The increasing availability of “big data” in healthcare presents both opportunities and challenges for health services research. With access to vast amounts of patient information and numerous variables, researchers face a dual challenge of managing this complexity while ensuring relevance and reliability of the data for specific research goals. This necessitates careful consideration in data analysis, particularly in selecting variables contributing to understanding and identifying patient risk for a given outcome.
A primary objective of health services research is to accurately identify patients at the highest risk for adverse outcomes. Linking administrative patient data with external socioeconomic datasets offers a promising strategy for achieving this goal. However, integrating these diverse data sources presents significant challenges, including compatibility issues, variation in data collection methods, and differences in data granularity. Addressing these challenges is essential to ensure the analysis is both feasible and meaningful.
The selection of appropriate methods for variable selection requires thoughtful consideration of the specific research context and goals. In this paper, we outline several variable selection techniques, highlighting their unique strengths, limitations, performance, and interpretation (Table 1). To illustrate their practical application, we present a comprehensive variable selection and evaluation framework using the LexisNexis Social Determinants of Health (SDOH) dataset. This framework demonstrates how various methods can be tailored to address the complexities of large datasets in health services research, ultimately providing more accurate and actionable insights.
1.1 Variable preprocessing: a step to eliminate redundancy and irrelevance
Variable preprocessing is a crucial step in data analysis that ensures the quality and relevance of the variables used in advanced modeling techniques. Before applying sophisticated methods, it is essential to identify and remove variables with high missingness, as they may lead to biased results or reduce the reliability of the model. Similarly, variables with high homogeneity, which show little to no variation, provide limited value in distinguishing patterns and should be excluded. Moreover, variables irrelevant to the analysis, such as indices or area-level metrics when not needed, may be filtered out. This preprocessing step enhances the efficiency of the analysis, ensuring that only meaningful and actionable variables are included in the final model.
In health services research, preprocessing can help exclude variables with extensive missing data, such as specific socioeconomic status (SES) variables like employment status or education attainment, which might otherwise skew the analysis. However, caution is needed, as missing data patterns could still provide insights, especially if they reflect underlying disparities.
1.2 Manual variable selection: a knowledge-driven approach
Manual variable selection is a process where researchers deliberately choose which variables to include in a model based on prior knowledge, theoretical understanding, or exploratory analysis. This approach ensures that the model focuses on specific, well-understood variables, making it easier to interpret and explain, particularly in fields where theoretical grounding is essential. Manual selection can be used in combination with data-driven methods, often either as an initial step or as a final refinement. When used initially, researchers select variables known to be relevant based on established theory or previous findings, ensuring that key predictors or confounders are included before applying automated techniques. Alternatively, after running a data-driven process, manual selection can refine the model by reintroducing variables that may have been excluded due to statistical insignificance but are crucial from a theoretical or practical standpoint. This hybrid approach helps balance the strengths of both manual expertise and data-driven insights.
For example, in examining racial/ethnic disparities in healthcare access, researchers might manually select SES as a known confounder even if it was deemed statistically insignificant in preliminary analyses. Including SES aligns with established literature on race and health disparities, ensuring that the model reflects essential theoretical insights.
1.3 Correlation matrix: a statistical overview
A correlation matrix is a statistical tool that displays the correlation coefficients between pairs of continuous variables in a dataset, with values ranging from − 1 to 1. Coefficients closer to 1 or -1 indicate strong positive or negative correlations, respectively. This method is particularly useful for identifying highly correlated variables, which can lead to multicollinearity—a situation where two or more variables are so strongly correlated that they provide redundant information. Multicollinearity can inflate the variance of the coefficient estimates and make the model unstable. By identifying and potentially removing correlated variables, researchers can reduce multicollinearity and improve model performance. To determine which variables are highly correlated, a threshold is often set for the correlation coefficient, commonly around 0.7 or higher. For most SDOH-health outcome analyses, a correlation coefficient of 0.5 or higher can be considered moderate to strong. These correlations suggest that the social factors (e.g., income, education, housing, access to healthcare) are influencing health outcomes in a meaningful way. Among highly correlated variables, the ones most strongly associated with the outcome variable are usually kept, while the others are removed or combined to reduce redundancy.
In health services research, correlation matrices can be instrumental in managing highly correlated SDOH variables. For example, when studying healthcare access, variables like income and poverty often correlate closely. By setting an appropriate correlation threshold and removing one of these variables or selecting the one more directly tied to the health outcome, researchers ensure a clearer model that emphasizes the most relevant predictors without redundancy.
