
Remember me
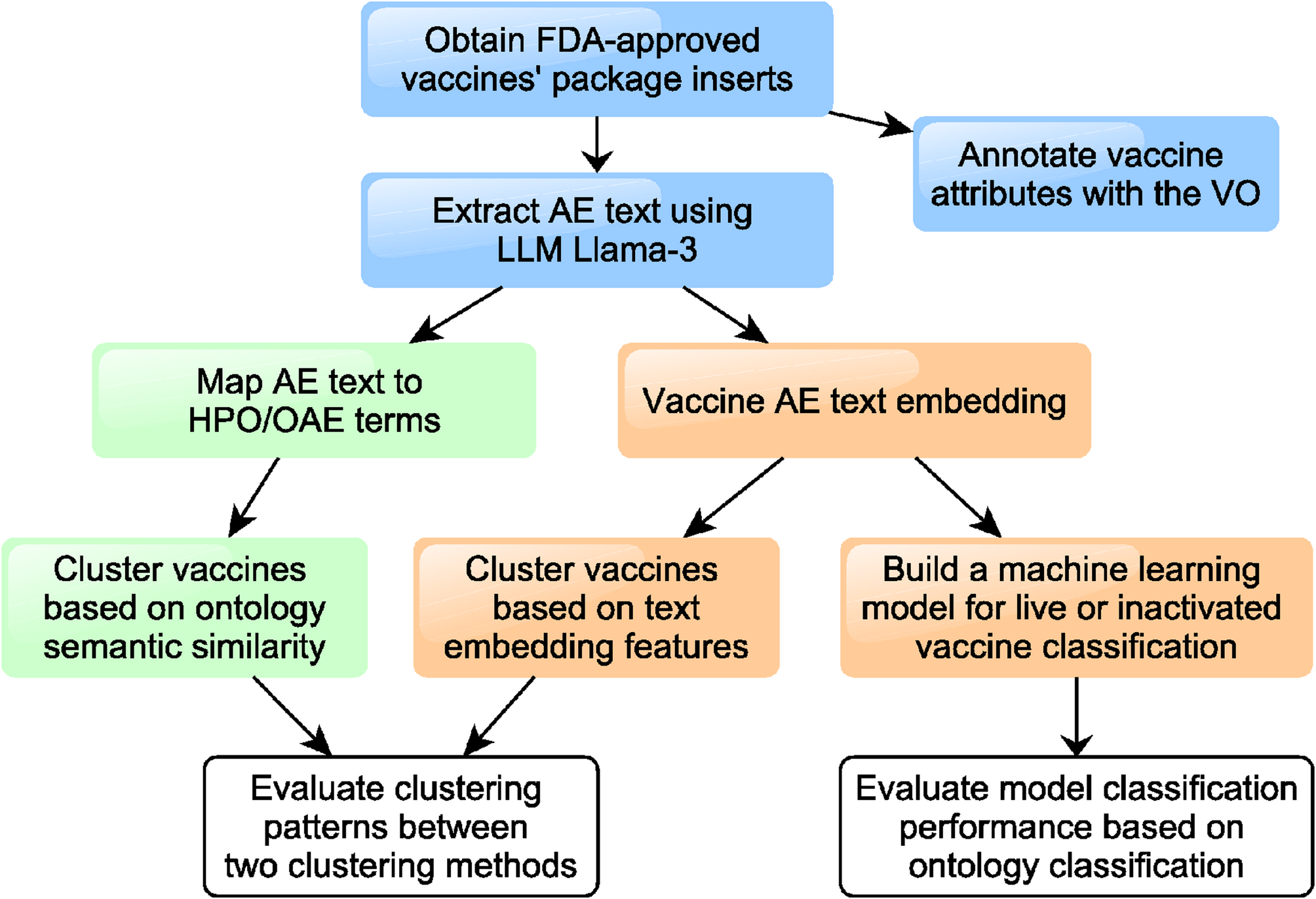

This section outlines the interview study conducted with pharmacists and the construction of the medicX-KG knowledge graph. We detail the qualitative methodology used for interviews (including data analysis), summarise quantitative insights from the interview data, and describe the technical process of building and mapping the knowledge graph with illustrative examples.
