
Remember me





To study the interplay between NPIs and mobility, we employ the panel spatial autoregressive (SAR) model to obtain direct effects and SSE from different NPIs [36]. Unlike the linear panel model, the spatial panel model considers the dependence between geographically adjacent units [37]. This enables us to capture the SSE across geographical units [25].
$$\begin \varvec = \rho \varvec + \varvec} \varvec + \varvec +l_N \xi _t + \varvec}, \end$$
(2)
where \(}_}}\) denotes the change of human mobility for 49 regions at week t. \(}_}}\) contains in total seven 1-week lagged NPI intensities for 49 regions, and \(\varvec\) is the corresponding slope coefficient. \(\varvec\) denotes the spatial weights matrix that captures the connectivity of 49 regions. \(\varvec\) represents the spatial lag term of intrastate human mobility and \(\rho\) denotes the spatial effect across regions. \(l_N\) represents a \(49 \times 1\) column vector of ones. \(\nu\) and \(\xi _t\) are, respectively, \(49 \times 1\) vector of regional effects and a scalar time effect. \(\epsilon _t = (\epsilon _,\cdots , \epsilon _)^T\) is a vector of disturbance terms, where \(\epsilon _\) is assumed to be independently and identically normally distributed for all i with zero mean and variance \(\sigma ^2\).
Note that the spatial weight matrix is an important pre-defined input for the spatial econometric model. The spatial weight matrix \(\varvec=[W_]\) reflects the degree of adjacency or association between spatial units that can be specified based on the adjacency or distance relationship [38]. However, it’s important to keep in mind that the transmission of infectious diseases, such as COVID-19, may not always be limited to geographically close regions. Geographical proximity does not fully capture air-traffic-mediated epidemics [39]. Thus, determining neighbors merely from geographical distance is not sufficient. To overcome this limitation, we use the spatial interaction distance, which captures the dependence relationship by human interaction across regions. Following the concept of KNN, we construct the K maximum interaction matrix (KMI) based on the spatial interaction distance. Like KNN, the key aspect of the KMI method is selecting the K-value and calculating the distances. We define the distance by origin–destination (OD) flows between region i and j as: \(d(i,j) = flow_\), if \(i = j\), \(d(i,i) = 0\). Then, we identify the first k regions with the closest interaction distances to region i as its neighbors. To determine the value of k, we use the deviance information criterion (DIC) as described in Gelman [40]. The KMI is constructed based on the interstate human mobility data from 6 January to 2 February 2020 and all spatial weight matrices are normalized. The detailed specifications of the spatial weights can be found in the Supplementary materials.
Derivation of direct and spatial spillover effects of NPIsFollowing [36, 41], we rely on the following reduced form of Eq. 2 to derive the direct effects and SSE:
$$\begin \begin \varvec&= (\varvec -\rho \varvec)^ \varvec \lambda }+ (\varvec -\rho \varvec)^(\varvec + l_N \xi _t + \varvec), \end \end$$
(3)
where \(\varvec\) is the identity matrix of dimension n. The \(n \times m\) matrix of \(\varvec}\) can be partitioned by columns as \(\varvec}=(X_,\cdots ,X_)\), where \(X_=(x_,x_,\cdots ,x_)'\) is the \(n \times 1\) vector of the rth NPI measure for all n regions and \(x_\) represents the rth NPI measure of region i at period \(t-1\). Denote \(V(\varvec)=(\varvec -\rho \varvec)^\) and \(U_r(\varvec )=V(\varvec) \lambda _r\), with \(\lambda _r\) being the rth coefficient of \(\varvec\). Equation 3 can be rewritten as:
$$\begin \varvec&=V(\varvec) \sum _^m \lambda _r X_+ V(\varvec) (\varvec + l_N \xi _t ) +V(\varvec) \varvec, \nonumber \\&=\sum _^m U_r(\varvec)X_+ V(\varvec) (\varvec + l_N \xi _t ) +V(\varvec) \varvec. \end$$
(4)
Let \(U_(\varvec)\) be the \(i\hbox \) row and \(j\hbox \) column element of \(U_r(\varvec)\), and \(V(\varvec)_i\) be the \(i\hbox \) row of \(V (\varvec)\). The \(i\hbox \) row of Eq. 3 reads:
$$\begin \begin Y_=\sum _^m [U_(\varvec)x_+\cdots +U_(\varvec)x_] + V(\varvec)_i (\varvec + l_N \xi _t ) +V(\varvec)_i \varvec. \end \end$$
(5)
Following LeSage and Pace [36], the marginal effect of the rth NPI measure of region j, namely, \(x_\) on the intrastate human mobility of region i, \(Y_\) is
