
Remember me
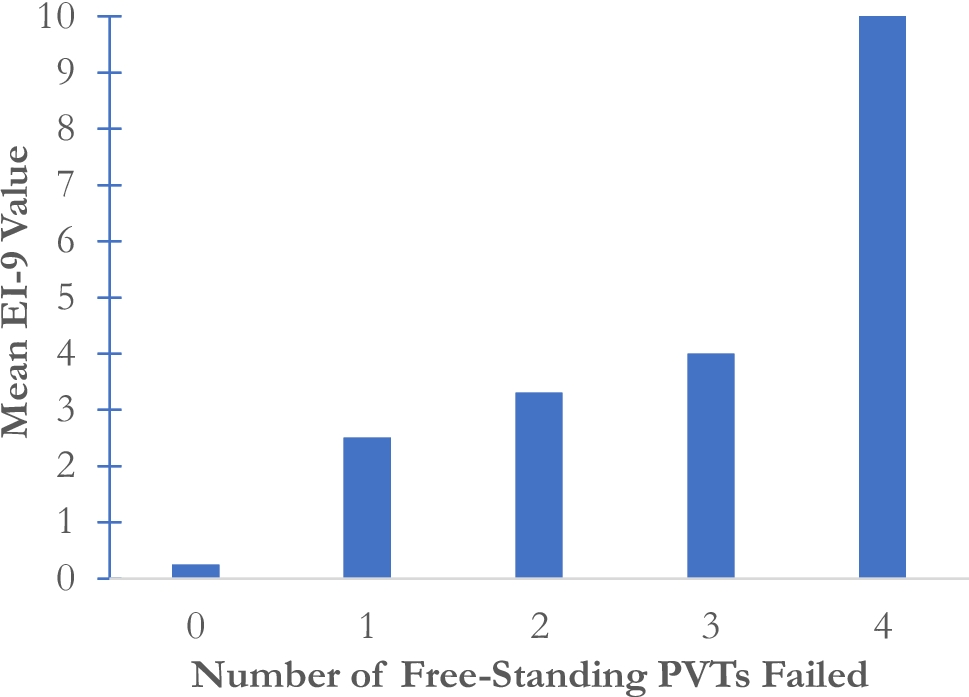
In forensic settings, mental health professionals may be called to opine on the credibility of the symptoms and/or performance presented by the defendant, and psychologists are increasingly considered one of the most important sources of information in relation to expert testimony (Melton et al., 2017). In fact, it is common for a lawsuit to involve negative impression managementFootnote 1 as a crucial consideration for litigation – and in other legal situations as well (e.g. reduce criminal responsibility, plead for incompetency to stand trial, claim disability, demand military service discharge). Accordingly, forensic psychologists provide testimony as experts at the nexus of the psycholegal question, which often includes evaluating the credibility of the self-reported symptoms and/or the cognitive deficits demonstrated by the examinee during the assessment (Woody, 2016). To this end, psychologists can rely on two types of instruments: Performance Validity Tests (PVTs) and Symptom Validity Tests (SVTs). The former are designed to assess the credibility of the evaluee’s performance on cognitive tasks (e.g., memory, attention), while the latter assess the credibility of self-reported symptoms (Larrabee, 2012; Sweet et al., 2021). Both PVTs and SVTs are essential tools in forensic evaluations, as they help identify non-credible responding, feigning, or symptom exaggeration (Bush et al., 2014; Heilbronner et al., 2009). Nevertheless, they represent only one of the possible components that should constitute a comprehensive test battery, and their results should be integrated with other instruments and methods, e.g., clinical interview, collateral information, psychometric testing, and record review (Ardolf et al., 2007; Boone, 2021).
In this regard, psychologists are increasingly being relied upon by the courts because of their unique training and skill sets germane to psychometric testing. Additionally, there are an increasing number of venues and avenues by which a psychologist might be involved in a forensic proceeding (Koponen, 2024; Sethi, 2024). This includes both criminal and civil law, question of both cognitive and psychological damages, issues of capacity and competency, fitness for duty, interdiction, and others (APA, 2013). A quick PsychINFO search about the proliferation of manuscripts on forensic topics demonstrates the increased presence of psychologists, psychological evaluations and psychological assessment instruments in court. For example, using the key terms of, “forensic psychology in legal systems,” “psychologists in criminal justice,” “international forensic psychology,” “forensic psychological testing in legal systems,” “psychological testing in criminal justice,” “international forensic psychological testing,” 120 results were found from 1937 to date. Limiting this search to the last 10 years, 45 results were found, that means that almost 40% of the articles fall in the last decade.