Qualitative study: interviews with pharmacistsParticipants, interview design and procedureTo inform the design of medicX-KG with real-world pharmacist needs, we conducted semi-structured interviews with six pharmacists (five female, one male) based in Malta. Participants were purposefully selected to maximise diversity across practice domains, including community pharmacy, hospital paediatrics, regulatory risk management, green manufacturing, quality assurance, and digital health (see Table 2). All interviewees had doctoral degrees in fields related to pharmacy.
Table 2 Participant profiles highlighting diverse practice settingsThe interviews were conducted remotely (owing to COVID-19 restrictions) by two researchers, including a senior pharmacy expert. Each session lasted approximately 60 minutes, was recorded with consent and complemented by interviewer notes. The interviews followed an open-ended, exploratory format structured around three focal areas:
1.Information-Seeking Behaviour: exploration of the types of drug-related information most frequently queried, resources used, and perceived deficiencies.
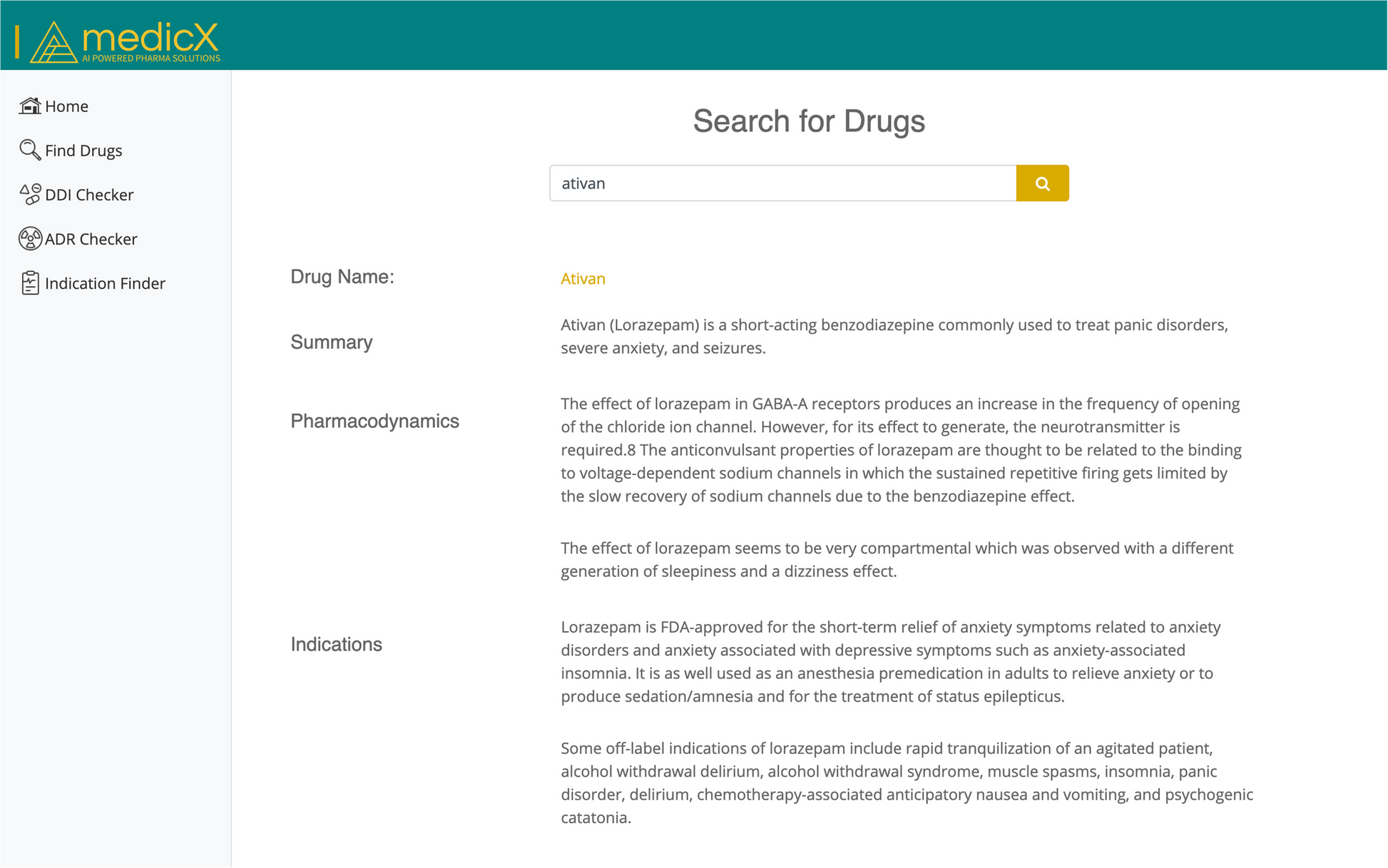
2.Evaluation of the medicX MVP: participants interacted with a Minimum Viable Product (MVP) [64] of the medicX portal (Fig. 1), featuring semantic drug search, local SmPC integration, and a predictive DDI checker. The MVP evaluation was framed around usability, relevance, and desired features.
3.Expectations for Predictive DDI Features: soliciting perspectives on the feasibility, trust, and clinical utility of AI-driven DDI prediction within pharmacy workflows.
Fig. 1
Minimum Viable Product (MVP) [64] of the medicX portal, showing semantic drug search, pharmacodynamics, indications, and predictive DDI scoring
The interview guide was developed collaboratively and was informed by previous studies on pharmacist information practices [37, 57, 65]. The questions were refined iteratively by consulting with a practising pharmacist to ensure clinical relevance. The final list of questions that were asked during the interview is found in Appendix A.
Qualitative data analysis methodologyAll interviews were transcribed verbatim. We used an inductive thematic analysis approach [8], allowing dominant patterns to emerge directly from the data without forcing predefined categories.
