
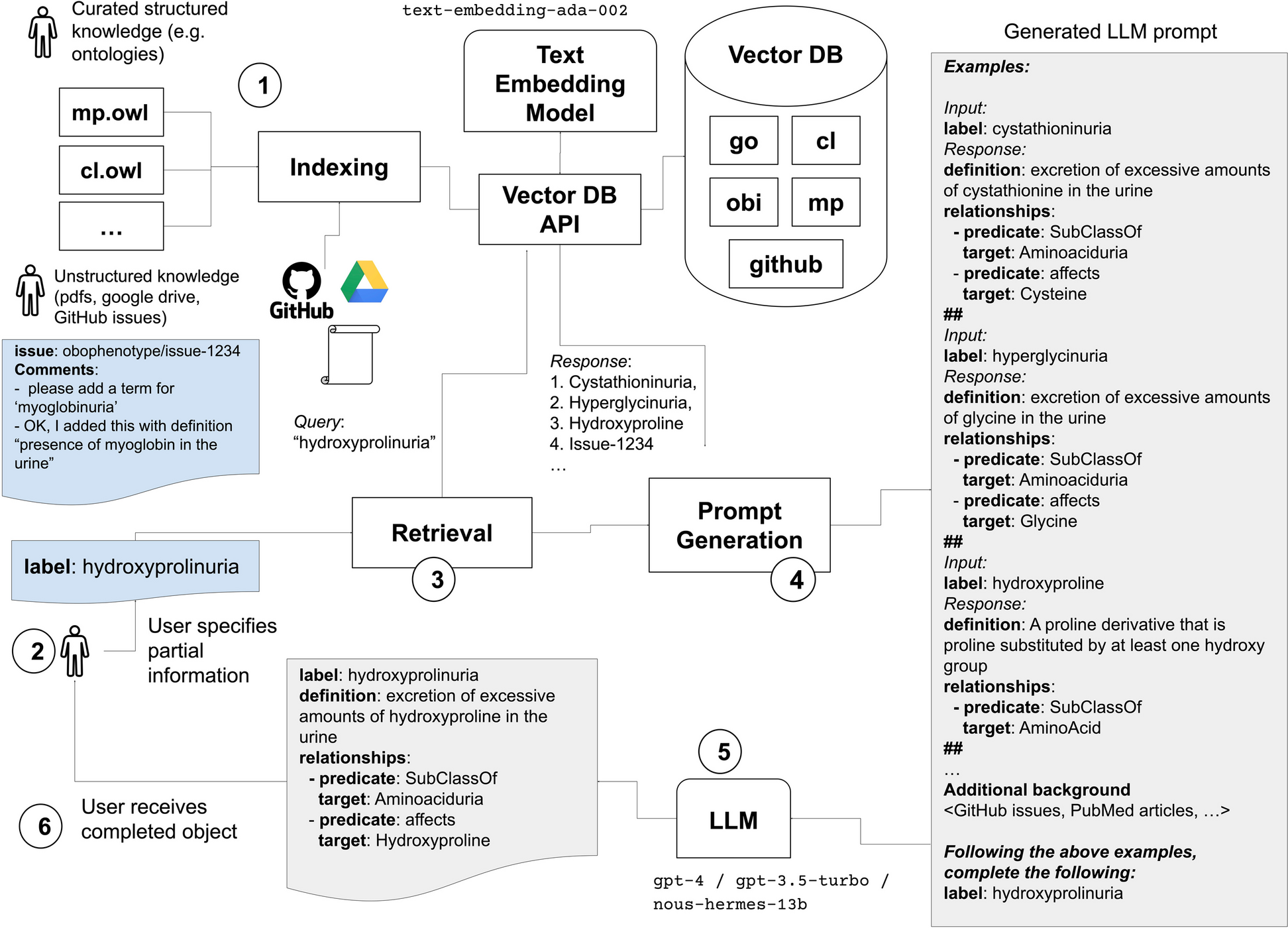
Remember me
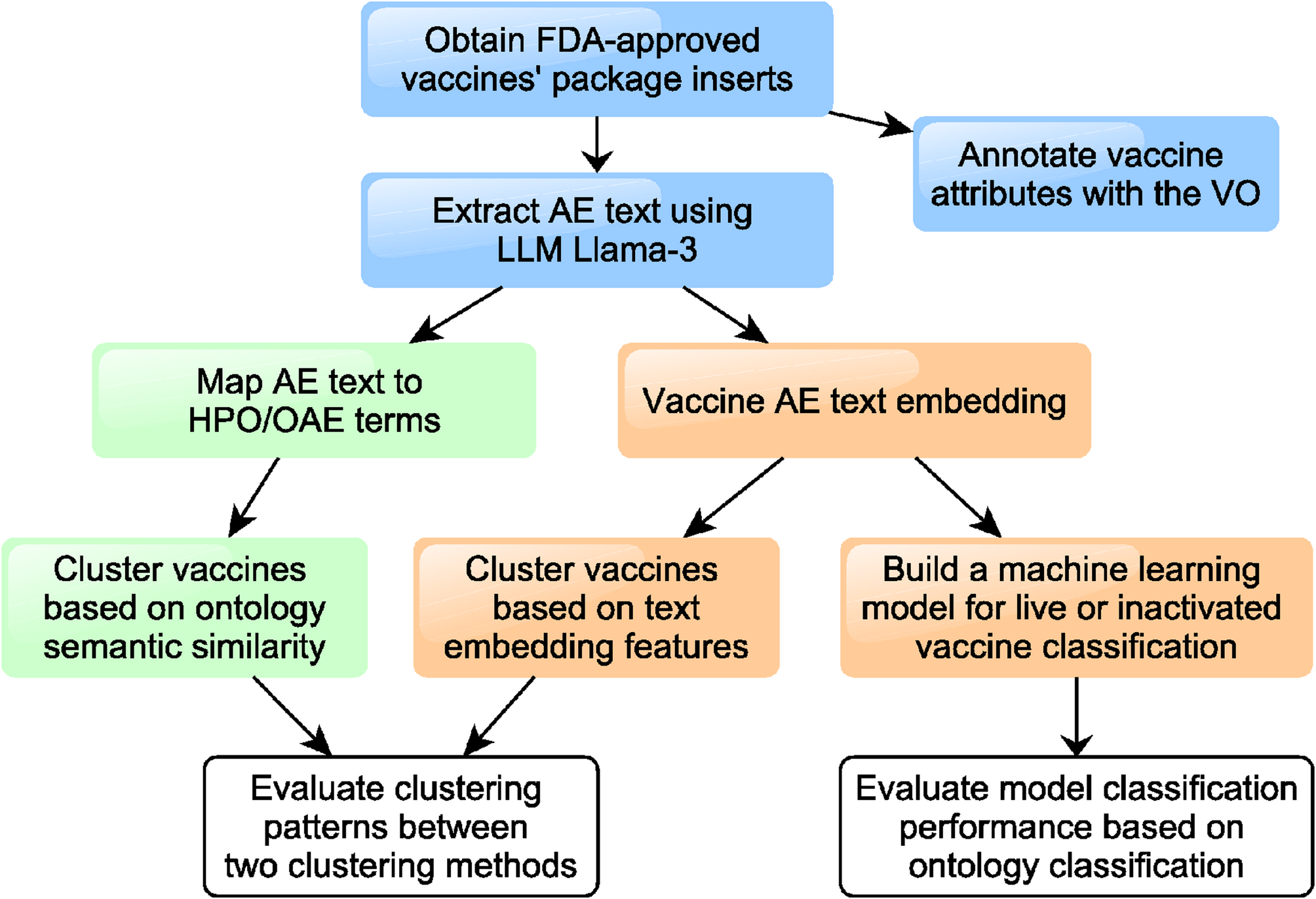

Having outlined the data collection, data pre-processing, data extraction, and data integration steps, we now layout the capabilities of the BASIL DB. Subsequently, we discuss some limitations of our approach and explore potential avenues for future work, including a focus on data quality.
OverviewThe BASIL DB is designed to enable users to navigate through arrays of scientific literature regarding bioactive compounds. This enhancement is intended to assist users in understanding and processing complex clinical data more efficiently, providing a clearer and faster route to information in both nutritional science and medical research. It has the potential to support dietary intake assessments, aid in nutritional education for consumers, provide healthcare professionals with robust data for dietary recommendations, capture information on synergistic compound combinations, and assist research on diet-health relationships.
The process of discovering compounds with previously unrecognized therapeutic potential can be approached through various methods such as biodiversity-based, chemo-systematic, ecological, computational, and ethnopharmacological approaches [28]. The BASIL DB was designed to enhance the computational [29] and ethnopharmacological [30] approaches by providing a robust dataset of bioactive compounds and their documented health effects, simplifying data-driven insights, validations, and the exploration of traditional medical practices through modern scientific studies. Compared to the random model, leveraging ethnomedical knowledge and computational strategies is more cost-effective and time-efficient [31] and can even yield a higher success rate in identifying promising compounds [32, 33].
