
Remember me
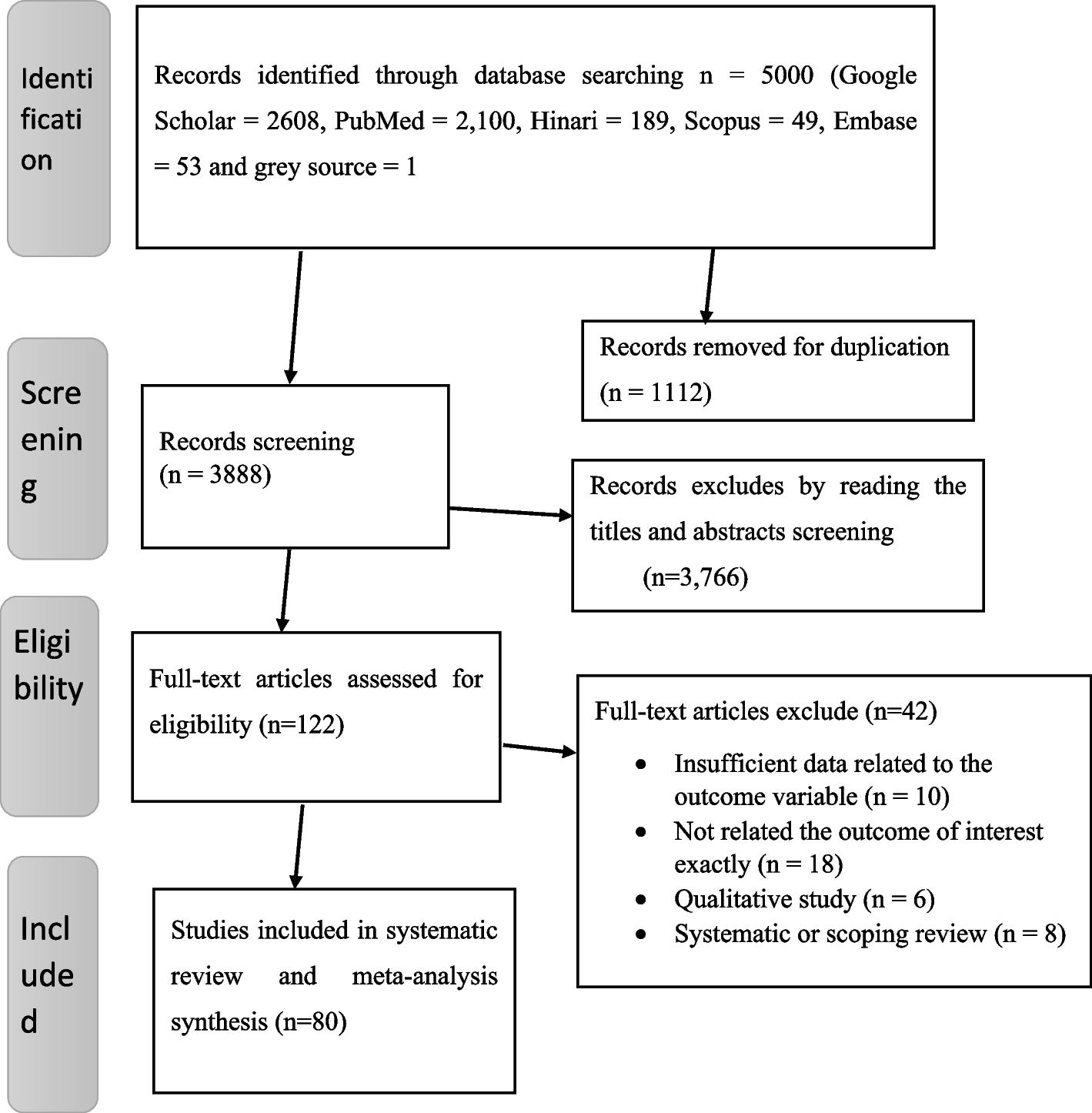
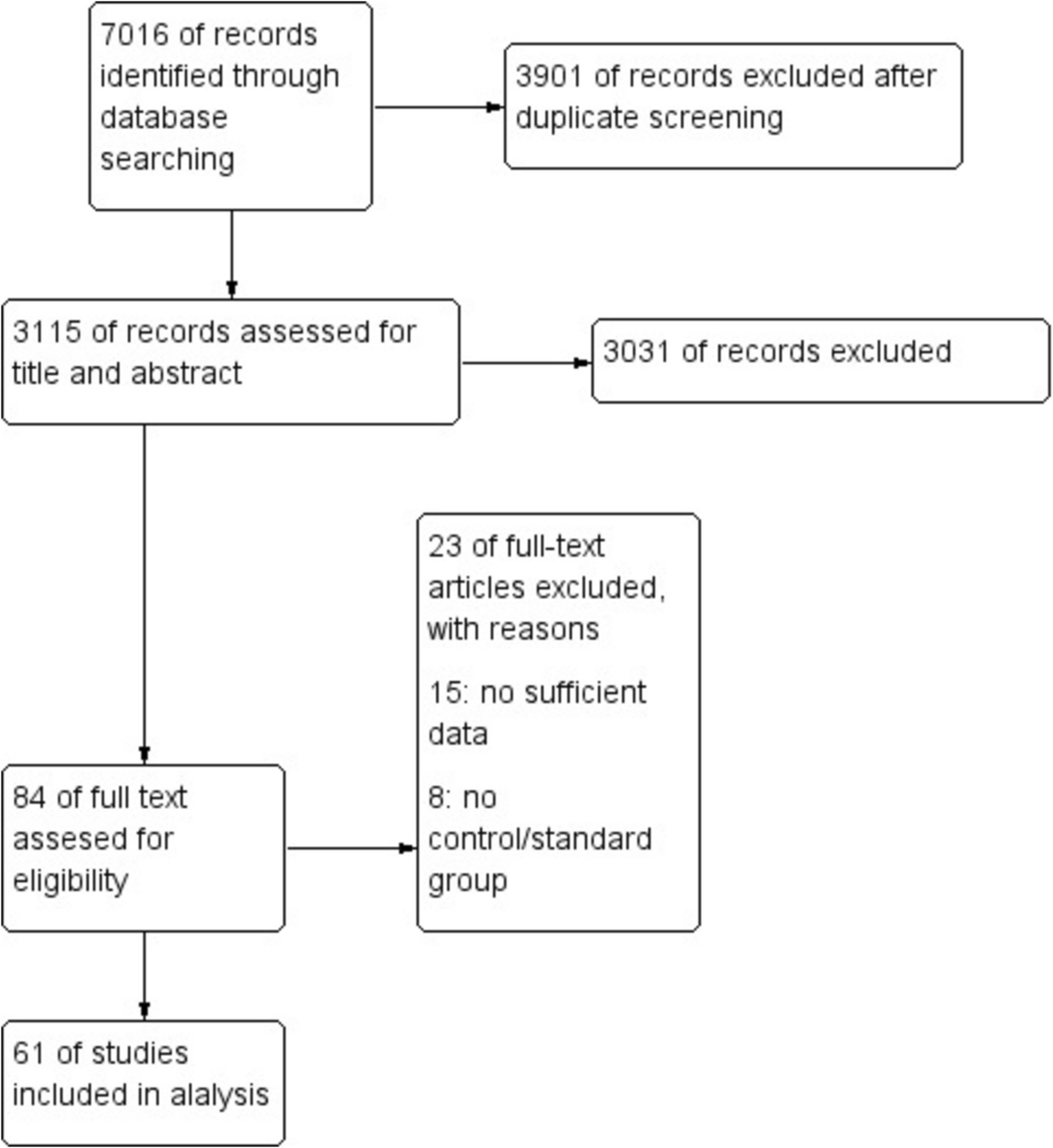
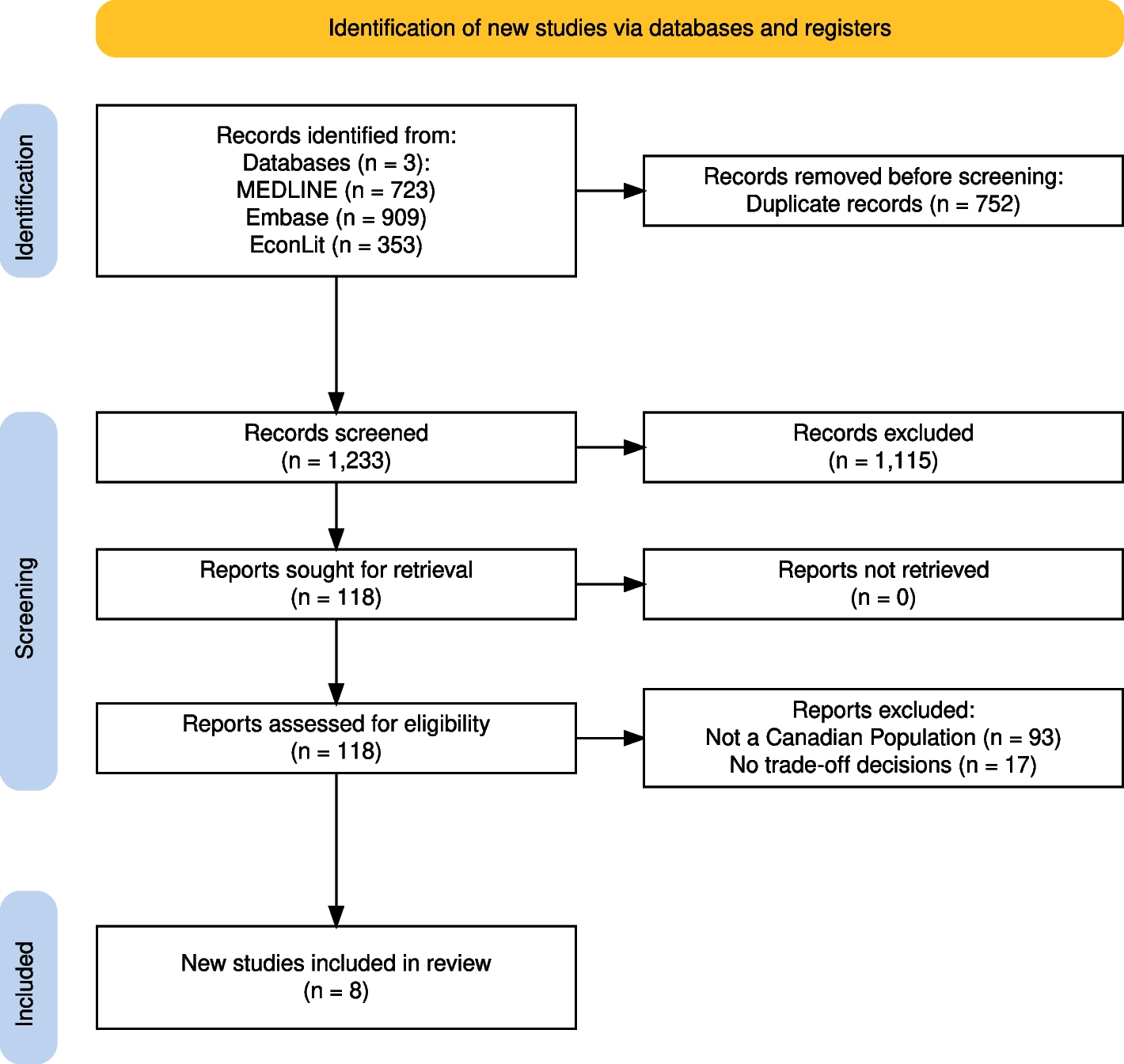
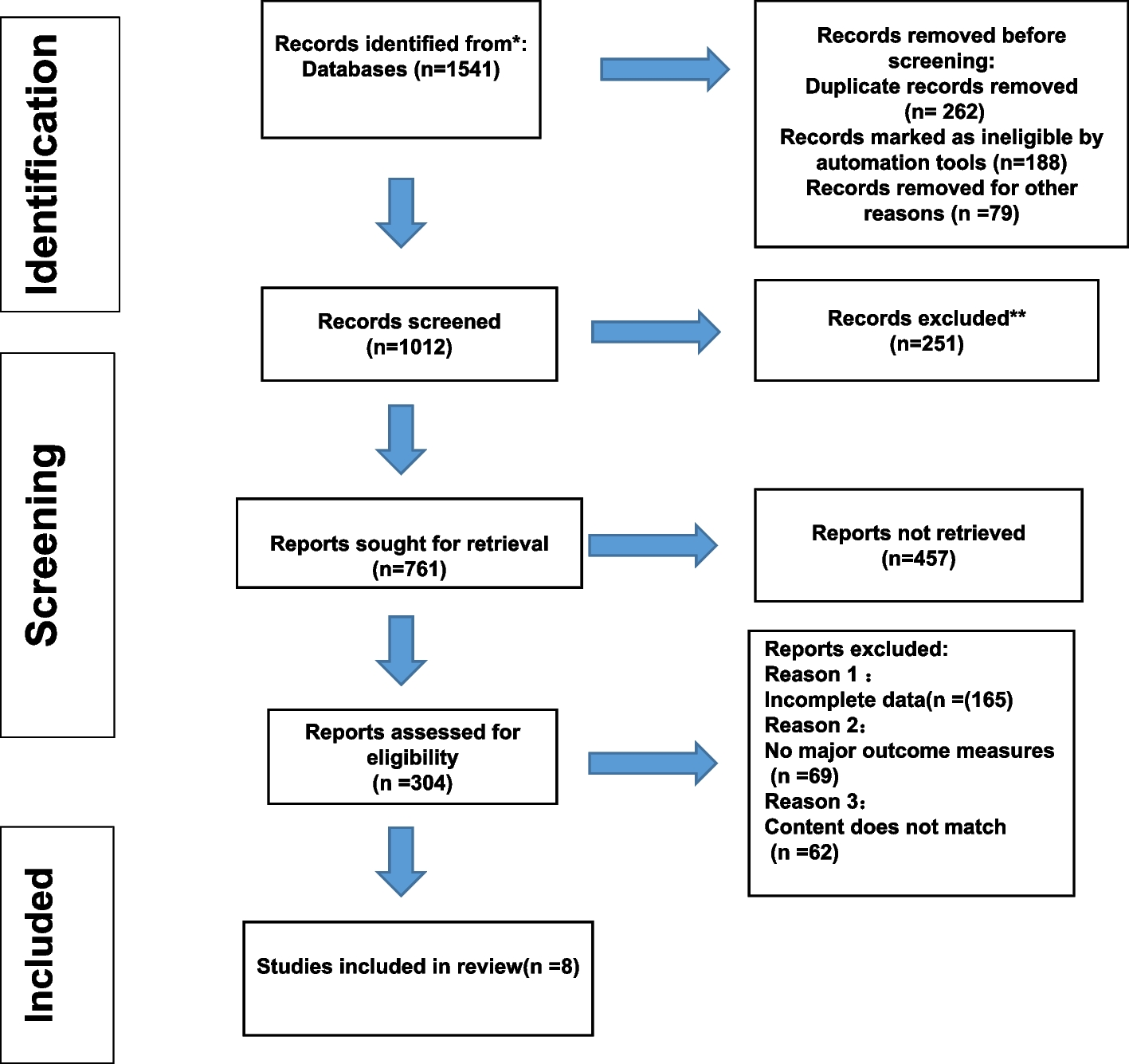
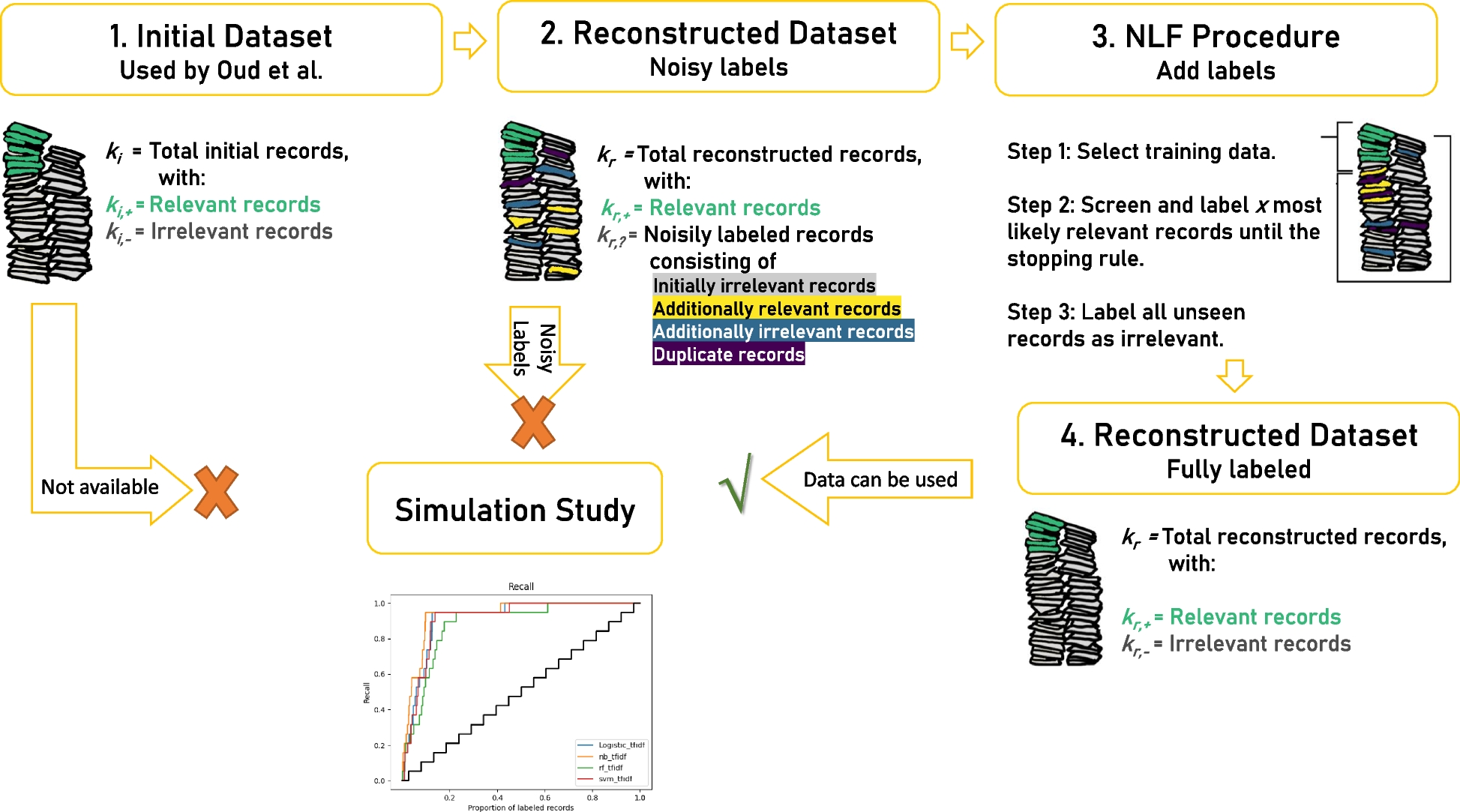


In this study, we explored a method to create a dataset to conduct a simulation study evaluating the performance of active learning models. The information we did have access to consisted of the published search queries and the corresponding number of results, the list of included papers, and the number of screened records. Although the authors of the initial systematic review (i.e., [29]) followed the, at that time, prevailing 2009 and the updated 2020 guidelines [25, 30], the list of excluded records was not available. We discovered that replicating the initial search query 5 years later to reconstruct the