This study aimed to evaluate the potential accuracy and relevance of ChatGPT in addressing medical questions related to meningioma therapy, as perceived by patients who underwent radiation treatment. Additionally, the quality of information was reviewed by clinicians to determine whether ChatGPT could effectively support patient education and decision-making without posing a safety risk.
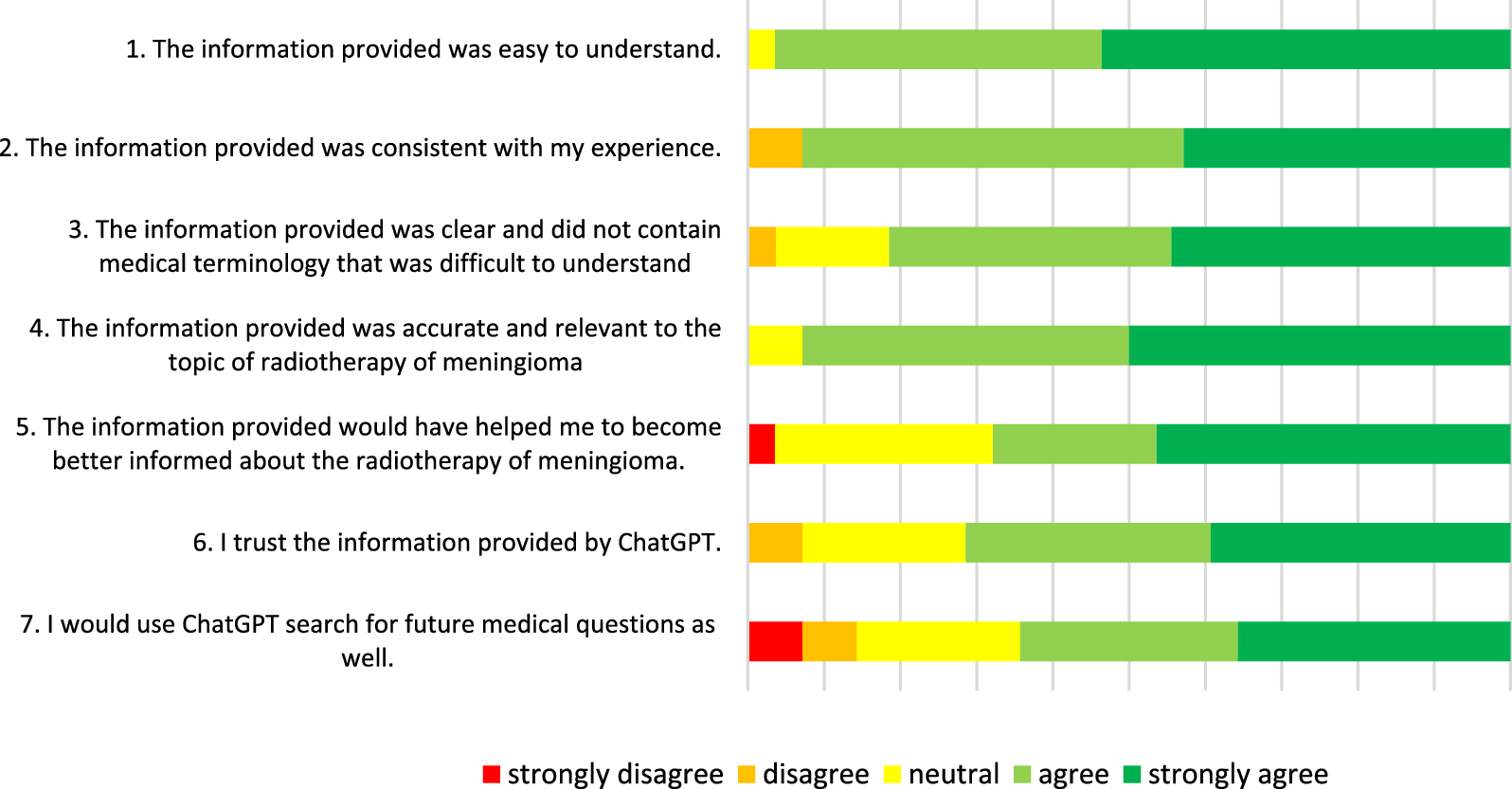
The current literature has primarily focused on rating ChatGPT’s responses by experts [7,8,9,10]. This study introduces also patient evaluations of ChatGPT-generated information on meningiomas. By enrolling patients who have already undergone radiation treatment, the study offers a unique perspective based on their firsthand experience with treatment outcomes and side effects. Patients were asked to review the information after their first follow-up meeting ensuring that acute toxicities had resolved and that they had sufficient time to reflect on their treatment experience. While one patient noted that the vocabulary of ChatGPT4 was difficult to read, most patients rated the answers clear and easy to understand. This may be biased by their prior exposure to medical terminology before and during the treatment. It should be noted that previous studies already described the tone used by ChatGPT as professional and concise [1]. This raises the question of whether its tone contributes to its trustworthiness, since more than 60% of patients enrolled in this study stated that they trust the information received by ChatGPT 4. On the other hand, the fact that about 90% of patients agreed that the information provided was consistent with their own experience surely also contributed to ChatGPT’s trustworthiness. Although patients completed the questionnaire after consulting with our physicians —which may have influenced them to underestimate the value of the LLM—they still gave high ratings to the information provided by ChatGPT-4.
