
Remember me





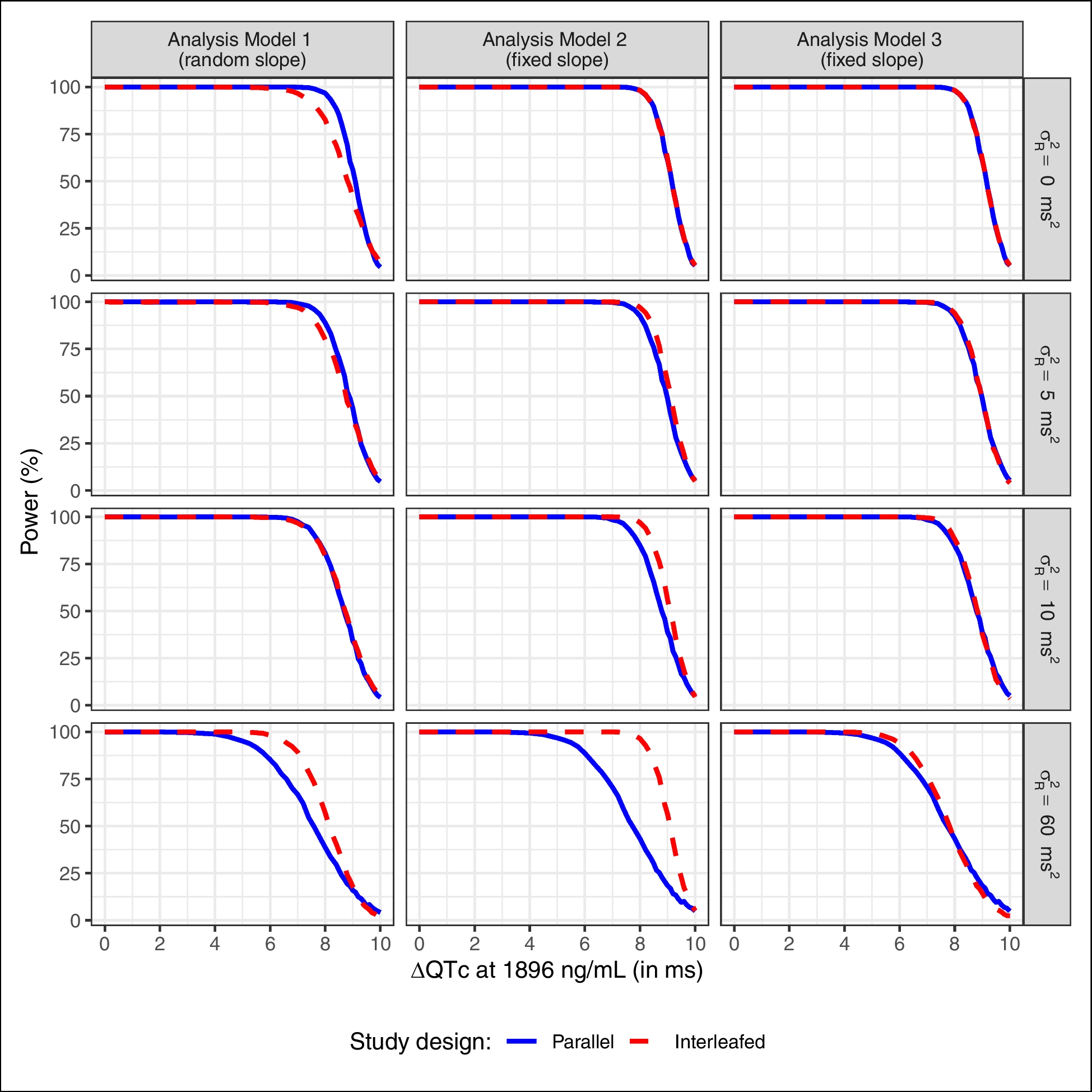
This Appendix outlines the detailed theoretical basis for the IR-MC algorithm.
Iterative reweighting MC algorithm for aggregate dataThe algorithm estimates population parameters through maximizing the loglikelihood of the estimated summary metrics \((\widetilde\boldsymbol,\widetilde)\) based on N individuals sharing a study design. In this method \(\tilde\) and \(\widetilde\)are calculated as a Monte Carlo integral of elementary predictions \(\dot y_\)weighted by a vector \(\boldsymbol w\).
