
Remember me
Brain-Computer Interfaces (BCIs) enable direct connection between a user and a machine by translating brain activity into command signals for external device control. This technology can enhance the quality of life for patients with spinal cord or limb nerve damage and is increasingly applied in rehabilitation (Chen et al., 2023), such as using BCIs to assist robotic rehabilitation for patients with motor impairments (Gao et al., 2023). BCIs also have other broad applications, including robotic arms (Chen et al., 2019), gaming interfaces (Li et al., 2021), and Virtual Reality (VR) control (Deng et al., 2023).
In BCIs, brain signals can be classified into evoked and spontaneous types based on their formation. In non-invasive BCIs, evoked potentials are typically triggered by external stimuli (Wu and Wang, 2024), such as steady-state visual evoked potentials (SSVEP) and P300 potentials (Yin et al., 2014; Yin et al., 2013a; Yin et al., 2013b). In contrast, spontaneous EEG arises from cortical neural activity associated with mental processes, including Slow Cortical Potentials (SCP) and Motor Imagery (MI), and does not require external stimuli. Current EEG decoding research indicates that evoked potential BCI systems generally exhibit lower accuracy rates, while spontaneous EEG BCI systems demonstrate significant advantages. Notably, SCP-based BCIs remain underdeveloped, with research primarily focusing on Motor Imagery (Al-Saegh et al., 2021).
In Motor Imagery EEG signal acquisition, researchers have observed that different motor imagery tasks elicit responses from distinct brain regions. For instance, during ipsilateral versus contralateral movements, amplitude responses in the sensory-motor cortex vary across different frequency bands (8–12 Hz and 13–30 Hz), known as Event-Related Synchronization (ERS) and Event-Related Desynchronization (ERD) (Savić et al., 2020). Based on these phenomena, various feature extraction methods have been proposed, including Short-Time Fourier Transform (STFT), spatial filtering, Continuous Wavelet Transform (CWT), Common Spatial Pattern (CSP), and other algorithms (Annaby et al., 2021; Malan and Sharma, 2022; Zhang et al., 2022). Classification algorithms such as artificial neural networks (ANN), Support Vector Machines (SVM), and Bayesian classifiers are also widely used (Echtioui et al., 2024; Echtioui et al., 2023; Thenmozhi and Helen, 2022; Wang et al., 2023). CSP is a spatial domain filtering technique that extracts spatial components for different classification tasks but focuses solely on spatial features while neglecting temporal and frequency domain features, potentially affecting experimental results.
In deep learning, Convolutional Neural Networks (CNNs) have shown mature applications in natural language processing (Mehrdad and Salimi, 2023) and computer vision (Bhatt et al., 2021). Recently, they have been introduced to EEG signal classification with promising results. For instance, Li et al. (2022) combined CNNs with Long Short-Term Memory (LSTM) networks, achieving an average decoding accuracy and Kappa value of 87.68% and 0.8245, respectively. Zhang et al. (2023). developed a multi-branch fusion CNN model using two types of CNN networks to analyze EEG data and temporal-frequency maps, achieving a 78.52% average accuracy rate. Roy (2022) employed a multi-scale CNN combined with data augmentation to extract information across different frequency bands, reaching a 93.74% accuracy rate on the BCI Competition IV-2b dataset. Zhang et al. (2020) proposed a graph convolutional neural network with an attention mechanism, which assigns different weights to the features extracted by the CNN. This approach enhances the focus on critical spatiotemporal features. The model achieved an accuracy rate of 74.71% on the EEG Motor Movement/Imagery Dataset, outperforming advanced networks at the time. These findings demonstrate that deep learning methods exhibit strong performance in classifying EEG signals. These results demonstrate the effectiveness of deep learning methods for EEG signal classification.
However, existing research primarily focuses on learning temporal or spatial–temporal features of EEG signals and does not fully exploit the frequency and spatial domain information contained within these signals. To better utilize the multidimensional characteristics of EEG signals, this study proposes the following innovations:
1. To address the limitations of traditional convolutional networks that primarily focus on the spatial–temporal features of EEG signals, this study converts raw EEG data into two-dimensional spatial-frequency spectral images. EEG signal segments are extracted using a sliding window approach, and power spectral features are obtained via the Welch method. By selecting appropriate frequencies and electrode spatial topology and combining these with cubic interpolation, power spectral density (PSD) maps containing the spatial-frequency features of EEG signals are generated. This feature fusion method effectively extracts spatial-frequency characteristics and enriches the original data, providing more effective input for subsequent model training.
2. To decode the spatial-frequency feature maps, this study proposes a novel 3D CNN architecture. By employing a combination of 1D and 2D convolutional structures in series, the network performs convolutions in both spatial and frequency domains. The dual-layer convolutional structure enhances the network’s capacity to extract both spatial and frequency domain features from EEG signals, facilitating effective learning of spatial-frequency characteristics and improving model training and performance.
3. Analyzing the frequency band information of EEG signals allows for the identification of features particularly relevant to motor imagery tasks, leading to the optimization of the spatial-frequency feature maps accordingly. By focusing on these key features, the training effectiveness and overall model performance are significantly enhanced. The proposed method is rigorously evaluated against classical machine learning and deep learning models using publicly available EEG datasets, demonstrating its superior effectiveness. Additionally, visualization techniques are employed to observe feature classification throughout the convolution process, thereby enhancing the model’s interpretability.
2 Data source and data transformation 2.1 Motor imagery datasetThe dataset used to evaluate the network performance in this study is the publicly available EEG Motor Movement/Imagery Dataset (Goldberger et al., 2000). This dataset includes EEG recordings from 109 volunteers, capturing their brain activity during various motor and motor imagery tasks.
