
Remember me
The technology of music voice recognition holds extensive application potential not only in areas such as music information retrieval, music education, and digital entertainment but also plays a crucial role in the development of intelligent voice assistants and accessibility technologies. With continuous advancements in artificial intelligence and machine learning, music voice recognition can offer users more accurate music search and recommendation systems, as well as support in music creation and learning. However, the complexity of music voice recognition far surpasses that of general voice recognition due to the need for multi-dimensional analysis, including pitch, rhythm, and timbre. Therefore, in-depth research into music voice recognition is essential, not only to enhance the accuracy of current technologies but also to foster innovation and development in related fields.
Traditional methods for music voice recognition primarily involve symbolic AI and knowledge representation. Among these, expert systems were early technologies that relied on predefined rules and knowledge bases to process musical information. For instance, some systems perform music analysis using rules based on music theory (Exposito et al., 2006), while others employ expert systems for automated score analysis (Betancourt et al., 2018). Another approach is rule-based systems, which utilize detailed music rules for recognition and parsing, such as systems based on pitch and rhythm rules (Oramas et al., 2015) or systems combining note and rhythm pattern rules (Liu and Fung, 2000). Additionally, gradient-based methods, as a more recent technology, enhance the recognition process through optimization algorithms and gradient descent, including gradient optimization methods using convolutional neural networks (Costa et al., 2017) and advanced deep learning algorithms (Hongdan et al., 2022). These methods are theoretically robust and interpretable, enabling them to manage complex music patterns and rules to a certain extent. However, they often struggle with adaptability to complex musical variations, particularly when dealing with non-standard music data or rapidly changing musical features, which can lead to reduced recognition accuracy.
To overcome the limitations of traditional algorithms in handling complex music data, data-driven and machine learning algorithms have increasingly been applied to music voice recognition. These methods mainly include decision trees, random forests, and multi-layer perceptrons (MLPs). The decision tree algorithm classifies and predicts music data by creating a tree-like model that recursively splits the data into different categories, clearly illustrating the relationships between features (Lavner and Ruinskiy, 2009). Another commonly used method is random forests, which enhance classification accuracy by combining multiple decision trees. Each tree is trained on a random subset of the data and features, and the final prediction is determined by a vote among these trees, effectively reducing overfitting and increasing model stability (Thambi et al., 2014). Additionally, multi-layer perceptrons (MLPs), a deep learning approach, learn complex music features through a multi-layer neural network structure. Each layer's neurons transform the input data using nonlinear activation functions, enabling the model to capture high-level features and thus improve recognition accuracy (Ajmera et al., 2003). While these methods offer significant flexibility and robustness in handling complex music features and patterns, they also face challenges related to the high computational complexity of large-scale data and high-dimensional features, which can lead to prolonged training times and considerable computational resource demands.
As a solution to the limitations of traditional statistical and machine learning algorithms in handling complex music features, deep learning algorithms have become increasingly dominant in music voice recognition. These methods primarily include Convolutional Neural Networks (CNNs), Reinforcement Learning, Transformers, and Attention Mechanisms. Convolutional Neural Networks (CNNs) effectively extract spatial and temporal features from music signals through multiple layers of convolution and pooling operations, demonstrating superior performance in audio classification and feature extraction tasks (Hema and Marquez, 2023). Reinforcement Learning optimizes models through interactions with the environment, enabling adaptive learning and improvement of strategies, thus exhibiting strong self-learning capabilities in music generation and real-time adjustment tasks (Chen et al., 2023). Transformer models, which use self-attention mechanisms to model input sequences, capture long-range dependencies and have significant advantages in modeling and generating music sequences (Wen and Zhu, 2022). Attention Mechanisms dynamically adjust the weights of input data, enhancing the ability to capture important features and have achieved notable success in music translation and generation tasks (Li et al., 2021). While these methods offer powerful feature learning and modeling capabilities that significantly improve recognition and generation accuracy, they come with high computational resource demands, lengthy training times, and increased model complexity, which can substantially raise computational costs and training challenges, especially when handling large-scale datasets.