1.4 Principal component analysis: dimensionality reduction
Principal Component Analysis (PCA) is a dimensionality reduction technique that transforms the original variables into a smaller set of uncorrelated components called principal components (Wold et al. 1987). Each component is created by combining the original variables with specific weights or coefficients in a linear relationship without considering an outcome variable. PCAs are ordered by the amount of “variance” they explain in the data. The first principal component captures the largest amount of variance in the data. Each subsequent principal component captures the next highest amount of variance remaining in the data after the previous components have been extracted. The first few principal components typically capture most of the variability in the data, allowing researchers to reduce the number of variables without losing much information. By focusing on the principal components, PCAs can help reduce noise in the data, potentially improving model performance.
In health services research, PCA is often used to combine multiple related SDOH variables into a single composite deprivation index. For instance, unemployment, income, and education related variables can be reduced to fewer components, making it easier to analyze how general SES impacts health outcomes across various populations without an overwhelming number of individual variables.
1.5 Classification and regression trees: a decision-making tool
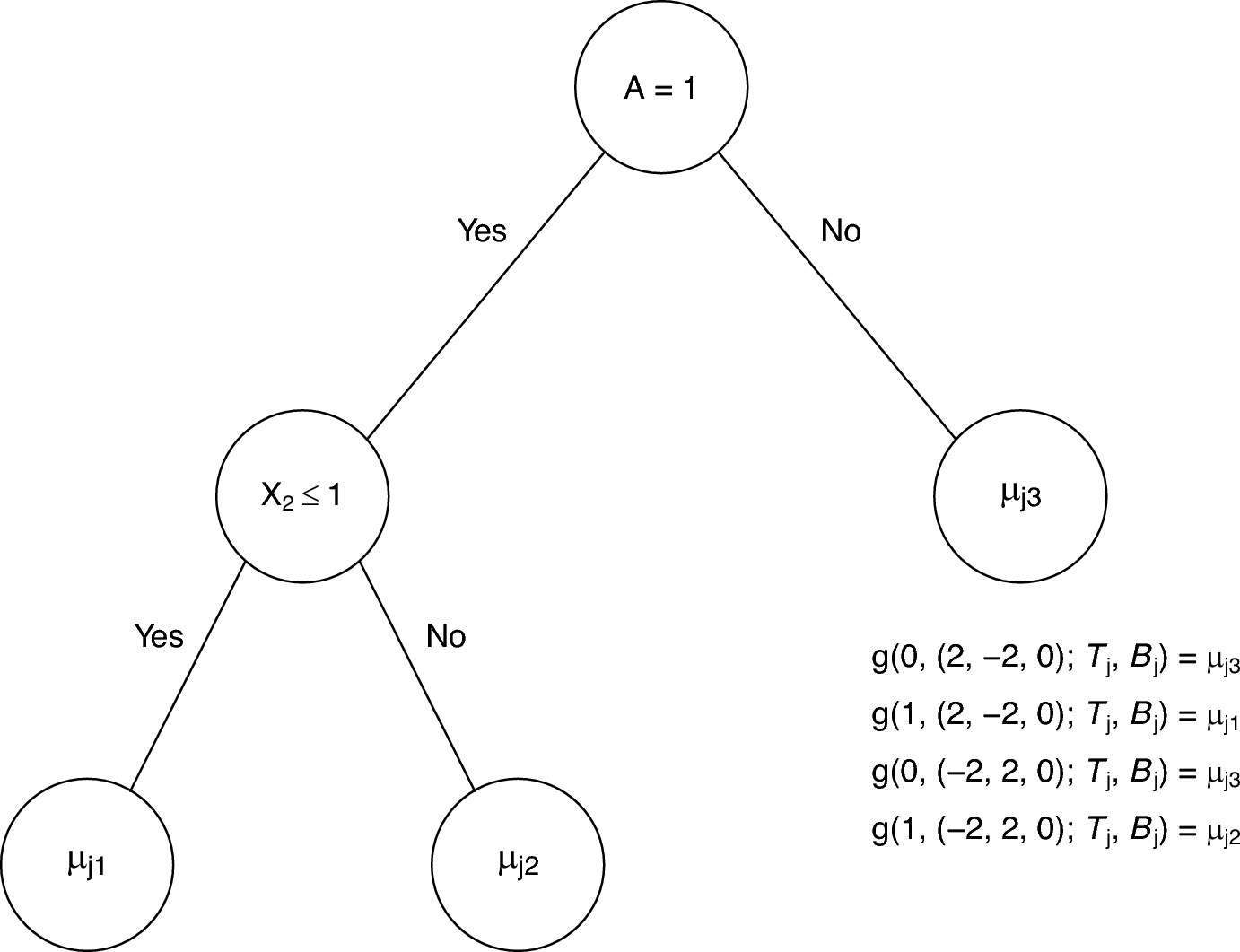
Classification and Regression Trees (CART) is a decision tree algorithm for classification and regression tasks (Breiman 1984). It works by recursively splitting the data into subsets based on the value of the input features to create homogeneous groups for the target variable. The resulting model is easy to interpret as it is represented as a tree structure, where each node represents a decision based on an input feature, and each branch represents the outcome of that decision.