The experimental procedure is as follows: EEG signals were collected from 64 electrode sites on the scalp of each participant using the BCI2000 system, adhering to the international 10–10 electrode system. The sampling rate was 160 Hz (excluding electrodes Nz, F9, F10, FT9, FT10, A1, A2, TP9, TP10, P9, and P10). Each participant sat in front of a monitor and, upon the display of specific instructions, either imagined or performed the corresponding movements. The system recorded EEG data corresponding to the motor executed and motor imagery (MI) tasks. Each participant completed multiple rounds of these tasks with appropriate rest periods between rounds. The MI tasks were binary classification tasks: imagining left-fist and right-fist movements. Due to the poor quality of EEG signals from 5 participants (S004, S088, S089, S092, S100), the final analysis used EEG data from 104 participants.
2.2 EEG signal preprocessingIn the signal data preprocessing, we employed segmentation and filtering methods. To enhance processing speed and focus on key time windows for motor imagery (MI) tasks, the raw EEG data were cut and divided into 4-s segments. For each subject and each EEG channel, a total of 640 EEG time points from one segment were preprocessed within this 4-s window, tailored to the characteristics of the selected dataset. To minimize interference such as power-line noise, the segmented EEG signals were filtered. Relevant EEG frequency bands for MI tasks primarily focus on alpha and beta rhythms (Wu and Wang, 2024). Therefore, we used a bandpass MNE filter with a stopband attenuation value of 40 dB and a gain of approximately −3 dB, operating within the frequency range of 5–35 Hz. This filter effectively removes artifacts from sources such as electrocardiogram (ECG), eye movements, and unstable respiration, thereby improving the overall signal-to-noise ratio.
2.3 Welch power spectral density estimationThe Welch power spectral density (PSD) estimation is a method for spectral estimation based on averaging over segments of the signal, allowing for the determination of energy distribution across different frequencies. Compared to traditional spectral estimation methods, Welch’s approach offers improved computational efficiency and estimation accuracy and is widely used in fields such as signal processing, communications, and acoustics. The principle of Welch’s power spectral density estimation is as follows (Altan et al., 2021):
First, the data x(n) of length N is divided into L segments, each containing M data points. The i-th segment of data is denoted as Equation 1:
xin=xn+iM−M,0≤n≤M,1≤i≤L (1)Then, using the Fast Fourier Transform (FFT), apply the window function w(n) to each data segment and calculate the power spectral density for each time segment. The power spectral density of the i-th segment is given by:
Iiω=1U∑n=0M−1xinwne−jωn2,i=1,2,…,M−1 (2)In Equation 2, U is referred to as the normalization factor Equation 3:
U=1M∑n=0M−1w2n (3)Assuming the power spectral densities of each segment are approximately independent, the final power spectral estimate, known as the Welch power spectral density, is given by Equation 4:
Pxxejω=1L∑i=1LIiω (4)This estimate is obtained by averaging the power spectral densities of individual segments, which reduces variance and improves reliability. In this paper, this technique utilizes 640 time points from one segment for analysis.
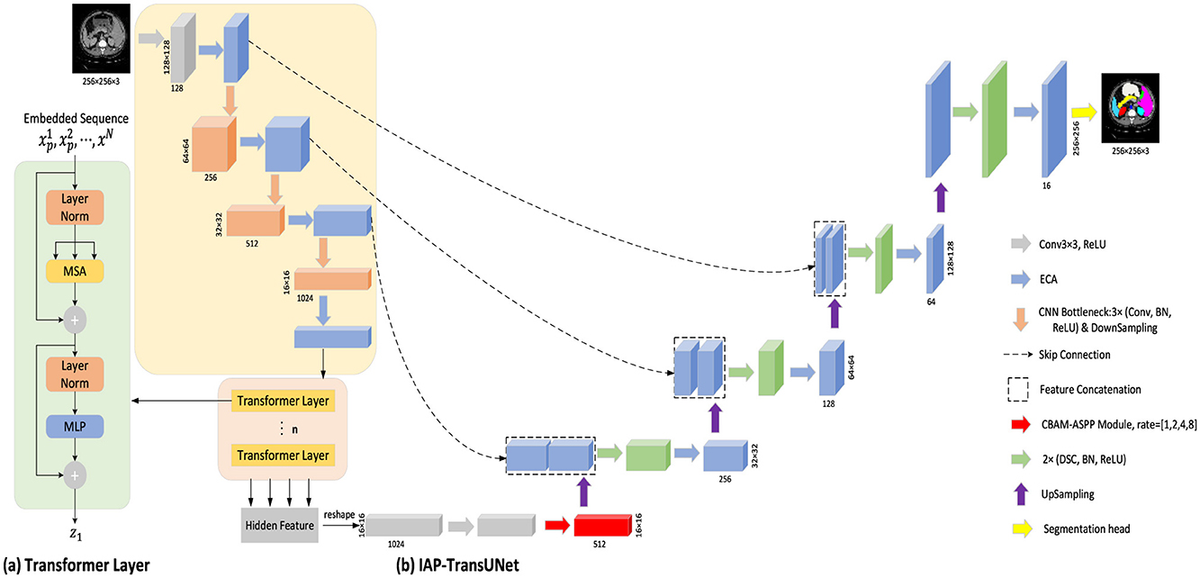
2.4 Data transformationThe process of dataset transformation is illustrated in Figure 1. The original EEG signals, collected from 64 channels, are first sliced into multiple short time windows using a Segment technique. For these EEG segments, the Welch PSD estimation method is employed to compute the power spectral density features in the 10–15 Hz frequency band for time segment. The selection of the 10–15 Hz frequency band is an optimized result obtained through experiments and is the most relevant EEG frequency band for the imagined movement of the left and right fists. The specific selection criteria are detailed in Section 3.1.