To address the high computational resource demands, extended training times, and model complexity associated with these methods for handling complex music features, we propose a novel solution: MusicARLtrans Net. This multi-modal intelligent interactive music education system is designed to overcome the limitations of traditional deep learning methods through reinforcement learning. MusicARLtrans Net combines reinforcement learning with multi-modal inputs, dynamically adjusting and optimizing the music learning process through interactions between intelligent agents and users. The motivation behind this approach is to enhance the personalization and interactivity of music education while effectively reducing reliance on computational resources. By leveraging reinforcement learning, the system can adaptively adjust teaching strategies and provide personalized feedback, thereby improving the effectiveness and efficiency of music education. Additionally, the use of multi-modal inputs allows the system to integrate audio, visual, and textual data, making it more comprehensive and precise when handling complex music data. Through this approach, we aim to achieve efficient learning while reducing the computational complexity and time consumption associated with traditional methods.
• MusicARLtrans Net introduces a novel combination of reinforcement learning and multi-modal inputs, innovatively applying an intelligent agent system to music education. By leveraging adaptive learning and interactive optimization, the system enhances educational outcomes.
• The system features multi-scenario adaptability, efficiently handling audio, visual, and textual data. It achieves personalization and versatility in music education, making it suitable for various learning environments and needs.
• Experiments show that MusicARLtrans Net outperforms traditional methods in music learning tasks, significantly improving learning efficiency and accuracy while reducing computational resource demands.
2 Related work 2.1 Speech recognitionThe development of speech recognition technology has evolved over several decades, transitioning from early rule-based systems to modern deep learning models through multiple pivotal stages. Initially, speech recognition systems relied on expert systems and rule-based approaches, which typically featured limited vocabularies and lower accuracy. However, the introduction of statistical learning methods, particularly the application of Hidden Markov Models (HMMs) and Gaussian Mixture Models (GMMs), marked significant advancements in the 1980s and 1990s. HMM-GMM models effectively captured the temporal characteristics of speech, greatly enhancing recognition accuracy (Wang et al., 2019b). As the 21st century unfolded, the rise of machine learning, particularly deep learning, further accelerated the progress of speech recognition technology. Models based on Deep Neural Networks (DNNs), Convolutional Neural Networks (CNNs), and Long Short-Term Memory Networks (LSTMs) have demonstrated remarkable performance in speech recognition tasks. These deep learning models can automatically extract features from speech signals, significantly reducing the need for manual feature engineering and improving the accuracy and robustness of speech recognition systems (Lin et al., 2024b). In recent years, end-to-end speech recognition models, such as Deep Speech and Transformer-based architectures like Google's WaveNet and OpenAI's Whisper, have further streamlined the speech recognition process while achieving notable improvements in system performance. These models integrate all components of speech recognition into a single neural network, simplifying the architecture and enhancing overall efficiency (Lin et al., 2024a). Moreover, the application scope of speech recognition technology has expanded considerably—from early implementations in telephone customer service systems and voice assistants to today's smart homes, automotive voice control systems, and healthcare monitoring devices. Speech recognition technology holds immense potential, particularly in areas such as multilingual and dialect recognition, robustness in noisy environments, and real-time speech translation. As more advanced deep learning algorithms and larger datasets become available, speech recognition technology is poised to deliver more natural, precise, and versatile applications.
