
Remember me

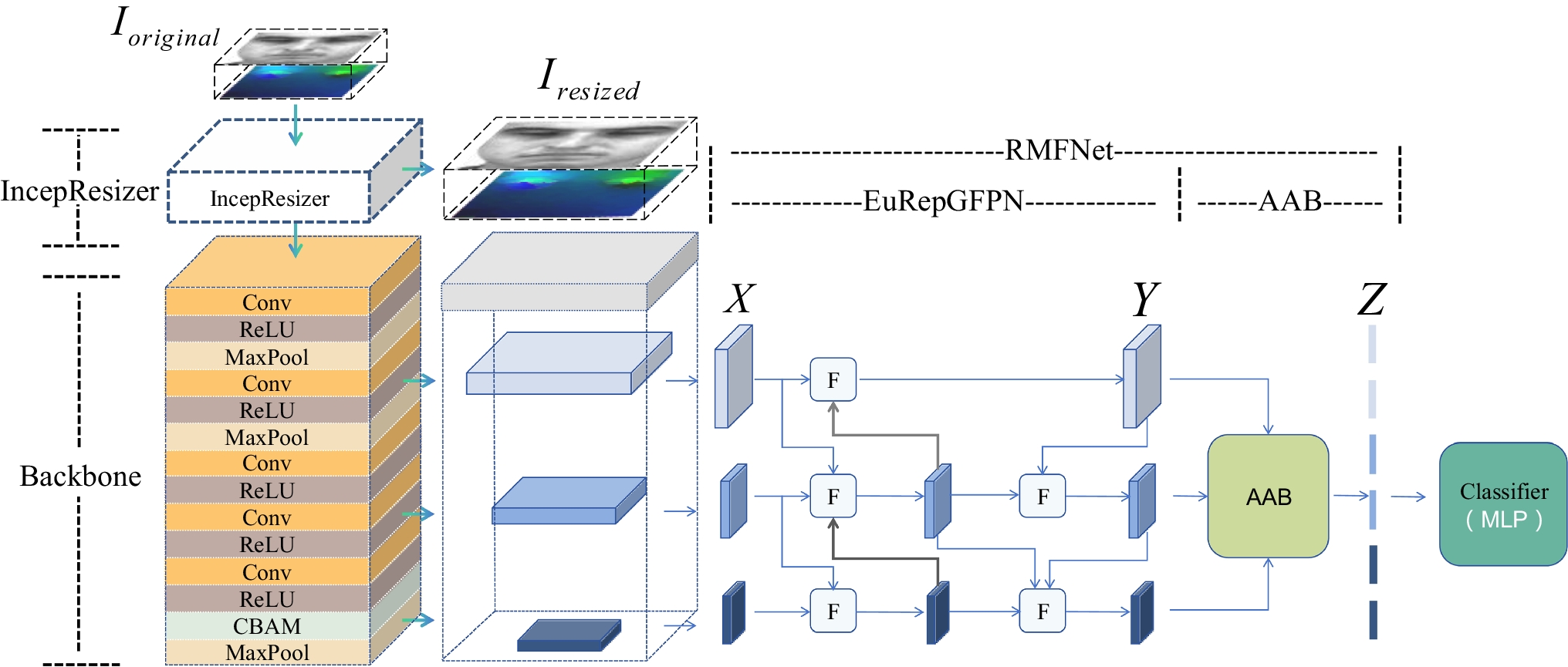

This section presents an overview of our proposed model (Fig. 2) for speech utterance-based emotion recognition. To efficiently train the SWT transformer model with feature vectors that ultimately result in speech emotion recognition, we highlighted the key details from the auditory speech database, pre-processing, feature extraction (Mel Spectrogram), and feeding of the model. Ultimately, the proposed transformer model was implemented with the aid of the Keras and Tensorflow libraries, making simulations easier to run. Two bilingual datasets were used for evaluation, where accuracy and robustness were the main criteria.
Speech Feature ExtractionThe quality of the feature extraction used significantly influences the performance of a model in a recognition task. Inadequate features may also lead to unsatisfactory recognition results. In the context of Deep Learning (DL), feature extraction is an essential phase in deep learning [55], since the diversity of the features the SER model employs significant impact on the model’s success or failure. Recognition will be accurate if there is a substantial correlation between the derived features and the emotional classes; otherwise, it will be complicated and lead to misclassification. The overall quality of the feature set has a big impact on how well the SER model performs. This study utilized a popular feature extraction approach that captures essential features for our transformer model to efficiently recognize emotion from speech signals.