Ethically, testimony provided by the experts should be limited to that which is relevant to the case, within the expert’s purview, and is valid and reliable (Pomerantz, 2014). In fact, unbiased testimony is a key element in forensic contexts (VandenBos, 2015). Current legal standards (see section below “The Daubert Standards”) require psychologists to make unbiased judgments, that is, based on empirical and verifiable data. Said differently, expert psychologists called to testify have to make judgments that are based on sound scientific foundations (Ackerman & Gould, 2015). Using data or assessment methods that lack solid empirical evidence and/or ethically dubious can undermine the admissibility of expert testimony (Woody, 2016).
Complicating the development of a ubiquitous set of standards is that different jurisdictions can have different standards and requirements which are placed upon experts. Within the United States legal standards have often developed within the federal system and then trickle down to state and local jurisdictions. Federal standards were codified within the Federal Rules of Evidence (FRE; 2024). Specifically, Rule 702 states that “A witness who is qualified as an expert […] may testify in the form of an opinion or otherwise if the proponent demonstrates to the court that it is more likely than not that: […] (b) the testimony is based on sufficient facts or data; (c) the testimony is the product of reliable principles and methods; and (d) the expert’s opinion reflects a reliable application of the principles and methods to the facts of the case.” In addition, it is required that mental health professionals who qualify as experts express their opinions in the terms of their expertise, based on their specific training and degree of experience (American Psychological Association, 2002). This applies not only to forensic psychologists who are called to testify about the assessment performed, but also to researchers who are asked to express their opinion about their science.
Historical Pathway to Daubert as the Best Standard for Expert TestimonyFor years, the verdict in Frye v. United States, 54 App. D.C., 293 F. 1013 (1923) was considered the standard for admissibility of expert testimony. In Frye v. United States, the validity of the polygraphFootnote 2 was rejected because the technique did not have sufficient acceptance within the scientific community. Subsequently, the D.C. Circuit Court of Appeals ruled that the admissibility of expert testimony must be based on information that is generally accepted in the particular area at issue. There have been several criticisms of the Frye standard over the years, mainly because it prevented the use of new technologies as evidence in courts; however, it is still applied in some state courts.
Seventy years after Frye, Daubert v. Merrell Dow Pharmaceuticals, Inc., 509 U.S. 579 (1993) was heard by the United States Supreme Court, and had major implications regarding expert witness testimony. The case involved two children born with significant birth defects. It was alleged that in utero exposure to a drug used during the mother’s pregnancy was responsible for the birth defects. Both sides presented conflicting expert witness testimony. Merrell Dow Pharmaceuticals, the manufacturer of the drug, provided evidence in the form of peer-reviewed (i.e., generally accepted – meeting the Frye standard) scientific papers as evidence, showing no connection between the drug and fetal malformations. In contrast, opposing counsel presented expert opinions that included not yet published, peer-reviewed, findings. Using the Frye standard, defense counsel objected to the admissibility of the plaintiff’s evidence, arguing that the methodology had not yet been generally accepted by the scientific community. The objection was sustained, and the case remanded for appeal. Thus, the Supreme Court, referring to FRE 702, reversed the judgment and indicated the Frye principle was too conservative (i.e., excessively rigid) because it excluded evidence that is potentially valid even though it is still from emerging areas of study.
In 2015, in the APA Handbook of Forensic Psychology, Heilbrun and LaDuke stated that, while general acceptance by the scientific community is a sine qua non for the admissibility of expert testimony in criminal and civil cases, it is also true that evidence presented to the court has to be scientifically sound (i.e., testable, peer-reviewed, published, with a known – or estimable – rate of error, and with standards of reference). Said differently, the Supreme Court highlighted the need for expert testimony to be based on more solid scientific grounds.
Therefore, when it comes to error rate, it is important that the variables on which the results are based are well defined, the administration of the instruments that produced those variables is standardized, and the data are interpretable in light of established cut-offs (Rogers & Fiduccia, 2015). On this premise, the Daubert ruling emphasized the importance for experts to base their testimony on techniques and instruments with a known – or potentially known – error rate and, additionally, that this error rate be reported to the judge and jury, who would thus be able to assess the validity of the evidence. Rather, the Court noted that information about the error rates associated with a technique should be available to experts who use it so that they may take this information into account when formulating their opinion, and triers of facts can consider it when weighing such evidence.