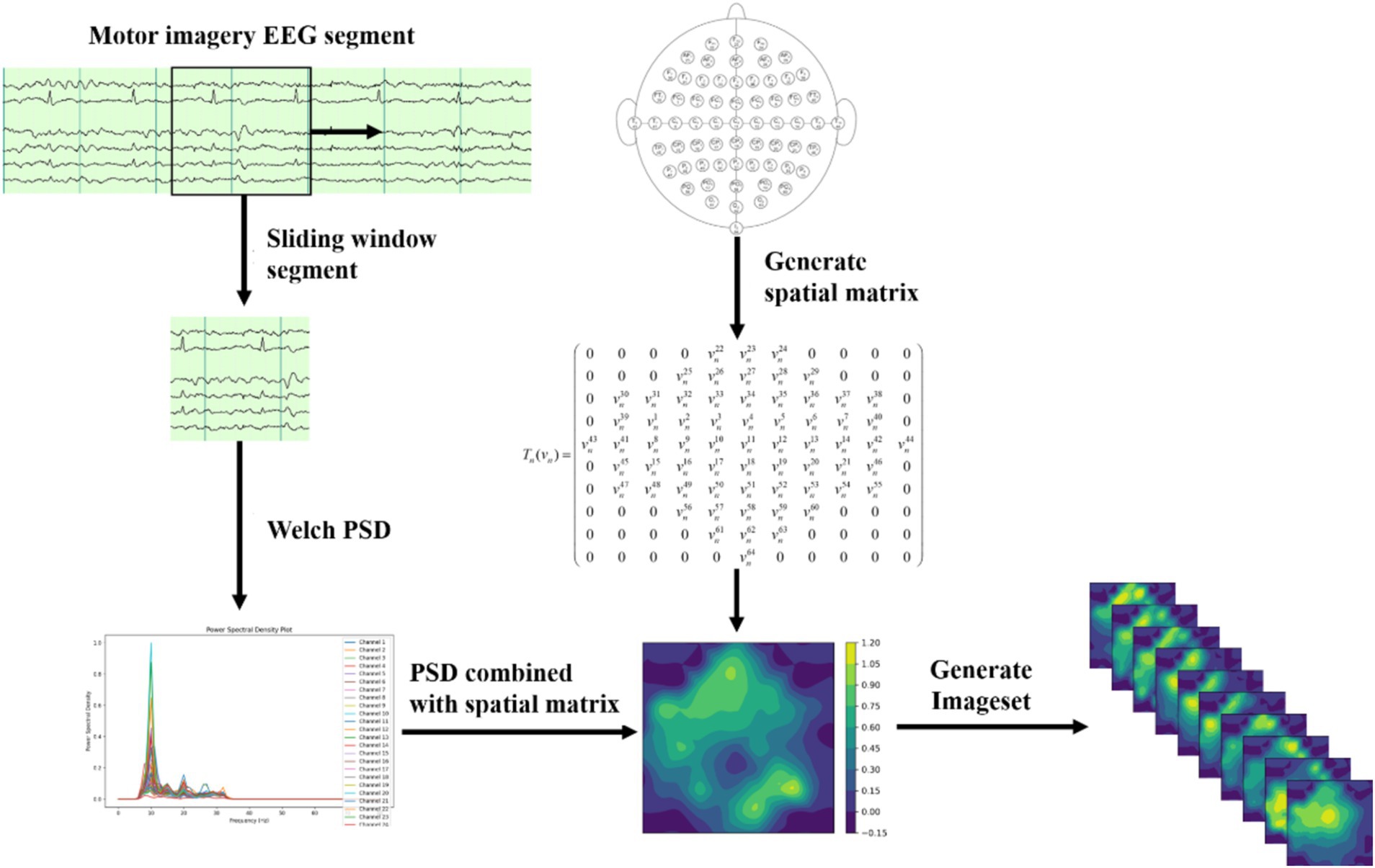
Figure 1. Dataset transformation process.
Next, we divide the 10–15 Hz frequency band into 10 sub-bands. For each sub-band, the signal values are organized into a 2D matrix based on the spatial distribution of the 64 electrodes in the dataset. Let the individual signal value be denoted as vn, where vn=vn1+vn2+vn3+.…vn64 . An empty 2D matrix Tn is created, and vn is transformed into the 2D matrix Tn (vn) using the spatial information from the dataset, as shown below Equation 5:
Tn(vn)=(0000vn22vn23vn240000000vn25vn26vn27vn28v9n290000vn30vn31vn32vn33vn34vn35vn36vn37vn3800vn39vn1vn2vn3vn4vn5vn6vn7vn400vn43vn41vn8vn9vn10vn11vn12vn13vn14vn42vn440vn45vn15vn16vn17vn18vn19vn20vn21vn4600vn47vn48vn49vn50vn51vn52vn53vn54vn550000vn56vn57vn58vn59vn600000000vn61vn62vn63000000000vn6400000) (5)This method effectively represents the signal characteristic distribution at different electrode positions within this frequency band. EEG signals typically exhibit spatial correlation, where the signal variation trends of adjacent channels are similar. To further capture the spatial topology relationship among electrodes, this paper employs a triangulation-based cubic interpolation technique in MATLAB to interpolate the generated 2D matrix.
Specifically, 110 linear vectors are uniformly generated at one coordinate, and 100 linear vectors are generated at another. This transforms the original matrix shape of (11, 10) into a high-resolution matrix with the shape of (110, 100). The high-resolution matrix simulates the relatively dispersed distribution of brain electrodes on the brain’s surface, allowing for smoother transitions of EEG signals in subsequent image generation processes and restoring more realistic features of biological EEG signals.
