
Remember me
Formally, our aim is to define a framework with the following property:
$$\begin : \mathcal \rightarrow \mathcal \end$$
(A1)
Where:
E is the execution of a model m.
\(\mathcal \) is the set of all existing models.
\(\mathcal \) is the space of all possible results of \(\mathcal \).
Then for a specific model \(m \in \mathcal \)
where \(r \in \mathcal _m \subseteq \mathcal \).
Then we define \(f \in \mathcal \) where \(\mathcal \) represents all result processing tools, and we define a processing function:
$$\begin f: \mathcal \rightarrow \mathcal \end$$
where \(\mathcal \) is the output space of the tool; and with this we define the universal property
$$\begin \forall r \in \mathcal , \exists y \in \mathcal : y = f(r), \forall f \in \mathcal \end$$
(A2)
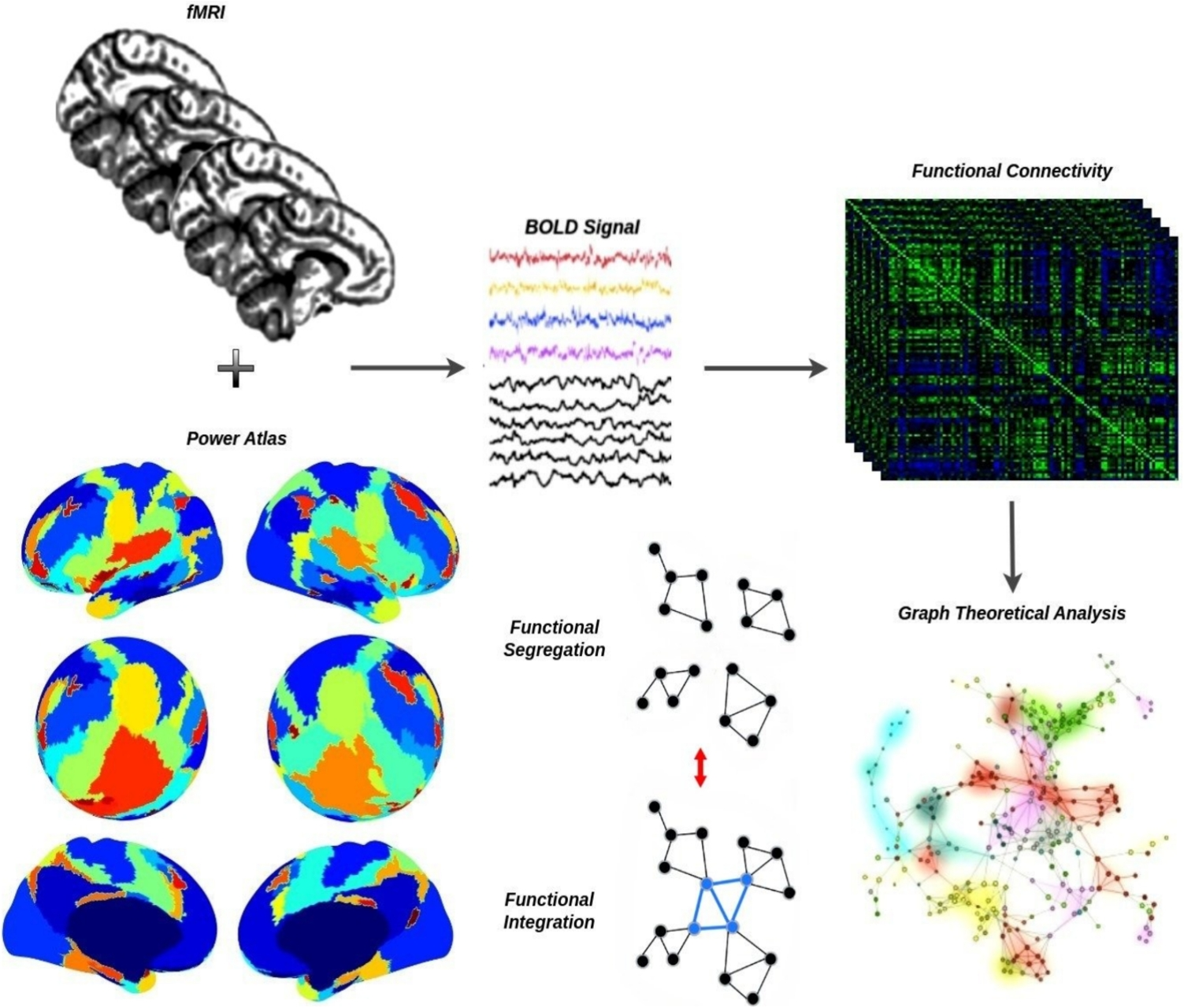
Appendix B Classes and ObjectsThe abstract class ModelABC defines the functionalities responsible for configuring mode names and establishing a common protocol for all models defined in the package. In terms defined in the previous equations, any model that inherits from ModelABC belongs to the set M of the Eq. A1.
