
Remember me
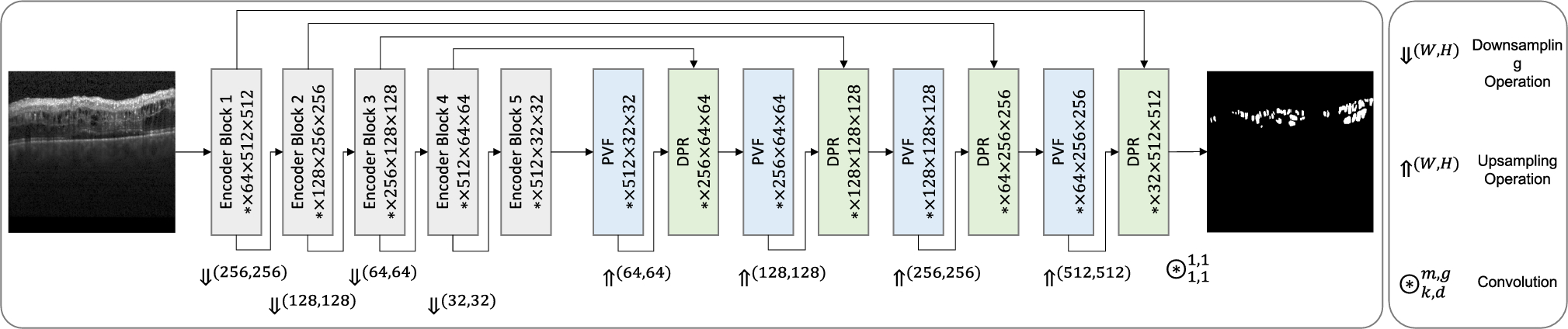


The proposed visualization framework is evaluated through a user study using the Cholec80 dataset [7]. In addition to the user study, we use our framework to analyze splits of five popular datasets for the surgical phase and instrument recognition tasks, highlight problematic cases, and propose optimized splits.
User studyIn total, ten participants with data science background have been recruited to participate in the evaluation study of the proposed visualization framework. After a brief introduction into the domain of surgical phase recognition and the features of the proposed application, the participants were asked to solve ten tasks covering a wide range of possible exploratory analyses that can arise during the preparation of Cholec80 dataset [7]. Further details on the user study are provided in the supplementary information. To measure the results of this study, task completion percentage was used, which has the value of 1 only if the participant solves the task correctly, 0 otherwise. Overall, the majority of the tasks were completed successfully by \(\ge 80\%\) of participants.
After completing the tasks, the participants were asked to fill out the System Usability Scale (SUS) [33] questionnaire. It consists of ten statements that the study participants ranked on a 5-point Likert scale ranging from 1 (strongly disagree) to 5 (strongly agree). The ranking of the statements is then used to calculate the SUS score which expresses the usability of the system. The value of the score ranges between 0 and 100, with higher values expressing better usability. The proposed application reached the SUS score of 81.25.
Analysis of dataset splitsIn order to validate the proposed framework, we perform analysis of various dataset splits for the Cholec80 [7], CATARACTS [10], CaDIS [34], as well as the M2CAI workflow and tool datasets [7, 35] using our visualization framework, report our observations, and propose improvements in the dataset splits. The datasets represent a diverse selection of surgical procedures, workflows, surgical instruments, dataset splits, as well as annotation and data types.
Analysis of the Cholec80 datasetFor the analysis of the Cholec80 dataset splits, we chose the three most common Cholec80 splits [15]. We downsampled phase annotations of the Cholec80 dataset to 1 fps to obtain frames with both phase and instrument labels.