initial dataset is only possible to a certain extent, but we could not reproduce the exact same data. There are several explanations, all outside the influence of the original authors, such as search reproduction being limited by differences in institutional access, search strings without specified search fields, and changes in the literature databases over time.
As a result, it remains unknown whether our reproduced dataset contains exactly the initial records. The issue with running a simulation study with such noisy labels is the possibility of additional relevant records: a paper only found by the replication process and relevant according to inclusion criteria. Such a noisy label will hamper the performance of active learning models since a model will be trained with erroneously labeled data. That is why one should not naively label all noisy labels as irrelevant. Therefore, we introduced the Noisy Label Filter (NLF) procedure. In short, a researcher screens the most likely relevant but noisy labels as predicted by a machine-learning model until a pre-specified stopping rule is met. This way, one can test for the presence of additional relevant records with minimum screening effort. The NLF outcome for our case study was that we labeled all noisy labels as irrelevant, with more confidence than without the NLF procedure. Then, we were able to run the simulation study testing the performance of active learning on our reconstructed, fully-labeled dataset.
As this type of research is quite specific and new, there were informational constraints. To the best of our knowledge, there was no other study on reconstructing a database to run a simulation study. Because of that, some decisions in our process and design were made based on personal judgment and intuition rather than prescribed rules and norms. For example, we decided not to include The Cochrane Library database because of viability and expected overlap in records. We believe this did not harm our goal of finding the initial inclusions; all initially included records were retrieved from the other databases. Furthermore, we implemented a provisional stopping rule where screening was halted after approximately one hour or upon labeling 50 consecutive records as irrelevant. The selection of this threshold is subject to ongoing debate within the screening literature. However, we contend that this heuristic likely had minimal impact on our results. This assumption is based on the premise that the records imported into the screening software were predominantly irrelevant, and given that our active learning model prioritizes the presentation of records it classifies as most likely to be relevant, we posited that it was highly unlikely for a new relevant record to emerge after 111 records were screened. We recognize the arbitrariness of this cutoff and acknowledge that the ideal threshold may vary considerably, influenced by the volume of records retrieved from database searches and the complexity inherent to the research question and evidence base. For further discussion and a heuristic for determining a more nuanced stopping rule, we refer readers to the works of [5, 7, 39], and [40] who provide a comprehensive evaluation of this issue. Additionally, see Boetje and van de Schoot [6], for a practical and high-quality heuristic.
