
Remember me
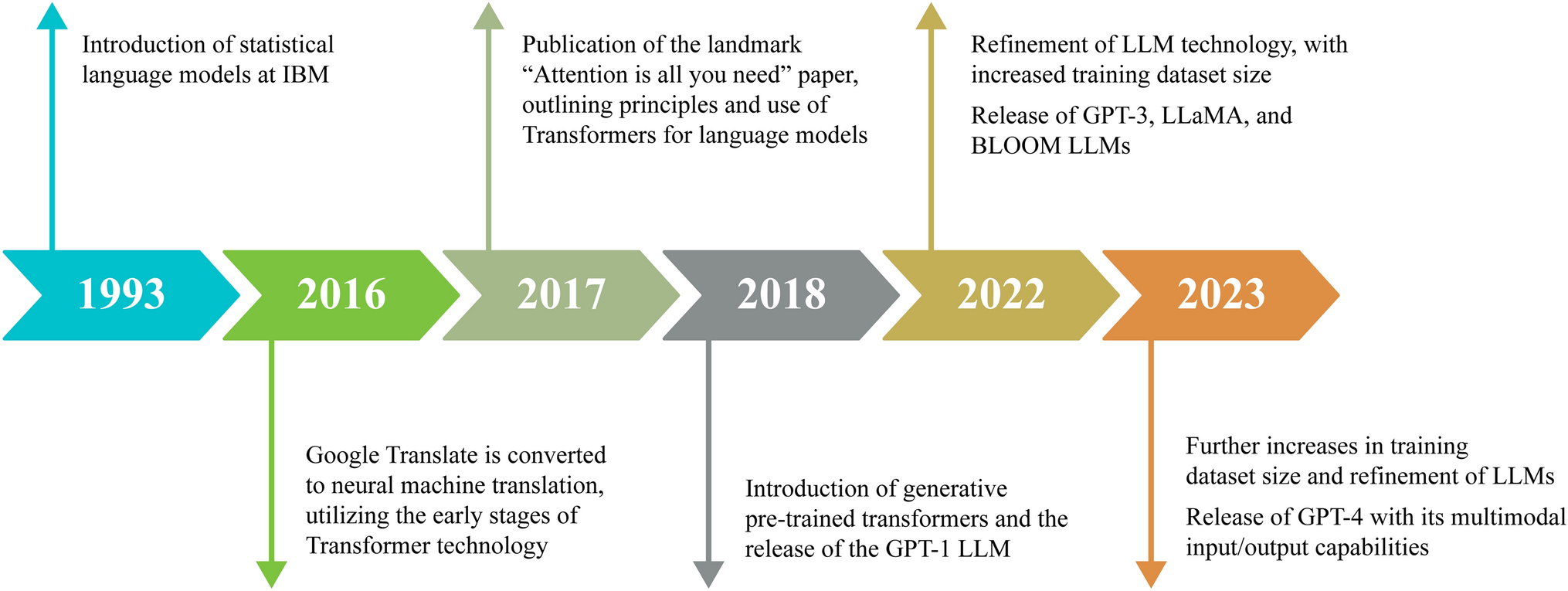
Given their advanced capabilities, LLMs are actively transforming clinical practice, including perioperative medicine. In Figure 3 and the following sections, we outline these practical applications and their potential to transform patient care, which includes decision support systems, patient education tools, diagnostic assistance, and administrative task automation. Each application aims at improving the quality, efficiency, and personalization of perioperative care.
Fig. 3
Clinical applications of large language models in perioperative medicine
Medical diagnosis and risk stratificationIn fast-paced perioperative environments, rapid and accurate diagnosis is essential for effective surgical planning and management. This requires synthesizing diverse clinical data, including patient history, physical exams, lab results, and imaging studies. A recent study by Liu et al. evaluated the diagnostic accuracy of GPT-3.5 and GPT-4.0 for colon cancer diagnoses across seven categories, such as symptoms, lab results, and intraoperative findings.16 GPT-4.0 significantly outperformed GPT-3.5 in both primary and secondary diagnoses. The mean (standard deviation [SD]) accuracy rate for primary diagnoses was 0.97 (0.14) for GPT-4.0 and 0.85 (0.33) for GPT-3.5 (P < 0.001). Similarly, for secondary diagnoses, GPT-4.0 achieved a mean (SD) accuracy of 0.91 (0.16) vs 0.62 (0.35) for GPT-3.5 (P < 0.001).
Large language models also show potential in risk stratification by analyzing large datasets and identifying patterns in medical records and clinical data.17 For instance, Lim et al. used 10 standardized hypothetical patient scenarios to show that GPT-3.5-turbo consistently classified patients according to the American Society of Anesthesiologists Physical Status (ASA-PS) score, performing comparably to anesthesiologists with a Fleiss’ kappa of 0.62.18 The authors further validated these findings with variations of the patient scenarios, where the model achieved Fleiss’ kappa scores of 0.73 and 0.60, indicating substantial agreement.
While LLMs have shown promise in simulations, they have yet to be adopted in routine clinical practice. Large language models’ integration into perioperative care could improve diagnostic accuracy and enable timely risk mitigation strategies. Future research should focus on real-world clinical applications to fully assess their impact.