In 1999, Kumho Tire Co, Ltd. v. Carmichael, 119 S.Ct. 1167 extended the principles expressed in Daubert to all technical and specialized information on which expert testimony might be based. In the Kumho case, a tire blowout had caused an automotive accident resulting in the death of a passenger in the vehicle and injuries to other persons. The defendant, Kumho Tire Co, Ltd., challenged the scientific nature of the testimony brought by the prosecution, which was based on an alleged manufacturing defect in the tire. The US Supreme Court, however, affirmed that the relevance and reliability of evidence should refer not only to testimony derived from science, but also to all expert testimony on the subject. In other words, the Kumho sentence greatly expanded the leeway regarding the court’s verdict. In fact, while it is true that, with Kumho Tire Co, Ltd. v. Carmichael, 119 S.Ct. 1167 (1999), expert testimony was no longer necessarily to be derived from traditional scientific methods, it is nevertheless true that the decision on the admissibility of the testimony now depended on how valid the court considered that testimony to be.
It should be noted that, in most legal procedures, both judge and jury have always been given great credit, which opened critical loopholes for subjectivity and bias. However, following Daubert, it was assumed that the potential risk of prejudices would be counterbalanced by the procedural safeguards of cross-examination and opposing expert testimony, and that judicial instructions on the standard of proof would ensure juror impartiality. However, Kovera and Levett (2015) seem to doubt that Daubert actually provided adequate assurance in this regard.
The judge’s function as a guarantor of the admissibility of expert testimony – function that so far was exerted based on the two historic verdicts (i.e., Daubert and Kumho) – was further defined by a third federal decision that, along with the first two, constitutes the so-called Daubert trilogy (see Table 1), i.e. General Electric v. Joiner, 522 U.S. 136 (1997). Robert Joiner sued the company he was employed by, General Electric, after being diagnosed with cancer, allegedly due to exposure to toxic chemicals in the transformers he worked with. Both in court and later in front of the US Supreme Court, the case was won by the defense. This case is relevant – and that is why it is part of the well-known Daubert trilogy – because on that occasion the judge was allowed to review the studies brought by the experts called to testify and expressed his judgment on them, which, in this case, disagreed with the experts’ opinions. In fact, the judge found the expert’s testimony inadmissible, despite the fact that it was based on scientific principles and valid and reliable methodology. Crucially, the Joiner case paved the way for the possibility of the judge and the court not only assessing the robustness of the methodology underlying the expert’s testimony, but also expressing their own opinions regarding the admissibility of such testimony. Said differently, this case is significant because it reinforced the role that the trial judge has as gatekeeper for the introduction of scientific or expert witness testimony, and this verdict clarified the standard of review for appellate courts. A couple of years later, in Kumho Tire Co, Ltd. v. Carmichael, the same practice that occurred in the Joiner case was confirmed. Moreover, if one were to apply the implications that this case might have in psycho-legal contexts, it could be said that Joiner emphasized that the expert should demonstrate a clear connection between data in their possession and conclusions they draw. Accordingly, Joiner addressed the degree of judicial error in its decision-making that would be required for an appellate court to overturn a trial court’s decision. Certainly, judicial decision making for admissibility of evidence requires a high level of knowledge on the part of the trier of fact (judge). However, judges differ considerably in their understanding of the scientific method in general as well as case-specific technical knowledge, thereby creating a variable degree of judicial exactitude in applying the standards for evidence.
Table 1 Overview of the three cases that constitute the so-called Daubert TrilogyIn light of what has been discussed so far, Daubert standards are in line with the current status of psychology, which increasingly requires conceptual and empirical rigor in all psychological fields, from clinical settings to academic environments. More specifically, in the forensic field, an evidence-based approach to psychological testing has become increasingly valued and indeed deemed necessary for the admissibility of expert testimony (Heilbrun, 2002; Otto & Heilbrun, 2019; American Psychological Association, 2013). Thus, the Daubert trilogy lays the foundation with respect to what is required of psychologists, when they may be called upon to testify about their work products. The methodology applied by professionals not only needs to be sound, the instruments and tests administered also need to independently meet the Daubert criteria.
