
Remember me










Atrial fibrillation (AF) is the most common arrhythmia in developed countries,1 and its prevalence is gradually increasing as societies age.2 AF is associated with a high risk of stroke, heart failure and all-cause mortality.3 The Framingham study was the first to describe the mortality risk of AF,4 and recent studies revealed that AF is significantly associated with not only cardiovascular death but also non-cardiovascular death.5 A possible reason for the high risk of mortality is that patients with AF frequently have various comorbidities.6 Thus, AF is becoming an epidemiologically important heterogeneous syndrome rather than simply one of the arrhythmias.
Currently, AF is usually classified by using arrhythmia subtype (paroxysmal, persistent or permanent) or thromboembolic risk score, such as CHADS2 (congestive heart failure, hypertension, age ≥75 years, diabetes, and stroke) and CHA2DS2-VASc (congestive heart failure, hypertension, age ≥75 years, diabetes, stroke, vascular disease, age 65–74 years and male).7 8 However, these classifications are not always sufficient to characterise the heterogeneous pathophysiology of AF.
One candidate approach to adequately categorise this heterogeneity is cluster analysis, a machine learning methodology for subclassifying complex data.9 This approach has recently been widely used to identify subphenotypes of heart failure with preserved ejection fraction or coronary artery disease.10 11 Furthermore, recent research reported the usefulness of cluster analysis in AF.12 13 However, one of the limitations of these studies is the lack of external validation; that is, it is unknown whether the phenotypes identified in one study can be applied to other AF cohorts. Accordingly, in the present study, we applied the clustering approach to a large AF cohort, investigated the characteristics and prognostic value of each phenotype, and validated the prognostic differences of phenotypes in an external validation AF cohort.
MethodsStudy populationWe used two large-scale, prospective, multicentre AF registries: the SAKURA AF registry (Real World Survey of Atrial Fibrillation Patients Treated with Warfarin and Non-vitamin K Antagonist Oral Anticoagulants) and the RAFFINE registry (Registry of Japanese Patients with Atrial Fibrillation Focused on anticoagulant therapy in New Era). In the present study, the SAKURA AF registry was categorised as the derivation cohort and used to construct a subphenotyping model, while the RAFFINE registry was categorised as the external validation cohort and used to assess the validity of the subphenotyping model.
SAKURA AF registry (derivation cohort)This registry is a prospective, observational multicentre study (UMIN000014420). The study design, data collection and patient characteristics have been reported previously.14 15 The registry enrolled 3267 patients with non-valvular AF from September 2013 to December 2015 at 63 Tokyo institutions: 2 cardiovascular centres, 13 affiliated hospitals or community hospitals, and 48 private clinics (online supplemental methods).
RAFFINE registry (external validation cohort)This registry prospectively enrolled 3889 patients with AF between January 2013 and December 2015 at 4 university hospitals and 50 general hospitals/clinics (UMIN000009617). The study design and primary results have been reported previously (online supplemental methods).16
Definitions of variablesAF types were categorised as paroxysmal, persistent or permanent. Regarding ischaemic heart disease (IHD), the RAFFINE registry defined IHD as angina, myocardial infarction (MI), silent myocardial ischaemia, and history of coronary intervention or coronary artery bypass grafting, whereas the SAKURA AF registry defined it as only angina or MI. Creatinine clearance (CrCl) was calculated with the Cockcroft-Gault formula (online supplemental methods).
Cluster analysis by machine learningCluster analysis identifies similar individuals based on their features. We applied the K-prototype clustering method, a non-hierarchical iterative clustering algorithm that combines the K-means of numerical variables and K-modes of categorical variables to cluster a mixture of continuous and categorical data.17 Variables with more than 1% missing data in the derivation cohort were excluded from the analysis, and the following 14 variables from among baseline characteristics, medical history, comorbidities and laboratory variables were used: age, sex (categorical data), systolic blood pressure, body mass index (BMI), history of heart failure (categorical data), hypertension (categorical data), diabetes (categorical data), haemoglobin, platelet, aspartate transaminase, alanine transaminase (ALT), CrCl, CHA2DS2-VASc score and HAS-BLED bleeding risk score (hypertension, abnormal renal/liver function, stroke, bleeding, labile international normalised ratio, age >65 years and use of drugs/alcohol). We used the elbow method to select the optimal number of clusters, which was found to be five, and thereby observed the sum of squared errors (online supplemental methods and online supplemental figure 1). We calculated the centroids of the five clusters in the derivation cohort and assigned the external validation cohort individuals to each cluster by applying the obtained centroids. Cluster analysis was performed with Python V.3.8.9 (Python Software Foundation, Beaverton, Oregon, USA).
