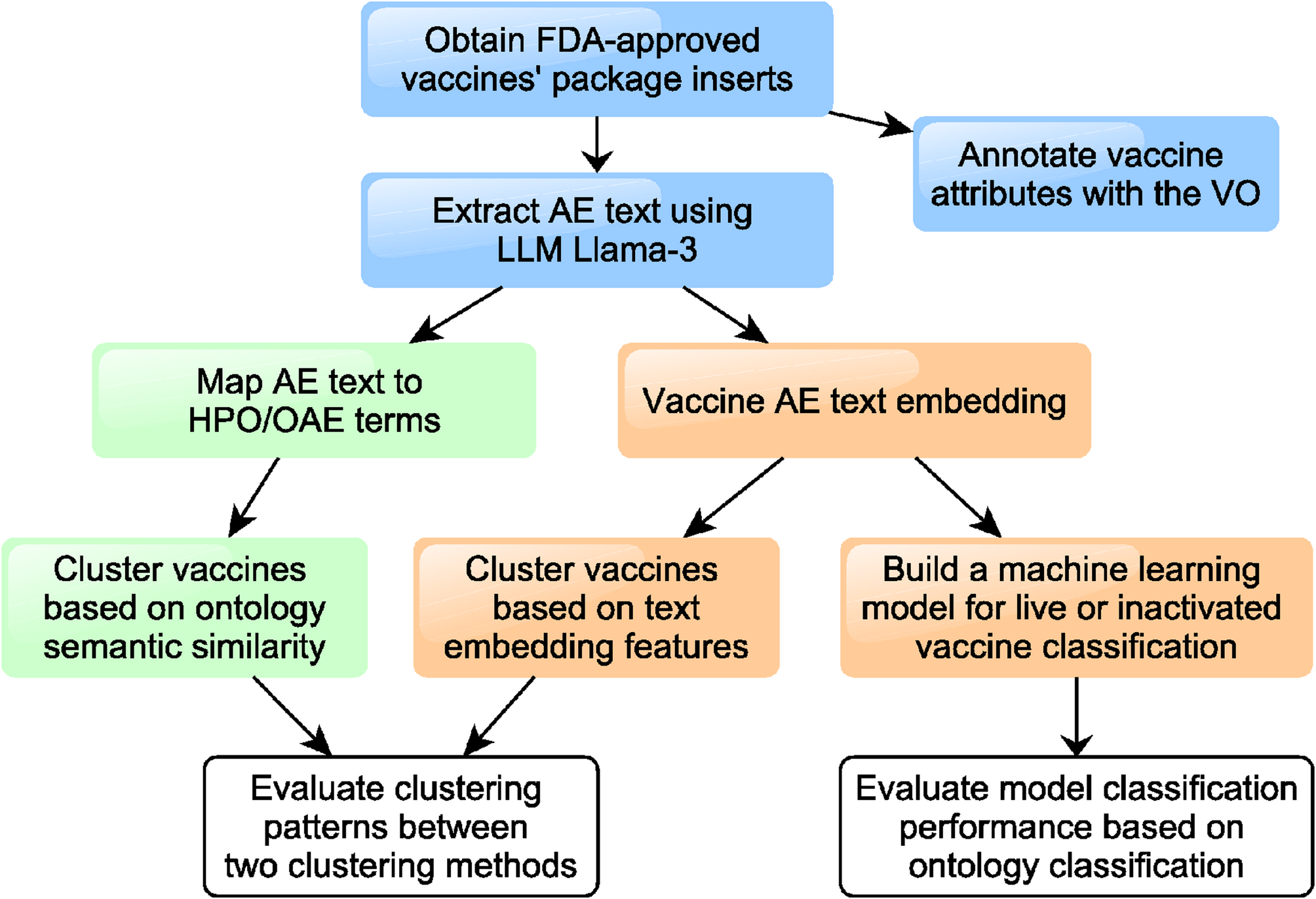
This study made three primary contributions. Firstly, we leveraged LLMs to efficiently process and extract itemized adverse events from FDA-approved vaccine package inserts with high accuracy. Secondly, we compared two methods, namely an ontology-based semantic similarity analysis and an LLM text embedding method, for analyzing and classifying the relationships between these vaccines based on their adverse event profiles. Lastly, we explored the potential of LLM text embeddings to classify vaccines based on vaccine attributes, such as live or non-live. Our findings demonstrate that LLM text embeddings can quickly analyze biomedical descriptive texts, bypassing complex ontology mapping steps. The embedding-based methods can also complement ontology-based clustering and classification. This approach helps uncover potential vaccine classifications, encapsulates latent information within the text [29], and may serve as a valuable tool for medical knowledge discovery.