2.2 Robotic visionRobotic vision is a pivotal research area within artificial intelligence and robotics, focused on equipping robots with the ability to comprehend and interpret visual information. The evolution of robotic vision has transitioned from traditional image processing and computer vision techniques to modern deep learning methods, progressing through several significant stages. Early robotic vision systems primarily relied on classical image processing techniques, such as edge detection, shape recognition, and feature extraction. While these methods were somewhat effective for simple visual tasks, they often struggled in complex environments (Wang et al., 2016). With the dawn of the 21st century, advancements in computing power and the accumulation of big data catalyzed significant breakthroughs in robotic vision technology, particularly through the adoption of machine learning and deep learning techniques. Convolutional Neural Networks (CNNs) have become central to this field, as they can automatically extract multi-level features from images through multiple layers of convolution and pooling operations. This approach has greatly enhanced performance in image classification, object detection, and semantic segmentation. Notable deep learning models, such as AlexNet, VGGNet, ResNet, and YOLO, have propelled robotic vision into a new era, demonstrating exceptional performance on large datasets like ImageNet (Hong et al., 2024). Beyond the understanding of static images, robotic vision must also process information from dynamic scenes, requiring technologies like video analysis and 3D reconstruction. Optical flow methods and object tracking algorithms analyze motion information in videos, while structured light, stereo vision, and SLAM (Simultaneous Localization and Mapping) technologies are employed to construct 3D models of the environment. The integration of these technologies enables robots to navigate, recognize objects, and interact with humans in complex and dynamic settings. In recent years, the integration of multimodal information in robotic vision has gained increasing attention. By combining visual, auditory, and tactile modalities, this approach enhances a robot's ability to understand its environment and execute tasks more effectively. As more advanced deep learning algorithms and sensor technologies continue to develop, robotic vision is expected to achieve even greater precision, robustness, and real-time performance. These advancements will drive extensive applications across various sectors, including manufacturing, service industries, healthcare, and beyond (Fishel and Loeb, 2012).
2.3 Reinforcement learningReinforcement Learning (RL) is a machine learning approach that enables agents to learn optimal actions within an environment by maximizing cumulative rewards through a trial-and-error process. The theoretical underpinnings of RL are rooted in Markov Decision Processes (MDP) and dynamic programming. However, significant advancements in computational power and the integration of deep learning have propelled RL to new heights, enabling its application across a wide range of practical domains. In the realm of gaming, RL has demonstrated remarkable potential. A notable example is DeepMind's AlphaGo, which defeated the world champion in Go using deep reinforcement learning, marking a significant milestone in the field. This achievement highlighted RL's potential in mastering complex strategic games. Building on this success, AlphaZero further showcased RL's generalization capabilities by combining self-play with deep neural networks, excelling not only in Go but also in chess and shogi (Wang et al., 2019a). In robotics, RL has proven effective in learning optimal control strategies for robots tasked with complex operations. Traditional robot control methods often rely on predefined rules and models, whereas RL enables robots to autonomously learn optimal action strategies through interaction with their environment. This approach has been widely applied in areas such as robotic arm manipulation, autonomous drone flight, and path planning for self-driving cars. The integration of deep reinforcement learning allows robots to master complex control strategies within high-dimensional, continuous action spaces (Oudeyer and Kaplan, 2007). The financial sector represents another significant application area for RL. By modeling financial environments such as stock markets, RL assists in designing and optimizing trading strategies, asset allocation, and risk management. RL algorithms learn market dynamics and adapt autonomously to varying market conditions, enhancing the accuracy and profitability of investment decisions. In natural language processing (NLP) and dialogue systems, RL is employed to optimize dialogue strategies and generate natural language responses. For instance, RL can empower chatbots to learn how to guide users through conversations, offer personalized recommendations, and improve overall user satisfaction. Additionally, RL is leveraged to optimize advertising strategies by dynamically adjusting ad content and timing in real-time, thereby maximizing user click-through rates and conversion rates (Ai et al., 2023).
3 Methodology 3.1 Overview of our networkOur approach centers on adapting the ALBEF (Align Before Fuse) multimodal architecture to better cater to the specific needs of music education through voice interactions. Traditionally, ALBEF fuses visual and textual modalities to enable a comprehensive understanding of inputs. In our system, we replace the visual editor with an audio editor to align with the primary task of speech recognition. This adaptation allows us to focus on enhancing audio processing capabilities, making the system more effective for music education.
A key innovation in our approach is the development of a novel Speech-to-Text (STT) model specifically tailored for the music education domain. This model integrates a new Acoustic Model (AM) and Language Model (LM). The AM is designed to capture the nuances of musical terminology and speech patterns relevant to music education, while the LM facilitates accurate transcription of domain-specific language. By combining these models, we significantly improve the system's ability to transcribe and interpret user inputs with precision. Furthermore, to align with our audio editor, we implemented a refined Transformer-based text editor. This editor reduces the original 6-layer Transformer structure to a more efficient 3-layer configuration, enhancing processing speed while maintaining high effectiveness.