The class NDResult is the implementation of any result from models inherited from ModelABC and from a mathematical point of view, they are the code realization of the set R from Eq. A1. As a data structure, NDResult (N-Dimensional Result) is a thin layer that adds multisensory integration analysis capabilities on top of the DataArray structure from the XArray library (Hoyer and Hamman, 2017). XArray was originally designed to work with high-dimensional data from NetCDF format (Rew and Davis, 1990), commonly used in satellite data processing. Additionally, since XArray provides persistence facilities, a .ndr persistence format was defined, which compresses a NetCDF file along with its metadata in a ZIP container (PKWARE Inc., 2022). Furthermore, NDResult also supports compression, as model results typically consume significant memory resources.
The ParameterSweep class is the primary tool designed to perform parameter sweeps over a model, automatically executing model multiple times while systematically varying the value of a target parameter within a specified range. The class allows configuration of the number of repetitions for each parameter value, supports parallel execution using multicore architectures, and implements memory management to prevent overflow conditions. Notably, ParameterSweep is model-agnostic and can work with any model that inherits from ModelABC, making it highly flexible and reusable. This is the first use of DIP.
The second use case implements the Strategy Pattern (Gamma et al., 1995), allowing interchangeable algorithms to process the results of each model execution. By default, ParameterSweep() employs a strategy called NDCollectionProcessingStrategy, which acts as a processing pipeline that first compresses each individual result and then aggregates them into a coherent data structure called NDResultCollection, facilitating subsequent analysis. This architectural decision was driven by the memory footprint of the results, which typically occupy hundreds of megabytes, making concurrent storage of multiple results computationally expensive. The design allows for the implementation of custom strategies that can selectively store specific data points from each result, thus optimising memory utilisation.
ParameterSweep supports any model that instantiates from a class inheriting from ModelABC, and knows how to process the NDResult objects it generates by delegating them to the chosen strategy. In other words, it is the code implementation of the property defined in Eq. A2.
NDResultCollection is the final piece of the puzzle that makes up Scikit-NeuroMSI. It is an auxiliary class that allows grouping many compressed results from the same model into a single collection and extends them with classic area functionalities such as cross-modal bias and causal analysis (Körding et al., 2007). Additionally, it is the default data type returned by the ParameterSweep() tool when used with the default strategy. Similar to NDResult, it offers the capability to export each data point to NetCDF format in a ZIP compressed file with its metadata in a format we call *.ndc.
Appendix C Implemented ModelsC.1 Near-Optimal Bimodal IntegratorThe Near-optimal Bimodal Integrator (Alais and Burr, 2004) for auditory (A) and visual (V) signals in the context of an auditory spatial localization task can be computed as:
$$\begin \hat_ = w_\hat_ + w_\hat_ \end$$
(C3)
where \(\hat_\) and \(\hat_\) are unimodal auditory and visual estimates, respectively, and \(\hat_\) is the multimodal estimate.
In addition, \(w_\) and \(w_\) are the relative weights for each modality, defined as:
$$\begin w_ = \frac^}^ + \sigma _^} \end$$
(C4)
$$\begin w_ = \frac^}^ + \sigma _^} \end$$
(C5)
where \(\sigma _\) and \(\sigma _\) are the variances of each unimodal stimuli, respectively.
These equations show that the optimal multisensory estimate adds the unisensory estimates weighted by their normalized reciprocal variances.
The Near-optimal Bimodal Integrator model can be called using Code 7.