Next, a 2D EEG map of the frequency sub-bands features is formed using the high-resolution matrix data. Finally, we integrate the 2D EEG maps corresponding to the 10 frequency sub-bands into a three-dimensional spatial frequency image dataset. This fusion of spatial frequency domain features enhances the capture of the complex characteristics of EEG signals and provides richer input data for subsequent deep learning models.
3 Motor imagery EEG decoding method 3.1 3D convolutional neural network based on spatial-spectral feature pictures learningTraditional convolutional network models are limited by the type of input raw EEG signals, typically processing only time-frequency or spatiotemporal features while neglecting the exploration of spatial and frequency domains. To address this limitation, this study proposes a MI EEG decoding method based on spatial frequency feature maps, utilizing 3D convolutional neural networks (P-3DCNN). This approach leverages the local receptive field and weight-sharing characteristics of convolutional networks, enabling CNN to learn richer feature representations through specially designed convolutional structures in both frequency and spatial dimensions. Specifically, the method employs two sets of 3D convolutional structures to abstractly learn spatial frequency features and capture multidimensional EEG signal information. The network comprises two sets of convolutional components, each containing spatial convolution, frequency domain convolution, and a pooling layer, as illustrated in Figure 2.
ŷ=softmaxz=softmaxWTx+b (7)1. Input layer: The input to the network is the transformed 2D EEG spatial-frequency map dataset. Each sample is represented by a data matrix of size 110 × 100 × 10, where 110 and 100 denote the number of pixels in the x and y axes of the 2D EEG map (representing spatial information), and 10 denotes the number of image frames in each MI task (representing frequency domain information).
2. Spatial-frequency pseudo-3D convolution module: This module is designed to extract spatial and frequency domain features from the spatial-frequency maps. Pseudo-3D convolutions sequentially convolve EEG map sequences in both spatial and frequency directions. For the spatial direction convolution, the 3D convolution kernel in Convolution Layer 1 has its frequency domain parameters set to 1, while the spatial parameters are configured to 5 × 5. This configuration emphasizes spatial convolution, allowing the model to focus on the spatial relationships within the EEG data. In Convolution Layer 2, the kernel parameters are adjusted to capture frequency domain features: the frequency domain parameters are set to 5, and the spatial direction parameters are set to 1 × 1. This setup enables the layer to effectively extract key frequency characteristics from the EEG signals. Following these convolutions, operations such as squaring, 3D convolution-pooling, and logarithmic transformations are applied to fully extract and enhance the spatial-frequency features of the EEG samples. Throughout all convolution layers, we utilize non-linear Rectified Linear Unit (ReLU) activation functions in Equation 6 to introduce non-linearity and improve the model’s capability to learn complex patterns.
3. 3D convolution-pooling module: The convolution-pooling module reduces the dimensionality of the EEG signal’s spatial-frequency features and learns more abstract high-level features, achieving multi-scale learning. 3D convolution operations alter the data structure, with a stride of 2 and no padding to reduce feature map size during pooling. This 3D convolution also computes more advanced feature representations from the spatial-frequency features extracted by the spatial-frequency 3D convolution module.
4. Fully connected layer and softmax output layer: This part maps the feature representations to the final classification results, achieving motor imagery task classification. The features extracted by the convolution-pooling module are processed into feature vectors. The fully connected layer consists of 256 neurons, each connected to all feature vectors, using ReLU as the activation function. The Softmax output layer is widely used for classification tasks, normalizing input values into a probability distribution between 0 and 1. This study’s Softmax layer includes two neurons corresponding to the left and right fist motor imagery tasks. The calculation for the Softmax output layer is as follows Equation 7:
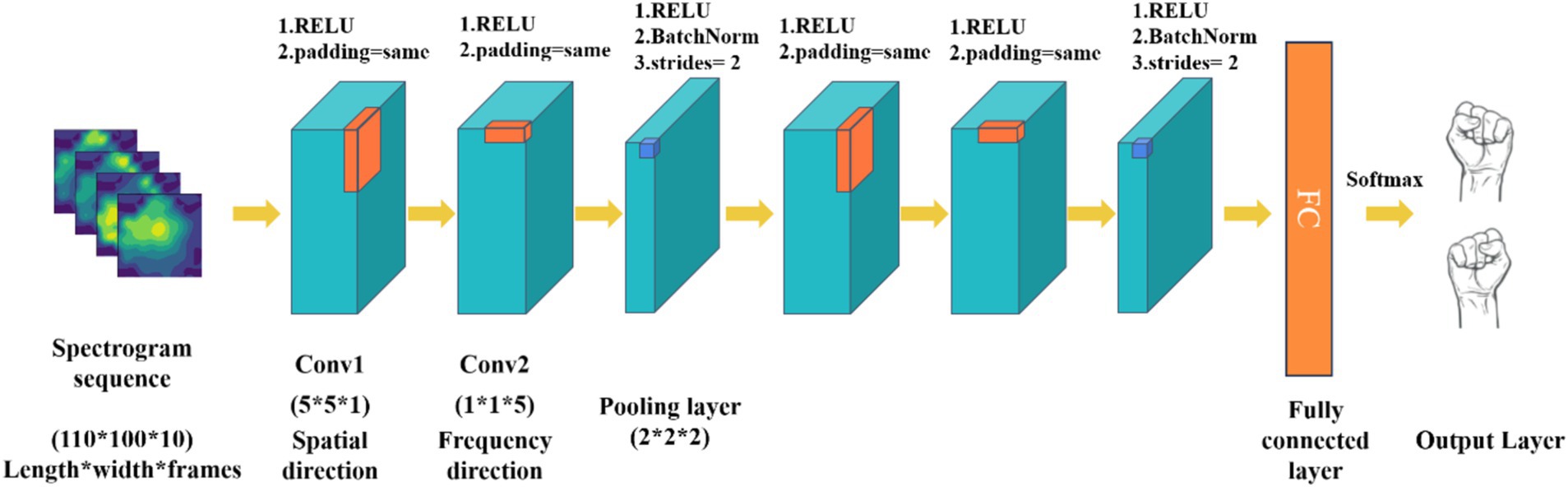
Figure 2. The architecture of 3D CNN based on spatial-spectral feature pictures learning (P-3DCNN). The convolution kernel sizes for the three convolutional layers are (5 × 5 × 1), (1 × 1 × 5), and (2 × 2 × 2), respectively.
