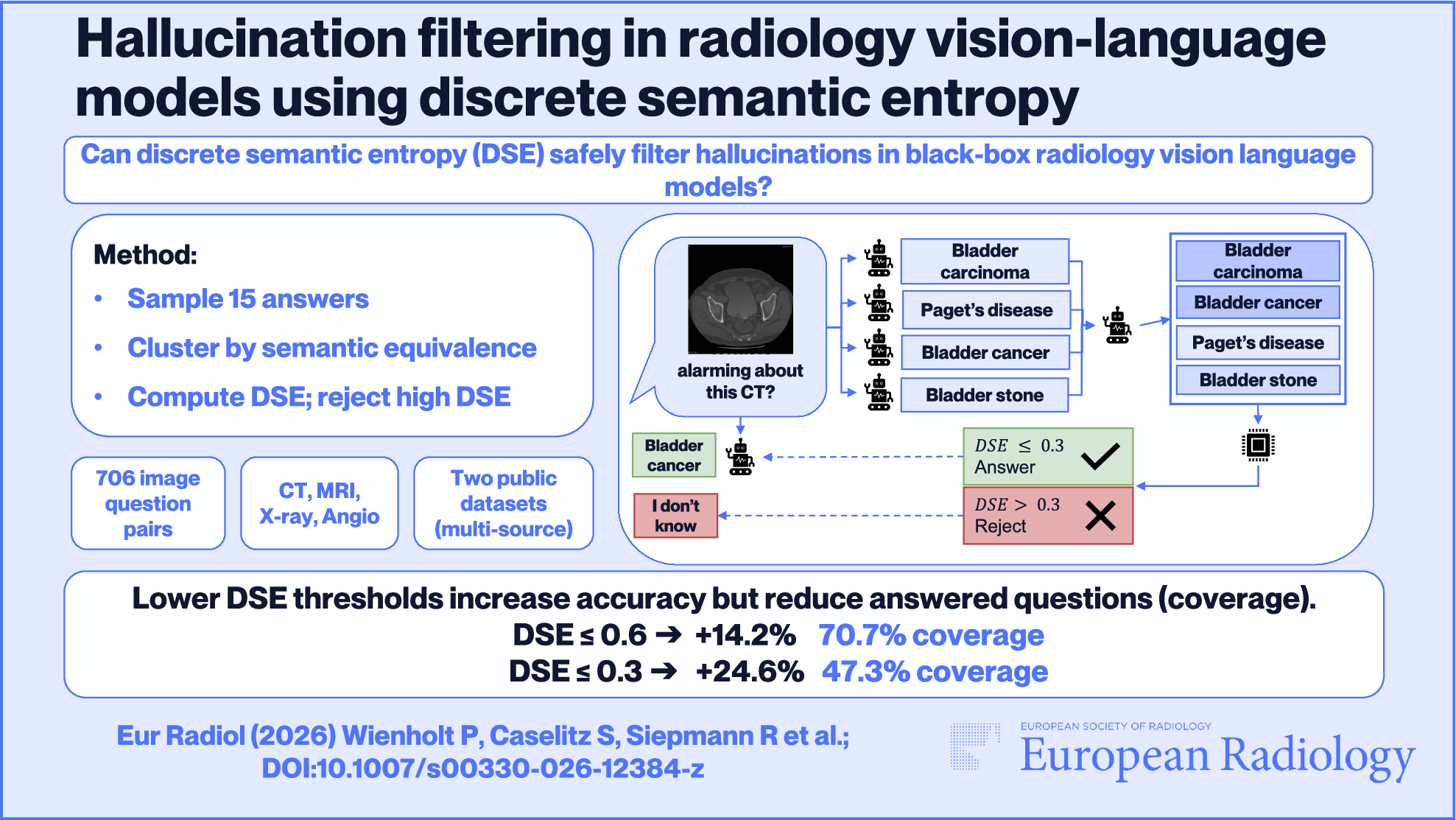
The integration of advanced AI, particularly VLMs, into radiology holds promise for alleviating workload pressures and supporting diagnostic tasks [2, 7]. However, the tendency of these models to generate plausible but factually incorrect outputs, or “hallucinations,” presents a significant barrier to safe clinical adoption [13, 14]. This study investigated DSE—a measure of semantic consistency across multiple model responses—as a practical method for identifying and filtering unreliable VLM outputs in radiologic image interpretation tasks, extending DSE from its original text-only application [14] to the multimodal domain of radiology. Our central finding is that applying DSE filtering significantly improves the accuracy of accepted VLM responses by selectively rejecting questions associated with high semantic inconsistency, thereby enhancing model trustworthiness.
