The present study evaluated the reliability of two off-the-shelf LLMs (i.e., ChatGPT and Gemini) when used to assess the causality assessment of AEFI reports related to COVID-19 vaccines and myocarditis and pericarditis with the WHO algorithm. Our results align with the considerations provided by Matheny et al. (2024) and others, who highlight the potential of LLMs in post-marketing surveillance. Matheny and colleagues’ discussion underscores key challenges associated with the use of LLMs in pharmacovigilance, such as the need for prompt engineering, computational infrastructure, and the risk of generating nonfactual statements that could impact regulatory decision-making. Specifically, our findings support Matheny et al.’s expectation that LLMs function best as complementary tools rather than standalone solutions [25, 31, 32].
4.1 Implementation
The implementation was feasible. Several advantages and disadvantages of implementing these LLMs in the causality assessment process were found. ChatGPT was noted for its ease of use and flexibility because it can manage sessions separately for each case, combined with the option to correct errors without restrictions, providing significant operational flexibility. ChatGPT also supports team collaboration through link-sharing and can be integrated with statistical software via APIs, which facilitates automation. However, ChatGPT did have several drawbacks, including occasional speed issues, for example, it often took more than 5 min to generate the output, and the generation of non-existent references.
Gemini allowed for continuity in conversations without the need for an active session, which could enhance workflow efficiency and shared many of the same advantages as ChatGPT, such as team collaboration capabilities, session management, and integration with APIs. Gemini exhibited similar limitations. Notably, Gemini’s use of synonyms sometimes caused confusion in the categorization of causality scores, for example, it used classes that were not among those described in the algorithm. Furthermore, Gemini occasionally refused to perform causality assessments unless clearly specified as part of a research project. Additional limitations were identified for both LLMs during the evaluation process. One of the most critical issues in the implementation of the LLMs was the inability of both LLMs to accurately identify AEFIs that were already listed in the FDA Prescribing Information of the vaccines or recognized that they were well established AEFIs in the peer-reviewed biomedical literature. This limitation is particularly problematic because recognizing previously documented AEFIs is a key component of the WHO causality assessment algorithm. Additionally, both ChatGPT and Gemini often failed to assign the correct causality classification output, often deviating from the WHO algorithm’s step-by-step instructions, which compromised the reliability of the assessment.
4.2 Algorithm Adherence
ChatGPT demonstrated a higher overall adherence rate compared to Gemini. This discrepancy underscores the variability in how different LLMs interpret and follow the structured, rule-based algorithms that are essential in causality assessment. The differences in adherence could be attributed to the inherent language-processing capabilities of the models and their ability to handle complex, algorithmic reasoning [33].
Both LLMs performed better with cases that involved lower string complexity in the prompt sections. These findings suggest that the LLMs may struggle with more complex or nuanced inputs, which often contain multiple medical terms, abbreviations, or convoluted case histories. Simpler cases allowed the models to follow the algorithm more closely, whereas more detailed or intricate cases likely increased the cognitive load on the models, leading to lower adherence rates [33].
The underperformance of LLMs in causality assessment with the WHO algorithm may stem from difficulties for the LLMs in connecting sub-questions and aligning them with overarching rules of the algorithm. While ChatGPT performed relatively well on individual questions within the assessment process, it was often not able to integrate these answers into a coherent, rule-based conclusion. This disconnect can be compounded by the variability in prompt strategies, where certain prompts elicit better responses than others, leading to inconsistent results.
4.3 Predictive Model for Adherence
The RF model demonstrated poor accuracy for predicting adherence. Considering the sensitivity, specificity, PPV, and NPV, we concluded that the RF model had a moderate to low capacity to predict adherence based on the features present in the prompts. The most important terms identified by the RF model included “patient,” “myocarditis,” “pericarditis,” and “chest.” These medical terms appeared frequently in both adherent and non-adherent cases, but all adherent cases contained at least one of these key terms. This suggests that adherence may be influenced by the presence of specific medical terms in the prompts, although the mere presence of these terms is not sufficient to guarantee adherence. Also, when combination of words was considered for predicting adherence in conditional inference trees, we were not able to find discriminative patterns between adherent and non-adherent cases.
4.4 Human Expert versus LLM Classification Agreement
The variability in agreement between the LLMs and the human expert suggests that while LLMs can be useful tools, they cannot yet replace the nuanced decision-making process that human experts provide. The moderate agreement achieved by ChatGPT indicates that it might be more aligned with human reasoning compared to Gemini, yet it still requires improvements to achieve higher levels of reliability in critical decision-making tasks like causality assessment.