Here, x represents the input to the fully connected layer, W is the weight matrix, b is the bias term, and ŷ denotes the output probabilities of the Softmax function, given by Equation 8:
softmaxz=ez∑Kez (8)K represents the number of labeled outputs. For instance, K = 2.
5. Training and optimization of the P-3DCNN network: To achieve effective convergence of the P-3DCNN network and ensure that the model’s predictions are as close as possible to the correct classifications, it is essential to define and minimize the network’s loss function. The P-3DCNN network can be represented by the mapping function g (Xj; θ): RC×T→ RK, where Xj is the given input to the network, which in this study is the spatial-frequency EEG dataset, C and T represent spatial and frequency features, θ represents all parameters in the P-3DCNN network, and is a crucial optimization target in network training, and K denotes the number of output classes.
To compute the conditional probability distribution of the network input Xj given different labels lk, the formula is as follows Equation 9:
plk|gXj;θ=egXj;θ∑KegXj;θ (9)To optimize θ and determine the optimal parameters for the P-3DCNN, the goal is to minimize the sum of the loss across all samples. The optimization can be formulated as follows Equation 10:
θ∗=argmin∑j=1Nlossyj,plk|gXj;θ (10)In this context, yj represents the actual class of the sample Xj, and loss(g) denotes the loss function, also known as the Negative Log-Likelihood Function (NLL) (Murphy, 2012). The Negative Log-Likelihood Function for classification tasks, particularly when using Softmax, is defined as Equation 11:
lossg=∑k=1K−logplk|gXj;θgδyj=lk (11)To enhance the training performance of the P-3DCNN network, the following optimization strategies were employed:
1. Mini-batch stochastic gradient descent: The mini-batch stochastic gradient descent (SGD) was utilized to update and optimize the network parameters (Woodworth et al., 2020). This optimization method not only improves model stability and generalization but also effectively optimizes memory usage, reduces computational requirements, and shortens decoding time.
2. Batch normalization: After the second and sixth convolutional layers, batch normalization (BN) was incorporated. This technique helps prevent overfitting and enhances the robustness of the model by normalizing the activations and gradients, ensuring that the network learns more effectively.
3. Dropout: A dropout operation with a probability of 50% was added after the sixth convolutional layer. Dropout further improves the model’s convergence speed, generalization performance, and classification accuracy by randomly deactivating a subset of neurons during training, which helps in reducing overfitting.
4. These strategies collectively contribute to a more efficient and effective training process for the P-3DCNN network, leading to better overall performance.
3.2 Evaluation criteria and statistical methodsFor each subject’s temporal-frequency image dataset, the split function in Python is used with a random seed of 42 to shuffle the entire dataset. The data is then divided into training and testing sets with a 75–25% split. Various machine learning and deep learning models are trained and evaluated using these sets. The primary evaluation metrics include: (1) the average accuracy rate of each model on the subject data. The formula for calculating Recall is Equation 12:
Average=1N∑i=1NRiSi×100% (12)In this formula, N represents the total number of subjects, Ri represents the number of correct predictions for subject i, Si represents the total number of instances for subject i; (2) the Kappa coefficient, which measures the consistency of classification results compared to completely random classification, calculated using the following formula Equation 13:
Kappa=Po−Pe1−Pe (13)In this context, Po represents the overall accuracy rate, Pe denotes the random classification rate (for binary classification problems, Pe is defined as 0.5); (3) Recall, which reflects the model’s ability to correctly identify positive samples. The formula for calculating Recall is Equation 14:
Recall=TPTP+FN (14)Here, True Positive (TP) represents the number of samples correctly predicted as positive, and False Negative (FN) represents the number of positive samples predicted as negative. A higher recall indicates a model’s stronger ability to identify positive samples correctly. (4) F1 Score is a metric that combines accuracy rate and recall, with its calculation formula being Equation 15:
F1=2×Precision×RecallPrecision+Recall (15)Here, Precision represents the proportion of true positives among the samples predicted as positive. The F1 Score ranges from [0, 1], with a higher value indicating better performance of the classification model. F1 Score integrates both Precision and Recall, serving as a comprehensive evaluation metric. When both Precision and Recall are high, the F1 Score will also be high. (5) The confusion matrix for each type of motor imagery EEG is computed, which visually reflects the classification model’s accuracy for each category and illustrates how samples are misclassified into other categories.
4 Experimental results and analysis 4.1 Optimization of specific frequency bandsDue to the inherent weakness of EEG signals, they are inevitably affected by environmental factors such as power line noise and eye movement artifacts during data collection. Even with extensive efforts to remove these artifacts during the preprocessing stage, complete elimination remains challenging. Therefore, before converting the raw EEG signals into two-dimensional EEG topographic maps, the EEG topographic maps generated for different frequency bands are first subdivided, with frequency bands segmented into 5 Hz intervals (Pei et al., 2021), as shown in Figure 3. Subsequently, these subdivided data are pre-classified, and the classification results are presented in Table 1.
Figure 3. Frequency band segmentation method.

Table 1. The average accuracy rate for each frequency band.