Follow-up data and outcome assessmentWe defined the primary outcomes as all-cause mortality and composite events. Composite events included major bleeding, stroke, MI and all-cause mortality (online supplemental methods).
Statistical analysisContinuous variables were represented as mean±SD or median (IQR), and categorical variables as number (percentage) of patients. Differences between continuous variables were analysed by one-way analysis of variance, and differences between categorical variables by the χ2 test. Kaplan-Meier curves were plotted for the cumulative incidences of events, and the log-rank test was used to compare the differences in each cluster. Univariate and multivariate-adjusted Cox regression models were used to assess the association between clusters and clinical outcomes. We created two multivariate analysis models: model 1, which was adjusted for the CHA2DS2-VASc score; and model 2, which was adjusted for age ≥75 years, sex and AF type.
All statistical analyses were performed with JMP V.16.2 (SAS Institute, Cary, North Carolina, USA). For all analyses, a p value less than 0.05 was considered statistically significant.
ResultsBaseline patient characteristicsIn the derivation cohort, 212 patients were excluded because laboratory data were missing; thus, 3055 patients were analysed (mean age, 72 years; 26.3% female). Of these, 52.3% were treated by direct oral anticoagulants (DOACs) and 47.6% by warfarin. In the external validation cohort, 37 patients were missing laboratory data and were excluded, and 3852 patients were analysed (mean age, 72 years; 31.3% female); 43.0% were treated by DOACs and 44.7% by warfarin. Compared with the derivation cohort, the external validation cohort had higher CHA2DS2-VASc and HAS-BLED scores (online supplemental table 1). Baseline characteristics were not significantly different between the included patients and the excluded patients in both cohorts, except for AF types and prevalence of hypertension (online supplemental tables 2 and 3).
Description of clustersThe cluster analysis identified five clusters in the derivation cohort. Baseline clinical characteristics, medications and laboratory data are shown in table 1. Figure 1 shows the specific features of each cluster.
 Figure 1
Figure 1 Description of characteristics in each cluster. AF, atrial fibrillation; BMI, body mass index; BNP, B-type natriuretic peptide; CKD, chronic kidney disease; IHD, ischaemic heart disease.
Table 1Baseline patient characteristics in the derivation cohort (SAKURA AF registry)
Cluster 1 (n=414, 13.6%) comprised younger patients (57.1±6.8 years) and mainly male patients (91.8%). The BMI was the highest of all the clusters (25.8±4.2 kg/m2), and the rates of IHD were the lowest (0.9%). The main treatment was DOACs (61.8%), and usage of antiplatelet agents was the lowest (2.9%). As to laboratory data, the cluster had the highest levels of haemoglobin, platelets, total cholesterol, triglycerides, ALT and CrCl and the lowest level of B-type natriuretic peptide (BNP).
Cluster 2 (n=1003, 32.8%) was the largest cluster. The main characteristics of this cluster were older age and male sex. The prevalence of hypertension was high, and the risk of hypertension was the highest among all the clusters (99.5%). Furthermore, the cluster had the second highest levels of haemoglobin and CrCl and the second lowest BNP level. About half of the patients (50.2%) were treated with DOACs.
Cluster 3 (n=517, 16.9%) had the lowest prevalence of hypertension (0.4%) and a mean age similar to that of cluster 2 (73.2±6.2 years). The prevalence of diabetes (12.9%), history of heart failure (19.7%) and IHD (4.6%) was similar to other clusters. This cluster had the second lowest CHA2DS2-VASc score (2.0±0.8).