The database was constructed with 433 compounds, 40296 papers, 7256 health effects, and 4197 food items, available for access at https://basil-db.github.io/info.html.
The 3 bioactive entities with most associated papers are “Carotene” (979), “Docosahexaenoic acid (DHA)” (958), and “Arachidonic acid” (937). The conditions with the most associated papers are “Pain” (706) “Symptoms” (653), “Hypotension” (581), and “Continuance of life” (531). The 3 highest weighted edges between bioactives and condition nodes are “Vinblastine” and “Non-Small Cell Lung Carcinoma” (657), “Ephedrine” and “Hypotension” (607.9), and “Artemisinin” and “Malaria, Falciparum” (497.3). Excluding food nodes, the graph has 5 components, the largest of which contains 12,844 nodes, and the average degree is 24.5.
Web interfaceWe provide a web interface to browse the database. Importantly, we host the data and code on GitHub allowing for open development. We now describe the features of the web interface.
BASIL DB searchUsing the search function, users can query the categories “Compound”, “Condition”, “Food”, and “Other”, where the latter refers to any entities that were identified by the NER pipeline but do not fall within the semantic types classifiable as “Health Effect”. Examples include geographic locations, temporal concepts, or occupational activities.
Table 2 Three exemplary evaluation entries for the compound “Curcumin”. Some columns, such as “Other Compounds” were excluded for simplicity, and N refers to the number of participantsTo illustrate, when querying “Curcumin” under the “Compound” category, users can explore its associations with various health conditions, such as inflammation or pain, discover foods high in “Curcumin”, and examine other contextual factors recognized by the system but not directly related to health effects. Tables 2, 3, and 4 provide detailed examples of such a query.
Table 3 Concentration of the compound “Curcumin” in various foods Table 4 Top six conditions with the highest edge weight for the compound “Curcumin”VisualizationWe provide a number of visualizations that show various aspects of our dataset. Figure 4 is a heatmap showing the connection strengths between bioactive compounds and health conditions; Fig. 5 displays a graph of compound-to-condition links, indicating effect similarities; Fig. 6 features a Sankey graph of food-compound-condition relationships; and Fig. 7 presents a multidimensional scaling (MDS) plot of compounds on the basis of the Tanimoto similarity.
Fig. 4
Heatmap presenting the connection strengths between 10 bioactive compounds and 10 health conditions, where lighter colors reflect a greater weight. For example, there seems comparably high evidence for the connection between “Capsaicin” and the concept “Pain” or “Curcumin” and the concept “Inflammation”
The Tanimoto coefficient, also known as the Jaccard index, is a measure of the similarity between two sets and is calculated via the following formula:
$$\begin T(A, B) = |A \cap B| / |A \cup B|, \end$$
where A and B are sets of characteristics (in our case using the Simplified Molecular Input Line Entry System (SMILES)) for two different compounds. The coefficient ranges from 0 to 1, where 0 indicates no similarity and 1 indicates identical sets.
Fig. 5
Graph linking compound nodes such as L-theanine or Dadzein (green) to various condition nodes (red). This visualization informs us of the effect similarity of two or more compounds. Users are able to adjust the minimum edge weight for overview
Fig. 6
Sankey graph displaying the connections between selected foods and their respective compounds and health effects. The blue links represent edges between foods and compounds, and the orange links represent edges between compounds and conditions
Fig. 7
Multidimensional scaling (MDS) plot of the compound dataset as found on the BASIL DB website. Each pair of points is positioned to display, as accurately as possible, the dissimilarity between those two samples based on their Tanimoto similarity
Updates and scalabilityUsers have full access to the setup via GitHub, which they can fork and run independently, with the entire existing dataset available for download. Given the use of the described data sources in “Data collection” section users can easily scale the current version by adding new paper, bioactive, or condition entities. The respective identifiers such as PubMed ID or UMLS concept ID can be used as criteria to avoid duplicating existing entries. For detailed instructions on configuring and running the setup, including versioning of the tools used, please refer to the GitHub repository.
Data extraction pipeline evaluationTo evaluate the accuracy of our NLP-based pipeline, we conducted two complementary assessments: first, a manual review in which annotators examined a random sample of our outputs for correctness, and second, an automated benchmark against a publicly available, labeled dataset. For the manual review, we randomly selected 100 compound-paper pairs from our KG, ensuring that different compounds and effect sources were included. Two independent annotators were asked to assess the accuracy of the extracted information. For each compound-paper combination, annotators evaluated the following aspects:
Compound involvement: Was the compound indeed studied in the trial? For example, was it actively investigated in the study rather than merely mentioned in the introduction?
