
Remember me

Accurate identification of pulmonary embolism (PE) within electronic health records (EHRs) remains a central methodological challenge in thrombosis research. Across registry studies, administrative database analyses, and EHR-based investigations published, case ascertainment (how cases are defined and identified within a dataset) has emerged as a determinant of internal validity and interpretability rather than a technical afterthought, a challenge widely recognized in EHR-based phenotyping using routinely collected data.[1]
Contemporary registry analyses, such as ETNA VTE Europe[2] and RIETE,[3] depend on clearly specified exposure and outcome definitions to support meaningful inference, while nationwide administrative database studies illustrate how coding strategies and cohort definitions shape epidemiological conclusions.[4] Similarly, recent reviews of machine learning approaches for venous thromboembolism (VTE) prediction have emphasized that model performance depends on the validity of underlying EHR-derived labels.[5]
In this context, the PE-EHR+ study by Rashedi et al,[6] in this issue of the journal provides external validation of two rule-based natural language processing (NLP) algorithms for PE detection and evaluates their performance when integrated with administrative claims data.
Several recent studies in TH have relied on International Classification of Diseases (ICD) codes to define VTE and PE cohorts for analyses of incidence, treatment patterns, recurrence, and bleeding outcomes, including time trend studies, registry sampling strategies, and real-world anticoagulant effectiveness analyses.[7] [8] [9] ICD coding enables scalable and reproducible research across large datasets, yet it was designed for administrative billing rather than clinical phenotyping. Variability in coding practice, incomplete capture of secondary diagnoses, and limited clinical granularity remain recognized constraints, with important clinical detail often embedded in unstructured text rather than structured fields.[10]
Against this background, the Rashedi et al study[6] examined whether combining structured administrative data with unstructured radiology reports could improve case identification. Two previously published rule-based NLP tools were applied to radiology reports within a large tertiary health system and benchmarked against physician adjudicated chart review. When applied across all hospitalized patients, both algorithms demonstrated high sensitivity and specificity, yet positive predictive value (PPV) was approximately 60% in weighted analyses, reflecting the low prevalence of PE in the underlying hospital population (approximately 2%). Because PPV depends strongly on disease prevalence, even modest false positive rates can materially alter cohort composition and bias downstream analyses of recurrent VTE, PE-related mortality, or comparative effectiveness, a well-recognized limitation in predictive modelling using EHR data.[11]
An important methodological consideration concerns the population to which these weighted estimates apply. The authors recalibrated performance metrics using weights derived from the entire hospitalized population to reflect the true prevalence of PE. While appropriate for estimating performance in population-level EHR screening or epidemiological studies, the intended deployment population for such algorithms may be narrower, for example, patients undergoing CT imaging for suspected PE, where disease prevalence is higher, and PPV would likely increase. Clarifying the intended operational population, therefore, remains important when interpreting algorithm performance.
To address this limitation, the authors evaluated two structured refinements. Restricting the NLP application to patients with ICD discharge codes for PE substantially improved PPV but reduced sensitivity. Expanding eligibility to those with ICD codes or a present on admission (POA) indicator preserved sensitivity while maintaining high PPV, yielding the highest F1 scores. Methodologically, this reflects a simple yet robust strategy: structured administrative variables enrich the candidate population and increase the pretest probability of PE prior to interrogation of unstructured radiology text. Rather than positioning ICD coding and NLP as competing approaches, the study shows that they function more effectively in combination.