 C.2 Bayesian Causal Inference
C.2 Bayesian Causal InferenceThe Bayesian Causal Inference model (Körding et al., 2007) uses the following formulation:
$$\begin p\left( C \mid x_, x_ \right) = \frac, x_ \mid C \right) p\left( C \right) }, x_ \right) } \end$$
(C6)
where \(x_\) and \(x_\) are two unimodal signals and C is a binary variable that represents the number of causes in the environment.
The posterior probability of the signals having a single cause in the environment is defined as follows:
$$\begin & p\left( C = 1 \mid x_, x_ \right) \nonumber \\ & = \frac, x_ \mid C=1 \right) p\left( C=1 \right) }, x_ \mid C=1 \right) p\left( C=1 \right) + p \left( x_, x_ \mid C=2 \right) \left( 1 - p\left( C=1 \right) \right) } \end$$
(C7)
and the likelihood is computed as:
$$\begin p\left( x_, x_ \mid C = 1 \right) = \int \hspace\int p\left( x_, x_\mid X \right) p\left( X \right) dX \end$$
(C8)
Here \( p\left( C = 1 \right) \) is the prior probability of a common cause (by default 0.5). X denotes the attributes of the stimuli (e.g. distance), which are then represented in the nervous system as \(x_\) and \(x_\).
These equations show that the inference of a common cause of two unisensory signals is computed by combining the likelihood and prior of signals having a common cause. A higher likelihood occurs if the two unisensory signals are similar, which in turn increases the probability of inferring that the signals have a common cause.
The Bayesian Causal Inference model can be called using Code 8.
 C.3 Audio-Visual Integration and Causal Inference Network
C.3 Audio-Visual Integration and Causal Inference NetworkThe audio-visual integration and causal inference network (Cuppini et al., 2017) consists of three layers: two encode auditory and visual stimuli, separately, and connect to a multisensory layer where causal inference is computed. Each of these layers consists of 180 neurons arranged topologically to encode a 180°space. In this way, each neuron encodes 1°of space and neurons close to each other encode close spatial positions.
Each neuron will be indicated with a superscript c indicating a specific cortical area (a, v or m for the auditory, visual or multisensory area, respectively). Similarly, each neuron will have a subscript j referring to its spatial position within a given area. Neurons in each layer have a sigmoid activation function and first-order dynamics:
$$\begin \tau ^ \frac_\left( t \right) } = - y^_\left( t \right) + F \left( u^_\left( t \right) \right) , & c = a, v, m \end$$
(C9)
Here, u(t) and y(t) are used to represent the net input and output of a given neuron at time t. \(\tau ^\) denotes the time constant of neurons belonging to a given area c. F(u) represents the sigmoidal relationship:
$$\begin F\left( u_^\right) = \frac^ - \theta \right) } } \end$$
(C10)
Here, s and \(\theta \) denote the slope and the central position of the sigmoidal relationship, respectively. Neurons in all regions differ only in their time constants, chosen to mimic faster sensory processing for stimuli in the auditory region compared to visual stimuli.
These neurons are recurrently connected in a “Mexican hat” pattern within each layer. Such connectivity pattern consists of defining a central excitatory area surrounded by an inhibitory ring for each neuron, so that the entire layer generates excitation for spatially close stimuli and inhibition for distant stimuli:
$$\begin L_^ = \left\ L_^ \cdot exp\left( - \frac \right) ^}^ \right) ^} \right) - L_^ \cdot exp\left( - \frac \right) ^}^ \right) ^} \right) , & D_ \ne 0 \\ 0, & D_ = 0 \end\right. \end$$
(C11)
Here, \(L_^\) denotes the weight of the synapse from the pre-synaptic neuron at position k to post-synaptic neuron at position j. \(D_\) indicate the distance between the pre-synaptic neuron and the post-synaptic neurons within a given area:
$$\begin D_ = \left\ \left| j-k\right| , & \left| j-k\right| \leqslant N/2 \\ N - \left| j-k\right| , & \left| j-k\right| > N/2\end\right. \end$$
(C12)
This defines a circular structure where each neuron receives the same number of lateral connections.