$$\begin \frac}}=U_ (\varvec), \end$$
(6)
for \(j=1,2,\cdots ,n\). In particular, the direct effect from region i’s own NPI can be captured by \(U_ (\varvec)\), the ith diagonal element of \(U_ (\varvec)\). Hence, we can derive the overall direct effect and SSE of all NPI measures on \(Y_\), by adding the direct effect of all NPIs from region i, as well as the NPI spillovers from all other regions:
$$\begin \begin DE_&= \sum _^ U_ (\varvec) x_, \\ SSE_&= \sum _^ \sum _^ U_ (\varvec) x_. \end \end$$
(7)
The intrastate human mobility of region i can then be expressed as:
$$\begin \begin Y_ = DE_ + SSE_ + V(\varvec)_i (\varvec + l_N \xi _t ) +V(\varvec)_i \varvec, \end \end$$
(8)
which further implies
$$\begin E(Y_)=DE_ + SSE_ + V(\varvec)_i (\varvec + l_N \xi _t ). \end$$
(9)
In terms of estimation, we use the summation of the posterior means of the overall direct effect, the SSE, and the regional and time effect influence \(V(\varvec)_i (\varvec + l_N \xi _t )\) to approximate \(Y_\). Additionally, we set the estimated value of \(Y_\) equal to \(q_\), which means \(q_\) is the estimated change of intrastate human mobility. We use the Bayesian Markov Chain Monte Carlo (MCMC) method to estimate the coefficients of panel spatial econometric model. Details on the MCMC estimation algorithm as well as the direct effect and SSE estimates are provided in the Supplementary materials.
Based on the spatial panel SAR model, we evaluate the impact of NPIs on intrastate human mobility. The change in human mobility can significantly affect the transmission of infectious diseases like COVID-19. For example, the stay-at-home order restricts people’s travel and reduces human flow in the region, which minimizes contact between infected and susceptible individuals and ultimately contains infectious disease transmission. Therefore, many studies use the change in human mobility before and after interventions to construct infectious disease models that simulate disease transmission and evaluate the impact of policies [42, 43]. Here we use the estimated changes (\(q_\)) in human movement to develop the infectious disease model because it includes the direct effects and SSE of NPIs, which can help us simulate the effect of SSE of NPIs on disease transmission.
Parameter inference of S-SEIRThe introduction of the classical SEIR model is necessary prior to develop our infectious disease model, as it serves as an important reference. The basic form of the SEIR model can be expressed as:
$$\begin \begin \fracS}t} =&-\beta \frac \\ \fracE}t} =&\beta \frac -\frac \\ \fracI}t} =&\frac - \frac, \\ \fracR}t} =&\frac, \\ \end \end$$
(10)
where S, E, I, and R are susceptible, exposed, infected, and removed populations, N denotes the total population (\(N = S + E + I + R\)). \(\beta\) denotes the transmission rate, which is related to disease characteristics and population exposure. Z and D denote the incubation and infection periods. The inverse of the incubation period indicates the fraction of exposed individuals that become infected, while the inverse of the infection period indicates the fraction of infected individuals who recover or dead. Classical SEIR models typically assume that many disease characteristics, such as the transmission rate and infection period, are constant. However, this assumption does not apply to the complex transmission of COVID-19.
The change of intrastate human mobility can reflect the influence of NPIs [44], which may also affect the transmission rate of infectious diseases. When the interventions occur, the transmission rate can be quantified as \(\beta _t = (1-q) \beta _0\), with q being the proportion of an infectious individual’s daily susceptible contacts who will not go on to develop diseases and thus can be temporarily removed from the susceptible pool [45]. \(\beta _\) is the initial transmission rate. To incorporate the effects of NPIs on the transmission rate, we utilize the estimated changes (\(q_\)) in intrastate human mobility from our panel spatial econometric model to represent the number of removed susceptible contacts. Meanwhile, the estimated changes in intrastate human mobility can help us isolate the direct effects and SSE of NPIs. Therefore, we can develop the S-SEIR metapopulation model, taking into account the role of SSE on intrastate human mobility change during disease transmission.