In our study, the selection of Llama-3, nomic-embed-text, and mxbai-embed-large embeddings was primarily driven by the need to address privacy concerns regarding biomedical data and the requirement for local deployment. These factors were essential to ensure the protection of sensitive medical information and maintain full control over the research process. While GPT-based embeddings are powerful, they often require cloud-based operation, which raises privacy concerns, especially when handling sensitive medical data.
Traditionally, ontology provides an important knowledge representation platform that classifies the knowledge of entities in a specific domain and the relations among these entities. For example, the VO classifies the list of vaccines and their attributes, such as vaccine types, and attributes, such as live or non-live. Furthermore, ontology can be used to support clustering analysis based on the ontology semantic similarity analysis. However, the development of ontology is time-consuming, and the information recorded in ontology may be incomplete. In this study, we used the FDA vaccine package insert documents to build up LLM embeddings and further used them to perform vaccine clustering analysis. Our results showed that the vaccine AE text, when recorded in embeddings, contains global information that can be used to support machine learning studies, such as vaccine clustering. We did not use metadata such as the manufacturing methods and storage conditions, which could introduce new information and potentially affect the clustering patterns of vaccines. These embedding-based clustering methods even show some distinct advantages compared with the classical ontology semantic similarity method. Furthermore, our study demonstrated that the LLM embedding-based classification method was able to classify vaccine information, such as vaccine live or non-live. Therefore, such an LLM embedding-based method has the potential to automatically extract useful vaccine attributes.
In mapping the adverse event description texts to ontology terms, we took several measures to ensure the quality of the mappings. First, all mappings of vaccine adverse event terms to ontology terms were manually reviewed for accuracy. Experts in the field of vaccines also participated in the review process to guarantee both the accuracy and professional integrity of the mappings.
To further enhance the accuracy and completeness of these mappings in future work, we developed an advanced mapping tool, OntoRetriever. This tool leverages large language models and text embeddings for mapping, utilizes text-embedding vector similarity to evaluate the results of multiple mappings, and provides a final score for each mapping. Our testing of the tool using HPO and OAE validated the accuracy of the tool. The tool uses the OBO format as input. Tools like ROBOT [14] can be used to convert OWL format files to OBO format. Therefore, OntoRetriever can be adopted for other ontology usage.
While our study did not find missing mappings, we would like to note that possible missing or misaligned mappings could influence the results of our semantic similarity calculations. Specifically, if a vaccine adverse event term is not mapped to an ontology term or is incorrectly mapped, this could lead to false negatives, where two similar adverse events are mistakenly classified as dissimilar. On the other hand, if unrelated adverse event terms are mapped to the same ontology term or closely related events are mapped to different terms, it could result in false positives, causing the model to incorrectly group dissimilar events as similar.
One surprising result of our study is the discovery of latent information about vaccine AEs through LLM text embeddings. Specifically, the analysis revealed a potential association between vaccine AEs and whether the vaccine is live or inactivated, even though this relationship was not explicitly stated in the AE text. By leveraging the features extracted from text embeddings, we successfully built a classification model to distinguish live vaccines from non-live ones, demonstrating strong predictive performance. This finding not only validates the effectiveness of text embeddings in capturing hidden patterns but also suggests that this approach could be a powerful tool for uncovering latent medical knowledge.
Our method of LLM-based text embeddings has shown its capability of efficiently and accurately identifying new patterns from vaccine package insert documents. The potential applications of LLM-based text embeddings extend beyond vaccine safety and may provide new insights across various healthcare research areas, including drug discovery, disease classification, and personalized medicine. However, an important challenge remains: evaluating the scalability and generalizability of our methodology across larger datasets or different vaccine types. Note that our systematic study used all the available 111 FDA vaccines, which is the largest vaccine package insert document dataset in English. It is possible to use the same method to analyze other vaccine or drug package inserts. However, adverse event descriptions in FDA-approved package inserts follow specific styles, while other package inserts may use different ways of presenting the information. This variability in presentation styles could potentially lead to inconsistencies in text vectorization, making it challenging to compare adverse event profiles across different datasets. Meanwhile, for data from different sources, clustering based on embedding features may possibly reveal entirely novel patterns, indicating the need for further exploration by researchers. In the future, we plan to apply our methods to analyze more datasets and compare results out of datasets with different data formats.