Patient care: patient-facing education materialThe ASA holds anesthesiologists responsible for ensuring that patients understand and adhere to preoperative instructions, which should be presented at an appropriate literacy level.19,20 Nevertheless, studies show that most written materials are too complex for the average patient, contributing to nonadherence, delayed or canceled surgeries, and worse outcomes, further exacerbating health care disparities.21,22
Large language models can personalize information on surgical risks, preoperative instructions, and postoperative recovery by adapting content to patients’ reading levels. For instance, Hong et al. compared standard English-language preoperative instructions with those enhanced by language models and found that GPT-4 improved the readability to a sixth-grade level, outperforming GPT-3.5 (mean readability score of 5.0 [0.76] vs 10 [0.37]), while maintaining accuracy and detail.23 GPT-4’s preoperative instructions were significantly less complex across all patient scenarios than both the standard hospital text (P < 0.01) and GPT-3.5 (P < 0.01).23 The assessment of accuracy and completeness showed no missing, inaccurate, or incomplete information.23 Similar improvements have been observed in the creation of postoperative instructions for common surgeries.24,25
By leveraging LLMs, perioperative clinicians can produce tailored, easy-to-understand patient education materials, enhancing comprehension and ultimately improving patient outcomes. Nevertheless, ensuring the accuracy and reliability of LLM-generated content is crucial to maintain patient safety.
Patient care: patient-facing ChatbotClear perioperative instructions can ease postoperative recovery, reduce anxiety, and shorten hospital stays.26 Large language model-powered chatbots provide 24/7 support by assisting with scheduling, reminders, health assessments, and answering common questions. Patnaik et al. examined how well LLMs could respond to anesthesia-related queries from a patient’s perspective.27 Patients indicated that ChatGPT’s linguistic quality was 19.7% better than Bard’s (ChatGPT: 66.2 [13.4] vs Bard: 55.3 [11.8]; P < 0.001). Nevertheless, the issue of hallucinations—plausible but incorrect responses—remains a concern, especially with Bard. Notably, ChatGPT provided no incorrect answers or hallucinations, whereas Bard had a marked error rate (0 out of 33 queries for ChatGPT vs 10 out of 33 for Google Bard, resulting in a 30.3% error rate).
Large language models can offer personalized, accessible responses to each patient’s questions on procedure, recovery, and concerns. Integrating LLMs into clinical practice could allow patients to explore the surgical process, learn pain management techniques, and reduce anxiety, promoting a more personalized and informed perioperative experience. While LLM-powered chatbots show promise for personalized patient education, further efforts are needed to reduce hallucinations and rigorously compare LLM performance against clinicians.
Clinical decision supportPerioperative clinicians face time-sensitive decisions that can significantly affect patient outcomes and safety. Cognitive errors, often exacerbated by fatigue or inexperience, contribute to over half of the adverse events reported in clinical settings.28,29 To mitigate this, LLMs are increasingly being explored for their ability to quickly process vast datasets, offering enhanced predictive and classification capabilities that can support decision-making. These models improve health care quality and efficiency by helping clinicians navigate complex clinical scenarios and deliver personalized care.30,31
AI-driven clinical decision support systems integrate diverse perioperative data, from imaging trends to medication adjustments, to predict critical events. These systems also enhance access to the relevant literature, streamline chart reviews, improve documentation, and provide real-time recommendations.32,33 In a recent study, Gomez-Cabello et al. compared the performance of ChatGPT-4 and Google’s Gemini Pro for intraoperative decision-making in plastic and reconstructive surgery using 32 independent intraoperative scenarios spanning five procedures.34 The authors used 5-point and 3-point Likert scales to assess the medical accuracy and relevance, respectively, as well as model response time. While both models demonstrated sufficient knowledge to assist surgeons, ChatGPT-4 significantly outperformed Gemini in terms of accuracy (3.6 [0.8] vs 3.1 [0.8], P = 0.022) and relevance (2.3 [0.8] vs 1.9 [0.8], P = 0.032). Nevertheless, Gemini provided notably faster response times (8.1 [1.4] sec vs 13.7 [2.9] sec, P < 0.001). Although promising, further validation of LLMs in real-time surgical environments is needed, considering the dynamic, high stakes nature of perioperative care.