ChatGPT was already investigated in various situations as a tool for support in cancer patients. Its utility expands from quick and free access to medical information to patient-friendly explanations of medical terms or side-effects [3, 8, 11]. This suggests that ChatGPT can serve as an accessible source of concise, relevant information and help simplify medical vocabulary for patient education. Patients in our study agreed that the information provided by ChatGPT 4 about the radiation treatment of meningiomas would have been helpful beforehand, indicating its potential educational role prior to treatment. Decision aids have been shown to be highly effective tools for both physicians and patients in the medical decision-making process [12]. Our findings indicate that ChatGPT could serve as a valuable resource by offering neutral and unbiased information to support shared decision-making. By helping patients gain a balanced understanding of their treatment options, ChatGPT can empower them to participate more confidently in discussions with their physicians. This approach has the potential to significantly enhance patient education, as increased patient involvement in health decisions has been linked to improved medical outcomes [12].
In their review Lleras de Frutos et. al demonstrated that internet use generally has a positive impact on the psychological well-being of cancer patients. However, they also identified forums and social media platforms as major sources of misinformation, which can contribute to confusion among patients. This issue appears to be particularly pronounced among older adults, who reported experiencing higher levels of anxiety and confusion after seeking medical information online. The confusion is likely attributable to the overwhelming volume of unfiltered information as well as the lack of specificity in online resources [5]. Similarly, our study found that 10% of meningioma patients included in the research disagreed with the consistency of information provided by ChatGPT 4 when compared to their personal experiences. This divergence underscores the limitations of standardized medical information in offering a nuanced and comprehensive understanding of individual conditions. To our surprise, ChatGPT refrained from offering very detailed medical advice. While this can be seen as a lack of specificity, it also avoids misinformation by ensuring that critical decisions—such as determining treatment regimens—remain under the purview of qualified medical specialists within the appropriate clinical context. This observation is encouraging and may suggest an ongoing improvement of ChatGPT, since older studies had noted that ChatGPT might also generate fabricated unreal data [13].
Overall, the five potential risks described by Liu et al., such as generating fake medical content, perpetuating bias, and raising privacy concerns, must still be considered when using LLMs. They discussed in their analysis the challenges of training AI systems for workflows in radiology and proposed guidelines for implementation in clinical practice. The authors highlighted issues such as the lack of generalizability, limited reproducibility, and ethical concerns related to data privacy and the potential for biases embedded in training data [14]. On this note, Leon et. al summarized the challenges posed specifically by the use of ChatGPT in the medical sector and proposed several ways of implementing the use of such a LLM safely, among which data protection and clear ethical guidelines [15]. Our study also proved that as LLMs should be used in optimizing the process of patient education only with rigorous professional – and human - oversight.
The additional clinician evaluation conducted in this study revealed that the responses generated by ChatGPT 4 were medically correct and relevant, consistent with findings from other studies on oncology-specific information [7, 10]. However, our clinicians were hesitant to consider the responses generated by ChatGPT 4 regarding radiation treatment of meningiomas as complete, with only 3 out of 8 questions scoring an average of more than 4 on the Likert Scale. Notably, the response concerning the radiotherapy-associated side effects scored the lowest score (3,2). This may be due to ChatGPT’s tendency to provide general answers that do not adequately address the complexity of a certain treatment administered to the brain. Considering the complex anatomy of the central nervous system, the range of expected side-effects both on short and long term can significantly vary based on the exact location of the meningioma. While the answer provided by ChatGPT 4 did not cover the full range of symptoms, it specified that the side-effects depend on the tumor localization. This raises the question of whether ChatGPT could deliver a more specific answer if provided with more detailed information about the localization and size of the meningioma. So far, Haemmerli et. al assessed ChatGPT’s ability to deliver treatment recommendations similar to those of interdisciplinary tumorboards by presenting 10 glioma cases including data regarding the histology, localization and size. While ChatGPT was able to offer general treatment recommendations for gliomas, it failed to specify the radiation and chemotherapy regimen and to consider the patient’s functional status for decision-making [16].
Following the announcement of ChatGPT 4o mini and the rise of other LLMs, we conducted an evaluation comparing the responses generated by three other large language models (LLMs): ChatGPT 4o mini, Gemini free and Gemini advanced. The assessment revealed that while ChatGPT 4o mini neither significantly outperformed nor underperformed its predecessor, both versions of ChatGPT were rated higher than Google's Gemini models—both the free and paid advanced versions—in terms of correctness, relevance, and completeness. The assessment also revealed that over 50% of clinicians selected the ChatGPT versions as the most appropriate for correctness, eloquence, and comprehensiveness.
One limitation of this study is the small cohort size, influenced by various factors such as limited time availability. Moreover, the sample is disproportionately composed of female participants, likely reflecting the higher prevalence of meningiomas among women. While the limited sample size constrains the generalizability of the findings, the study nonetheless provides a foundational basis for future prospective investigations involving larger, more diverse cohorts. Subsequent studies should also consider collecting data on participants’ educational backgrounds and incorporating open-ended questions to facilitate the inclusion of qualitative insights.
A notable strength of this study lies in its combined patient and clinician perspectives, providing a more comprehensive assessment of ChatGPT’s potential in patient education. By evaluating how well AI-generated information meets patient needs for clarity and usefulness—while simultaneously verifying its medical accuracy, completeness, and relevance through clinical review—we can gain deeper insight into how LLMs can be effectively integrated into healthcare. Future research could assess the robustness of large language models (LLMs) in more complex and uncertain clinical scenarios. Specifically, within the context of radiotherapy, the reliability of LLMs may be evaluated in the assessment of acute toxicities. Additionally, LLMs hold potential for integration into decision-support frameworks aimed at facilitating shared decision-making during physician–patient consultations.
Furthermore, the study’s comparison of ChatGPT with three other large language models underscores differences in performance, reinforcing the value of rigorous, multifaceted evaluations in guiding their safe and optimal implementation. Although the patient sample size may be a limitation, this dual-perspective design remains pivotal in ensuring that both user experience and professional standards are addressed.


Comments (0)