Effect source classification: Was the “Effect Source” classified correctly?
Positivity of health effects: Were all positive health effects actually positive?
Participant extraction: Was the number of participants correctly extracted?
To ensure the reliability of our evaluation, interannotator agreement was measured via Cohen’s Kappa, yielding scores of 0.78 for compound involvement, 0.78 for effect source classification, 0.82 for positivity of health effects, and 0.94 for participant extraction. Disagreements were resolved through discussion to establish a gold standard for final accuracy calculations.
For the assessment of whether the compound was actively studied in the trial, the pipeline achieved an accuracy of 89% (89 out of 100 pairs correctly identified). Errors occurred in cases where compounds were mentioned in the introduction only for context, or compounds had a more complex function, for example, as a target for reduction rather than as a therapeutic agent. One included paper (PMID: 8741209) was a review, not an RCT. These cases were the most critical, as they could lead to follow-up errors.
The classification of “Effect Source” was correct in 80% of cases (80 out of 100). The most common error involved misclassification of “Combination” studies. For example, in study 34587702 the compound “monacolin K” was classified as “single”, although the study researched “red yeast rice with monacolin K”.
With respect to the classification of extracted health effects, three cases were incorrectly classified as positive, yielding a 97% accuracy. For instance, “increased cough reflex sensitivity” was classified as a beneficial effect of capsaicin in asthma patients, although this symptom is generally considered a negative outcome in asthma management.
The extraction of the number of participants was correct in 84% of the cases, with errors mainly stemming from abstracts that reported participant numbers ranges or subgroup breakdowns that RobotReviewer occasionally failed to parse correctly.
To further assess the generalizability of our pipeline in a fact-checking scenario, we evaluated our approach on the HealthFC dataset [34], which consists of 750 health-related claims labeled “health claim supported”, “health claim refuted”, and “not enough information”. Since our original pipeline focuses on extracting bioactive-specific information from RCT abstracts, we modified the LLM prompting strategy: instead of extracting health benefits for predefined compounds, the prompts were adjusted to retrieve health claims from the HealthFC texts with predefined interventions (e.g., “masks”) and classify the respective claim as “supported”, “refuted”, or “inconclusive”.
Using the dataset’s labels as ground truth, the pipeline achieved an overall accuracy of 74.8% in claim verification (561 out of 750 correctly classified). The most common error type was the classification of inconclusive claims as supported claims, pointing to an overreliance on positive outcomes. These results demonstrate the pipeline’s ability to extract health effects, even for broader health fact-checking tasks, although further refinement could improve handling of ambiguous or multifaceted claims.
For more detailed evaluations of the individual NLP tools, we point to previous literature assessing the performance of LLMs [35], RobotReviewer [18], and MetaMap [36]. We provide further discussion in “Limitations and future work” section.
Limitations and future workBy using various tools and sources for the creation of the BASIL DB, the quality of the final output is inherently dependent on the precision of these methods and the quality of the underlying data. In utilizing LLMs to extract the purported health effects of compounds from scientific studies, we must acknowledge the limitations inherent in non-expert systems interpreting nuanced medical data. Assessing and improving the ability of these systems to understand the nuanced implications of clinical terms and relationships represents a critical area of future work [37, 38].
While developing BASIL, we frequently encounter data quality challenges commonly faced by large-scale medical datasets, including incorrectness, incompleteness, lack of standardization, and other issues that can compromise the robustness of data-driven insights. These problems are not unique to this work, as the literature shows that medical big data often suffer from errors, missing information, and inconsistencies [39]. For example, in PubMed, errors may arise from incorrect indexing of articles or misclassification of research topics. A notable case is the article with PMID 38474802, which was incorrectly classified as a randomized controlled trial despite not meeting the criteria for such a designation. Additionally, indexing issues are evident in the case of “Camptothecin”, where over 800 of the retrieved articles were tagged with this MeSH term, yet none of them discussed “Camptothecin” as a single compound, and 711 were classified as either “None” or “Derivative”. Such classification issues can mislead researchers and reduce the precision and efficiency of search results. In the BASIL DB, one can filter such instances by simply using the “Effect Source” feature.
