We performed this cross-sectional comparative study in October 2024. The study was exempt from research ethics board approval and the need for informed consent in accordance with European law, given the lack of involvement of human participants or patient data. We utilized the TRIPOD-LLM guideline for reporting [13].
Dataset
This study utilized 1181 critical care MCQs from the gotheextramile.com (GETM) dataset [14]. GTEM is a comprehensive dataset, designed to assess critical care knowledge at the European Diploma in Intensive Care (EDIC) examination level. Similar to the EDIC exam, the dataset included two types of questions: 74.5% (n = 880) were Type A MCQs (single best answer from four options) and 25.5% (n = 301) were Type K MCQs (four or five true or false statements). The GTEM dataset covers a wide range of critical care domains, which can be found in Supplement A. Due to the nature of the specific LLMs tested, image-based questions were omitted.
Human comparison
For the comparison with human physicians, we evaluated the LLMs on a practice exam at EDIC examination level, consisting of 77 questions, of which 68.8% (n = 53) were Type A and 31.2% (n = 24) were Type K MCQs. For this exam, performance was calculated using a scoring system, in which false answers would deduct points. Human comparators were GTEM subscribers who took the practice exam in 2023 or 2024.
GTEM’s subscriber base spans roughly 50 countries, with India accounting for the largest portion (40–50%). European nations, notably the Netherlands, Denmark, Switzerland, Germany, and the UK, make up the second-largest group, while the United States has minimal representation. The subscriber base consists of physicians, both residents and consultants, predominantly those preparing for the written EDIC exam. Subscribers typically have backgrounds in anesthesiology, with 3 to 5 years of experience in anesthesiology and 1 to 5 years in intensive care. Approximately 30% are repeat subscribers.
Large language models
In total, five LLMs were evaluated: four proprietary foundation models, i.e. GPT-4o, GPT-4o-mini and GPT-3.5-turbo, developed by OpenAI, and Mistral Large 2407 (Mistral AI), and one open-source model, being Llama 3.1 70B (Meta). They were accessed via the Microsoft Azure OpenAI platform. For each model, the temperature setting, which controls the randomness of the model’s outputs, was set to 0, to achieve the most consistent results.
Prompting methods
The prompts were written by a team of experts in medical prompt engineering in an iterative manner. The final prompt used in this study is available in Supplement B. It was important for the final prompt to have utilized zero-shot prompting, meaning that the models are presented with critical care MCQs without prior fine-tuning on medical datasets or knowledge of example questions. This approach aims to assess the models’ inherent critical care knowledge and provide accurate answers based solely on their pre-trained knowledge.
Evaluation
The performance of the LLMs was assessed using multiple evaluation metrics. The primary outcome measure was the overall accuracy, calculated as the percentage of correctly answered MCQs, which we compared to random guessing (e.g., 25% accuracy for questions with four options).
Secondary outcomes included consistency, domain-specific accuracy, costs as a proxy for computing resources or energy use and performance of the LLMs compared with human physicians on a practice exam.
A consistency check was performed by presenting the models with repeated questions to assess the reliability of model responses. One hundred randomly selected questions from the dataset were given to each model 10 times. A model’s response was considered consistent if it provided the same answer for at least 8 out of 10 repetitions (80% threshold) of a given question. The consistency score for each model was calculated as the percentage of questions for which the model demonstrated consistency, distinguishing between consistently correct and consistently incorrect responses.