Based on the classification results in Table 1, it is evident that the 10–15 Hz frequency band dataset performs better than others, with an average accuracy rate higher than that of the other bands. Therefore, this study has decided to use the 10–15 Hz frequency band data for subsequent EEG signal decoding and classification. This choice not only capitalizes on the significant features within this frequency band but also effectively reduces decoding time and enhances overall classification performance.
4.2 Comparison of results from decoding methodsThe experimental setup was designed to evaluate the performance of the proposed model under controlled conditions. We conducted the training for a total of 500 epochs, employing a learning rate of 0.001 to facilitate effective convergence. The batch size was set to 64, optimizing the trade-off between training speed and memory usage. All experiments were executed on an NVIDIA RTX 3090 GPU-24GB, ensuring sufficient computational resources to handle the demands of deep learning tasks. These configurations were selected to enhance the robustness and accuracy of the model’s performance in the decoding tasks.
To validate the decoding performance of the P-3DCNN network, we compared it with several advanced algorithms, including two traditional machine learning algorithms and five state-of-the-art deep learning algorithms.
Antony et al. (2022) used online recursive independent component analysis to analyze seven principal components and employed adaptive SVM for classification. Yacine et al. (2022) combined Riemannian space with artificial neural networks, using 144 samples of 253-dimensional data as input, with ReLU as the activation function, completing the classification task after 60 iterations. Zhang et al. (2023) utilized two convolutional neural network-based architectures to extract temporal and frequency features. These features are then fused and input into a fully connected layer for classification. Li and Ruan (2021) proposed a four-layer 3DCNN for feature extraction from EEG data, optimizing decoding capabilities with ReLU and batch normalization after each convolution. Lawhern et al. (2018) introduced EEGNet, utilizing one-dimensional and deep convolutional layers for real-time feature extraction. Chaudhary et al. (2019) created DeepConvNet with a convolutional layer and pooling layer, enhanced by short-time Fourier transform for improved time-frequency feature capture. Milanes Hermosilla et al. (2021) developed ShallowConNet, which uses two shallow convolutional layers with small kernels, enabling fast decoding and effective handling of local time-frequency features. The decoding performance of these networks, based on publicly available datasets, is summarized in Table 2.
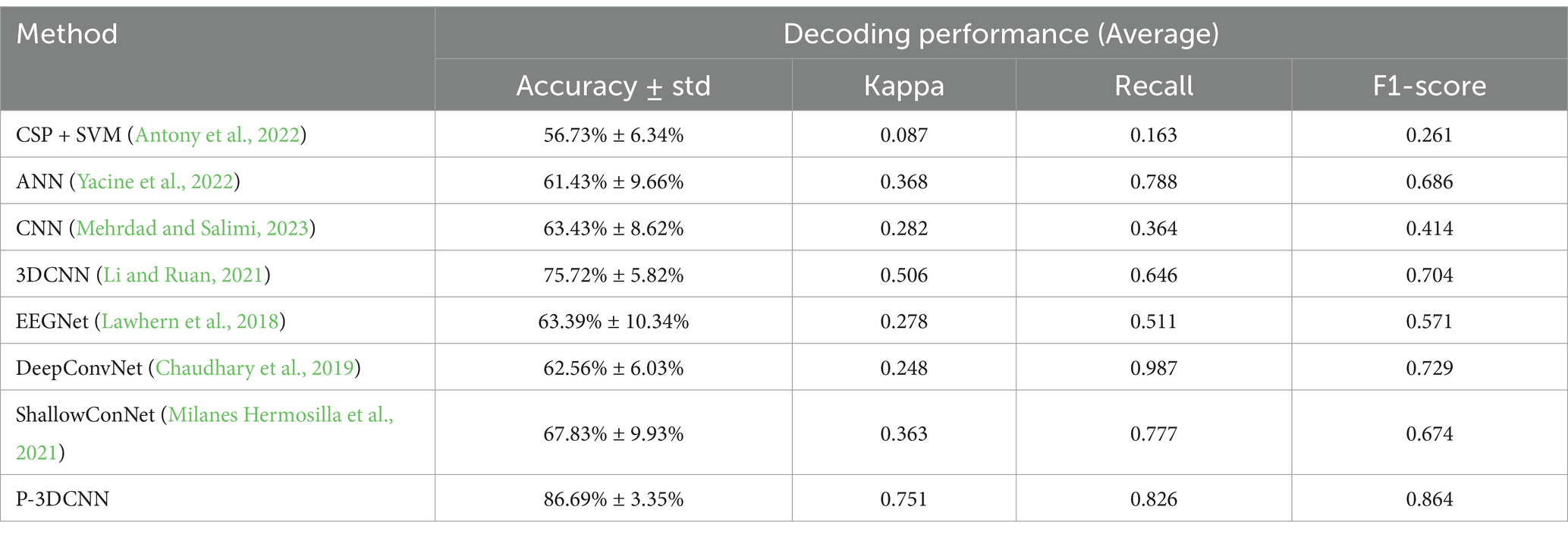
Table 2. The decoding performance for each method.
The comparison results in Table 2 indicate that deep learning methods, compared to traditional machine learning approaches such as CSP + SVM and ANN, significantly enhance EEG signal classification accuracy and Kappa coefficient metrics. Specifically, the proposed P-3DCNN method achieves an average accuracy rate of 86.69%, which is 12–31% higher than traditional machine learning and existing advanced deep learning algorithms. The P-3DCNN method also attains an average Kappa coefficient of 0.751, falling between 0.61 and 0.80, reflecting a high level of consistency. Among similar machine learning and deep learning methods, 3DCNN has the highest Kappa coefficient of 0.506, but it is still lower than that of the proposed P-3DCNN. The P-3DCNN method also performs well in terms of recall and F1 score. Overall, P-3DCNN significantly improves decoding performance compared to methods like CSP + SVM, EEGNet, and DeepCovNet, validating its effectiveness in the domain of motor imagery EEG decoding.