Cluster 4 (n=652, 21.3%) comprised mainly of the oldest patients and had the highest number of women (84.5%) and the lowest BMI (22.5±3.3 kg/m2). The prevalence of a history of heart failure was the highest among the clusters (31.6%), and the prevalence of hypertension was high (83.1%). Regarding laboratory data, this cluster had the lowest levels of haemoglobin, triglycerides, ALT and CrCl and the highest level of BNP.
Cluster 5 (n=469, 15.3%) comprised older patients (75.4±6.7 years) and had a high proportion of men (84.8%) and the highest prevalence of permanent AF (61.2%). This cluster was characterised by a high prevalence of diabetes (85.4%), hypertension (92.4%), history of heart failure (33.8%) and IHD (8.7%). In particular, this cluster had the highest prevalence of diabetes and IHD and the highest CHA2DS2-VASc and HAS-BLED scores. Concerning medications, the prescription ratios of antiplatelet agents (43.5%) and warfarin (60.1%) were the highest in this cluster, and the prescription ratio of DOACs was the lowest. The cluster had the second lowest levels of haemoglobin and CrCl (second only to cluster 4).
Clinical outcomes between AF clustersDuring a median follow-up of 1176 days (IQR, 853–1309 days), 186 deaths, 116 major bleeding, 114 strokes and 40 acute MIs occurred in the derivation cohort. The Kaplan-Meier curves of endpoints (all-cause mortality and composite events) across the five clusters are shown in figure 2 (log-rank p<0.001, p<0.001). Cluster 1 had the lowest risk of all-cause mortality and composite events, and the incidence of these risks was significantly different across all the clusters. On univariate Cox regression analysis, the risk of both all-cause mortality and composite events was significantly higher in clusters 2–5 than in cluster 1 (table 2). These associations remained significant in the multivariate Cox regression analysis, even after adjustment of models for CHA2DS2-VASc score and AF type (table 2).
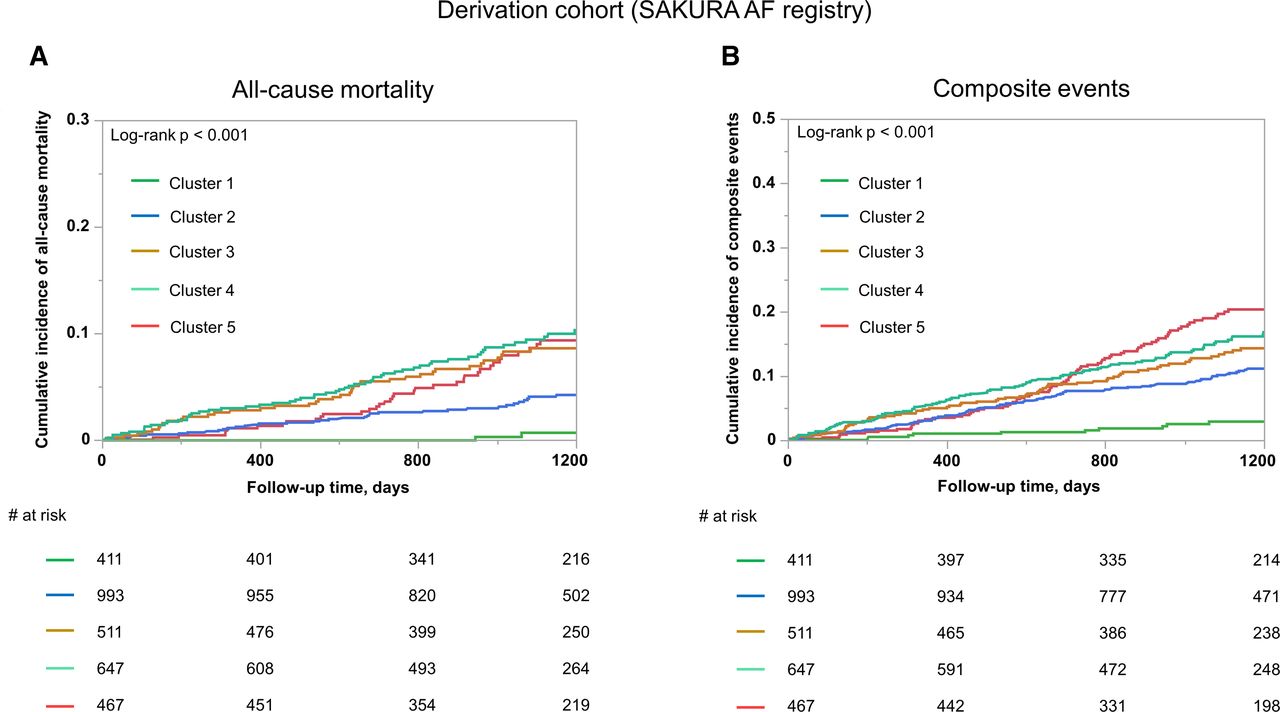 Figure 2
Figure 2 Kaplan-Meier curves for the incidence of all-cause mortality (A) and composite events (B) during the follow-up period according to the clusters in the derivation cohort (SAKURA AF registry). SAKURA AF, Real World Survey of Atrial Fibrillation Patients Treated with Warfarin and Non-vitamin K Antagonist Oral Anticoagulants.