On the other hand, neurons in each unisensory layer (e.g. auditory) are reciprocally connected with neurons in the opposite layer (e.g. visual). These connections are excitatory and modify the spatial perception of unisensory stimuli. These synaptic weights are symmetrically defined (\(W_^ = W_^\) and \(\sigma ^=\sigma ^\)) by the Gaussian function:
$$\begin W^_ = W^_ \cdot exp\left( - \frac\right) ^}\right) ^}\right) , cd = av\ or\ va \end$$
(C13)
\(W_\) denotes the highest level of synaptic efficacy and \(D_\) is the distance between neuron at position j in the post-synaptic unisensory region and the neuron at position k in the pre-synaptic unisensory region. \(\sigma ^\) defines the width of the cross-modal synapses.
In addition, neurons in the unisensory layers have excitatory connections to the multisensory layer. These synapses are used to encode information about the mutual spatial coincidence of cross-modal stimuli and the probability that two stimuli were generated by a common source (i.e. they solve the problem of causal inference). The weights of these feedforward synapses are symmetrically defined as:
$$\begin W^_ = W^_ \cdot exp\left( - \frac\right) ^}\right) ^}\right) , c = a,v \end$$
(C14)
Here \(W^_\) denotes the highest value of synaptic efficacy, \(D_\) the distance between the multisensory neuron at position j and the unisensory neuron at position k, and \(\sigma ^\) the width of the feedforward synapses. The distance is defined as:
$$\begin i^_\left( t\right) = \sum ^_ W^_ \cdot y^_\left( t - \Delta t_\right) + W^_ \cdot y^_\left( t - \Delta t_\right) \end$$
(C15)
Here, \(\Delta t_\) represents the latency of feedforward inputs between the unisensory and multisensory regions. \(W^_\) and \(W^_\) are the synapses connecting the pre-synaptic neuron at position k in a given unisensory area and the post-synaptic neuron at position j in the multisensory area.
Finally, the visual and auditory stimuli used as input to the network are defined with a Gaussian function to mimic the spatially localized external stimuli filtered by the receptive fields of the neurons. The stimulus from the external world is simulated as a 1-D Gaussian function to represent the uncertainty in the detection of external stimuli:
$$\begin e^_\left( t\right) = E^_ \cdot exp\left( - \frac_\right) ^}\right) ^}\right) \end$$
(C16)
Here, \(E^_\) denotes the strength of the stimulus, \(d^_\) the distance between the neuron at position j and the stimulus at position \(p^\), and \(\sigma ^\) the degree of uncertainty in sensory detection. The distance \(d^_\) is defined as:
$$\begin d_^ = \left\ \left| j-p^\right| , & \left| j-p^\right| \leqslant N/2 \\ N - \left| j-p^\right| , & \left| j-p^\right| > N/2\end\right. \end$$
(C17)
The central point of the Gaussian function corresponds to the point of application of the stimulus in the external world, while the standard deviation of the Gaussian function reflects the width of the receptive fields of the neurons and the reliability of the external input. This parameter is used to represent the different spatial acuities of the auditory and visual sensory modalities.
The net input of a neuron is the sum of an inside (i.e. within region) component (\(l_^\)) and an outside (i.e. extra-area) component (\(o_^(t)\)):
$$\begin u^_\left( t\right) = l^_\left( t\right) + o^_\left( t\right) \end$$
(C18)
The within region component \(l_^\) is defined as:
$$\begin l^_\left( t\right) = \sum _L^_ \cdot y^_\left( t\right) \end$$
(C19)
Here \(L^_\) represents the strength of the lateral synapse from a presynaptic neuron at position k to a postsynaptic neuron at position j in the region c. \(y^_\) is the activity of the presynaptic neuron at position k.
Importantly, the extra-area input is defined differently for unisensory and multisensory areas. The extra-area input for the unisensory areas includes a stimulus from the external world (\(e^_(t)\)), a cross-modal component coming from the other unisensory area (\(c^_(t)\)) and a noise component (\(n^_\)). Furthermore, the cross-modal input is defined as:
$$\begin \begin c^_\left( t\right) = \sum ^_ W^_ \cdot y^_ \\ c^_\left( t\right) = \sum ^_ W^_ \cdot y^_ \end \end$$
(C20)
The noise component \(n^_\) is extracted from a standard uniform distribution in the interval \(\left[ n_ +n_\right] \). Here, \(n_\) is defined as the 40% of the strength of the external stimulus for each modality.