The implementation of our music education system involves several key steps, each designed to optimize the integration of the audio editor, STT model, and refined text editor, with reinforcement learning enhancing the overall performance. 1. Audio editor and STT model development: The first step involves developing and training the Speech-to-Text model. The Acoustic Model (AM) is meticulously designed to process and interpret musical terms and speech patterns. This model is trained using a comprehensive dataset that includes various musical and educational audio samples, ensuring it captures the specific characteristics of the music domain. Concurrently, the Language Model (LM) is developed to understand and generate domain-specific phrases, improving the accuracy of text transcriptions related to music education. The STT model is then integrated into the audio editor, which is tailored to handle the complexities of music-related speech. 2. Adaptation of text editor: The text editor, essential for processing the transcribed text from the STT model, is modified by reducing the Transformer architecture from six layers to three layers. This modification enhances the efficiency of the model, making it faster while maintaining its ability to handle textual data effectively. The alignment between the audio editor and the text editor is fine-tuned to ensure that the transcriptions and text processing are coherent and contextually accurate. This alignment is crucial for the system to provide relevant and timely educational content. 3. Integration of reinforcement learning: Reinforcement learning is introduced to optimize the agent's performance continually. The RL framework enables the agent to learn from interactions with users, adjusting its responses and teaching strategies based on feedback. The agent receives rewards based on its effectiveness in providing personalized and accurate music education, allowing it to refine its approach over time. This iterative learning process ensures that the system adapts to user needs and improves its teaching methods. 4. System evaluation: Finally, the integrated system is evaluated on several metrics, including transcription accuracy, alignment between audio and text, and overall effectiveness in delivering educational content. User feedback is collected to assess satisfaction and identify areas for improvement. This comprehensive evaluation ensures that the system meets the desired educational objectives and provides a valuable tool for interactive music education.
3.2 Audio editor and STT modelIn this article, the audio editor of the multimodal interactive music education system consists of three main components: a strategy-based acoustic model (AM), a melody model based on recurrent neural networks (RNN), and a reward-based action decoder (as is shown in Figure 1). Specifically, we developed two architectures: one that uses note sequences as the output units for the acoustic model and melody model, and another that employs rhythmic units. The rhythmic unit model has advantages in real-time interactive sessions, as the acoustic model can operate effectively at a lower temporal resolution. The following sections will provide a comprehensive and detailed description of each component of the system.
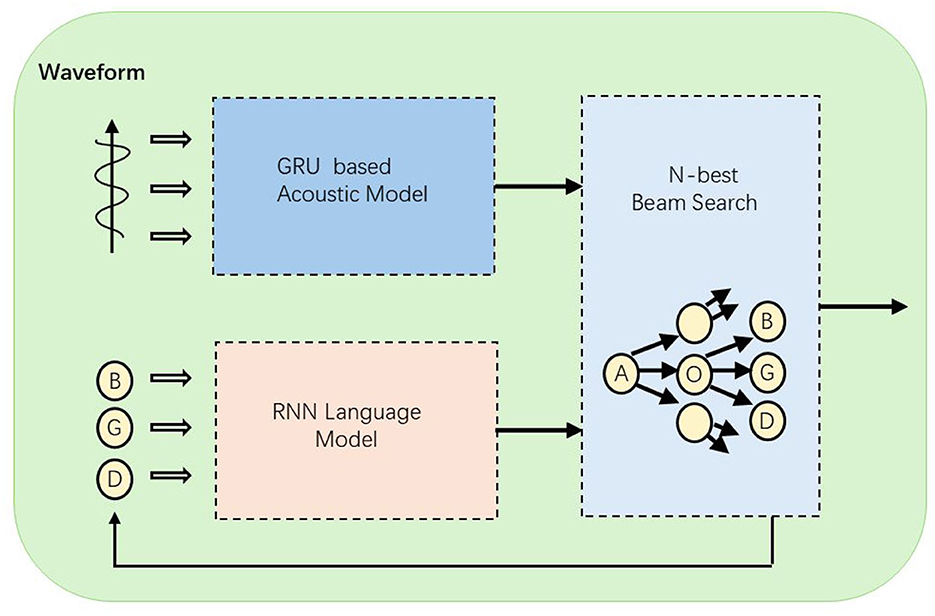
Figure 1. The structure of the Speech-to-Text model. After the audio waveform is input, acoustic modeling is first performed through the GRU model, and then combined with the RNN language model, and the final result is output after N-best beam search.