$$\begin \begin \fracS_i}t} =&-(1-q_) \beta _ \frac - a (1-q_) \beta _ \frac \\&+ \theta \sum _ \fracS_j} - \theta \sum _ \fracS_i}, \\ \fracE_i}t} =&(1-q_) \beta _ \frac + a (1-q_) \beta _ \frac - \frac\\&+ \theta \sum _ \fracE_j} - \theta \sum _ \fracE_i}, \\ \fracI_i}t} =&\mu _i \frac - \frac, \\ \fracA_i}t} =&(1 - \mu _i) \frac - \frac + \theta \sum _ \fracA_j} - \theta \sum _ \fracA_i}. \end \end$$
(11)
\(S_i\), \(E_i\), \(I_i\), \(A_i\), and \(N_i\) are susceptible, exposed, symptomatic infected, and asymptomatic infected persons and total population of region i, with \(S_i + E_i + I_i + A_i + RI_i + RA_i = N_i\). \(RI_i\) and \(RA_i\) are removed for symptomatic and asymptomatic patients, respectively. \(\textrmRI_i/\textrmt = /\), \(\textrmRA_i / \textrmt = /\). For model parameters, \(\beta _\) can be expressed as \(\beta _0 = R_0 /D\), in which \(R_0\) is the basic reproductive number, indicating the average number of people infected by an infectious person. \((1-q_) \beta _\) indicates the transmission rate of symptomatic infected individuals, adjusted by the NPI direct effects and SSE influence of region i at time t. a is the transmission rate of asymptomatic infected persons relative to symptomatic infected persons. \(\mu _i\) denotes the reported fraction of symptomatic infections in region i, \(D_i\) is infectious period in region i. In addition, our model characterizes the interactions and movements between different subpopulations across time and space [46,47,48]. Specifically, the human movement among regions leads to weekly changes in the population of each region: \(N_i(t+1) = N_i(t) + \theta \sum _ \Delta M_(t) - \theta \sum _ \Delta M_(t)\), \(\Delta M_(t)\) denotes the population flows from region i to j at week t. \(\theta\) is an adjustment factor to adjust the human movement data as it is only a sample data set. Inter-regional population movement can cause case exchange across regions. We assume that symptomatic individuals are immobile but susceptible, exposed, and asymptomatic patients can move across regions. \(\Delta M_S_i\), \(\Delta M_E_i\) and \(\Delta M_A_i\) denote the susceptible, exposed, asymptomatic patients moving from i to j, respectively.