Here, \(_\) represents the prediction for the k-th measurement or output based on the i-th Monte Carlo sample of the individual parameter vector, computed as:
$$\dot y_=f_x(\dot_,\xi_)$$
(A1)
With the individual parameter vector \(\dot_\)is defined as:
$$\dot_=g(,\dot_i\boldsymbol),$$
(A2)
where \(g(.)\) is a function defining the individual parameters as a function of fixed effects and random effects, \(\boldsymbol\) is the Cholesky decomposition of \(\boldsymbol\Omega\), and \(\dot_\) is the ith set of Sobol-sampled vectors with a mean of zero and standard deviation of one [7, 8]. We use \(\boldsymbol\Psi\) to define the set of all parameters, including the fixed-effects vector \(\boldsymbol\beta\:\), random effects variance-covariance matrix \(\boldsymbol \Omega\) and the residual variance matrix \(\boldsymbol\Sigma\).
Using the elementary predictions \(}_\) calculated in Eq. 2, the predicted mean at the \(k\)-th measurement is computed by:
$$\widetilde_k = \boldsymbol \kappa_k + \sum_^} w_i \dot_$$
(A3)
Equation 4 introduces the term \(_\), which is explained in detail in Eq. 8. For now, we briefly mention that this term is necessary for the estimation of fixed effects parameters that are not associated with a random effect.
The predicted variance-covariance matrix \(\widetilde\) can be computed element by element. The covariance between \(k\)-th and \(l\)-th measurement, \(\widetilde _\) can be calculated as
$$\widetilde_=\sum_^}w_i\left(\left(\dot_-\widetilde_k\right)\left(\dot_-\widetilde_l\right)+N_\right)$$
(A4)
Where \(N_\) is the impact of the residual variability on the diagonals of \(\widetilde \) and is calculated by linearizing the residual error function h(.) with respect to the residual error term \(\boldsymbol \epsilon\) as follows:
$$N_=\left\\left(\frac_i,\;\xi_,\;\boldsymbol \epsilon_=0\right)}}\right)&\boldsymbol \Sigma&\left(\frac_,\;\xi_,\;\boldsymbol \epsilon_=0\right)}}\right)^T&if\;k=l\\&0&otherwise\\&\end\right.\\\\\\\\$$
(A5)
The weights \(_\) of the previously generated elementary predictions can be updated based on current parameter estimates \(\boldsymbol \Psi\). Each weight \(\:_\) reflects the relative importance of sample \(\dot\) by comparing the likelihood of the sample under the target distribution \(p(\dot\vert \boldsymbol \Psi)\) with its likelihood under the original proposal distribution \(q(\dot)\):
$$\:\beginw_i(\boldsymbol \Psi)=\:\frac_i\vert \boldsymbol \Psi\right)q\left(\dot_i\right)^}_j^}\left(p\left(\dot_j\vert \boldsymbol \Psi\right)q\left(\dot_j\right)^\right)}\end$$
(A6)
Thus, it is possible to generate an updated set of predictions on the basis of previously generated elementary predictions calculated on the basis of previously generated individual parameters \(\dot_i\), and on the basis of a new set of parameters \(\boldsymbol \Psi\) by emphasizing those individual parameter values that are more likely under the new set of \(\boldsymbol \Psi\) when compared to the parameters that were used in obtaining the previously generated elementary predictions. This allows the reweighting of all individual parameters associated with a random effect.
In the case wherein an individual parameter is not associated with a corresponding random effect, in our opinion the most efficient solution is to compute a correction term \(\boldsymbol \kappa\) to account for fixed effects that apply consistently across all individuals, without inter-individual or inter-occasion variability. Elements of \(\boldsymbol\kappa\) were already included in Eq. 4. Now we outline how the correction factor for the k-th prediction is calculated.
$$\:\begin_k=f_k\left(g(\acute ,\overrightarrow),\xi_k\right)-f_k\left(g(\dot,\overrightarrow),\xi_\right)\end$$
(A7)
Where \(\overrightarrow\) is a vector of zeros with length equal to the number of random effects, \(\dot\) is the previous set of fixed effects used to generate the set of elementary predictions, and \(\acute\) is a vector consisting of a mix of both previous and current fixed-effects estimates; the fixed effects not associated with random effects are set to current estimates, whereas the rest of the fixed effects are set to previous values that were used to generate the set of elementary predictions. This way, the \(_\) only reflects the differences in predictions between the previous and the updated fixed-effects parameters not associated with random effects. The value of \(_\) is fast to compute, because it is not integrated over the random effects values but rather computed with an assumption of random effects being zero.