The Audio-visual Integration Network model can be called using Code 9:
 C.4 Multisensory Spatiotemporal Causal Inference Network
C.4 Multisensory Spatiotemporal Causal Inference NetworkThe model consists of three layers: two encode auditory and visual stimuli separately and connect to a multisensory layer via feedforward and feedback synapses. At the unisensory areas, the model computes the spatiotemporal position of the external stimuli. In addition, at the multisensory area the model computes causal inference.
This model maintains the neural connectivity (lateral, crossmodal, feedforward) and inputs described in the network presented in the previous section (Cuppini et al., 2017). Our model now includes feedback connectivity (\(B_^ = B_^\) and \(\sigma ^=\sigma ^\)), defined by the following equation:
$$\begin B^_ = B^_ \cdot exp\left( - \frac\right) ^}\right) ^}\right) , cm = am\ or\ vm \end$$
(C21)
\(B^_\) denotes the highest level of synaptic efficacy and \(D_\) is the distance between neuron at position j in the post-synaptic unisensory region and the neuron at position k in the pre-synaptic multisensory region. \(\sigma ^\) defines the width of the feedback synapses.
Overall, the feedback input is defined as:
$$\begin b^_\left( t\right) = \sum ^_ B^_ \cdot y^_\left( t - \Delta t_\right) \end$$
(C22)
Here \(\Delta t_\) represents the latency of feedback inputs between the multisensory and unisensory regions. The feedback synaptic weights are also symmetrically (\(B_^ = B_^\) and \(\sigma ^=\sigma ^\)) defined:
All these external sources are filtered by a second order differential equation to mimic the temporal dynamics of the stimuli in a cortex:
$$\begin \left\ \qquad \qquad \qquad \qquad \quad \frac o^_\left( t\right) = \delta ^_ \left( t\right) \\ \frac \delta ^_ \left( t\right) = \frac}} \cdot \left[ e^_\left( t\right) + c^_\left( t\right) + b^_\left( t\right) + n^_ \right] - \frac_ \left( t\right) }} - \frac_\left( t\right) } \right) ^}\end\right. , c= a,v \end$$
(C23)
Here, \(G^\) represents gain and \(\tau ^\) the time constants of the dynamics.
These external sources are also filtered by a second order differential equation:
$$\begin \left\ \qquad \qquad \qquad \quad \quad \frac o^_\left( t\right) = \delta ^_ \left( t\right) \\ \frac \delta ^_ \left( t\right) = \frac}} \cdot \left[ i^_\left( t\right) \right] - \frac_ \left( t\right) }} - \frac_\left( t\right) } \right) ^} \end\right. \end$$
(C24)
Here, \(G^\) represents gain and \(\tau ^\) the time constants of the dynamics in the multisensory neurons.
Furthermore, the cross-modal input is defined as:
$$\begin \begin c^_\left( t\right) = \sum ^_ W^_ \cdot y^_ \left( t - \Delta t_ \right) \\ c^_\left( t\right) = \sum ^_ W^_ \cdot y^_ \left( t - \Delta t_\right) \end \end$$
(C25)
Here, \(\Delta t_\) represents the latency of cross-modal inputs between two unisensory regions.
The Multisensory Spatiotemporal Causal Inference Network model can be called using Code 10.
 Appendix D Model FittingD.1 Model ReadoutsD.1.1 Implicit Causal Inference Task
Appendix D Model FittingD.1 Model ReadoutsD.1.1 Implicit Causal Inference TaskThe audio-visual spatial localization task (Noel et al., 2022b) involves participants determining whether an auditory stimulus is perceived to the right or left of a central position, indicated by a button press. Subsequently, psychometric functions are constructed by plotting the proportion of responses directed to the right as a function of the stimulus position. These data are modeled using a cumulative Gaussian function. The psychometric function provides two parameters that delineate the localization performance of the participants: bias and threshold. Bias is defined as the stimulus value at which responses are equally divided between rightward and leftward. A bias approximating 0°denotes highly accurate localization. The threshold is represented by the standard deviation of the fitted cumulative Gaussian function. A lower threshold indicates a higher precision in spatial localization.
In order to streamline the process and acknowledging the absence of noise in our simulations, we chose not to directly simulate the participants’ left-right responses. Instead, we concentrated on modeling the auditory position estimate for each model. The auditory position estimate for the network model was ascertained by pinpointing the neuron displaying the highest activity level during the simulation, with each neuron corresponding to a discrete spatial segment.