The Mel spectrogram feature, which shows the frequency content of an audio signal as a function of time, was extracted from the speech signal. It is based on the conventional spectrogram, but the frequency scale has been modified to better correspond with human hearing. Auditory spectrograms are often used to examine different sounds and phonetically identify spoken words. It provides the time-frequency information of the utterance. However, it is more challenging to identify higher frequency differences than lower frequency variations because human perception of frequency does not follow a linear scale. Even if the distance between the two pairs is the same, we can precisely distinguish between 500 and 1000Hz, but we struggle to differentiate between 10, 000 and 10, 500Hz.
The main processes in the Mel spectrogram feature extraction technique are pre-emphasis, windowing (frame segmentation), Fast Fourier transform (FFT), Mel-filtering, and determining the magnitude’s log scale. (1) and (2) are used to mathematically obtain the feature extraction process.
$$\begin w(n)= 0.54 - 0.46\cos \Bigl \\Bigr \} 0 \le n \le N-1 \end$$
(1)
$$\begin Y(n) = X(n).W(n) \end$$
(2)
where N = number of samples in each frame Y(n) = Output signal X(n) = Input signal W(n) = Hamming window
The Hamming window function splits the audio signal into short frames to maintain continuity and prevent overlapping. Secondly, each frame is subjected to FFT to convert the signal from the time domain to the frequency domain and reveal the frequency components contained in that frame. Following this, each frame’s FFT magnitude spectrum is filtered using a set of triangular filters arranged under the Mel-scale to extract energy within distinct Mel-frequency bands. The speech signal’s dynamic range is finally compressed by computing and standardizing the log magnitude of the filtered outputs. A 2D representation (fit for model) is created by stacking the resulting Mel spectrogram frames, with the y-axis denoting frequency bins and the x-axis representing time. The structured, relevant, and informative representation of speech signals provided by Mel spectrograms as features for emotion recognition enables models to efficiently capture and distinguish emotional cues included in the speech utterance.
Swin Transformer (SWT) BlockOriginally, machine-level translation was intended to be accomplished with the transformer model. Nevertheless, due to its effective performance, it substitutes RNN in NLP and gains prominence [56, 57]. To eliminate the recurrent nature of any kind of processing, the transformer model uses an alternative internal attention mechanism called the self-attention mechanism. The original Swin Transformer framework is illustrated in Fig. 3 and computed mathematically using ().
$$\begin & \widehat}^l= W-MSA(LN(Z^))+ Z^ \nonumber \\ & \widehat}^l= MLP(LN(\widehat^l))+\widehat^l\\ & \widehat}^= SW - MSA(LN(^l))+^l\nonumber \\ & \widehat}^= MLP(LN(\widehat^))+\widehat^\nonumber \end$$
(3)
where MLP is the multi-layer perceptron, LN is the Layer Normalization, \(Z^\) denotes \( L-1\) SWT block, and \(^l\) is obtained from Lth SWT block.
Fig. 3
Structural view of Swin Transformer. W-MSA and SW-MSA represent window-based and shift-window self-attention, respectively
The proposed SWT model generates relevant features using a linear transformation for a given speech utterance. The transformer model consists mainly of self-attention (SA), LN, multi-head self-attention(MSA), and MLP. The goal of the self-attention (SA) layer is to aggregate global information from the complete input sequence to capture the internal correlation of the input sequence, which is a challenging task for traditional recurrent models.
The input feature \(X ( X \in \mathbb ^)\) comprising of N entities withD dimension each, is usually transformed into a query, key and value (Q, K, V) through a matrix of learnable weight respectively, which can be obtained mathematically from \(\mathbb ^ Q, \mathbb ^ K, \mathbb ^ V \), where W denotes the weights.
Contrarily, Multiple Self-Attention (MSA) blocks comprise Multi-Head Self-Attention (MHSA), as opposed to a single attention computation that exists in a single-layer attention network. To make it possible to simulate dependencies between various components in the input sequence, these SA blocks are collectively concatenated channel-wise. For each head in (MHSA), a matrix of learnable weight expressed by \( \bigl \^Qm,\mathbb ^Km, \mathbb ^Vm \bigr \}\). Where m=0...(n-1) and n represent the total count of MHSA heads, and \(\mathbb ^ O \in \mathbb ^ \times N} \) represents the linear transformation of the head.