Table 2Univariate and multivariate Cox regression analyses for all-cause mortality and composite events in the derivation cohort (SAKURA AF registry)
External validationWe used the external validation cohort to externally validate the cluster analysis and classified 3852 patients into five clusters based on the centroids of the clusters obtained in the derivation cohort: cluster 1 (n=418, 10.8%), cluster 2 (n=1341, 34.8%), cluster 3 (n=664, 17.2%), cluster 4 (n=648, 16.8%) and cluster 5 (n=781, 20.2%). Baseline patient characteristics in each cluster were consistent with the derivation cohort (table 3). During a median follow-up of 1390 days (IQR, 1078–1820 days), 382 deaths, 197 major bleeding, 166 strokes and 26 acute MIs occurred in the external validation cohort. The Kaplan-Meier curves of these outcomes across the five clusters are shown in figure 3. The incidence of all-cause mortality and composite events increased from cluster 1 to cluster 5 (log-rank p<0.001, p<0.001). As regards consistency with the derivation cohort, the association between the differences between clusters and clinical events (all-cause mortality and composite events) remained significant in the multivariate Cox regression analysis, even after adjustment for CHA2DS2-VASc score and AF type (table 4).
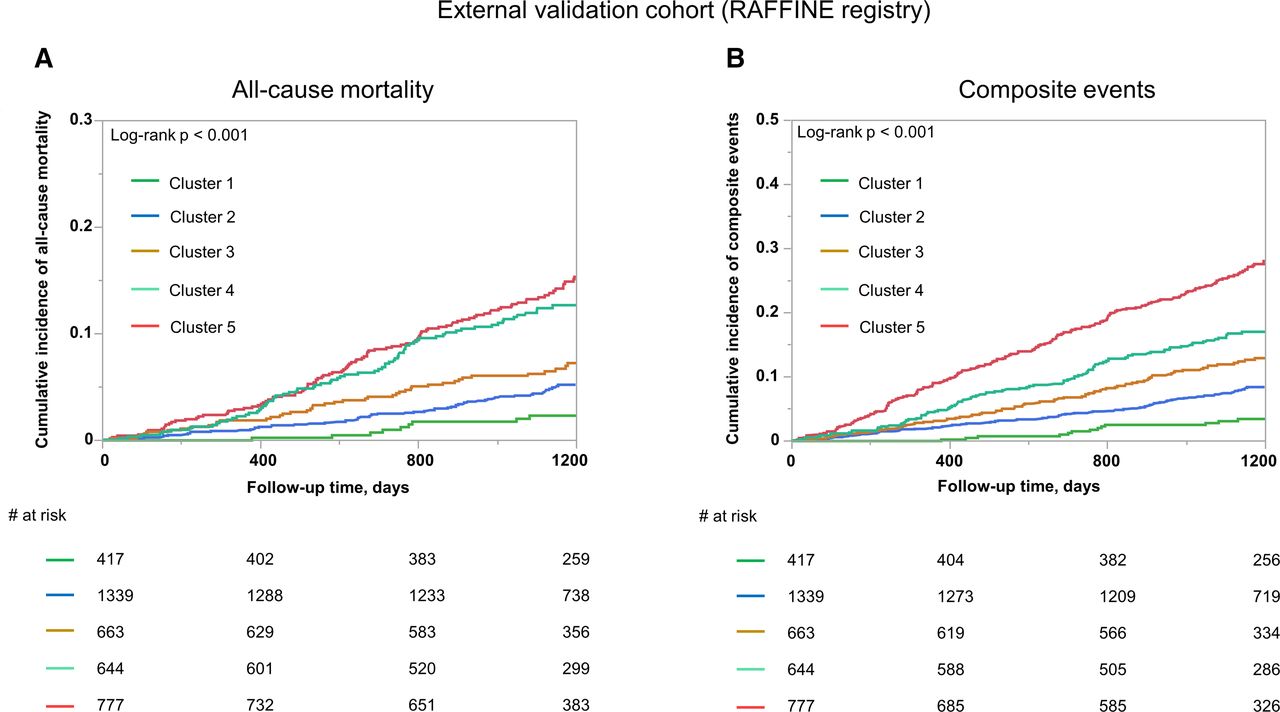 Figure 3
Figure 3 Kaplan-Meier curves for the incidence of all-cause mortality (A) and composite events (B) during the follow-up period according to the clusters in the external validation cohort (RAFFINE registry). RAFFINE, Registry of Japanese Patients with Atrial Fibrillation Focused on anticoagulant therapy in New Era.
Table 3Baseline patient characteristics in the external validation cohort (RAFFINE registry)
Table 4Univariate and multivariate Cox regression analyses for all-cause mortality and composite events in the external validation cohort (RAFFINE registry)
DiscussionIn the present study, we used cluster analysis to identify subphenotypes of patients with AF. The major findings are as follows: (1) cluster analysis identified five clinically relevant phenotypes that present with different specific features in AF; (2) these clusters were associated with different risks of all-cause mortality and composite events; and (3) the demographic features of each phenotype and the association with clinical outcomes were externally validated, showing the robustness of the cluster analysis. These findings highlight the large heterogeneity of AF and suggest that phenotyping by cluster analysis unmasks new phenotype classifications that are not revealed by conventional approaches.
