With the global diffusion of different TIRADS [12], standardization of the lexicon has become a hot topic in the field of thyroid US [5]. On the one hand, US operators must ask themselves if they actually adhere to what eminent societies have defined as the standardized terminologies to describe TNs. On the other hand, all users have to consider that AI has been rapidly diffused throughout medicine and that non-medical personnel and patients can also access online tools to better understand their clinical risks. In the thyroid field, although AI is gaining momentum, no strong results have been published about the performance of AIs in assessing the RoM of TNs on the basis of their US written description. Therefore, we conducted the present study to assess the IOA between AIs in their risk assessments according to the three major TIRADSs. These data are relevant when we consider AI as a potential tool to improve our clinical practice, and the data can also intrinsically help us to evaluate the capability of AI in understanding the US terminology.
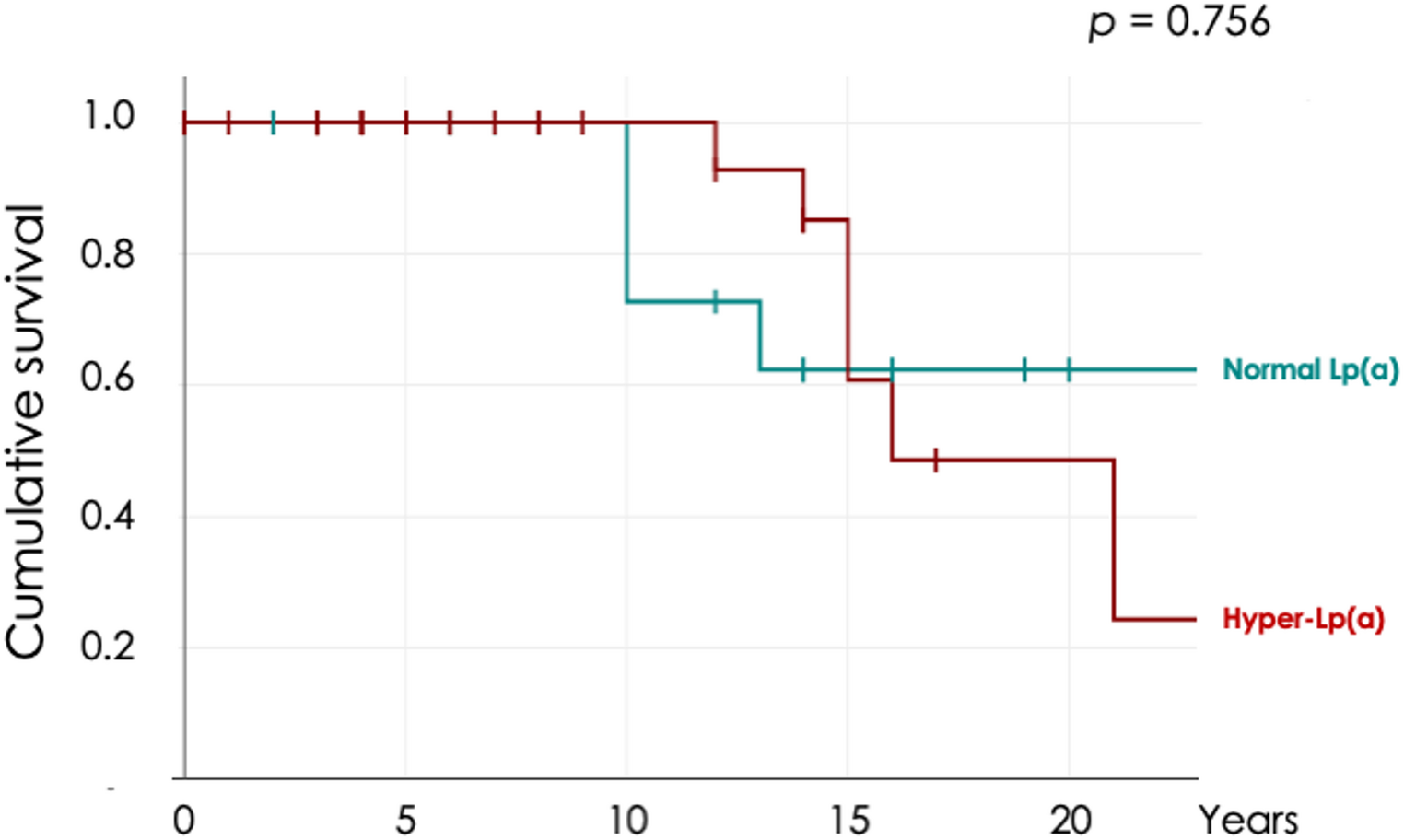
The present study results can be summarized as follows. 1) Non-negligible heterogeneity is observed between AIs in the assessment of TNs according to the three TIRADSs. ChatGPT shows lower risk assessment with ACR-TIRADS, Claude divides the TNs into low- or high-risk classes with EU- and K-TIRADS, and Gemini assesses some cases as high-risk with ACR- and K-TIRADS but none with EU-TIRADS. 2) The IOA between AIs is generally moderate to good. 3) The value of κ tends to change according to the TIRADSs: the IOA between ChatGPT and Gemini is lowest with ACR-TIRADS, increases with EU-TIRADS, and is higher with K-TIRADS. A similar trend is observed for the IOA between ChatGPT and Claude, and an inverse trend is observed for the IOA between Gemini and Claude. This intrinsically means that the IOA can depend on the systems compared. To the best of our knowledge, this is the first data concerning the IOA between AIs in assessing the RoM of TNs according to the TIRADS categories.
In the field of medical US, AI-enhanced tools can guide human operators in real time, improving image acquisition, probe positioning, and reproducibility. From this point of view, AI is expected to transform healthcare, particularly for imaging and diagnostics. Although AI applications on medical images include the automated detection of lesions, accurate organ segmentation, and quantitative analysis of features, further advancements are warranted in the AI understanding of the written lexicon. All AI tools learn from data reported in online documents. To develop AI tools, researchers initially created algorithms that attempted to imitate the reasoning of humans. These algorithms are based on all types of written language that constantly change over time with human progress. The present results demonstrate that AI shows promise for understanding the terminology of TIRADSs, but important differences are observed between the tested AIs. The suboptimal IOA between the AIs we observed can be due to the differences in conceptualization between the TIRADSs. The three TIRADSs were conceived in the USA, Europe, and Asia, and had significantly different cultural contexts (i.e., health systems, costs, national programs, patient opportunities, hospital access, availability of medical procedures, and physician–patient communication) [7]. In addition, although the EU- and K-TIRADS are pattern-based systems, ACR-TIRADS is point based. Furthermore, ACR-TIRADS was basically conceived to reduce costs from FNACs and the literature has proven this assumption to be true [13, 14]. As we recently showed, these features can influence the different understandings of terminology by computer scientists even if they work in the medical field [15]. Consequently, the present findings should be of interest to computer/AI specialists and warrant broad discussion among this research community.
The present study had limitations that need to be discussed. The TIRADS scenarios were randomly selected, and their categories were differently represented in the 90 cases. However, this strategy was intended to avoid bias from predefined series. Second, the structures of the three TIRADSs and their US descriptors differ from each other. However, the various descriptors can sound quite similar to human operators.
In conclusion, our study found that there was non-negligible variability among the three AI tools tested for assessing the RoM of TNs across TIRADSs categories. These results have high relevance for future advancements in this field and should be of particular interest to the researchers involved in the ongoing international project to create the I-TIRADS. Clinicians and patients should be aware of these new findings.


Comments (0)