Overall, the Daubert standards have significant implications for expert testimony not only regarding the admissibility of scientific evidence, but also regarding the methodologies that led to the collection of that evidence. Put differently, with the application of Daubert, it is no longer just the information per se under scrutiny, but also the method that produced the data used to formulate a particular opinion. Therefore, it is essential for lawyers, psychologists, researchers, and test developers to be familiar with the fundamental concepts underlying the scientific nature of psychological testing and the testimony that can result from these evaluation procedures.
The Daubert StandardsThe three cases that constitute the Daubert trilogy shifted the emphasis away from the ill-defined principle of “general acceptance” as the sole criterion for admissibility. In fact, the Court has clarified that “general acceptance,” however relevant, remains only one of the factors that judges may consider in determining the admissibility of expert testimony. Additionally, it should be noted that Daubert applies to federal courts through the Federal Rules of Evidence, while individual states retain discretion in their evidentiary standards. In fact, although Daubert could be considered the “gold standard” regarding the admissibility of expert witness testimony, there are still many jurisdictions in the U.S. following the Frye standard or hybrid approaches (see Melton et al., 2017). Therefore, as influential as it is, the Daubert trilogy has not rendered Frye’s general acceptance test obsolete.
Overall, the guidelines emerged from Daubert address both the theory in which experts ground their opinions and the methodology (measurement instruments and procedures, diagnostic algorithms, interpretation guidelines) they used to conduct the evaluation. Specifically, the Daubert standards state the court can consider the expert’s testimony valid if the methodology on which the testimony is based (a) has been empirically tested, (b) has been subjected to peer-review and was published in scientific journals, (c) has a known – or discoverable – error rate, (d) has established standards for controlling its use, and (e) is generally accepted within the scientific community (the Frye standard).
It should be noted that although the Daubert factors provide an overview on how to evaluate technical and scientific evidence, the admissibility of a particular method remains an evidentiary decision reserved to the judge acting as gatekeeper. Therefore, the following sections are intended to describe how IOP-29 aligns with the Daubert factors, aiming to inform psychologists, lawyers, and professionals working in forensic settings about the empirical basis of the instrument. Hence, they are not intended to replace the independent determination of admissibility by a court.
Application of the Daubert’s Standards to the IOP-29The aim of this work is to evaluate the Inventory of Problems-29 (Viglione et al., 2017) using the Daubert standards. The IOP-29 is a 29-item symptom validity test with three cognitive performance items, which takes five to ten minutes to complete. These 29 items were selected from an initial pool of 181 as the best predictors of an individual’s membership in either a group of bona fide patients or a group of feigners. In fact, the IOP-29 was developed specifically for mental health professionals to detect the exaggeration or fabrication of both cognitive and psychiatric symptoms and impairment. As a free-standing instrument, it was designed to be employed in both clinical and forensic settings and can be used alone, although the consensus within the field is that an accurate assessment of the credibility of a given clinical presentation should involve several SVTs and PVTs (Heilbronner et al., 2009; Marcopulos et al., 2024; Sherman et al., 2020; Sweet et al., 2021).
The IOP-29 produces a False Disorder Score (FDS), a continuous index that reflects the likelihood that the symptom presentation is feigned. The test manual (Viglione & Giromini, 2020) and subsequent research suggest three interpretive cut-offs: FDS ≥.30, ≥.50, and ≥.65. These thresholds were empirically derived from statistical analyses aimed at evaluating classification accuracy of the instrument in both simulation and real-world studies (cf. Research designs in IOP-29 studies), and can inform the user how to best balance sensitivity and specificity based on the context and needs. Specifically, a cut-off of.30, being more liberal, guarantees greater sensitivity (i.e., fewer false negatives), but exposes the risk of a higher number of false positives. Conversely, a cut-off of.65, being more conservative, preserves specificity (i.e., fewer false positives), at the expense of sensitivity. The intermediate cut-off of.50 is the one that the manual offers as a general benchmark and standard to use, although specific considerations may be made based on the particular assessment being conducted (e.g., in forensic evaluations, where the risk of false positives may have dramatic consequences, the cut-off score of.65 may be more definitive).