40/-/40 split
In the 40/-/40 split, which is used in the studies [7, 36], all surgical phases are represented in both sets. However, a closer inspection of phase transitions unveils a group of nine surgeries (10, 13, 19, 22, 23, 29, 32, 33, 38) that deviate from the standard workflow by skipping the first phase and initiating the surgery directly in the second phase (see Fig. 4A). Notably, all of the nine surgeries are assigned to the training set; therefore, the evaluation of the model’s performance on the test set does not include this special workflow. In addition, another unique workflow that only occurs in three surgeries (12, 14, 32) in the training set can be identified using the proposed visualization (see Fig. 4B). After the Gallbladder packaging phase, these three surgeries move on to the Gallbladder retraction, thus omitting the Cleaning coagulation phase. Subsequently, the surgeries return to the previously skipped Cleaning coagulation phase which is also the final phase of the three surgeries. Since this unique sequence of phases only appears in the training set, they are not included in the evaluation of the machine learning model. Proposed improvement: With this information at hand, the split can be optimized by re-assigning the surgeries 29, 32, 33, and 38 to the test set, as interactively determined in our tool. Accordingly, four randomly selected surgeries 58, 66, 71, 78 from the test set are assigned to the training set to retain the 40/-/40 split. As a result of this re-partition, the aforementioned cases of phase transitions now also appear in the test set.
Regarding the instrument use, the proposed visualization shows that all of the individual instruments are represented in all sets and also follow similar distributions. Nevertheless, there are several instrument combinations that do not occur in one of the sets (see Fig. 4C). However, these instruments combinations mostly represent rare cases, as they account for only a small fraction of the dataset and appear in single surgeries.
Fig. 4
Characteristics and shortcomings of the 40/-/40 split of the Cholec80 dataset [7]. Surgeries starting in the Calot triangle dissection phase are only present in the training set (A). The ending sequence Gallbladder retraction to Cleaning coagulation occurs only in the training set (B). The instruments Bipolar and Scissors co-occur only in the training set (C)
32/8/40 split
To perform model selection or hyperparameter search, studies [11, 25, 37] use eight surgeries from the training set for validation, resulting in a 32/8/40 split [15]. This split yields sufficient representation of phases across sets. However, surgeries from the validation set have fewer frames on average (\(\approx \) 1900 frames) than the training and test sets with \(\approx \) 2200 and \(\approx \) 2500 frames, respectively (see Fig. 5A). Especially, the disparity between the average duration of surgeries from the validation and test set (\(\approx 10\) min) might affect the performance estimation on these sets. As the surgery duration can indicate its complexity, the surgeries from the validation set may be easier to infer.
Similar to the 40/-/40 split, the surgeries skipping the first phase are found exclusively in the training and validation sets. Besides, the 32/8/40 split entails reduction in the training set size. This becomes especially apparent in case of two phase transitions (Gallbladder dissection, Cleaning coagulation) and (Cleaning coagulation, Gallbladder packaging) as they are reduced from three occurrences to just a single occurrence in the training set, as opposed to two and nine occurrences in the validation and test set, respectively (see Fig. 5B). This will presumably hinder the generalization of the model. Proposed improvement: This can be solved with our tool by re-assigning the surgery 14 to the validation set, surgeries 23, 29, 32 to the test set, and surgeries 37, 41, 57, 60 to the training set. Regarding the instruments, the co-occurrences of surgical instruments that are missing in one of the sets are more prevalent in this split due to the additional validation set. One considerable example is the simultaneous use of Grasper, Bipolar, and Irrigator occurring in 503 frames in the training set and in 154 frames in the test set (see Fig. 5C).
Fig. 5
Characteristics and shortcomings of the 32/8/40 split of the Cholec80 dataset [7]. Surgeries from the validation set have fewer frames on average, compared to the training and test sets (A). The phase transitions (Gallbladder dissection, Cleaning coagulation) and (Cleaning coagulation, Gallbladder packaging) occur only once in the training set (B). The simultaneous occurrence of the instruments Grasper, Bipolar, and Irrigator is not represented in the validation set (C)
40/8/32 split
Instead of setting aside eight surgeries from the training set, some studies [11, 38] select eight surgeries from the testing set for validation, thus creating a 40/8/32 split. In this split, all phases as well as single instruments are present in all sets and also follow similar distributions. Similar to the original 40/-/40 split, surgeries starting in the Calot triangle dissection phase are exclusive to the training set. Furthermore, the three surgeries that move on from Gallbladder packaging to Gallbladder retraction and end in the Cleaning coagulation phase are also found only in the training set. Proposed improvement: This particular issue can be addressed by moving the surgeries 14, 33, 38, 57 to the validation set, the surgeries 23, 29, 32 to the test set, and the surgeries 43, 46, 47, 48, 60, 70 to the training set to retain the 40/8/32 split.