Another illustrative example is the study with PMID 17939194, which highlights several data quality issues in PubMed. First, the article is translated from Russian, and the translation contains grammatical errors and incorrect drug spellings (e.g., “Metoclopramid” instead of the correct “Metoclopramide”). While this particular spelling error may not lead to significant confusion, similar errors involving drugs with nearly identical names could have serious consequences, such as misidentification of medications in clinical or research settings. Furthermore, the abstract is incomplete and ambiguous, lacking critical details about the study’s methodology, results, and conclusions. For instance, it mentions “vegetotropic therapy” and “hypobaric hypoxic adaptation” without providing sufficient context or definitions, making it difficult for researchers to assess the study’s relevance or validity. Compounding these issues, the full text of the article is unavailable in public or academic databases, limiting the ability of researchers to verify or build upon its findings.
The study is also indexed with a large number of MeSH terms, some of which may not be directly relevant to its focus or are redundant. For example, the terms “Biliary Dyskinesia/diagnostic imaging”, “Biliary Dyskinesia/drug therapy”, “Biliary Dyskinesia/physiopathology”, and “Biliary Dyskinesia/therapy” are all indexed separately, even though they could potentially be consolidated under a single term like “Biliary Dyskinesia/therapy” to avoid redundancy. Over-indexing with broad or irrelevant terms can dilute the relevance of search results and make it harder for researchers to find studies that are truly focused on their topic of interest.
Furthermore, occurrences of empty abstracts (e.g., PMIDs 4922015, 19701267, 2573775) or incomplete abstracts (likely due to data entry errors, as seen in PMIDs 33075061, 33641356, 30453844) are common in PubMed. These issues hinder the ability of researchers to assess the relevance of studies quickly. Variations in terminology across different journals and disciplines [40] further exacerbate the lack of standardization, potentially leading to inconsistencies in article retrieval and cataloging. For instance, the Unified Medical Language System (UMLS), which integrates over 160 source vocabularies [41], may contain variations in definitions and usage that are not fully consistent. This can affect the accuracy of semantic searches and data integration tasks. An example is the distinction between terms like “Diabetes Mellitus” and “Diabetes Type”. While these terms serve different semantic roles, their overlapping usage in the literature can still lead to challenges in accurately retrieving and integrating relevant studies, particularly when automated systems such as MetaMap fail to account for their contextual differences.
Table 4 reveals a well-documented challenge in the biomedical knowledge graph literature, where generic health concepts such as “pain” can become high-degree nodes that may hinder knowledge discovery efficiency [42]. Several methodological approaches have been developed to address this problem. Van Haagen et al. [43] proposed systematic filtering on the basis of concept frequency thresholds and semantic specificity metrics, while recent work has employed advanced harmonization methods [44] and Kullback-Leibler Divergence reranking to weight concepts on the basis of their disproportionate representation in condition-specific versus general biomedical literature [45]. Future iterations of the BASIL DB could incorporate these methodologies to distinguish between general terms and specific health conditions. Additionally, MetaMap’s confidence scores can be leveraged to downweight low-confidence generic extractions. Finally, our separation of health effect and population terms may provide some mitigation by adding contextual specificity to generic concepts. For example, in PMID 29908031, while “pain” appears as a health effect, it is qualified by specific population descriptors including “post-surgical” and “impacted third molars”, enabling more targeted queries than the generic concept alone would allow.
FooDB aggregates food composition data from diverse sources, including scientific literature, government databases, and industry reports. While this diversity enriches the dataset, it also introduces challenges such as inconsistent measurement methods, varying units, and terminological differences. As shown in “Data pre-processing” section, there are significant discrepancies between values reported from different sources, such as the quercetin content in “European cranberry”, which varies widely from 0.515 mg/100 g to 16.392 mg/100 g. Additionally, FooDB may not cover all food varieties, such as differences in nutrient content based on cultivation practices, geographical origin, or processing methods.
Having outlined some of the data quality challenges, we aim to address these issues more comprehensively in future work. This could involve developing more sophisticated data cleaning and harmonization techniques, as well as exploring advanced methods for integrating diverse data types to ensure comprehensive and accurate data representation. Strategies for improving data quality in health research typically involve the use of business intelligence models, statistical analyses, data mining techniques, and qualitative approaches [46].
Finally, future work could extend the “knowledge as a product” strategy by expanding the database to a wider range of papers, compounds, foods, and other entities representative of the domain. As only RCT abstracts were considered, a variety of study types such as cohort or case studies, as well as full trial texts, could increase cohesiveness of our approach. This could be further developed to include other forms of interdisciplinary knowledge, such as sustainability, market trends, or technology development, and create even more opportunity for innovation.
Comments (0)