Five observations are particularly relevant ([Fig. 1]):
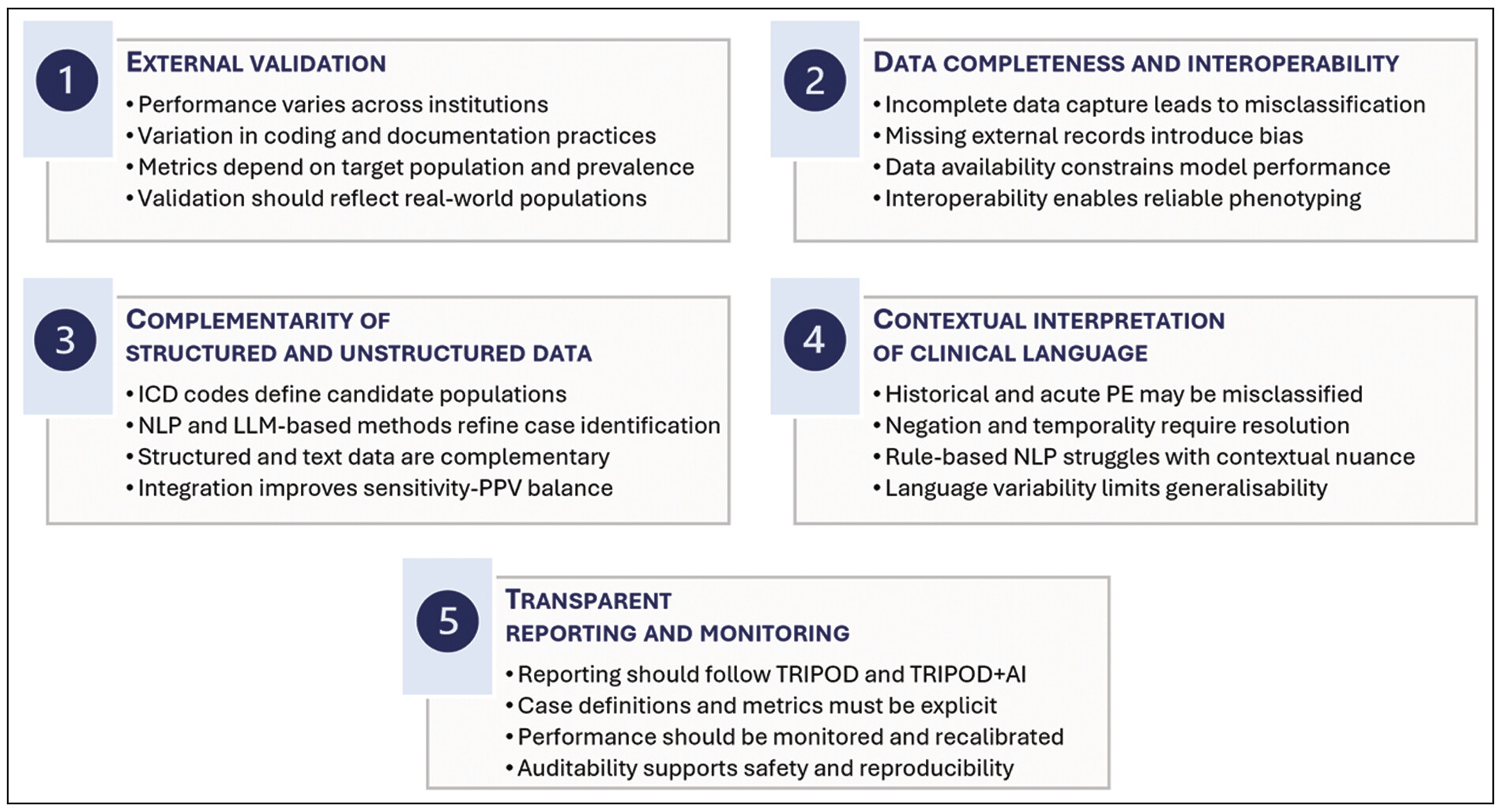 Fig. 1 Key methodological considerations for pulmonary embolism identification in electronic
health record data. Five interrelated considerations that underpin reliable phenotyping
of PE using EHRs in real-world settings: external validation, data completeness and
interoperability, integration of structured and unstructured data, contextual interpretation
of clinical language, and transparent reporting and monitoring.
Fig. 1 Key methodological considerations for pulmonary embolism identification in electronic
health record data. Five interrelated considerations that underpin reliable phenotyping
of PE using EHRs in real-world settings: external validation, data completeness and
interoperability, integration of structured and unstructured data, contextual interpretation
of clinical language, and transparent reporting and monitoring.
External validation: performance metrics derived in development cohorts often decline when applied across institutions with different documentation practices and coding behaviors. By applying weighted estimates reflecting the distribution of PE across more than 380,000 hospitalizations, the authors adjust for the enriched sampling design and estimate performance under real-world prevalence conditions.
Data completeness and interoperability: a large proportion of false negatives occurred in patients diagnosed at external institutions whose imaging reports were not available in the receiving system EHR. This highlights a structural limitation independent of algorithm design, and reflects broader infrastructural and data access challenges for clinical NLP deployment.[12] NLP performance depends on data completeness, and in multi-center thrombosis research, health information exchange remains essential for reliable phenotyping.