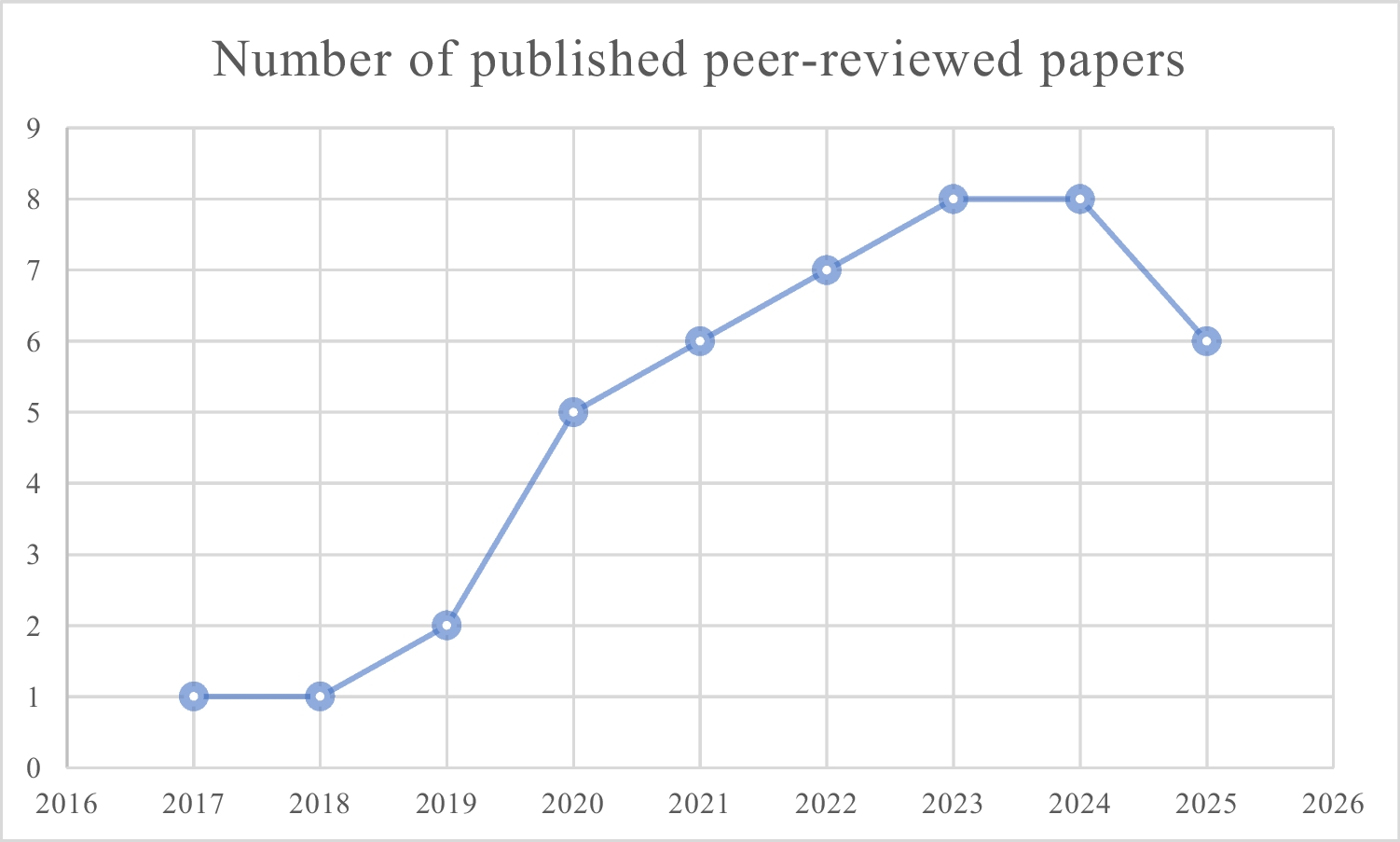
Has the IOP-29 been Tested? Brief Overview of the IOP-29The IOP-29 was originally published in 2017 (Viglione et al., 2017). While the test may be relatively new, it has enjoyed a rapidly expanding foundation of evidence-based research since its introduction (Puente-López et al., 2023a, b; Young et al., 2020). Specifically, as of November 2025, 44 articles have been published on it in peer-reviewed journals. The IOP-29 was intended to assess negative impression management and distinguish credible from non-credible symptoms presentation, across a wide range of disorders (i.e., PTSD, depression, psychosis, neuropsychological problems and combinations thereof).