Our study demonstrated a high performance of using LLMs to automatically process and extract itemized adverse events from vaccine package insert text. For this LLM study, we developed a Python code that automatically processes individual package insert documents. Over 80% of the extracted information was accurate, and re-running the extraction process could complement the results, enhancing overall accuracy. However, minimal manual intervention was required throughout the entire LLM-based vaccine AE extraction process, a significant advantage over traditional manual methods. In the future, to further reduce manual intervention, we may introduce multiple language models, each generated independently, which will then be aggregated through a final decision-making model.
Our comparative analysis shows that the LLM method outperformed ontology-based approaches in identifying differential AE profiles among vaccines. The higher similarity scores from the ontology-based method were likely due to its focus on annotation terms within the hierarchical structure. In contrast, LLM embeddings capture richer, more nuanced representations of text, understanding complex semantic information, context, and relationships [30], which allows them to better handle intricate medical terminology and contextual nuances in vaccine adverse event descriptions.
LLM embeddings excel in adapting to complex and evolving contexts, handling terms that may not fit rigid ontologies. Their ability to generalize across various contexts enables them to effectively address emerging adverse events or new expressions, something ontology-based methods struggle with due to their fixed structures. Overall, LLM embeddings provide a dynamic and context-aware approach, enabling more sensitive identification of differential AE profiles and allowing for faster and more efficient analysis of biomedical texts, such as adverse events. They can serve as a valuable complement to ontology-based methods.
Using the LLM embeddings, we were able to discover many latent adverse event (AE) patterns. For example, our approach identified an 81% accuracy rate in the classification of live and non-live vaccines. By examining the AE profiles between live and non-live vaccines, we found that live vaccines tend to induce systemic, respiratory, and inflammatory responses such as fever and fatigue. Our analysis found that live attenuated influenza vaccine FluMist Quadrivalent is associated with asthma and recurrent wheezing, a phenomenon not observed in other influenza vaccines. This finding fits in with the general adverse event patterns of live vaccines. On the other hand, non-live vaccines are commonly associated with local skin and muscular symptoms and neurological reactions such as swollen, redness, local injection site pain, and movement disorders. These profiles are aligned with previous studies such as the AE results of the analysis of the VAERS [6].
By examining the adverse event profiles of those misclassified live and non-live vaccines, we found that the misclassified live (or non-live) vaccines tend to have AE profiles of non-live (or live) vaccines. For example, PRIORIX (Measles, Mumps, and Rubella Vaccine, Live) and IXCHIQ (Chikungunya Vaccine, Live), both live vaccines, were incorrectly classified as non-live, likely due to their local reactions such as pain and redness. Conversely, non-live vaccines such as SPIKEVAX, Gardasil, Typhim Vi, and H1N1 2009 Monovalent were incorrectly classified as live, likely due to these vaccines’ association with systemic reactions such as fever and fatigue, which were usually seen in live vaccines.
Our study acknowledges certain biases in the dataset, which may affect the generalizability and interpretation of the results. Two factors contributing to bias are the geographic scope and vaccine type of the vaccine dataset. Since it primarily consists of FDA-approved vaccines, vaccine package inserts from other countries may contain different components or follow distinct regulatory guidelines. As a result, our conclusions, drawn from a dataset limited to FDA-approved vaccines, may not be directly applicable to vaccines used in other parts of the world. This bias may introduce limitations to the external validity of our study, highlighting the need for caution when attempting to generalize the findings beyond the U.S. context. Additionally, inactivated vaccines are more prevalent than non-inactivated ones among FDA-approved vaccines, which may influence the development of classification models. Note that our study addressed type bias by assigning weights to each type. Further analysis of the bias effect may deserve further investigation.
Overall, our research demonstrates the power of LLMs in efficiently extracting and analyzing itemized vaccine adverse events. Our future work includes an extension of the methods for the analysis of other vaccines’ information and an automatic conversion of the LLM-generated results to an ontological representation. Such work will significantly help us better understand vaccine adverse events, leading to advanced public health research.


Comments (0)