Complementarity of structured and unstructured data: administrative coding and NLP-based analysis of radiology reports should not be viewed as competing approaches to case identification. Instead, combining structured variables (such as ICD codes) with text-derived information (such as NLP applied to radiology reports) produced the most favorable balanced performance, illustrating the value of integrating structured and unstructured data for digital phenotyping in EHR-based research, consistent with broader computational phenotyping frameworks that emphasize multimodal data integration and increasingly support joint representation of multiple, overlapping clinical events.[13] [14] [15]
Contextual interpretation of clinical language: misclassification of historical PE and imperfect handling of negation contributed substantially to false positives, highlighting the challenges of resolving temporality, context, and uncertainty in clinical text. These issues are particularly evident in NLP-based approaches, where rule-based systems relying on predefined lexical patterns may struggle to capture contextual nuance and may not generalize well across institutions.[10]
Transparent reporting and monitoring: reporting should follow TRIPOD standards,[16] preferably the updated TRIPOD + AI[17] checklist for prediction models using regression or machine learning, to ensure reproducibility and clarity; the original TRIPOD 2015 statement remains informative for explanation and elaboration. Deployed tools require continuous monitoring for drift, calibration, and safety, supported by audit logs and structured issue triage.
At this juncture, it is reasonable to consider the potential role of large language models (LLMs). Transformer-based LLMs can capture contextual dependencies, temporality, and nuanced semantic relationships within clinical text more effectively than traditional rule-based NLP, as demonstrated in recent large-scale evaluations of medical LLMs. [18] In several clinical domains, they have improved the extraction of complex diagnoses, procedures, and outcomes from unstructured EHR narratives.[19] [20] Within thrombosis research, their application to PE detection remains limited but is likely to expand. LLMs may offer advantages in distinguishing acute from historical PE, interpreting uncertainty statements, and resolving negation without reliance on manually engineered rules. Nevertheless, the principal insight of the PE-EHR+ study remains applicable in the LLM era. Model sophistication alone does not overcome epidemiological constraints: in low-prevalence settings, indiscriminate application of any classifier will limit PPV. Structured data elements such as ICD codes and POA indicators, therefore, remain valuable filters that define a higher risk population for subsequent text-based adjudication.
Deployment of LLMs within EHR environments raises important considerations regarding data governance, reproducibility, computational infrastructure, and auditability, including the need for transparent and standardized reporting as emphasized in emerging LLM-specific reporting frameworks.[21] For studies intended to inform clinical guidelines or regulatory decisions, transparency in case definitions remains essential. Hybrid architectures that combine structured administrative data with LLM-based text interpretation may represent a logical next step, but they require careful validation, transparent reporting of appropriate performance metrics, and evaluation across institutions. As reliance on EHR and claims-based cohorts increases, methodological clarity in PE ascertainment will become increasingly important. Studies should clearly report whether case definitions rely on ICD codes alone, incorporate NLP-derived features, or use LLM-based approaches, and external validation with prevalence-adjusted performance metrics should become standard practice, in line with emerging reporting guidance for AI and LLM-based prediction models.[17] [21]
In summary, the PE-EHR+ study by Rashedi et al[6] provides a measured and methodologically rigorous contribution by showing that integration of ICD codes and POA indicators meaningfully enhances NLP-based PE detection. More broadly, it reinforces a central principle for digital phenotyping in thrombosis research: progress will depend not only on increasingly sophisticated language models, but also on careful consideration of the target population, disease prevalence, and integrated use of structured and unstructured data within sound epidemiological frameworks.
The tremendous growth in data science approaches also allows the creation of digital twins for creating pathophysiological models and appreciating the impact of treatments and management strategies.[22]
Ongoing studies will focus on the use of AI and machine learning for risk stratification and complementing risk assessment and decision making,[23] as well as digital twins for modelling risk prediction and management of atrial fibrillation and stroke.[24]
Publication HistoryReceived: 20 March 2026
Accepted: 23 March 2026
Article published online:
01 April 2026
© 2026. Thieme. All rights reserved.
Georg Thieme Verlag KG
Oswald-Hesse-Straße 50, 70469 Stuttgart, Germany
Comments (0)