4.5 Human Expert versus LLM Reasoning Agreement
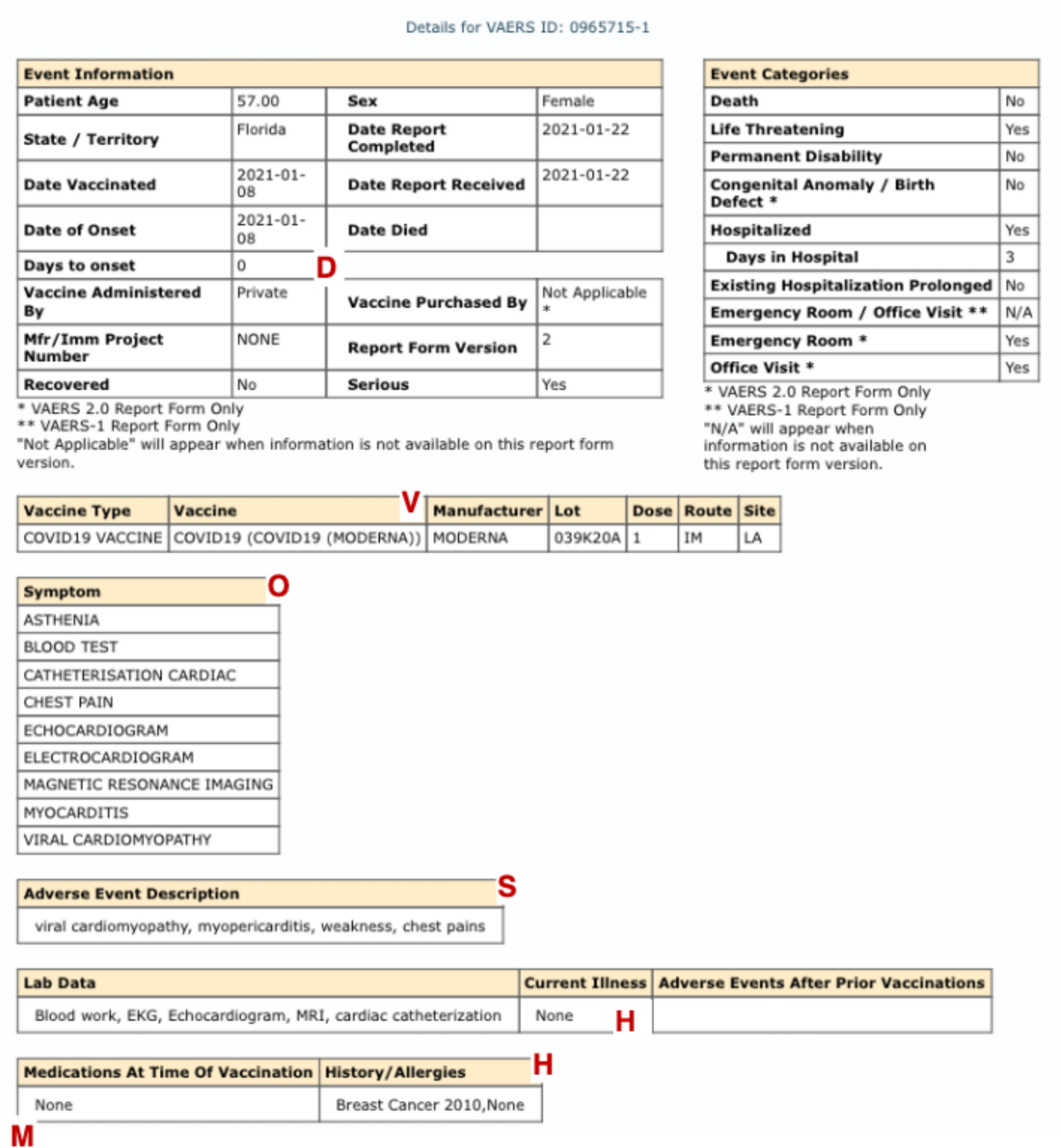
Inconsistent reasoning was observed in both ChatGPT and Gemini across several areas of the assessment. For Question 1, both LLMs required additional information to identify alternative causes for the AEFI and, in some cases, failed to recognize existing risk factors provided in the prompt (e.g., H: and M: sections). Similarly, for Question 2.1, both models occasionally disregarded available scientific evidence, incorrectly stating that there was no evidence, or that the evidence was not definitive, despite peer-reviewed literature supporting the vaccine’s causation of the event. When temporal plausibility was assessed, both models incorrectly evaluated the temporal relationship in a small proportion of cases (3.3% for ChatGPT and 6.7% for Gemini). Finally, in the final assessment, both LLMs struggled to provide coherent classifications consistent with their responses to preceding questions.