The eventual IR-MC algorithm updates parameters in two main steps, which are iterated through until a convergence criterion is met:
Step 1: Elementary predictions \(}_\) are computed using the current parameter estimates according to Eqs. 2 and 3, with an option to expand the current values of \(\boldsymbol \Omega\) by a scaling factor \(\rho\:\) which broadens the proposal distribution, allowing the iterative reweighting algorithm to explore beyond the strict proposal space implied by the current parameter estimates, and to accelerate convergence. The probability densities of the proposal distribution are stored into memory and treated as constant.
Step 2: Treating the elementary predictions \(}_\) and proposal distribution densities as constant, the parameters \(\boldsymbol \Psi\) affect predictions through weights which are calculated according to Eq. 7, through correction factor \(\:\varvec\) as defined in Eq. 8, and through residual error contribution terms as defined in Eq. 6. These terms are then used to update the predicted mean vector according to Eq. 4, and the predicted variance-covariance matrix according to Eq. 5. Parameters are estimated by maximizing the log-likelihood according to expression 3 using the predicted mean vector and variance-covariance matrix.
Original MC algorithm for aggregate dataFor the purposes of the aggregate data MC approximation in the original paper, are \(\boldsymbol w\) set to the number of MC samples \(\:_^\), making it a special case of the IR-MC algorithm. When weights are calculated as \(\:_^\), then Eqs. 5 and 6 together correspond to Eq. 18 from the previous study [1].
Thus, given that \(_=_^\) for all of \(\:_\) and thus not needing to be updated during step 1, and given that \(_\) in Eq. 4 is zero in the case of aggregate data MC approximation, fitting models to data using the aggregate data MC approximation can be accomplished by iteratively updating all the elementary predictions \(}_\) as a function of the current estimates of \(\:\varvec\) and then recomputing \(\widetilde \) and \(\widetilde \) the on the basis of these elementary predictions. Therefore, fitting models to data under maximum likelihood estimation, represents the following optimization problem:
$$\:\begin\text\underset,\widetilde \vert \boldsymbol \Psi}}\left(\text\left(L\left(\overline ,\boldsymbol V\vert\widetilde ,\widetilde \right)\right)\right)\end$$
(A8)
Optimized IR-MC function for practical applicationAn optimized function using the new IR-MC algorithm is included in the package. The core algorithm as outlined in the sections above remains the same. However, to ensure proper loglikelihood landscape exploration, two computational steps were added. First, sequential phases using different adaptive search bounds can be specified to more efficiently explore the loglikelihood space. This phased approach helps to map high-probability regions. The time spent in each phase, and the search bounds can be specified by the user. Secondly, multiple independent chains can be initialized with user-defined perturbations (using additive proportional Gaussian noise) applied to the starting values. This implementation increases the searched likelihood space, which enhances likelihood maximization.
Appendix BTwo compartmental modelFig. 4
Relative bias for the estimated parameters of the two compartmental model on all fixed and random effects of the model for 20 simulations, estimated using two methods (MC, IR-MC). Bias is measured as a percentage of the true parameter. Each model shows a boxplot of near-zero bias in the fixed effect and random effect
Simplified two compartmental modelFig. 5
Relative bias for the estimated parameters of the simplified two compartmental model on all fixed and random effects of the model for 20 simulations, estimated using two methods (MC, IR-MC). Bias is measured as a percentage of the true parameter. Each model shows a boxplot of near-zero bias in the fixed effect and random effect
Transit absorption modelFig. 6
Relative bias for the estimated parameters of the transit absorption model on all fixed and random effects of the model for 20 simulations, estimated using two methods (MC, IR-MC). Bias is measured as a percentage of the true parameter. Each model shows a boxplot of near-zero bias in the fixed effect and random effect
Comments (0)