Compared to the 32/8/40 split, the validation set holds a larger amount of frames, thus resulting in a better coverage of various cases (see Fig. 6A). Furthermore, the phase transitions (Gallbladder dissection, Cleaning coagulation) and (Cleaning coagulation, Gallbladder packaging) now appear three times in the training set, thus providing more samples for the training of the model (see Fig. 6B). Considering the co-occurrence of instruments, an improvement over the 32/8/40 split can be observed, as the combination of Grasper, Bipolar, and Irrigator now also appears on 47 frames in the validation set (see Fig. 6C).
Fig. 6
Characteristics of the 40/8/32 split of the Cholec80 dataset [7]. Surgeries from the validation set contain more frames on average than surgeries from other sets (A). Furthermore, this split provides a better coverage of the phase transitions (Gallbladder dissection, Cleaning coagulation) and (Cleaning coagulation, Gallbladder packaging) in the training set, compared to the 32/8/40 split (B). The combination of Grasper, Bipolar, and Irrigator appears in all sets (C)
Analysis of the CATARACTS datasetThe CATARACTS dataset [10] provides annotations of steps which describe the surgical procedures at a more fine-grained level compared to surgical phases. Since each step of the CATARACTS dataset is preceded by an Idle step, we exclude this step from the analysis to obtain a linear workflow. In the following, we inspect the suggested 25/5/20 split [10].
The inspection of the visualizations reveals that all steps are present in the training, validation, and test set. Particularly, even steps that are rare and appear only in 3 out of 50 surgeries are included in all dataset splits. Phase transitions that appear frequently prominently stand out in the visualizations. However, upon closer inspection, numerous rare transitions that are exclusive to single surgeries can be also identified. Furthermore, most of the surgeries start in the Incision step while two surgeries, one from the training and one from the test set, start in the Toric Marking step and consequently proceed to the Incision step.
Reviewing the occurrence of surgical instruments, it becomes apparent that the instruments Mendez ring and Vannas scissors generally do not appear in the test set (see Fig. 7A). Furthermore, Cotton is not used in the validation set and only rarely appears in the test set (see Fig. 7A). Proposed improvement: To achieve a better representation of Cotton across sets, we interactively re-assign the surgery 35 from the training to the validation set and surgery 14 from the validation to the training set. By performing these actions, we ensure that Cotton is also represented in the validation set (see Fig. 7B).
Fig. 7
Individual instrument occurrence and the co-occurrences of the CATARACTS dataset [10] (A). Mendez ring, Vannas scissors, and Cotton are not represented in one of the sets. Individual instrument occurrence and the co-occurrences after the suggested re-partitioning to ensure that Cotton also appears in the validation set (B). The widths of the radial bar charts are scaled per each individual instrument for better visibility
Analysis of the CaDIS datasetThe CaDIS dataset [34] consists of 25 surgeries from the training partition of the CATARACTS dataset [10] that have been annotated with the segmentation masks of anatomical structures and surgical instruments. We convert the segmentation masks of surgical instruments from the Task III of the original publication [34] into binary frame-wise annotation format that is required by the visualization application. Furthermore, we follow the suggested dataset split that has been specifically designed such that all instrument classes are similarly distributed across dataset splits.
The application reveals that all individual instrument parts are indeed present in all dataset splits (see Fig. 8). Nevertheless, when examining the co-occurrences of instruments, several instrument combinations that are unrepresented in one of the sets can be identified. Particularly, several instrument combinations are exclusive to the training set. For instance, the combination of Capsulorhexis Cystotome and Bonn Forceps only appears in two surgeries with the IDs 19 and 20 from the training dataset. Proposed improvement: To reduce the number of unrepresented co-occurrences, the surgery 19 should be moved to the validation set, surgery 21 to the test set, and surgeries 7 and 2 to the training set. Other instrument combination from the training set are unique to individual surgeries; therefore, this issue cannot be mitigated by a re-partition on a surgery basis.