3.2.1 Acoustic modelThe MusicARLtrans Net's architecture is depicted in Figure 2 and includes two 2D convolutional layers, six recurrent layers, and one densely connected layer. The network outputs labels that identify musical elements such as notes, chords, and rhythmic patterns, and it employs a training regime based on reinforcement learning loss. The network's input feeds into the convolutional layers, which process three sets of 2D feature maps generated from the mel spectrogram and its derivatives. These feature maps span across time and frequency dimensions. The architecture utilizes a 5 × 5 filter size for the convolutional layers, adhering to standards from prior research. By halving the dimensions of the input frames, these layers not only boost the system's efficiency in recognizing musical features but also simplify the decoding stage by easing the computational load on the recurrent layers.
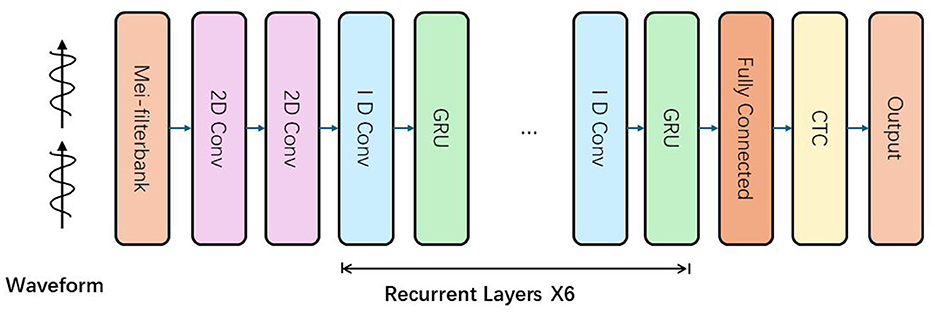
Figure 2. The structure of acoustic model. The input waveform signal is first processed by the Mel filter to generate Mel frequency cepstral coefficients (MFCCs) or other features, and then passes through multiple convolutional layers (2D convolution and 1D convolution) to extract features. After the convolutional layer, the data is processed in sequence through multiple recurrent layers (GRU layers), which are repeated six times. Finally, after being processed by the fully connected layer, the data enters the CTC (connected temporal classification) layer, which is used to process the sequence-to-sequence mapping and finally output the recognition result.
Our model is equipped with six recurrent layers, each integrating a 1-D convolutional component and a music-specific recurrent module (M-CU). This unit is designed to incorporate a state feedback mechanism, processing music vectors zt∈ℝ2xin. The computation for output qt∈ℝM and state vector st∈ℝM is detailed in Equation 1. Drawing inspiration from pitch pooling techniques in QRNN, our approach adjusts the input gate rt, as formulated in Equation 2. We refer to this model variation as “m-GRU" (shown in Figure 3). Experimental results show that incorporating a pitch control input into m-GRU not only enhances its training stability but also significantly lowers the error rate in predictions. Preliminary tests on the activation function tanh have demonstrated that its careful adjustment, as per Equation 2, substantially enhances convergence.
m-GRU: y˜t=A1zt+b1, ut=ϕ(A2zt+b2), athbfvt=ϕ(A3zt+b3), st=ut°st−1+(1−ut)°y˜t, qt=vt°tanh(st)+(1−vt)°y˜t (1) Advanced-m- GRU: y^t=tanh(A4zt+b4), pt=σ(A5zt+b5), rt=σ(A6zt+b6), wt=σ(A7zt+b7), st=pt ° st−1+rt°y^t, qt=wt°st+(1−wt)°y^t (2)
Figure 3. The structure of GRU Model.