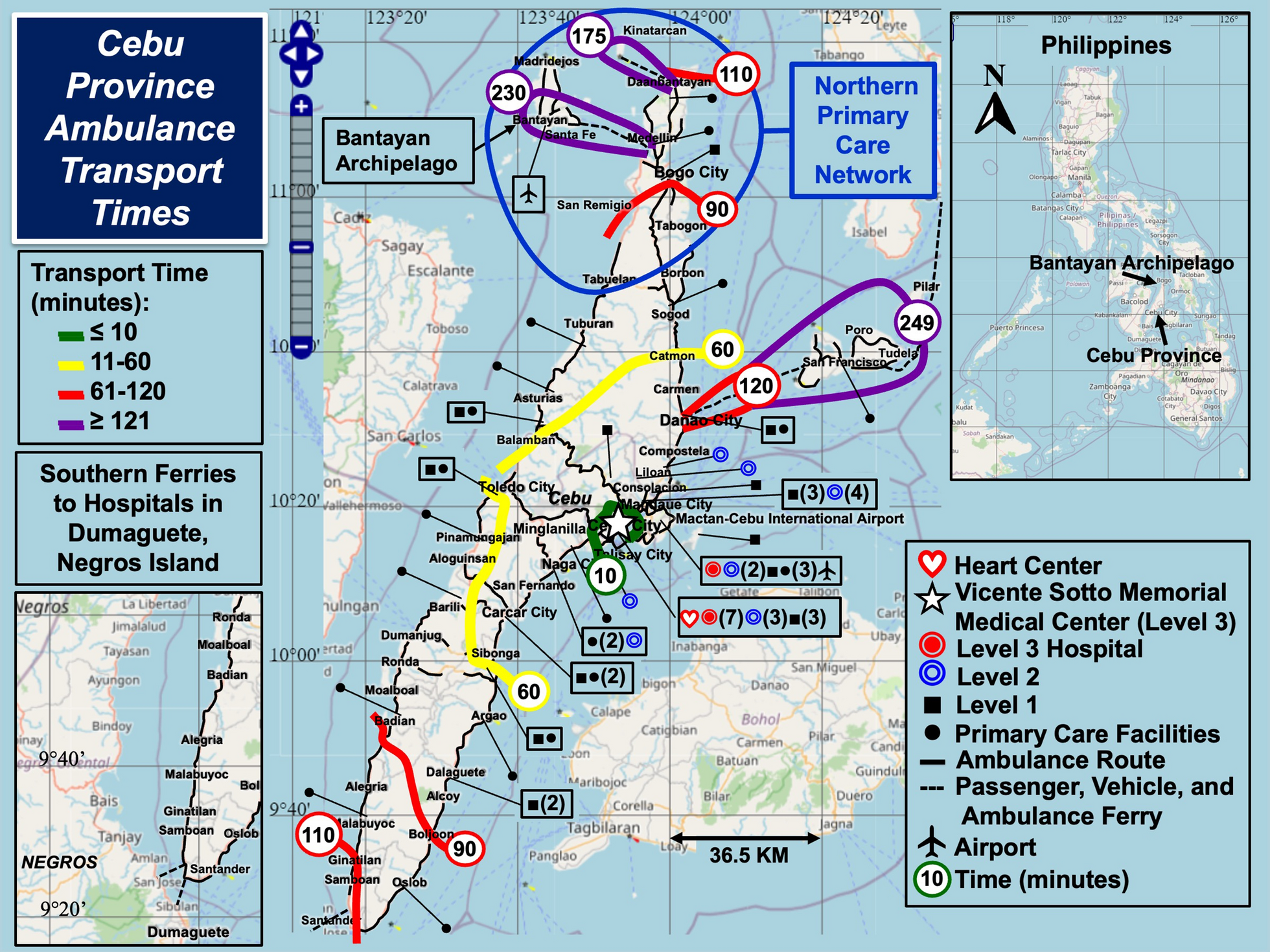
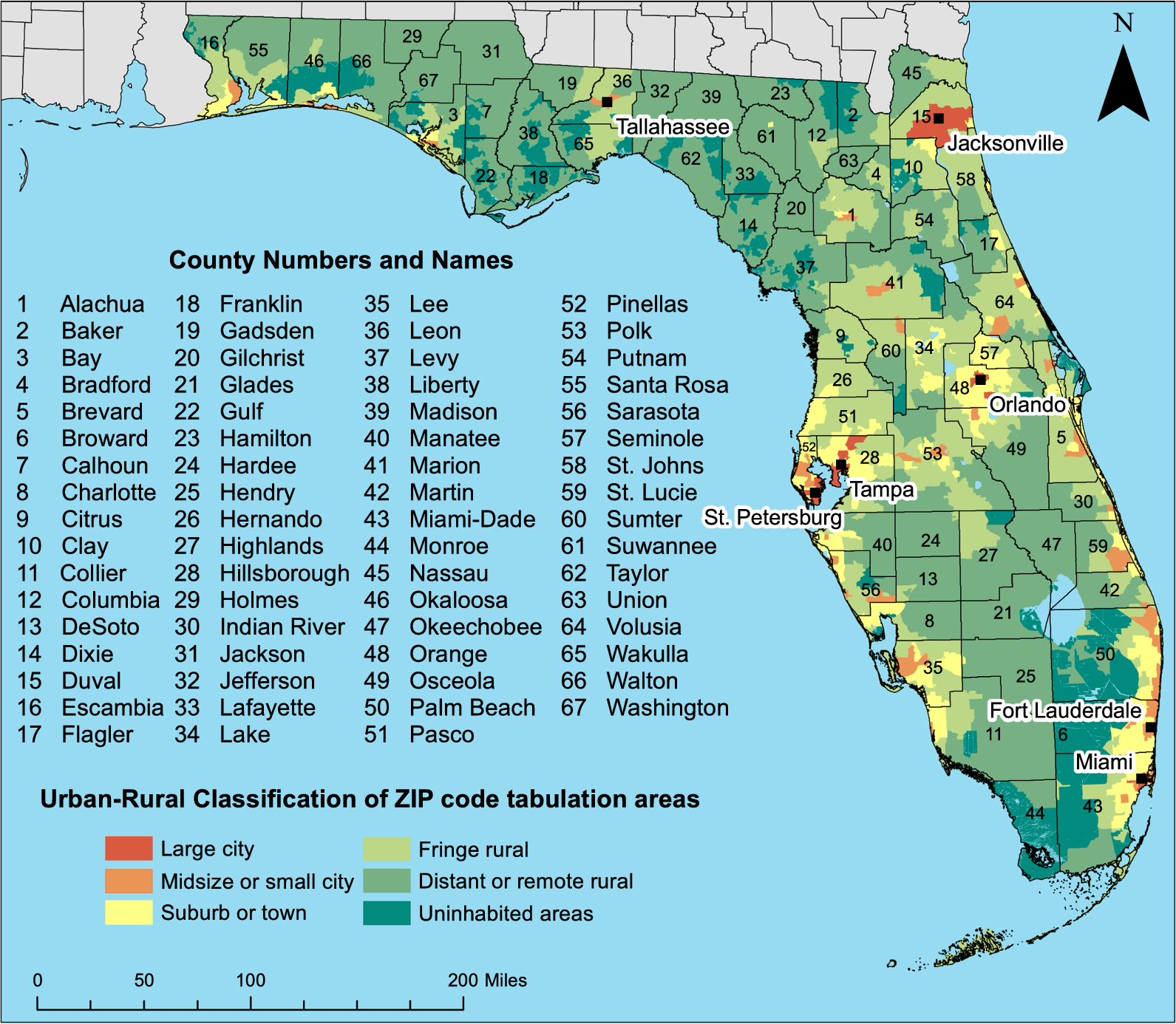
Fig. 2
Geographical representation of class map and spatial weight matrix.A The class map by Kmeans method according to the intrastate human mobility. Note: US states are divided into four groups: (1) Region 1 (\(r_1\)): 22 regions with relatively low human mobility; (2) Region 2 (\(r_2\)): 18 regions with intermediate human mobility; (3) Region 3 (\(r_3\)): 6 regions with higher human mobility; (4) Region 4 (\(r_4\)): 3 regions with the highest human mobility. B Flow matrix with nearest 8 neighbors: \(49 \times 49\) interstate interaction matrix, where each region is only connected to its closest 8 neighbors. The purple line represents neighbors of California. The color indicates the size of the element of the spatial weights. The darker the color, the larger the weight value
Following recent literature [49,50,51,52,53], we estimate model parameters by an iterative Bayesian inference algorithm [ensemble adjustment Kalman filter (EAKF)]. This method has been applied to metapopulation models and to infer epidemiological parameters for many infectious diseases successfully [50, 52, 54]. EAKF is a Monte Carlo implementation of the Bayesian update problem. It combines observations with the probability density function (prior) generated by the model simulation over time to generate a posterior estimate of the model state variables (including the variables and parameters). Therefore, we can estimate the four variables(S, E, I, A) of each region and infer six model parameters (\(R_0\), a, \(\theta\), \(\mu\), Z, D).
The spread and evolution of infectious diseases is a dynamic process, and their associated epidemiological parameters can vary over time and region. For instance, the infection period may be influenced by factors such as hospital admission policies and contact tracing. Accelerated hospital admissions or early isolation of close contacts can significantly shorten the infection period. Meanwhile, the reporting rate of the cases can be