There is considerable potential for further research in this area. Our study presents a single case study, and the ease or difficulty of replicating a search could vary substantially across different systematic reviews. Importantly, this case study included the participation of one of the authors from the original systematic review. As one of the reviewers aptly notes, replicating a search without the involvement of the original systematic reviewers could present more challenges in practice. Additionally, it is worth considering that this researcher, while more experienced now, conducted the initial screening several years ago. This gap could have influenced both their perspective and recall of the specific topic, potentially impacting the results of our replication.
Focused on search reproduction, we have concerns regarding the PRISMA guidelines [30]. A key limitation we identified is that while the PRISMA guidelines mandate the reporting of full search strategies for all databases, they lack specificity on what constitutes a ‘full search strategy’. Often, authors limit their reporting to databases used and search terms, omitting critical details such as field codes, access platforms, and institutional access parameters. Reproduction becomes more challenging when thesaurus terms and searches without specific search fields are used, as both differences between access platforms and changes in the thesaurus can affect the retrieved records. These elements are vital for true reproducibility but are frequently overlooked, leading to challenges in replicating systematic reviews accurately. Moreover, the level of description of a “full search strategy” is open to interpretation and reporting of search strategies in systematic reviews is suboptimal (e.g., [4, 18, 21, 22]). So, while these guidelines provide a comprehensive checklist covering various sections of a systematic review manuscript, including the title, abstract, introduction, methods, results, discussion, and other information, they fall short of ensuring complete reproducibility. In theory, adherence to this checklist should guarantee transparency and reproducibility of the systematic review process. However, our findings indicate that this is not always the case in practice. Based on our study, we recommend that the next update of the PRISMA guidelines will comprise more extensive reporting of the search strategies, specifying platforms, institutional access, and field codes besides the search terms, but also storage of the search results and of the full labeled dataset of included and excluded records.
Further research could assess the balance between comprehensiveness and reproducibility. Certain searchable database fields will change more frequently than others; for example, the content and hierarchy behind thesaurus fields will be adapted more frequently than the content of title and abstract terms. Searching thesaurus fields may thus make a reproduction of a search more challenging, but using them is essential for a comprehensive search and, thus, for any systematic review. It might be useful to know which part of the discrepancies was due to each of the individual reasons: differences in institutional access, search strings not specifying search fields, changes in internal dictionaries over time, corrections of errors, retractions, and changes in indexing. With this type of knowledge, the development of initial searches, reporting of searches, and reproduction of searches could all focus on improving reproducibility without losing relevant records. Besides, it would be useful to assess the overlap between search engines. In the current case study, we only know that The Cochrane Library database did not retrieve relevant studies that were not covered by the other databases. It is advantageous to search fewer literature databases for efficiency but also search reproducibility. Again, this is a balancing act with comprehensiveness.
Moreover, it could be useful to conduct other types of simulation studies and compare the outcomes with each other. We decided to classify the relevant records found in the NLF procedure application as irrelevant, meaning we selected all noisy labels as irrelevant. Subsequently, we conducted only one simulation study in ASReview. Then, we compared multiple models and discovered that Naïve Bayes had the best model fit. A relevant topic for further study is to investigate the effect of prior knowledge on the outcomes of simulation studies. In ASReview Makita, this is possible using the ARFI template De Bruin [11, 12]. In this template, the effect of changing relevant records as prior knowledge could be investigated relatively easily, keeping irrelevant records as prior knowledge constant. If the outcome of particular simulation studies with specific relevant records as prior knowledge differs significantly from the other relevant records’ simulation studies, we could investigate why this difference exists and how these particular relevant records differ from the other relevant records. With this comparison, we could increase our understanding of the effect of prior knowledge of relevant records on simulation studies, ultimately improving the machine learning-aided screening process.