In the Swin Transformer model, while other layers remain unchanged, a Transformer block’s normal multi-head self-attention (MHSA) module is swapped out with one based on shifted windows. A shifted window-based MHSA module and a 2-layer MLP with GELU (Gaussian Error Linear Unit) non-linearity in between makes up an SWT block, as shown in Fig. 2. Before every MHSA module, MLP, residual connection, and Layer Normalization (LN) layer are applied, the input Mel spectrogram feature, which was obtained during the architecture’s feature extraction phase, is first divided into non-overlapping patches using a patch-splitting module in the SWT model for SER. Every patch is considered a “token,” with its feature consisting of a concatenation of the raw features from the Mel spectrogram for each patch. As our architecture depicts, the input size is of \(H \times W \times C\) dimension, where C represents the channel and \(H \times W\) denotes the input size. The window size for each patch is set to C/2, since a \(2 \times 2\) patch size is employed in our experiment, and each patch’s feature dimension is expressed as \(2 \times 2 \times 3 = 12\). A uniform division of the window to standardize the dimension (C/2, C/2) is applied. Thereafter, a linear embedding layer (64 size) is utilized to project the output for appropriate transformation. Patch merging and feature transformation are then utilized to downsize the number of tokens as the network size deepens. At the topmost level of the model, an activation function with one dense layer is used for the final classification of seven emotions. The summary of our proposed model structure with the corresponding parameter size is shown in Table 1.
Table 1 Model structure summaryEvaluation MetricsAn evaluation technique that is suitable for a multiclass problem like SER is utilized in this study. This is necessary to ensure that all the seven classes of emotions from the three datasets are captured. We adopted standard evaluation metrics of Accuracy, Precision, Recall, and F1-score, respectively, in our experiment to establish the performance of our proposed model. A confusion matrix displays our model’s performance actual and predicted emotions across seven human emotions extracted from the datasets. The accuracy metric estimates the percentage of emotional utterances correctly predicted by the proposed SWTSER model from the whole speech sample. Given a number speech sample denoted by N, accuracy is computed mathematically from (4).
$$\begin Accuracy = \frac\sum ^_\frac^i}^i} \end$$
(4)
$$\begin Recall = \frac\sum ^_\frac^i}^i} \end$$
(5)
$$\begin Presicision = \frac\sum ^_\frac^i}^i} \end$$
(6)
While recall estimates the number of correct positive predictions made against the model’s wrong prediction, precision estimates the actual positive prediction only, as indicated in (5) and (6).
ExperimentDatasetsAt the preliminary stage of this study, two public datasets were utilized to verify the performance of our model and establish its generalizability. The two datasets (TESS and EMOVO) are in different languages (bilingual)-English and Italian. It is common in the literature to see many SER implementations using a single language; however, we chose a bilingual approach because the language has a role in human speech utterance. Moreover, our proposed model is exposed to two different language speech datasets to establish its robustness in capturing emotional cues from speech signals.
TESS DatasetMany SER initiatives have used the Toronto English Speech Set, or TESS for short, one of the biggest publicly available datasets. In 2010, TESS speech samples were recorded by Northwestern University’s Audio Laboratory [58]. A few of the 200 words were to be pronounced by the two actors during the unscheduled occurrence. A thorough collection of 2800 verbal utterances was obtained by recording their voices. In the scenario, seven distinct emotions were observed: pleased, shocked, terrified, furious, glad, sad, and neutral. Figure 4 shows the TESS description based on each emotion’s total speech dataset contribution.
Fig. 4
TESS Emotional speech percentage distribution
EMOVO DatasetThere are seven different emotional states in the EMOVO dataset: disgust, fear, angry, joy, surprise, sadness, and neutral. Italian language utterances are included in the first dataset, called EMOVO [59]. This dataset captures six actors on tape uttering the words in fourteen sentences. There are 24 annotators per group for each of the 588 utterances in this dataset, which has been further annotated. All voice recordings were made at the laboratory of the Fondazione Ugo Bordoni. The percentage distribution of each emotion is illustrated in Fig. 5.
Fig. 5
EMOVO emotional speech percentage distribution
Table 2 Hyperparameters utilized for the implementationFig. 6
Validation accuracy and loss plot on TESS
This study implemented the suggested model on GPU-T4, 10900K@3.70Ghz, 64GB RAM, and Google Colab platform. The model implementation parameters were carefully chosen to achieve an enhanced result in SER while minimizing emotion misclassification, as indicated in Table 2. The two datasets described in the preceding section were used in the experiments to evaluate the proposed transformer model. We utilized a split ratio mechanism to split the datasets into training and test sets. To split the dataset into training and test, we utilized a “RandomSplitter” approach (80:20), an emerging and special function in Python that splits the dataset into training and test set. This dataset-splitting technique is a standardized approach that can help achieve improved performance in SER models and prevent overlapping emotion recognition results. The SWT transformer model’s performance when applied to the datasets and trained with 128 feature sets is shown in Figs. 6, 7, and 8.
Comments (0)