Heterogeneity of AF and cluster analysisAF is often accompanied by various comorbidities and associated with poor clinical outcomes, such as stroke, heart failure and mortality.3 6 Because of this heterogeneous pathophysiology, conventional AF classifications, for example, based on AF type, might not be adequate to classify the underlying condition or risk stratification of AF. Here, we used the K-prototype method as a clustering approach. This method enables patients to be clustered on the basis of both continuous and categorical variables.17 Although several other studies have used a clustering approach in AF,18 19 this is the first study to apply this methodology to an AF cohort and validate the results in an external cohort.
Demographic features of AF clustersThe five subphenotypes identified in the present study show specific clinical characteristics. Cluster 1 is the ‘young/low IHD cluster’ and is characterised by young men, high BMI and low incidence of IHD. Individuals in this cluster were mainly treated by DOACs. Cluster 2 is the ‘hypertensive cluster’ and is characterised by older men and a high prevalence of hypertension. In our study, this cluster was the largest in both the derivation cohort (32.8%) and the external validation cohort (34.8%). Cluster 3 is the ‘without hypertension cluster’ and is characterised by the lowest prevalence of hypertension. Cluster 4 is the ‘oldest/female/heart failure’ cluster. This cluster had the highest prevalence of a history of heart failure in both the derivation (31.6%) and the external validation (33.8%) cohorts. Furthermore, it is characterised by anaemia, malnutrition (evidenced by low BMI, ALT and triglyceride) and renal dysfunction. Of note, cluster 4 had lower ALT levels than the other clusters. Recently, we reported that low ALT levels are significantly associated with ageing, sarcopaenia, malnutrition, and consequently with a high risk of all-cause mortality in patients with AF.20 Cluster 5 is the ‘multiple atherosclerotic comorbidity cluster’ and is characterised by the highest prevalence of diabetes and IHD and the highest CHA2DS2-VASc and HAS-BLED scores. The demographic features of each cluster were consistent in the derivation and external validation cohorts.