impacted by testing and record-keeping practices, which can vary across regions. Hence, we assume that the reporting rate (\(\mu _i\)) and the infection period (\(D_i\)) are subject to change with time and region, while the other four parameters are inherent properties of the virus and remain constant. In addition, to account for reporting delays in reported cases [54], we introduce a Gaussian-distributed report delay term (\(D_r\)), which varies by month. Details of model inference and initialization are provided in Supplementary materials.
Counterfactual simulationsWe delve into different counterfactual scenarios to investigate the SSE of NPIs on regional COVID-19 trajectories further and to measure intervention effects by comparing cumulative confirmed cases in different scenarios. Due to the spatial dependence among regions, the NPIs in some specific key regions may exert larger SSE \(\delta _\). Targeting these key regions and exploring the role of SSE in these specific regions on COVID-19 cases can help us maximize the impact of NPIs. To do this, we divide the US states into different groups based the intrastate human mobility, and implement different counterfactual scenarios within each group, specifically changing the intensity of different NPIs, determining the more effective regions, and restricting interstate human mobility.
Firstly, to locate appropriate intervention areas, we divide US states into four groups based on K-means clustering [55]. This algorithm, based on Euclidean distance, considers that the closer the distance between two targets, the greater the similarity. Therefore, we first define the distance between the targets. We calculate the average intensity of intrastate human mobility in each region from 6 January to 2 February. If the difference in human mobility within the two states is small, we assume that the two states are closer together. We then select the number of clusters based on the elbow method. Eventually, four different categories of regions are identified (Fig. 2A).
Table 2 The coefficients of different NPI estimates from the spatial econometric model
Comments (0)