In health services research, CART is not ideal for variable selection purposes; however, it can be applied to phenotype health outcomes by identifying combinations of individual or contextual characteristics linked to these outcomes (Dong et al. 2022). By examining these phenotype, researchers can better target interventions for specific patients or communities at higher risk due to the unique combinations of factors identified by the CART model.
1.6 Random forest: a robust ensemble method
Random Forest is an ensemble learning method that builds multiple classification and regression trees (using a technique called “bagging”) and combines their outputs to produce a more accurate and stable prediction (Breiman 2001). Each tree is trained on a random subset of the data and a random subset of the features, which helps to reduce overfitting and improve generalization. By averaging the predictions of multiple trees, Random Forest reduces the variance and increases the model’s predictive accuracy. Additionally, Random Forest measures feature importance, ranking variables based on their contribution to the model’s predictions.
In health services research, Random Forest and its derived models can be particularly useful for identifying the most impactful predictors of health outcomes by ranking SDOH variables, such as income, insurance status, and access to healthcare facilities. However, care must be taken when interpreting results, as correlated variables (e.g., income and poverty) may both appear important, potentially obscuring which factor more directly impacts health outcomes for underserved populations.
1.7 Stepwise variable selection: an iterative approach
Stepwise selection is a method of iteratively adding or removing variables from a linear or logistic regression model based on specific criteria, such as p-values, information criteria (e.g., Akaike Information Criterion and Bayesian Information Criterion), and coefficient of determination (R (Breiman 1984) (Chatterjee et al. 1986). The process can be performed in a forward (adding variables) or backward (removing variables) manner or as a combination of both (bidirectional). The method is easy to implement and understand, making it a popular choice for initial model building. Stepwise selection focuses on including statistically significant variables, potentially leading to a more parsimonious model.
In health services research, stepwise selection is valuable when identifying which SDOH factors, such as transportation access and insurance status, significantly predict healthcare access or cancer screening rates after adjusting for other covariates. By focusing on statistically significant predictors, this method can create concise models that highlight key barriers or facilitators of healthcare access, ultimately informing targeted interventions for underserved populations.
1.8 LASSO: a regularized approach to efficient variable selection
LASSO (Least Absolute Shrinkage and Selection Operator) is a regularization technique that improves variable selection by applying a penalty to the coefficients of less important predictors, forcing them to shrink toward zero (Tibshirani 1996). This results in a sparse model where only the most relevant variables remain. LASSO is especially effective in high-dimensional datasets, common in health services research, where numerous predictors, such as SDOH, may influence healthcare outcomes like access and cancer screening rates. By reducing the impact of irrelevant variables and preventing overfitting, LASSO helps create more accurate and generalizable models.
In comparison to traditional variable selection methods, LASSO offers several advantages, including greater efficiency and better predictive accuracy. It is particularly well-suited for situations where the number of variables is large relative to the sample size, ensuring that only the most significant predictors are retained. LASSO’s ability to handle multicollinearity and select important features simultaneously makes it a powerful tool for identifying key factors influencing health outcomes, ultimately leading to more reliable models for informing targeted interventions.
Table 1 Overview of variable selection methods1.9 Evaluation metrics for model performance
In health services research, selecting the most appropriate model evaluation metric is crucial for assessing the performance of machine learning models. Different types of models, including classification, regression, and tree-based models, require different evaluation approaches based on the dependent/outcome variable used to measure the risk. Tree-based models, such as random forests or CART, can be applied to either regression or classification tasks, and the evaluation metrics should be selected accordingly. For classification models, metrics like accuracy, precision, recall, and F1 score are commonly used, while for regression models, mean squared error (MSE) or root mean squared error (RMSE) are typically employed to assess prediction accuracy. For tree-based models, regardless of classification or regression, AUC and mean decrease in accuracy (MDA) can also be used to evaluate model discrimination and variable importance. LASSO, used for both feature selection and regularization, is commonly applied in both regression and classification tasks, and its performance is evaluated using metrics like MSE or cross-validation. The choice of evaluation metric impacts the interpretability, robustness, and utility of the model, particularly in healthcare applications where real-world implications are critical. Table 2 summarizes the key metrics and highlights their applicability to different types of models, helping guide the selection of the most relevant metric based on the specific goals of a given study.
PCA, unlike other methods, does not involve the outcome variable and is used to reduce dimensionality by transforming features into uncorrelated components. Its performance is evaluated based on how well the subsequent regression or classification model performs after dimensionality reduction, focusing on maintaining predictive power with fewer variables.
Table 2 Summary of accuracy metrics and their applicability to model evaluation

Comments (0)