Two researchers independently performed open codingFootnote 1, annotating key statements and observations across the dataset. Coding outcomes were then iteratively reviewed and clustered into higher-order thematic abstractions through collaborative discussion and consensus-building.
Coding was organised around three initial anticipated dimensions, namely drug information needs, information resources and improvement suggestions; however, thematic refinement led to expanded categories such as “local drug availability challenges” and “trust in predictive features.” Frequency counts between participants were used to quantify theme relevance where applicable.
The qualitative coding process was enhanced through the following:
Domain-expert triangulation: involving a pharmacist researcher in all stages of the analysis to validate domain-specific interpretations.
Collaborative codebook refinement: codes were merged, split, or redefined across multiple review cycles to maintain semantic precision.
Cross-participant comparison: examining consistency or divergence of themes in different settings of pharmacy practice.
This analytic process enabled the identification of critical pharmacist needs, including gaps in existing drug information systems, high trust thresholds for predictive features, and strong demand for local regulatory alignment, which directly informed the subsequent knowledge graph schema and query mechanisms developed for medicX-KG.
Findings from interviews: key information needs and resource useThematic analysis of the interviews revealed critical pharmacist information needs, resource usage patterns, and priority areas for system improvement (see Appendix C for more information about the findings from the interviews). Although the sample size (N=6) was limited, the diversity in practice settings enhances the indicative value of the findings. However, the results should be interpreted as indicative rather than representative.
Frequently sought drug information typesPharmacists consistently prioritised information related to dosage, DDIs, contraindications, and cautions, each mentioned by four of the six participants (Fig. 2). ADRs were also prominent, highlighted by half of the interviewees.
Fig. 2
Frequently sought drug information types (number of mentions across six participants)
Lower frequency but clinically significant queries included drug alternatives, pharmacokinetics, dietary compatibility (e.g. gluten-free medications) and pregnancy/lactation safety. Such specialised information needs often arise in context-specific problem-solving scenarios.