The variations in reasoning agreement between the human rater and the LLMs suggest differences in handling reasoning tasks of varying complexity. However, particularly with integrating multiple pieces of information, errors often occurred. This aligns with research indicating that LLMs tend to falter in tasks requiring deeper cognitive integration and nuanced understanding of domain-specific knowledge [33].
4.6 Strengths and Limitations
This study provides significant novelty by exploring the application of two off-the-shelf LLMs, ChatGPT and Gemini, in the context of causality assessment for vaccine-related AEFIs, specifically myocarditis and pericarditis following COVID-19 vaccination. The analysis, which covers algorithm adherence, agreement with human experts, and reasoning consistency, provides a robust evaluation of the potential of LLMs in pharmacovigilance. Furthermore, by using multiple LLMs and assessing inter-rater reliability among human experts, this work offers valuable insights into the comparative strengths and weaknesses of AI-driven decision support systems versus expert human judgment.
Several limitations need to be acknowledged. First, we used only one type of prompt, and did not investigate how different prompt-engineering strategies might improve the performance of off-the-shelf LLMs. Prompt optimization could be a critical factor in enhancing LLM accuracy and consistency. Second, this study was conducted retrospectively, meaning that much of the information regarding the association between the WHO algorithm and the AEFI of interest was already known at the time of the experiment, potentially influencing LLM performance and assessment strategies. Third, the study relied on information reported in the VAERS, which is known for its limitations, including variability in data quality and completeness, possibly affecting the robustness of LLM outputs.
Additionally, there is inherent subjectivity in the assessments performed by the human experts, particularly when comparing the reasoning agreement between LLMs and expert itself. Finally, this study focused on testing LLM performance using a relatively complex causality assessment algorithm (i.e., WHO algorithm). We did not investigate LLM performance with simpler algorithms, which might be more suitable for automated processing.
Our study did not aim to develop a fully autonomous pipeline for causality assessments but rather to evaluate the feasibility of using off-the-shelf LLMs as supportive tools and understand in which processes of the causality assessment they could be useful. Given the surge in vaccine safety reports during the COVID-19 pandemic, our motivation was to explore whether LLMs could have assisted in streamlining assessments, particularly by reducing the burden of manual reviews. How LLMs perform in other settings (e.g., drugs) is the subject of ongoing research. It should be highlighted that expecting LLMs to perform reliable causality assessments in rapidly evolving contexts, such as pandemics, could be challenging if relying solely on their pre-trained knowledge base. However, this limitation is mitigated by modern retrieval-augmented generation (RAG) approaches, which allow LLMs to incorporate newly available information dynamically without requiring retraining. By leveraging external, up-to-date sources, RAGs can help LLMs adapt to fast-paced scenarios like COVID-19 vaccinations, ensuring that assessments are based on the latest scientific knowledge.
We purposely used off-the-shelf LLMs, which means that no hyperparameter tuning was performed and default settings were used. The reason was to investigate the impact of using an off-the-shelf LLM as it is to investigate individual causality.
Finally, a key limitation of our study is the potential variability in the quality of the VAERS data, which may affect the reliability of the findings. Additionally, the publicly available VAERS dataset does not include the follow-up information received by the FDA and CDC, which can contain important updates or corrections to the initial reports. While the WHO causality algorithm explicitly requires access to the full data source including follow-up, there is no specific algorithm that is recommended for usage for vaccine reports without follow-up, a very common occurrence in pharmacovigilance; clearly, however, this absence of follow-up limits our ability to assess the full clinical course of reported adverse events, thereby making causality assessment in these cases more challenging.
4.7 Future Work
In future work, it will be important to explore several prompt strategies to optimize the performance of LLMs in causality assessment. A preparatory phase will be crucial to “calibrate” the prompting strategy on a small subset of cases, adjusting until the LLMs demonstrate consistent performance. Once this calibration is achieved, these optimized prompts will be applied to the larger dataset for the main analysis, ensuring a more reliable and effective causality assessment.
Additionally, assessing different LLM architectures will help identify the most suitable models for this task. Expanding the scope to include a broader range of adverse events and causality assessment algorithms is necessary to provide more robust and conclusive insights into the ability of the LLMs to effectively assess causality in various contexts.
We used a standard setup for sentiment analysis and did not extensively tune it for prediction purposes. However, we do not believe this significantly impacted our results. This conclusion is supported by the fact that we tested not only the aggregated sentiment of the cases but also individual words and their combinations as predictors, none of which showed highly predictive value. Additionally, we considered all case characteristics as potential predictors, suggesting that the variability in adherence may be attributed more to randomness than to the specific features used in our prediction model.


Comments (0)