
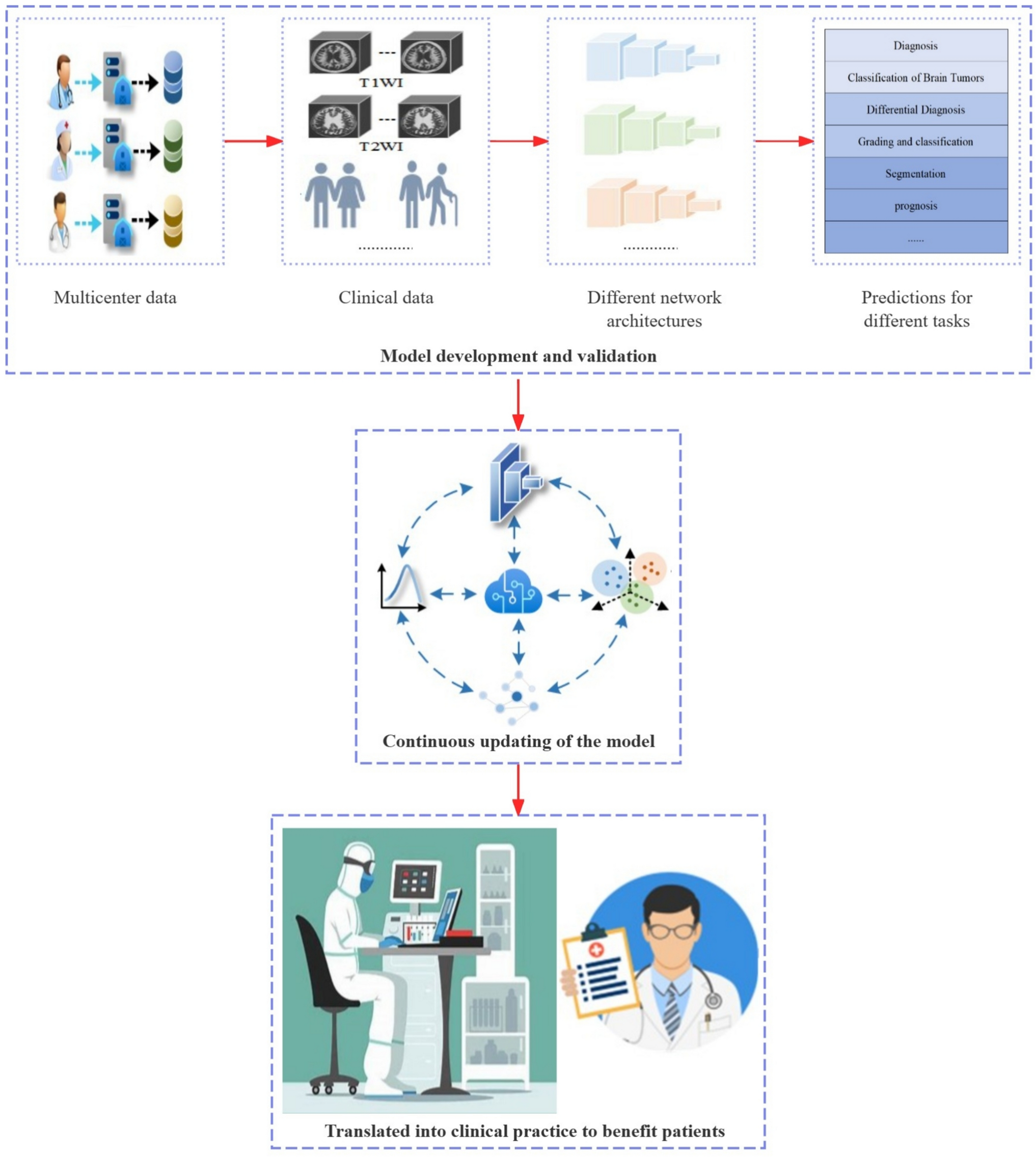
Remember me

ZS-NAC first involves adding additional noise to an already acquired, noisy image. Then, a convolutional network is trained to denoise by using the noisier image as input and the originally acquired noisy image as output (i.e., reference). Once trained, the originally acquired noisy image is fed to the trained network as input to be denoised.
In the MR context, let \(}=}+}\) be the noisy acquired complex MR image, where \(}\) is the noise-free image and \(}\) is the random Gaussian noise with zero mean and \(}}_}}^\) variance in the real and imaginary parts of the complex data. The variance \(}}_}}^\) is estimated by computing the noise standard deviation of the real and imaginary parts over the entire background of the MR complex image, from a computed binary mask excluding the imaged object (cf. Methods Experiment 1). Then, multiple noisier MR images \(}=}+}\) are created by adding noise \(}\) drawn from a noise distribution with zero mean and \(}}_}}^\) variance with \(}}_}}=\boldsymbol}}_}}\), where \(\alpha\) is a scalar number (set to 1 in ZS-NAC). Subsequently, a deep learning network \(}\) is trained to predict \(}\) given \(}\) as an input. Once trained, the estimated clean image \(}\boldsymbol}\) is predicted using \(}}^}}=}(})\).
Another popular method, noisier2noise [16], employs a similar strategy with a difference occurring in the inference phase. However, in a zero-shot context, we found that the ZS-NAC method led to better stability and image sharpness, particularly at low SNR levels (see supplementary materials A). Therefore, we proceeded with the ZS-NAC method.