Resource allocation and administrationPerioperative care involves a coordinated network of professionals, technology, and processes. Large language models, combined with clinician expertise, can enhance resource allocation by predicting factors such as ASA-PS scores, intensive care unit (ICU) admissions, hospital mortality, and surgical outcomes. Nevertheless, current models struggle with accurately predicting the duration of postoperative recovery, including time spent in the postanesthesia care unit (PACU) and hospital.35
Chung et al. investigated the capabilities of GPT-4 Turbo in risk stratification and the prediction of postoperative outcomes.35 The authors examined the model’s ability to explain its decisions on the basis of descriptions of procedures and the patients’ preoperative clinical notes.35 GPT-4 Turbo achieved an F1 score of 0.50 for ASA-PS, 0.6 for hospital admissions, 0.8 for ICU admissions, 0.6 for unplanned admissions, and 0.9 for predicting hospital mortality.35 While these scores indicate a balanced performance (F1 score ≥ 0.50), the model struggled to accurately predict duration outcomes, such as PACU phase 1 duration, hospital length of stay, and ICU duration.35
Danilov et al. corroborated the challenges faced by LLMs in predicting length of stay, by comparing physician estimates with the Russian-language version of GPT-3 in predicting patient length of stay in neurosurgery, using mean absolute error (MAE) in days.36 The analysis of narrative medical records by ruGPT achieved accuracy comparable to, but still inferior to, that of physicians and patients, with MAE values of 3.5, 2.5, and 3.5, respectively. This integration of LLMs with clinician expertise can optimize workflow efficiency, improving predictions of case durations, hospital stays, and workforce scheduling.37,38 Nevertheless, LLMs still need to enhance their performance in accurately predicting length of stay.
Administrative tasks, such as patient registration, billing, documentation, and scheduling consume significant clinician time, reducing overall care quality.39 Recent research found that ChatGPT-4 efficiently generated billing codes, thus alleviating some of these burdens.40 Ongoing studies are investigating how LLMs can further optimize operating room scheduling and improve efficiency, potentially reducing clinician burnout.
Automated medical report synthesis from imaging dataRapid bedside imaging, particularly whole-body point-of-care ultrasound (POCUS), plays a vital role in perioperative diagnosis and clinical management. The use of GPT models to assist in interpreting imaging findings is a growing area of interest.41,42 In addition to image interpretation, report generation also remains a time-intensive task, often involving the synthesis of images, clinical notes, and other documents—processes that are prone to human error and dependent on the clinician’s experience level. Automating report generation has emerged as a priority owing to its potential to improve efficiency and reduce errors.43 Bernardi et al. highlighted that Llama LLMs, when equipped with retrieval-augmented generation (RAG), can access and utilize external information to generate responses.44 Retrieval-augmented generation enables LLMs to provide more accurate and relevant answers, surpassing existing radiology reporting methods in both quality and accuracy. While these findings are primarily from radiology, LLMs application to POCUS could revolutionize perioperative care by improving the diagnostic accuracy and efficiency. Combining LLMs with clinician oversight could reduce the time spent on report generation, allowing for faster, more accurate clinical decision-making.
Medical educationLarge language models, such as ChatGPT, have gained prominence in medical education by achieving performance levels comparable to or surpassing thresholds on medical licensing exams, suggesting potentially impactful applications in medical education.45 For instance, Subbaramaiah et al. demonstrated that GPT-3.5 could generate multiple-choice questions for regional anesthesia fellowship exams, with half of the candidates rating the LLM-generated exams as superior to previous versions. Nevertheless, human oversight is essential to correct factual inaccuracies and grammatical errors.46
In addition to generating exam questions, these models can draft admission applications, raising serious concerns about the integrity of the application process. Studies by Johnstone et al. and Patel et al. found that LLM-generated personal statements for residency applications were often indistinguishable from those written by applicants; in fact, 80% of program directors could not tell the difference between the two.47,48 While LLMs hold promise for supporting exam preparation, their practical implementation in medical education faces challenges related to academic integrity and error detection.
Research medical literature analysisThe increasing volume of scientific literature generated annually can overwhelm perioperative researchers and clinicians, making it difficult to identify relevant data. As a result, the demand for systematic reviews has grown significantly over the past few decades. Nevertheless, completing these reviews requires substantial time and resources. The National Institute for Health and Care Excellence (NICE) has recognized the potential of AI, particularly LLMs, to automate the systematic review process, reducing both the time and effort required.49
Large language models have also been used to draft, edit, and guide writing in perioperative topics. Nevertheless, their outputs often suffer from hallucinations, which are plausible yet incorrect information, as well as poor organization.49 Studies by Hallo-Carrasco et al. and Wu et al. noted that LLMs lacked methodological rigor and originality in their analyses.50,51 While earlier studies by Grigio et al. identified fabricated references, more recent research by Boussen et al. found that ChatGPT-4, when combined with better prompts and plugin integration, generated more accurate citations.52,53 This suggests that ongoing developments, including web integration, have improved the utility of LLMs for literature review tasks. With careful oversight, LLMs hold the potential to streamline research efforts and revolutionize academic work.
The International Committee of Medical Journal Editors (ICMJE) now requires authors to disclose the use of AI-assisted technologies in manuscript preparation, including this information in both the manuscript and the cover letter. AI technologies cannot be credited as authors due to several ICMJE authorship criteria being unmet, such as the ability to take responsibility for published work, declare competing interests, and engage in copyright and licensing agreements. As a result, human authors must ensure that all AI-generated content is accurate and free from errors, fabrications, and plagiarism. Additionally, AI-assisted technologies should not be cited as primary sources, as information is merely replicated from other sources, which can often be inaccurate or of questionable quality.54
While LLMs hold significant promise for medical literature analysis, realizing their full potential requires a critical evaluation of the limitations and challenges they present, both in academia and routine clinical practice.
Comments (0)