A key advantage of DSE is its applicability to black-box models. Unlike methods that require access to internal model states such as probability distributions [16, 17] or need additional training data or fine-tuning for auxiliary components like uncertainty classifiers [13], DSE operates solely on the model’s outputs generated via standard API calls. This makes it readily deployable alongside proprietary VLMs without requiring specific cooperation from model developers. It provides a practical alternative or complement to other black-box consistency checks, such as those based on input paraphrasing [19] or multi-report sampling [18], by focusing directly on the semantic stability of the model’s own generated answers to a single, consistent query. Compared with RadFlag [18], question rephrasing [19], or vision-amplified semantic entropy [20], DSE avoids input modifications or long multi-report generation, offering lower latency and broader applicability. In practice, DSE incurs substantially lower token and computational cost than multi-report approaches such as RadFlag or paraphrase-consistency methods, because it reuses a single prompt and short answers instead of repeatedly rephrasing inputs or generating full-length reports. While RadFlag excels for full-report tasks but is computationally heavy, and rephrasing or vision-amplified methods risk altering clinical nuance or image fidelity, DSE focuses on semantic consistency alone—efficient yet still limited when hallucinations are repeated with high confidence.
Integrating DSE into PACS or reporting systems can streamline workflows by screening queries at the question level to either withhold unstable outputs or attach an interpretable uncertainty score derived from semantic dispersion across sampled responses. In practice, this identifies questions that are more likely to elicit hallucinations and, when answers are returned, provides a quantitative signal that radiologists can reference when judging the safety of acting on a given question–answer pair. Making uncertainty explicit is essential in clinical settings, where decisions depend on calibrated confidence rather than linguistic fluency. Because DSE operates solely on model outputs and requires neither access to token probabilities nor model retraining, it can be deployed as a lightweight wrapper around existing VLM integrations. By combining selective answering with transparent uncertainty, DSE can thus strengthen clinician trust and real-world acceptance of vision–language models in radiology. In clinical practice, selecting a DSE threshold requires balancing coverage against acceptable risk. For applications such as diagnostic decision support, we recommend a stricter threshold (e.g., 0.3 in our experiments) to prioritize specificity, minimizing the risk of incorrect advice by aggressively rejecting uncertain predictions. Conversely, in lower-risk scenarios like human-in-the-loop screening, a more lenient threshold (e.g., 0.6) may be preferable to prioritize sensitivity, ensuring that potentially relevant information is not discarded. These specific values are model-dependent, and the exact operating point should be determined via calibration on a held-out dataset for each clinical application.