Further analysis reveals that considering both frequency and spatial domain information, 3DCNN improves the average accuracy rate by 12.29% over traditional CNN. By optimizing the CNN architecture and employing methods such as spectrogram generation, the proposed P-3DCNN achieves an 11.61% improvement in average accuracy rate over 3DCNN, while also achieving higher Kappa coefficients, recall rates, and F1 scores. This underscores the superior performance of the P-3DCNN decoding scheme for motor imagery EEG classification tasks.
4.3 Analysis of confusion matrix resultsTo provide a more comprehensive evaluation of the proposed method’s performance in recognizing various types of motor imagery EEG, we calculated the average confusion matrix, as shown in Figure 5. In the confusion matrix, rows represent the actual motor imagery categories (e.g., left fist, right fist), while columns represent the predicted motor imagery categories. When the row and column categories match, it indicates the proportion of correctly classified motor imagery tasks; mismatches represent the proportion of misclassified tasks.
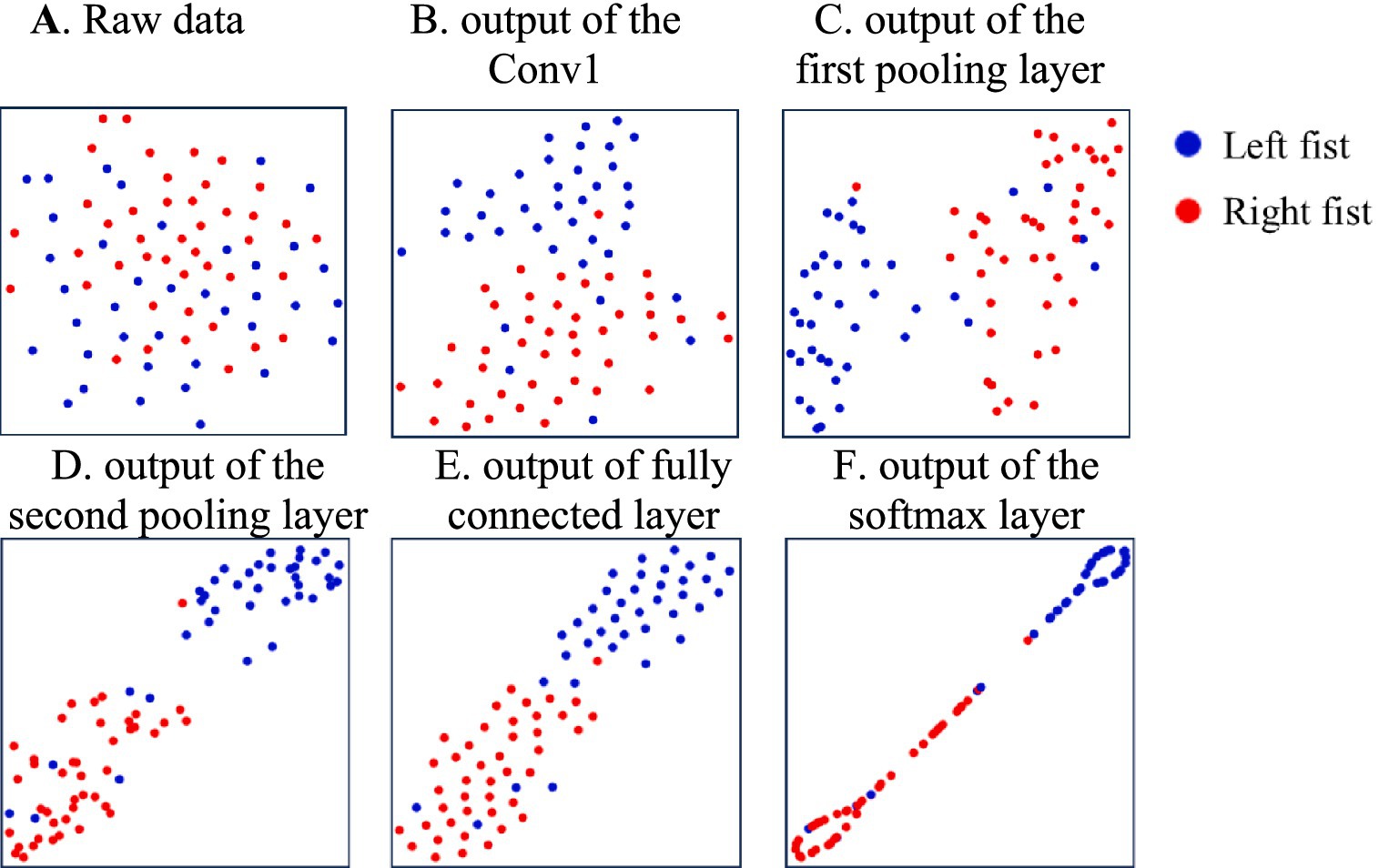
Figure 4. The distribution of features of the different model’s processing layers during the training of subject-2. (A) Raw data, (B) the Conv1, (C) the first pooling layer, (D) the second pooling layer, (E) fully connected layer, (F) the softmax layer.