Furthermore, besides additional tests of the NLF procedure in other case studies, it may be helpful to investigate whether the NLF procedure can be used for different purposes. In short, the NLF procedure filters all noisy labels (in our case, all non-inclusions) into potentially relevant and irrelevant records. In our study, this was done to ensure we did not miss any additional relevant records that could be found using the reconstructed queries. However, this NLF procedure could potentially be used as a second check if the screening process did not miss any relevant records. Further research could, for example, focus on the question of how to double-check the initial screening process by using the NLF procedure for a single original review. And if it yields the discovery of one or more falsely-labeled records, it is relevant to investigate the effect of adding/deleting these records to the meta-analysis. Last, further research with additional case studies could result in a general guide on reproducing searches and conducting simulation studies without access to fully-labeled datasets. Our first thoughts are described in the next section.
A decision treeLastly, we introduce a Decision Tree in Fig. 4, which you can use to undertake a simulation study to assess the efficacy of active learning models for a labeled systematic review dataset. A simulation study necessitates an initially screened dataset, incorporating the titles and abstracts derived from the search and the labeling decision that emerges from the screening process. If such a dataset is readily accessible, you may commence the simulation study immediately. However, if the initially screened dataset is unavailable, reconstruction of the dataset using search queries, as demonstrated in our current study, is required. The prerequisites for employing this decision tree are as follows:
1. The full set of initial search terms per database must be obtainable;
2. The list of initially relevant records must be on hand;
3. Information regarding the number of results retrieved per database for each search query must be accessible;
Fig. 4
Once these prerequisites are met, one is well-positioned to commence the process of dataset reconstruction. This involves a systematic approach, meticulously following the steps detailed in the decision tree.
The first stage of this process is preparation, which involves gathering all necessary materials and ensuring that they are in the appropriate format for the reconstruction. This primarily includes obtaining the initial search terms for each database, the list of initially relevant records, and the number of results retrieved per database for each search query. The second stage is the actual reconstruction, where the data is recompiled based on the provided search queries. This step requires careful attention to detail and adherence to the guidelines outlined in the decision tree. Here, the importance of the initial search terms and the list of initially relevant records becomes evident as they serve as the foundation for the reconstructed dataset. The final stage involves the verification and validation of the reconstructed dataset. At this point, the reconstructed dataset is compared against the list of initially relevant records to ensure accuracy. Any discrepancies need to be identified and corrected to ensure the dataset’s integrity. The decision tree results in a dataset that accurately represents the initial dataset, enabling running simulation studies. We recommend caution: if the numbers differ by more than 5% from the original publication or if search queries generate errors, the reconstruction of the initial database might pose substantial risks.
Despite the inherent complexities and challenges, our decision tree for reconstructing systematic review datasets offers an exciting prospect for advancing active learning in this critical field. It paves the way for reducing the labor intensity of systematic reviews, thereby potentially accelerating the production of high-quality research. As we continue to refine and evolve this methodology with further studies and use cases, we anticipate that our contributions will significantly enhance the efficiency and efficacy of future systematic reviews.
Generative AI usageDuring the preparation of this work, the authors used Grammarly to improve the language and readability but did not generate any IP with these tools. After using these tools, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
Open science statements: data, and code availabilityThe datasets supporting the conclusions of this article are available in the Open Science Framework repository [27], https://doi.org/10.17605/OSF.IO/PJR97.
1.Reconstruction
In the document’ reconstructed_data_after_reproducting_search_queries.ris’, the list of records after exporting but before deduplication can be found. In other words, these are the data after exporting the relevant search queries, without having performed any correction yet.
In the document ‘reconstructed_data_after_quality_check_2.ris’, the reconstructed data have been adjusted following the steps’ quality check 1, deduplication, and quality check 2’. This means the data are deduplicated, and the initially relevant records are labeled so (‘ASReview_relevant’) and all the other records – the noisy labels – are labeled as ‘ASReview_not_seen’ (by the ASReview datatools script referred to in the paper.)
2.Applying NLF procedure
The document’ nlf_procedure_test_trimbos.asreview’ can be opened in ASReview. The NLF procedure was performed in ASReview, and the ASReview file was exported.
In the document ‘reconstructed_data_after_NLF_procedure.ris’, following the results of the NLF procedure, all noisy labels were labeled as irrelevant. Now the relevant records are labeled as ‘ASReview_relevant’ and the irrelevant records are labeled as ‘ASReview_irrelevant’.
3.Simulation
In the folder ‘Simulation_Makita’, all relevant data concerning the simulation study can be found. For example, one can see the list of records used, the ASReview statistics, and a graph in which different simulation study modes can be compared.
Comments (0)