Pairwise similarity analysis (Fig. 3) further revealed convergence among pharmacists in similar roles (e.g., community pharmacy), and divergence among specialists, underscoring the heterogeneous nature of information needs across practice contexts.
Fig. 3
Heatmap of information need similarity between participants (Jaccard index)
Drug information resource usage and gapsSmPC documents and the BNF [9] were the most consistently used references, cited by all the pharmacists. International commercial databases such as Micromedex [48] and UpToDate [71] were also widely consulted (5/6), although cost barriers limited their accessibility (as can be seen in Fig. 4).
Fig. 4
Primary drug information resources cited by pharmacists
Other resources such as MedScape [47], EMC [14], DynaMed [16], and the MMA’s online platform were mentioned sporadically. In particular, several pharmacists reported resorting to ad-hoc online searches when authoritative resources were inaccessible, raising concerns about the reliability of the information.
The fragmented and non-standardised ecosystem of references, ranging from highly credible SmPCs to ad hoc Google searches, underscores the need for a unified, authoritative knowledge graph consolidating trusted sources.
Feedback on medicX MVP and desired featuresPharmacists expressed strong support for core aspects of the medicX portal (more information related to the MVP is found in Appendix D) but also identified clear areas for improvement:
Information Presentation: Calls for ADRs to be presented in frequency-ranked tables with clear definitions (e.g., ’common’ side effects explicitly quantified).
Usability Enhancements: Suggestions for interactive navigation features (e.g., clickable sections, collapsable menus) and mobile-friendly layout adaptations.
Terminology Simplification: Emphasis on avoiding jargon and clarifying clinical terms to ensure quick and safe comprehension.
Clinical Decision Support Tools: Recommendations for integrated calculators (e.g., dosage adjustment by indication) and drug–food/herb interaction alerts.
Local Regulatory Visibility: Requests for explicit labelling of local authorisation status (prescription vs. over-the-counter, brand equivalence).
The feedback notably converged on the need for:
Trustworthy, concise, contextually relevant information.
Rapid accessibility through optimised UI/UX design.
Local regulatory contextualisation embedded within drug profiles.
These findings directly informed medicX-KG’s schema, data requirements (e.g., ADR frequency attributes, local regulatory metadata), and interface design priorities.
Knowledge graph construction and ontology mappingFollowing the needs assessment from the interviews, we constructed the medicX-KG, which is tailored to address the identified information needs and integrate the disparate sources of drug information. This section provides technical details on the data sources used, the ontology design and mapping strategy to merge these sources, and examples of how mapping ambiguities were resolved to ensure a consistent and reliable graph.
Data sourcesmedicX-KG integrates three primary datasets selected to balance regulatory, clinical, and molecular information needs: the MMA registry [43], the BNF[9], and DrugBank[35]. While earlier sections reviewed the characteristics of these sources, here we focus on the technical extraction procedures and design choices underpinning their integration.
The MMA dataset provided the national reference list of pharmaceutical products authorised in Malta. The programmatic harvest of the online MMA portal yielded 9,784 product records. Pre-processing eliminated structurally invalid entries, withdrawn products, and duplicates, producing a curated subset of 9,746 products suitable for downstream integration. Each retained record contained structured fields specifying the product name, active ingredients (with concentrations), pharmaceutical form, and marketing authorisation holder.
BNF data, accessed via an academic licence, offered structured clinical information for more than 1,600 drug entries. Extraction focused on fields deemed most critical for pharmacist decision-making, including indications, standard dosage regimens, contraindications, ADRs, and DDIs. Web scraping was implemented using Selenium and BeautifulSoup to extract these fields from the online BNF repository, preserving both textual content and structured subsections.