In this model, the parameters A1,A2,A3,A4,A5,A6,A7∈ℝM×hin and b1,b2,b3,b4,b5,b6,b7∈ℝM are trainable. Solo training of i-m-GRU yields a prediction accuracy surpassing that of conventional LSTM networks. To mitigate overfitting, we incorporate a deep 1−D convolutional layer at each recurrent layer's entrance, elevating the parameter count by O(k×hin), where k denotes the convolution's filter width. The 1−D convolutional layers, possessing fewer parameters than the recurrent layers, enhance the model's efficiency. The insertion of these 1−D convolutional layers between recurrent stages results in notable enhancements in model performance.
Processing across multiple time steps transforms the operation from matrix-vector to matrix-matrix multiplication. By utilizing the same weight matrix across K time steps and retrieving it from DRAM just once, both execution time and power consumption are considerably reduced. This process, detailed in Formula 3, involves K steps of parallelization.
[y1y2…yKp1p2…pKr1r2…rKq1q2…qK]=[AyApArAq][v1v2…vK]The Speech-to-Text (STT) model is an essential component of the MusicARLtrans-Net system, responsible for accurately transcribing user voice commands into text that the system can process and respond to. The choice of STT model significantly influences the overall performance of MusicARLtrans-Net, particularly in terms of accuracy, responsiveness, and adaptability. The accuracy of the STT model is crucial, as it directly impacts the system's ability to correctly interpret user commands. High transcription accuracy ensures that the user's intentions are accurately captured and processed, leading to appropriate system responses. Conversely, lower accuracy could result in misunderstandings, causing errors in command execution and ultimately diminishing the effectiveness of the interactive learning experience. Another critical factor is the responsiveness of the STT model, which affects how quickly the system can process and act upon user commands. A model with higher latency may introduce delays in the system's response, disrupting the flow of interaction and potentially frustrating users. Therefore, selecting a model that provides a good balance between accuracy and speed is vital for maintaining a seamless and engaging learning experience. Additionally, the model's ability to handle specialized musical terminology is essential. General STT models might struggle with the specific vocabulary related to music theory and practice, leading to transcription errors that can affect the overall integration of multimodal data within the system. By carefully choosing or developing an STT model tailored to the domain of music education, we can enhance the precision, responsiveness, and overall effectiveness of MusicARLtrans-Net.
3.2.2 Language modelThe MusicARLtrans Net, characterized-based, outperforms conventional statistical approaches in music education systems. When the audio module (AM) outputs musical notes, utilizing a note-level language model (NLM) reduces error rates (ER). The NLM's design, limited to a specific set of musical notes, simplifies the input and output configurations while effectively handling issues related to out-of-vocabulary (OOV) notes. Rather than employing a segment-level language model, which struggles with OOV issues due to its larger parameter size, our approach integrates a hierarchical note-level language model (HNLM) to boost performance. The HNLM comprises two RNN units: one aligned with the musical time clock and another operating in sync with the note clock, enhancing efficiency. For decoding, we use a language model (LM) that operates within a beam search framework, adapting to various beam sizes, from 32 to 128, enhancing the responsiveness of the system. This setup allows multi-stream parallel processing, which enables simultaneous processing of multiple sequences, contrasting the sequential sample generation in traditional AM RNN systems. This capability allows traditional RNN structures, including LSTM and GRU, to be effectively incorporated into the LM architecture of MusicARLtrans Net during beam search decoding, with GRU models being particularly advantageous due to their reduced memory usage and fewer state requirements compared to LSTM models.