The IOP-29 assesses the credibility of the symptoms presented by comparing the evaluee’s responses with response patterns observed in both honest patients and individuals who were asked to exaggerate/feign symptoms. The 29 items that comprise the test were empirically selected because they were found to be those that best distinguished real-world patients from experimental feigners (Viglione et al., 2017). Specifically, the responses to the IOP-29 are aggregated to yield a single value, namely FDS, that can be easily interpreted. In fact, the FDS ranges from 0 to 1: the higher the score, the greater the likelihood that the examinee is exaggerating or fabricating their symptoms, and vice versa, i.e., lower scores suggest a credible presentation of symptoms. In the IOP-29 Professional Manual, the authors reported that the optimal cut-off to use for considering invalid a given protocol is FDS ≥ 0.50, with this being the cut score that maximizes classification accuracy. It is important to specify that the FDS represents a probabilistic index of non-credible responding. Therefore, although.50 is the recommended cut-off score, values above and below this threshold still provide significant information about the credibility of the symptoms presented. In fact, the FDS is based on odds ratios, which allows the examiner to assess the probability that an examinee is feigning (or exaggerating) their symptoms rather than presenting them genuinely. Therefore, from a practical standpoint, it is informative to consider the FDS not as a dichotomous measure (i.e., pass/fail), but rather as a continuum. This does not negate the use of the FDS at.65 as the critical level for forensic purposes in forensic practice.
Research Designs in IOP-29 StudiesTraditionally, SVT validation studies are of two types: simulation/analog designs or real-world (criterion-groups) designs. In simulation studies, groups of experimental feigners and honest responders are created based on instructions provided by the experimenters. This ensures high experimental control and internal validity, allowing the instrument to be evaluated in terms of its ability to distinguish between two (or more) groups. However, simulation studies have the disadvantage of potentially overestimating the effect size and diagnostic accuracy of the instrument, because participants’ motivations, external incentives, and context differ substantially from real-world clinical and forensic settings. Conversely, real-world designs (e.g., known-groups from clinical, medico-legal, or forensic populations) enjoy greater ecological validity, although they often include very heterogeneous samples, which implies less control by experimenters, and are thus subject to criterion contamination. Additionally, in real-world design studies, participants are indeed real-world evaluees, but they are assigned to research groups based on criteria that can be considered arbitrary or fallacious, e.g., scores obtained in other SVTs or PVTs. However, in this way, there is no certainty that presentations classified as “credible” are actually genuine, just as one cannot be certain that presentations classified as non-credible are actually exaggerated or simulated. Consequently, the criterion used to define whether a subject is honest or not may be inaccurate, and this inevitably leads to a degree of error. In summary, while simulation studies have high internal validity (the experimenter knows with a reasonable degree of confidence who is simulating and who is not), but low external validity (the incentives in the experimental condition are rarely as “attractive” as those in real-world situations), real-world design studies have high external validity (the context in which individuals are evaluated is “real”), but low internal validity (we cannot be sure that those who are considered feigners are actually simulating, and that the so-called honest responders are actually reporting their symptoms genuinely). To help readers gain an overview of the research designs adopted in the IOP-29 validation studies, in addition to what is reported in this article, we provide a supplementary table (Table S1) reviewing all IOP-29 studies published to date. Specifically, Table S1 provides a structured summary of the 44 peer-reviewed publications examining the IOP-29, and is organized into six columns: (1) Reference, listing each published study, (2) Goals, summarizing the main research objectives, (3) Research Design, specifying the methodological approach (e.g., simulation study, real-world design), (4) Methods, describing sample characteristics, experimental conditions, and procedures, (5) Results, reporting key findings relevant to the IOP-29 (e.g., classification accuracy), (6) Comments, highlighting relevant or distinctive contributions of a study when further considerations where needed.
Testing the IOP-29The IOP-29 has been validated for a range of disorders, including depression (Bosi et al., 2022; Ilgunaite et al., 2022), psychosis (Banovic et al., 2022; Winters et al., 2020), PTSD (Carvalho et al., 2021), and neuropsychological deficits (Gegner et al., 2022; Holcomb et al., 2022). Moreover, the classification accuracy (sensitivity, specificity, proportion of the overall sample correctly classified) of the IOP-29 have been empirically tested using various research designs (e.g., between-subjects and repeated-measures, experimentally induced simulation/analogue designs, known-groups designs; Giromini & Viglione, 2022), and in different cultural/linguistic contexts (e.g., Australia, Italy, France, Portugal, UK, USA). Additionally, the IOP-29 has been translated and cross-validated in several countries (Brazil, France, Italy, Lithuania, Portugal, Romania, Slovenia).