To supplement and enrich the KG with molecular and classification data, DrugBank version 5.1.4 was incorporated. This resource provided chemical structures, pharmacodynamics, ATC codes, and extensive synonym dictionaries for 14,315 drugs. Extraction of DrugBank entries prioritised fields essential for cross-dataset entity resolution and pharmacological classification. Unlike the MMA and BNF sources, DrugBank was partially pre-structured; however, minor inconsistencies (e.g., legacy synonyms, deprecated ATC codes) were addressed during harmonisation.
All datasets underwent rigorous cleaning and standardisation prior to integration. The names of the products and ingredients were normalised for casing, punctuation, and unit representation. Synonym fields were expanded through controlled vocabularies and ambiguous cases were flagged for manual curation during mapping. Where multiple synonyms or formulations were encountered for a single compound, primary names were selected based on regulatory precedence or international non-proprietary nomenclature (INN) standards. More information related to the data used from each of the sources can be found in the Appendix B.
This phase was not purely preparatory but a critical enabler of the semantic interoperability and clinical fidelity that medicX-KG aimed to achieve. The design decisions taken during data curation, including preserving granular distinctions between salt forms and formulations while unifying pharmacological equivalences, would later shape the ontology structure and mapping logic.
Mapping strategyThe central technical challenge in building medicX-KG was the accurate mapping of each product and active ingredient from the MMA dataset to the corresponding entries in the BNF and DrugBank.
Although established ontology alignment systems such as LogMap [33], OLaLa [25], and Matcha-DL [13] offer state-of-the-art capabilities for schema matching and logical alignment, their applicability to pharmaceutical datasets proved limited. While recent advances such as OLaLa have improved matching performance in settings with sparse logical structure by leveraging large language models, and Matcha-DL has enhanced scalability and multilingual support, these tools remain primarily optimised for reconciling structured OWL ontologies where class hierarchies and formal axioms are consistently available. In contrast, pharmaceutical product datasets, such as those from regulatory sources, are characterised by semi-structured formats, noisy terminologies, incomplete semantics, and domain-specific idiosyncrasies [26, 62].
Consequently, we adopted a custom rule-based mapping strategy deliberately designed to maximise interpretability, modularity, and domain-specific control, which are essential criteria in pharmaceutical contexts, where regulatory compliance, clinical accuracy, and manual traceability are paramount. This approach aligns with precedents in the construction of biomedical knowledge graphs, such as Hetionet [27] and DRKG [32], which similarly eschewed generic matchers in favour of domain-aware and heuristic-based reconciliation pipelines.
Our mapping procedure was implemented as a multistage, rule-based process comprising four core stages:
1.Direct Name Matching: For each active ingredient in the MMA dataset, we first attempted an exact match against BNF drug names, applying normalisation for case, punctuation, and common unit descriptors. Products such as Zyrtec 10 mg tablets (active ingredient: Cetirizine Hydrochloride) were successfully linked via this straightforward approach.
2.Synonym and Salt Resolution: Where direct matches failed, we leveraged DrugBank’s extensive synonym and salt-form mappings. For example, the MMA listing for Esomeprazole Magnesium was matched to the BNF monograph for Esomeprazole after identifying the salt relationship via DrugBank synonym data.
3.Combination Product Decomposition: For combination drugs (e.g., Amoxicillin + Clavulanic acid), we implemented a decomposition logic. Where there was a combined BNF entry (e.g., Co-amoxiclav) existed, mapping was performed accordingly. Otherwise, products were individually assigned to their component monographs, ensuring retrieval fidelity across different representation styles.
4.Unique Identifier Assignment: To maintain source traceability and prevent collisions, each Product entity in the graph was assigned a URI derived from standardised product names, pharmaceutical forms and, where available, marketing authorisation codes.
Mapping outcomes are summarised in Tables 3, 4 and 5. In the first phase, BNF matching yielded 677 direct alignments, supplemented by 114 matches through decomposition strategies. However, 852 entries remained unmatched after exhaustive resolution of synonyms and salt forms against BNF alone, illustrating the structural gaps in cross-national drug information coverage.