Training detailsThe absence of training set is balanced by the generation of multiple pairs (\(}}_}}\), \(}\)) where \(}}_}}\) is a noisier image simulated out of the noisy image \(}\) at each epoch \(}\). Subsequently, a convolutional neural network is trained to denoise the inputs \(}}_}}\). Once trained, the network is used to denoise the input \(}\) (Fig. 1a).
Fig. 1
a Schematic explaining the ZS-NAC approach used here. The first step consists of training the convolutional network to predict y given zi. The second step, or inference step, consists of using the trained network to denoise y. b Network structure: The two input/output channels correspond to the real and imaginary parts of the image. The network consists of a single downsampling/upsampling step. The downsampling step consists of two convolution operations with 32 features (size: 3 × 3, stride: 1) followed by a Maxpooling operation (size: 2 × 2, stride: 2). Then, two convolution operations with 64 features are executed followed by an upsampling operation. This last step is achieved by a transpose convolution followed by two additional convolutional operations. All convolution operations are followed by a rectified unit (ReLU) and Batch normalization operation
In the proposed work, ZS-NAC was modified to achieve a fast-denoising process. The choice of the network architecture is crucial for achieving both fast and accurate denoising. A fast training requires a simple network architecture, so a modified light version of residual U-Net network was adopted with a total of 101 k trainable parameters (Fig. 1b). The network consists of a single downsampling/upsampling step. The downsampling step consists of two convolution operations with 32 features (size: 3 × 3, stride: 1) followed by a Maxpooling operation (size: 2 × 2, stride: 2). Then, two convolution operations with 64 features are executed followed by an upsampling operation. This last step is achieved by a transpose convolution followed by two additional convolutional operations. All convolution operations are followed by a rectified unit (ReLU) and Batch normalization operations.
One challenge of zero-shot learning is the absence of validation set, which not only ensures an unbiased evaluation of the model but also helps drastically reducing the training time by stopping it once convergence is achieved. In reference [25], training was stopped after an arbitrary number of epochs. In this work, a validation pair was generated by downsampling the noisy image using the kernel = \(\left[\begin0& 1\\ 0& 0\end\right]\), and creating a noisier version of this small image by adding noise drawn from a noise distribution with zero mean and \(}}_}}^\) variance. This allowed to adopt an early stopping criterion essential to speed the overall process. One might assume that a simple noisier image could serve as a validation set. However, this would result in a loss equivalent to the training loss.
The complex nature of MR images was preserved by splitting real and imaginary data into 2 channels. Additionally, an ablation study of the effect of loss function used during the training was done (see supplementary material C). As a result, Mean Squared Error (MSE) was used as a loss function to train the network. Adam optimizer with an initial learning rate value of 0.01 was adopted. The learning rate gradually decreased by a factor of 0.9 when the training loss did not improve. A batch number equal to the number of slices in a 3D acquisition was adopted for training. A software package was developed for installation using PyPI, ensuring easy deployment. The code and installing instructions are available at https://github.com/reinaayde7/zs-nac.git.
BM4D in MRIThe ZS-NAC method was compared to BM4D. BM4D is an extension of BM3D for volumetric data. It operates by grouping similar patterns/patches present in the image into a 3D array and then filtering the latter using sparse representations in the transform domain [4, 27]. As BMxD is an analytical method, it does not require a database.
For pure Gaussian noise, BMxD is considered as one of the gold-standard methods [3, 24]. It is however important to avoid applying conventional BMxd to magnitude MR images, especially for low-field data, where noise distribution is more likely to follow a Rician distribution. BMxD can also handle Rician distributions using a variance-stabilizing transformation as previously communicated [4, 28]. In this work, we used the conventional BM4D python package for volumetric, multichannel data applied to our complex MR data.
The standard deviation of the underlying noise in the real and imaginary channels was estimated per data sample and used as an input parameter for BM4D. This standard deviation determines the threshold value when filtering coefficients in the transform domain. In practice, using the standard deviation led to non-optimal smoothed images. Therefore, we added a factor \(\theta\)<1, that multiplies the input standard deviation for optimal performance. To identify the \(\theta\) leading to the best denoising performance, we compared quantitatively the performance for different SNR levels and identified the best \(\theta\) value (see supplementary materials B). Accordingly, \(\theta\) = 0.9 was adopted in all experiments.
Zero-shot noise2noiseWe further compared our method to the latest, zero-shot denoising technique, known as zero-shot noise2noise (ZS-N2N), which offers relatively fast denoising times [26]. According to the authors, denoising a 256 × 256 image took 20 s on a GPU Quadro RTX 6000. Two downsampled images are generated from the acquired noisy image using two fixed filters. A small convolutional network (21 k parameters) is then trained to map one downsampled image to the other. This method builds upon noise2noise [15] and neighbor2neighbor [14] approaches, minimizing computational resources while preserving image quality. We adapted this network to handle two input channels (real and imaginary). Mansour et al. argue that there is no need for an early stopping criterion because a consistency loss was used which prevents overfitting. The hyperparameters used in their shared notebook was used for training. The maximum number of epochs was set to 2000 as the convergence is reached between 1000 and 2000 epochs.
Comments (0)