IOP-29 Validity Studies, their Strengths and WeaknessesSeveral studies have shown that the validity of the IOP-29 is comparable to that of other widely adopted and accepted measures of symptom validity already in use. Only a few studies, however, have tested the robustness of the IOP-29 in ecologically valid setting (e.g., with real-world forensic and/or clinical samples; see Boskovic et al., 2022; Gegner et al., 2022). This lack of in vivo field studies may pose some challenges in terms of ecological validity, and generalizability of the results to the real-word population.
Moreover, only a few IOP-29 studies have examined the effects of different types of coaching. Among these studies, Gegner and colleagues (2022) evaluated the effects of warning not to exaggerate symptoms presentation on experimental feigners who were asked to feign a mild traumatic brain injury (mTBI) condition. In this study, the IOP-29, the Inventory Of Problems – Memory Module (IOP-M; Giromini et al., 2020d),Footnote 3 and the Rey Fifteen Item Test (FIT; Lezak, 1983; Rey, 1941) were administered to a large Australian community sample (N = 275). One-third of the sample (n = 93) was asked to answer honestly, the other two-thirds (n = 182) to simulate mTBI symptoms, but only half (n = 90) were instructed not to exaggerate symptoms presentation, the other half (i.e., n = 92) were not. Their results showed that such warning did not affect the results produced by the IOP-29. This may also be due to the fact that most of the IOP-29 research involve the investigation of symptoms coaching. Nevertheless, the robustness of the IOP-29 against coached malingering attempts need to be studied further.
Additionally, it should be mentioned that most studies on the IOP-29 did rely on experimental malingering designs, which are known to inflate effect sizes (Rogers & Bender, 2018). Some experts went as far as to suggest that criterion groupsFootnote 4 based on instructions provided to examinees are quasi-experiments, as the researchers only have effective control over the task description – not the actual test-taking behavior. Consequently, assigning a participant to a given condition cannot be assumed to be equivalent to that individual faithfully emulating the desired characteristics of the prototypical patient/defendant in a real-world setting (see Sherman et al., 2020; Walczyk et al., 2018; De Marchi & Balboni, 2018). Nevertheless, it should be noted that both designs offer complementary advantages and limitations for evaluating symptom validity assessments.
There is growing evidence that the instructions provided to examinees are the Achilles heel of research designs based on the experimentally induced malingering paradigm, in that it results in contaminated criterion groups. In fact, some participants assigned to honest responding fail PVTs (i.e., they fail to demonstrate true ability level; Roye et al., 2019), whereas those instructed to appear impaired produce intact profiles (i.e., they fail to malinger; Abeare et al., 2021). Thus, this type of study, although very common, has its weaknesses, and more in vivo field research on the IOP-29 is needed to establish external validity and generalizability of the results using more ecologically valid methods. One particularly relevant to studies on IOP is the sharp difference in incentive structures between academic research and medicolegal/forensic assessments. Volunteers receive minimal compensation for their research participation, whereas plaintiffs in personal injury lawsuits and criminal defendants have significantly higher motivation to succeed in avoiding detection. Case in point, a recent study reported that a notable proportion of students incentivized to do well failed PVTs (Lam et al., 2025). Taken together, the evidence substantiates long-standing concerns about the ecological validity of research based on experimental malingering designs.
IOP-29 Comparability AnalysesBack to the question of whether the IOP-29 has been tested, a study (Roma et al., 2020), using a criterion group, produced results similar to those present in the previous literature based on experimental malingering in terms of classification accuracy (sensitivity and specificity) and overall discriminant power (effect size between relevant, empirically determined criterion groups). More recently, Holcomb et al. (2022) used psychometrically defined non-credible responding real-world clinical patients, and found that the standard cut-off of FDS ≥ 0.50 offered good classification accuracy, with high levels of specificity (0.90–0.91). Their results suggest that the false positive error rate, of the IOP-29 is ≤ 10% (considering the default cut-off of FDS ≥ 0.50), which meets the threshold for clinical and forensic practice. Moreover, the authors found that when using PVTs as criterion for forming credible vs non-credible groups, the IOP-29 o
Comments (0)