Table 3 BNF Mapping outcomes for MMA products and componentsTable 4 DrugBank mapping outcomes for active ingredients and componentsTable 5 PubChem mapping outcomes used as a chemical identifier fallbackThe integration of DrugBank proved pivotal, resolving 1,061 additional mappings, particularly for international brand variants, novel entities, and alternative formulations absent from BNF. Combination mappings and fallback matching based on complete product names further improved coverage. The remaining unmatched products, most often veterinary medications or highly localised formulations, were addressed through PubChem, achieving 1,226 chemical level matches, although with 303 entities still unresolved due to the lack of canonical identifiers.
The layered effectiveness of the mapping pipeline is further illustrated in Fig. 5, which aggregates the mappings by conceptual reconciliation strategy rather than by source. This abstraction highlights that integration success was not source-dependent, but method-dependent, emerging from cumulative, cross-source techniques operating in tandem.
Fig. 5
Effectiveness of Mapping Strategies in Linking MMA Products to BNF and DrugBank Entries. The bars correspond to distinct mapping strategies applied during entity resolution, not individual data sources. Counts reflect successfully mapped products using each technique, sometimes involving multiple sources (e.g. DrugBank used for salt resolution followed by BNF linking)
Concrete examples illustrate the criticality of the multistage pipeline. For example, the MMA listing Zyrtec 10 mg tablets was easily mapped by direct matching to the BNF entry for Cetirizine Hydrochloride. In contrast, Augmentin 500mg/125mg tablets required decomposition into its active components, Amoxicillin and Clavulanic acid, followed by synonym-based linking via DrugBank to the BNF monograph for Co-amoxiclav. More complex cases such as Adrenaline (British English) vs. Epinephrine (international naming) required a synonym expansion informed by DrugBank and PubChem to achieve the correct alignment of the entity.
Thus, the mapping strategy in medicX-KG was not a preparatory step but a core scientific contribution, enabling accurate integration of regulatory, clinical, and chemical knowledge. It established the semantic foundations necessary for the ontology design and for the subsequent clinical usability of the knowledge graph in real-world pharmacist settings.
To ensure persistence, disambiguation, and traceability across reconciled entities, each product in medicX-KG was subsequently assigned a globally unique URI, constructed from standardised product attributes (e.g. name, pharmaceutical form, marketing authorisation codes). In parallel, the mapping strategy preserved formulation specificity at the Product level, capturing differences between capsules, tablets, injectables, while unifying shared pharmacological properties at the Active_Ingredient layer. This layered abstraction was crucial for supporting fine-grained clinical queries without redundancy and laid the structural foundation for the ontology design.
Ontology designThe construction of medicX-KG involved a tightly integrated process of systematic data transformation and ontology schema design, both guided by the need to support pharmacist decision-making in regulated environments. Particular emphasis was placed on ensuring semantic precision, clinical relevance, regulatory traceability, and extensibility for future biomedical expansions.
Data Transformation ProcessFollowing entity mapping and reconciliation, curated pharmaceutical datasets were transformed into a formal semantic representation using the Resource Description Framework (RDF). A custom-built RDFizer tool, leveraging the Python RDFLib library,Footnote 2 was developed to automate this process. The tool parsed structured records from the Medicines Authority portal, BNF, and DrugBank, applied normalization procedures (e.g., unit standardization, casing harmonization, synonym disambiguation), and serialized the resulting data into RDF triples.
The transformation pipeline was designed to promote semantic interoperability and compliance with the FAIR (Findable, Accessible, Interoperable, Reusable) data principles [69]. Provenance was explicitly maintained through attribution properties, enabling every assertion within the KG to be traceable to its original source. Although the underlying architecture is complete, public release is pending the development of a continuous learning mechanism and further validation within pharmacist workflows, as outlined in the Future work section.
Ontology Schema DesignThe design of the medicX-KG ontology was structured to satisfy three principal objectives: (i) capturing clinical and pharmacological expressiveness relevant to pharmacist workflows, (ii) supporting semantic interoperability and property-rich reasoning, and (iii) enabling modular extensibility. A high-level representation of the medicX-KG T-Box schema, capturing its principal classes and object properties, is provided in Fig. 6.