Previous cluster analyses identified various AF phenotypes.12 18 21 For example, a recent study that used the J-RHYTHM Registry, a large prospective AF registry in Japan, identified four specific AF clusters: a younger/low comorbidity cluster, hypertensive cluster, high bleeding cluster and atherosclerotic comorbidity cluster; the hypertensive cluster was the largest.21 Our analysis also identified a ‘young/low IHD cluster’ and ‘hypertensive cluster’, and the ‘hypertensive cluster’ was the largest in both the derivation cohort and the external validation cohort.
To our knowledge, our analysis is the first to identify a ‘without hypertension cluster’ as an AF phenotype. Interestingly, in this cluster, the prevalence of other comorbidities, such as diabetes, heart failure and IHD, was similar to that in the other clusters. We speculate that other risk factors beyond generally relevant risk factors, such as liver diseases, inflammation and cancer, may contribute to the formation of this cluster.
Previous studies also identified clusters with atherosclerotic comorbid AF in older patients.13 22 The major differential features of our results are that they distinguish between an ‘oldest/female/heart failure cluster’ (cluster 4) and a ‘multiple atherosclerotic comorbidity cluster’ (cluster 5). Both these clusters encompass older patients with multiple comorbidities, but the major difference is sex in that the ‘oldest/female/heart failure cluster’ consisted mainly of female patients. Previous studies had not identified these specific features of clusters in older patients and patients with multiple comorbidities.
Prognostic significance of AF clustersIn the present study, the incidence of all-cause mortality and composite events was well stratified by the five identified phenotypes. Cluster 1 had the lowest risk of all-cause mortality and composite events, and cluster 5 had the highest risk of composite events, followed by cluster 4. We confirmed the prognostic relevance of each cluster in the external validation cohort, where cluster 1 had the lowest risk of all-cause mortality and composite events and cluster 5 had the highest risk of both adverse outcomes. One of the relevant findings of these associations between clusters and outcomes is that cluster 5 had a higher incidence of composite events than cluster 4 in both the derivation and the external derivation cohorts, although cluster 4 was older. Furthermore, the prognostic relevance of clusters remained significant after adjustment for CHA2DS2-VASc score and conventional AF type. Our results suggest that AF phenotypes classified by machine learning have prognostic relevance beyond conventional risk score, age and AF type.
AF is a complex condition requiring holistic management with multiple treatment decisions regarding stroke prevention, symptom control, rhythm or rate control, and management of comorbidities. It was recently reported that the implementation of an integrated holistic approach was associated with a lower risk of the composite outcome of cardiovascular events and all-cause death in patients with high-risk metabolic comorbidities.23 However, only 21%–23% of patients were adherent to this approach.23 Our clustering approach highlights the importance of identifying high-risk patients who need more intensive care and also reinforces the concept that patients with AF need improved clinical characterisation beyond simple classification based on arrhythmia patterns. In addition, early initiation of rhythm control therapy has recently been shown to reduce the risk of adverse events in patients with early AF (diagnosed within 1 year).24 However, the clinical benefit of this therapy may vary according to patient phenotype. Therefore, our clustering approach may help classify patient subgroups for the development of phenotype-specific treatments in the future.
LimitationsThis study has several limitations. First, it is a post-hoc analysis that uses two established multicentre registries. Second, the identified clusters may vary depending on the available data; in the present study, we selected a relatively small number of well-documented variables, whereas machine learning typically uses a large number of features. Third, we did not obtain echocardiographic data, so we could not include echocardiographic indices such as left atrial volume in the cluster analysis. Fourth, we did not perform multiple imputations for lacking data. The exclusion of missing data may have biased the overall results. Last, the present study was conducted on Japanese patients, and both the derivation cohort and the external validation cohort were from Japanese registries. Therefore, further studies including various other regions and ethnicities are warranted.
Comments (0)