Figures 5A,B show that EEGNet and DeepConvNet methods exhibit similar performance in recognizing motor imagery EEG for this task, with accuracy rates both below 80%. Figure 5C reveals that ShallowConvNet performs well for left fist imagery, with accuracy rates exceeding 80%, but struggles with right fist imagery, where the accuracy rate falls below 70%. Figure 5D illustrates that the basic CNN network structure yields suboptimal classification results compared to other networks, although 3DCNN (Figure 5E) shows substantial improvement. However, the accuracy rate for left fist imagery still does not exceed 80%. This may be due to both left and right fist motor imagery occupying the same sensory motor area, leading to lower spatial resolution of EEG signals. This suggests that while 3DCNN attempts to analyze the data from spatial and frequency domains, its decoding performance is still not ideal and does not fully leverage spatial-frequency domain information. Hence, even with advanced machine learning algorithms, there are inherent limitations in recognizing EEG signals for left and right fist motor imagery, indicating substantial room for improvement.
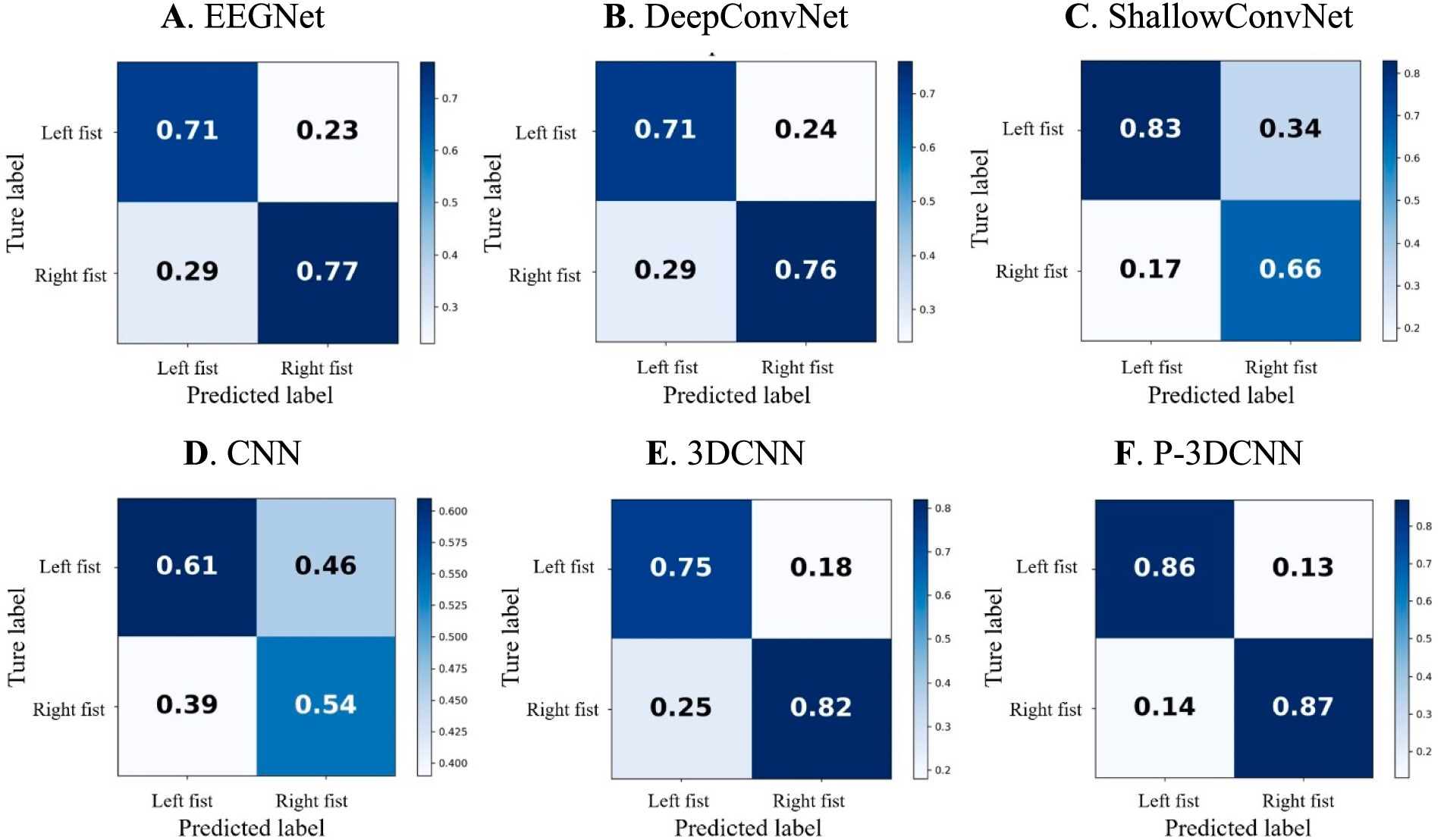
Figure 5. The confusion matrix for motor imagery EEG classes with deep learning decoding method. (A) EEGNet, (B) DeepConvNet, (C) ShallowConvNet, (D) CNN, (E) 3DCNN, (F) P-3DCNN, respectively.
In contrast, the proposed P-3DCNN method (Figure 5F) significantly improves accuracy rates for both left and right fist motor imagery EEG, with rates reaching 86 and 87%, respectively. This indicates that the P-3DCNN method more effectively extracts spatial-frequency domain information from the 2D spectrograms, resulting in better decoding performance by analyzing higher resolution spatial-frequency features.
4.4 VisualizationIn this section, we will visualize the process of the P-3DCNN to gain an intuitive understanding of its performance. We focus on the training process of Subject-2 to examine both accuracy and loss over the training epochs. As shown in Figure 6, the model’s accuracy improves rapidly between epochs 25 and 75, demonstrating a period of significant learning. After epoch 100, the accuracy stabilizes, indicating that the model has reached a steady state in terms of performance. Concurrently, the loss function approaches zero after 100 epochs, reflecting the excellent convergence capability of the P-3DCNN model. These observations highlight the model’s efficiency in learning and its ability to effectively minimize error, illustrating the robustness and effectiveness of the P-3DCNN approach in handling the given task (Figure 6).
Comments (0)