D.1.2 Explicit Causal Inference TasksThe explicit causal inference tasks require participants to ascertain whether auditory and visual stimuli originate from the same source. In the context of neural network models, this proportion is derived based on the maximal neural activation manifested within the multisensory neurons, contingent upon the condition that such activation exceeds the threshold of 0.15. In the spatial task, the evaluation of multisensory activity is conducted within the spatial domain at the concluding time point, while in the temporal task, the assessment occurs within the temporal domain at the locus of maximal activity. In cases where multiple peak values are identified, the average product of all potential combinations of these peak values is calculated to estimate the proportion attributable to the presence of multiple sources. Subsequently, the complementary proportion, representing the perception of multiple stimuli, is calculated to ascertain the proportion attributable to common source reports.
D.2 Fitting ProcedureThe proportion of auditory bias or common cause reports reported by each model was fitted to the experimental data (Noel et al., 2022b) with the cost function defined by Eq. D26.
$$\begin Cost = \sum _^ \left( \frac^-P_^}^} \right) ^ \end$$
(D26)
Here, \(P_^\) and \(P_^\) denote the proportion measured in the ith audio-visual stimuli disparity. N represents the number of disparities measured (i.e. 8 in the empirical study for the spatial tasks). This cost function was minimised by the implementation of the differential evolution algorithm (Storn and Price, 1997) available in the SciPy library for the Python programming language (Virtanen et al., 2020).
For the near-optimal bimodal integrator (Alais and Burr, 2004), parameters \(\sigma _\) and \(\sigma _\) were fitted under the constraint that parameter \(\sigma _\) exceeds parameter \(\sigma _\), thereby enhancing precision within the visual modality. The algorithm was provided with boundaries set at (0.1, 48) for both parameters.
For the Bayesian causal inference model (Körding et al., 2007), parameters \(\sigma _\), \(\sigma _\), \(p_\) and \(p_\) were also fitted under the constraint that parameter \(\sigma _\) exceeds parameter \(\sigma _\). For spatial tasks, the algorithm was provided with boundaries set at (0.1, 48) for all parameters, except \(p_\) which was set at (21, 69). For the temporal task, the algorithm was provided with boundaries set at (1, 500) for all parameters.
For spatial tasks, the audio-visual integrator and causal inference network (Cuppini et al., 2017), parameters \(\sigma ^\), \(\sigma ^\), \(E^\) and \(E^\), representing stimulus uncertainty and intensity, respectively, were fitted under the constraint that auditory uncertainty is larger than visual. The algorithm was provided with boundaries set at (0.1, 48) for uncertainties and (0.1, 30) for intensities. For the temporal task, the parameters \(\tau ^\), \(\tau ^\), \(\tau ^\), \(W_^\), and \(W_^\) were fitted with boundaries set at (0.1, 55), (0.1, 55), (0.1, 75), (0.01, 150), and (0.01, 24), respectively. In the course of these simulations, the parameters \(\sigma ^\), \(\sigma ^\), \(E^\), and \(E^\) were consistently maintained at values of 32, 4, 50, and 49, respectively, with the duration of stimuli being fixed at 6 ms.
For the spatial tasks, the Multisensory Spatiotemporal Causal Inference network parameters \(\sigma ^\), \(\sigma ^\), \(E^\) and \(E^\) with the same boundaries and constraints as the previous model. For the temporal task, the parameters \(\tau ^\), \(\tau ^\), \(\tau ^\), \(W_^\), \(W_^\) and \(W_^\) were fitted with boundaries set at (15, 50), (15, 50), (0.005, 50), (0, 7.5), (0, 0.15), (0, 0.005) respectively. During these simulations, the parameters \(\sigma ^\), \(\sigma ^\), \(E^\), and \(E^\) were consistently maintained at values of 32, 4, 2.55, and 2.5, respectively, with the duration of stimuli being fixed at 6 ms. Parameters \(\Delta t_\) and \(\Delta t_\) were assumed to be constant at 16 ms and 24 ms, respectively.
We acknowledge that employing a standardized fitting routine based on a genetic algorithm for noise-free model simulations may not constitute the optimal choice across all models. This approach may be particularly suboptimal for the Bayesian Causal Inference model, which was originally implemented utilizing a maximum-a-posteriori estimator with the assumption of random motor noise over 10,000 simulations (Körding et al., 2007).
Comments (0)