In addition to traditional models, we have developed an audio sequence recognition (ASR) model based on note sequences, which reduces complexity by lowering the frame rate. This model incorporates common musical elements like notes, chords, and rhythmic patterns and typically ranges from 500 to 1,000 sequences. By focusing on sub-notes and chord patterns, the note sequence model circumvents the out-of-vocabulary (OOV) challenge. The language model (LM) for note sequences tends to outperform the note-level language model (NLM) as it captures longer musical dependencies and includes multiple musical elements within each sequence. This model's strength lies in its reduced complexity, allowing the audio module (AM) to process at reduced speeds compared to models focusing on individual notes. Downsampling is applied not only in the convolutional layers but also in the recurrent layers to optimize processing. Nevertheless, the training demands of the note sequence model, particularly the audio module, escalate due to a greater number of labels required.
3.2.3 DecoderDuring the decoding phase, our goal is to identify the optimal sequence of musical elements z that maximizes the objective function R(z) based on input features a1:8. This process involves synthesizing the outputs from both the Audio Processing Module (APM) SAPM and the Harmonic Sequence Model (HSM) SHSM, as described below:
R1(z)=ϕ·log(SAPM(z|a1:θ)) R2(z)=γ·log(SHSM(z))+δ·|z|Here, z represents the sequence of musical elements, such as notes or chords. R1(z) evaluates the log-probability of the sequence given the audio features, weighted by a factor ϕ. R2(z) includes the log-probability from the Harmonic Sequence Model, weighted by γ, and a length penalty term proportional to the sequence length, weighted by δ.
Labels can consist of either a single note or a sequence of notes. We employ a beam search algorithm for incremental music recognition. The complexity involved in decoding sequences using RNN-based models scales with the product of beam width, sequence length, and the total number of elements. To streamline this process, we have adopted two approaches: for inputs where the probability of silence exceeds 0.95, we bypass the decoding step to minimize unnecessary calculations for silent sequences. Additionally, we focus on decoding the highest-ranked probabilities in the APM, which is especially advantageous for models dealing with multiple elements compared to those handling single notes. We configure the top-ξ setting to 10 for enhanced efficiency in sequence models.
3.3 Text editorThe ALBEF (Align Before Fuse) architecture is a powerful multimodal model designed to integrate and understand information from different modalities, primarily text and images. It operates on the principle of aligning features from multiple sources before fusing them into a unified representation. This approach enhances the model's ability to handle complex tasks that require understanding of both textual and visual information. In ALBEF, visual and textual inputs are processed separately through dedicated encoders, and their features are aligned and combined to produce a comprehensive understanding of the input data. This method has proven effective in a range of applications, including image captioning, visual question answering, and cross-modal retrieval.
3.3.1 Architectural adaptationIn our music education system, we adapt the ALBEF architecture by replacing the visual encoder with an audio editor to better align with speech recognition tasks. The text editor plays a crucial role in this adaptation, handling and processing the transcribed text produced by the Speech-to-Text (STT) model. To ensure seamless integration with the new audio editor, the text editor has undergone significant modifications. Originally, ALBEF uses a 6-layer Transformer model to process and interpret textual data. For our application, we have streamlined this architecture to a more efficient 3-layer Transformer model. This reduction is intended to optimize processing speed and resource utilization while maintaining the model's effectiveness in handling complex textual data. The adapted text editor is fine-tuned to align with the outputs of the audio editor. The fine-tuning process involves adjusting the model parameters and training the text editor to work in harmony with the transcriptions produced by the STT model. This ensures that the textual data processed by the editor is coherent with the audio context, allowing for accurate and contextually relevant responses in the music education system. The text editor is designed to process the transcribed text from the Speech-to-Text model, aligning it with the corresponding audio input. The model's efficiency is crucial in handling large volumes of textual data generated from user interactions. By reducing the Transformer layers and focusing on alignment with the audio editor, we ensure that the text editor can quickly and accurately process user inputs, providing relevant feedback and educational content.
The Transformer model processes input text data X through a series of encoder layers. Each encoder layer applies multi-head self-attention and feed-forward operations. The input to each encoder layer is denoted as Hl−1, and the output is Hl. The equations governing the Transformer encoder layers are:
Hl=LayerNorm(Hl-1+MultiHeadAttention(Hl-1,Hl-1,H
Comments (0)