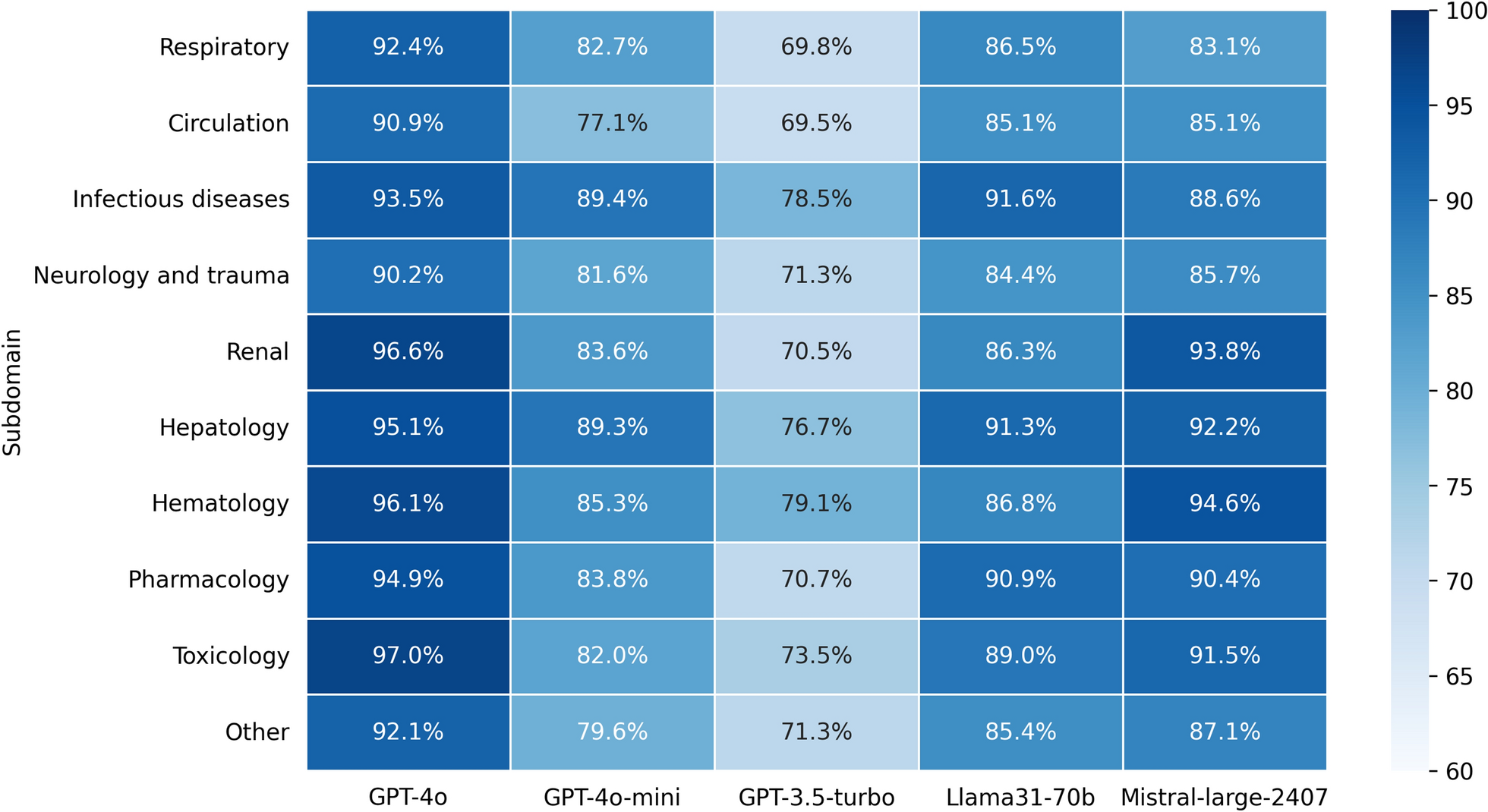
Domain-specific performance was evaluated by categorizing questions according to critical care topics and calculating accuracy rates for each domain.
Cost per model were calculated directly using the Microsoft Azure OpenAI platform. Pricing is based on the amount of input and output tokens. Efficiency scores were calculated by dividing the performance of the model with its cost.
Statistical analyses
All statistical analyses were performed with Python version 3.11, utilizing libraries such as Numpy, Pandas, Matplotlib, Seaborn and Statsmodels. Continuous variables were summarized using means and standard deviations (SD) or medians and interquartile ranges (IQR), based on the distribution of the data. Categorical variables were summarized as percentages.
The primary outcome measure, overall accuracy, was calculated as the percentage of correctly answered MCQs for each model. Comparative analyses between the performance of the LLMs against random guessing and human physician comparators were conducted using Z-tests for proportions. This method was selected due to the large sample size and binary nature of outcomes (correct/incorrect), allowing for reliable comparisons against fixed performance benchmarks (i.e. random guessing or human comparators).
A p value of < 0.05 was considered statistically significant.









Comments (0)