Despite its promise, DSE has important limitations. First, it measures semantic consistency, not factual correctness [14]. A VLM could consistently generate the same incorrect answer (a “confident hallucination”), resulting in a low DSE score that would bypass the filter. This represents a significant residual risk. An example of this is illustrated by the middle right panel of Fig. 3. Integrating DSE with complementary uncertainty signals (e.g., linguistic uncertainty cues, model calibration techniques if available) could lead to more robust hallucination detection systems. Accordingly, DSE should be interpreted as a selective-answering uncertainty signal rather than a guarantee of correctness; in safety-critical use cases, outputs should not be acted upon without radiologist verification. While additional validated clinical context or cross-model consistency checks may help, they are unlikely to eliminate this failure mode; approaching near-zero risk would require restricting the system to a closed set of vetted questions/answers (e.g., guideline- or database-backed retrieval), shifting from open-ended generation to curated decision support. Second, the reliability of the semantic clustering step relies on the VLM’s own entailment capabilities. Errors or biases in the VLM’s understanding of semantic equivalence, particularly for nuanced or complex clinical statements, could lead to inaccurate DSE calculations. This limitation could be mitigated by using an external, clinically validated entailment model for clustering, reducing dependence on the VLM under evaluation. Third, while evaluated on two datasets including clinical diagnostic questions, further validation is essential across a broader range of imaging modalities, pathologies, patient populations, and clinical query types to establish generalizability. Fourth, our evaluation was restricted to 2D images. VQA-Med 2019 consists of single 2D images, and in the RadDataset, we used manually selected key slices extracted from volumetric CT, MR, radiography, and angiography examinations. This design assumes that the most informative slice has already been identified and therefore does not fully capture the challenges of applying DSE to full 3D studies in routine practice. As a result, our findings should be interpreted as a best-case estimate for question-level hallucination filtering under simplified viewing conditions. Extending DSE-based uncertainty filtering to volumetric workflows, for example, by integrating it with automatic key-slice selection or with VLMs that natively operate on 3D image stacks, is an important direction for future work. Prospective clinical validation studies are also needed to evaluate the real-world impact of DSE-filtered VLM outputs on radiologist workflow, diagnostic confidence, efficiency, and, ultimately, patient outcomes. Such studies would also provide insights into how radiologists interact with and trust AI systems employing this type of uncertainty filtering. Whether high rejection rates increase clinician trust or render the system impractical, and whether selective answering might inadvertently promote over-reliance on the remaining outputs despite limited accuracy, are open questions that require prospective user studies to resolve. Finally, a stricter DSE threshold yielded higher accuracy gains at the cost of answering fewer questions, highlighting the inherent trade-off between accuracy and answer rate (coverage). The optimal DSE threshold will likely depend on the specific clinical application and the tolerance for potentially incorrect AI suggestions vs the need for comprehensive assistance. We also observed that the two evaluated OpenAI models differed in how rapidly accuracy improved under stricter numeric DSE thresholds (Fig. 6), reflecting that models can exhibit different degrees of answer variability (and thus different DSE distributions) even when queried with the same temperature. Because the model internals and decoding details are not fully transparent, we cannot further analyze or technically attribute this effect; however, it is an important practical consideration when transferring DSE-based filtering to additional models, as thresholds should be calibrated per model. Prior work on semantic entropy has demonstrated consistent effects across models from different providers [14], suggesting that DSE-based filtering is likely transferable to other VLMs. The observed performance differences between datasets and VQA subcategories underscore the sensitivity of both VLMs and DSE filtering to the specific task context.
In conclusion, DSE offers a practical method to quantify uncertainty and filter unreliable outputs from black-box VLMs applied to radiologic image interpretation. The VLMs generally exhibited low baseline accuracy on complex interpretive tasks, especially for abnormality detection, reinforcing that current general-purpose VLMs are not yet suitable for autonomous diagnostic interpretation. This work should therefore be viewed as a proof-of-concept demonstration of applying DSE to radiologic data, not as establishing clinically practical operating points, especially for abnormality detection where rejection rates are high. By enabling selective prediction based on semantic consistency, DSE significantly improves the percentage of accurate responses, a step towards enhancing the safety and trustworthiness of AI tools in radiology. While DSE is not a panacea for the current limitations of VLMs, particularly in complex diagnostic tasks, it provides a crucial mechanism for managing uncertainty as these powerful models are increasingly explored for clinical support roles in radiology practice.



Comments (0)