Fig. 8
Visualization of individual instrument occurrence and the co-occurrences of the CaDIS dataset [34]. The combination of instruments Capsulorhexis Cystotome and Bonn Forceps appears exclusively in the training set
Analysis of the M2CAI-workflow datasetThis dataset has been introduced as part of the M2CAI EndoVis challenge 2016 and provides surgical phase annotation for a total of 41 cholecystectomy surgeries [7, 35]. For the analysis of the dataset, we downsample the annotations to 1 fps and use the dataset split that has been used in the challenge.
The visualizations reveal that all eight phases are represented across splits (see Fig. 9). Besides, the majority of the phase transitions occur in both training and test sets. Nevertheless, the visualization also uncovers four phase transitions that are rare and appear exclusively in the test set. These four transitions are particularly conspicuous as they skip multiple sequential phases and therefore might indicate aberrant surgical courses. Upon filtering of surgeries that contain the aforementioned transitions, it becomes evident that these surgeries generally follow unique workflows. The surgery 3 initially follows a linear workflow, starting from the first phase Trocar placement, consequently moving on to the Preparation, and then, it abruptly ends after the third phase Calot triangle dissection skipping five succeeding phases. Similarly, the surgeries 1 and 11 from the test set adhere to the conceptual order of the phases for the first five phases and then finish in the Gallbladder dissection, thus omitting the phases Gallbladder packaging. Cleaning coagulation, and Gallbladder retraction. Proposed improvement: By moving the surgery 11 from the test set to the training set and a randomly selected surgery 10 from the training set to the test set, this workflow is now represented in both training and test sets.
Fig. 9
Visualization of phase occurrences and transitions from the M2CAI-workflow dataset [7, 35]
Furthermore, the proposed application shows that procedures from the test set are on average nine minutes shorter than the training counterpart. If the duration of the procedure indicates its overall complexity, it can be assumed that the evaluation on this test set might yield overly optimistic results.
Analysis of the M2CAI-tool datasetThe M2CAI-tool dataset [7, 35] has been introduced as part of the M2CAI EndoVis challenge 2016 and provides binary instrument annotations of 15 surgeries. For the analysis of the dataset, we follow the suggested split of 10/-/5 [35]. The visualizations show that all individual instruments are included in the training and test sets (see Fig. 10A). With respect to the instrument combinations, there are four combinations that appear exclusively in one of the sets and are unique to a single surgeries. Further three combinations are heavily imbalanced, for instance, the combination of Grasper, Irrigator, and Specimen bag with 126 frames in training set and a single frame in the test, or the combination of Bipolar and Irrigator with a single frame in the training set and 28 frames in the test set. Proposed improvement: By switching the surgeries 6 and 14, the distribution of instrument combinations across dataset splits can be significantly improved (see Fig. 10B). The combination of Grasper, Irrigator, and Specimen bag is now split into 87 and 40 frames in the training and test set, respectively.
Fig. 10
Visualization of the instrument usage of the M2CAI-tool dataset [7, 35]. Several instrument co-occurrences, e.g., Grasper, Irrigator, and Specimen bag, are not well distributed across the training and test, appearing only on one frame in the test set (A). By swapping two surgeries, these co-occurrences show an improved distribution across sets (B)
Summary of unrepresented casesTable 1 shows dataset splits of the five datasets as well as the number of phase transitions, and instrument combinations that are not represented in one of the sets. The improved dataset splits that are presented as part of this work are denoted with *.
Table 1 Number of phase transitions, instrument co-occurrences, and individual instruments that are unrepresented in one of the sets and were discovered using the proposed visualization framework. Improved splits proposed as part of this work are indicated with *
Comments (0)