At the core of the ontology, distinct classes represent:
Product: Specific medicinal products authorised in Malta, distinguished by formulation and strength.
ActiveIngredient: Chemical substances (INNs) encapsulating shared pharmacological properties.
Compound: Additional chemical constituents present within formulations.
Excipient: Non-active ingredients included in drug formulations.
Indication: Therapeutic conditions targeted by medicinal products.
Contraindication: Clinical scenarios where product use is contraindicated.
AdverseDrugReaction: Documented adverse events linked to product usage.
TherapeuticClass: Pharmacological groupings supporting therapeutic substitution.
ATCCode: Anatomical Therapeutic Chemical classification codes.
Storage: Regulatory and clinical storage requirements.
MarketingAuthorisation: Authorisation entities granting market approval.
MethodOfAdministration: Approved methods for administering drugs.
DrugDrugInteraction: Entities capturing pharmacokinetic or pharmacodynamic interactions between two or more active ingredients.
Fig. 6
High-level T-Box schema of medicX-KG, illustrating the principal classes and object properties that underpin the semantic structure of the knowledge graph. The ontology captures clinical, pharmacological, and regulatory information essential for pharmacist decision support in regulated environments
Each Product instance links semantically to its associated ActiveIngredient, as well as to clinical and regulatory concepts such as Indication, Contraindication, AdverseDrugReaction, Storage requirements, and MethodOfAdministration. ActiveIngredient nodes are cross-referenced with ATCCode classifications, supporting therapeutic grouping and substitution. Furthermore, DrugDrugInteraction nodes explicitly model clinically significant interactions, annotated with interaction mechanisms, clinical effects, and severity levels.
Unlike simpler pharmacist-facing datasets that capture drug attributes individually, medicX-KG models complex pharmacological and regulatory realities through semantically rich n-ary relationships. This enables more expressive queries, such as identifying contraindicated product combinations or retrieving storage-specific regulatory conditions, thus supporting evidence-based decision making in both clinical and regulatory contexts.
Critically, the ontology design of medicX-KG was deliberately aligned with the dual practical challenges pharmacists encounter: ensuring therapeutic appropriateness while adhering to regulatory frameworks. By integrating clinical entities (e.g., indications, ADRs, contraindications) with regulatory artefacts (e.g., marketing authorisations, storage requirements), medicX-KG provides a unified semantic infrastructure tailored to pharmacist needs. This design is particularly pertinent for smaller jurisdictions such as Malta, where pharmacists must navigate partially harmonised EU frameworks alongside non-EU supply chains, such as UK imports following Brexit. The ontology remains operationally lightweight for real-world usability while enabling structured, regulation-aware knowledge exploration.
Design PrinciplesSeveral key design choices underpin the semantic robustness and extensibility of medicX-KG:
Formulation granularity: Product nodes preserve dosage form specificity (e.g., capsule, suspension, injection), critical for dispensing accuracy.
Salt normalization: Variants are normalized at the ActiveIngredient level, with clinically relevant salt descriptors preserved at the Product level.
Therapeutic class linkage: ActiveIngredient nodes are cross-linked to ATCCode entries, facilitating therapeutic substitution workflows.
Interaction modelling: Drug-drug interactions are modelled as first-class entities, enabling property-rich annotation including severity, mechanism, and evidence source.
Evidence provenance: All assertions retain explicit source attributions (e.g., MMA portal, BNF, DrugBank), ensuring transparency and auditability.
Modular extensibility: The ontology is designed to accommodate future domains such as pharmacogenomics and real-world evidence without structural disruption.
In summary, the medicX-KG ontology and data transformation framework provide a structured, clinically relevant, and regulation-aware representation of pharmaceutical knowledge tailored to pharmacist decision support. The following sections present the evaluation results and discuss the clinical applicability, strengths, and limitations of the knowledge graph.
Comments (0)