
Remember me
Lung cancer is the leading cause of cancer deaths among both men and women (1), representing approximately 25% of cancer deaths each year (2). Lung cancer is divided into two main histological subtypes: small-cell lung cancer (SCLC) and non-small cell lung cancer (NSCLC). NSCLC constitutes approximately 85% of all lung cancer cases and is the focus of our study. The treatment landscape of NSCLC is rapidly evolving due to progress in biomarker-driven targeted therapies. Mutations in 11 genes (EGFR, KRAS, ALK, ROS1, BRAF, NTRK1, NTRK2, NTRK3, MET, RET, ERBB2) have been reported as FDA-recognized biomarkers predicting patients’ response to targeted therapies. Similarly, IHC (Immunohistochemistry) quantified PD-L1 (CD274) expression, microsatellite instability, and Tumor Mutation Burden (TMB) have been used in clinical settings to assess whether NSCLC patients could benefit from Immune Checkpoint Inhibitor (ICIs) (Table S1A).
Biomarkers are being used at an ever-increasing rate to predict disease risk, prognosis, and treatment response. Several national and international efforts have been established to standardize and catalogue disease biomarkers. BEST (Biomarkers, EndpointS, and other Tools), a joint task force between the FDA and NIH, was formed to standardize biomarker definitions in different contexts of clinical use (3). The EDRN (Early Detection Research Network) catalogues biomarkers that may improve detection of early-stage cancers (4). The Pharmacogenomics Knowledgebase (PharmGKB) curates the impact of genetic variation on drug response and catalogues pharmacogenetic biomarkers (5). The FDA regulates and catalogues pharmacogenomic biomarkers in drug labeling (6). Resources such as OncoKB, COSMIC, ClinVar, and ICGC (incorporating TCGA and Cancer Genome Project data) provide prevalence information and clinical significance assertions for genetic biomarkers in cancer (7–10). The My Cancer Genome from Vanderbilt University (11) offers an integrative database summarizing the potential clinical impact of genetic as well as protein expression and genomic instability biomarkers. Similarly, TCIA (The Cancer Imaging Archive) and IBSI (Imaging Biomarker Standardization Initiative) were formed to curate and standardize image biomarkers (12, 13). Professional societies such as the NCCN (National Comprehensive Cancer Network), ESMO (European Society for Medical Oncology), ASCO (American Society of Clinical Oncology), CAP (College of American Pathologists), IASLC (International Association for the Study of Lung Cancer), and AMP (Association for Molecular Pathology) provide clinical guideline recommendations for disease biomarker testing to help improve diagnosis and selection of targeted therapies.
These important efforts contribute to improving the delivery of personalized treatment decisions. Advancements in targeted treatments in the last 20 years have improved survival of NSCLC patients with actionable biomarkers (14). However, the long-term survival rate of NSCLC is still poor with an overall relative 5-year survival rate of less than 20% (15). Clinically utilized biomarkers for NSCLC were identified using traditional statistical approaches and are currently assumed to be mutually exclusive in therapeutic decision-making. However, there is growing evidence showing that actionable biomarkers of NSCLC can co-occur within the same patient’s tumor (16–18) and it is crucial to evaluate both linear and non-linear effects of the disease biomarkers. In this regard, machine learning algorithms promise more flexible model building and the ability to recognize non-linear, complex patterns in high dimensional datasets. Notably, several AI/ML-enabled medical devices have been FDA-approved and are being used in clinical settings for automated tissue segmentation (i.e., the use of computer algorithms to identify and distinguish different structures within medical images) and feature extraction (i.e., identification of specific patterns from the medical images to aid in diagnosis) from lung CT (Computed Tomography) images (19). Similarly, several deep learning approaches have been developed to aid whole slide image analysis (20, 21) and promise to enable enhanced performance in digital pathology workflows.
Overall, machine learning algorithms have made noteworthy contributions to NSCLC diagnostic workflows and promise growing applications in biomarker discovery. In this study, we sought to evaluate trends in AI/ML applications in NSCLC biomarker research. Using a text-mining approach, we identified 215 studies that reported potential biomarkers of NSCLC using AI/ML algorithms. We catalogued these studies with respect to BEST (3) biomarker sub-types and summarized emerging patterns and trends in AI/ML-driven NSCLC biomarker discovery We emphasize that our focus in this study was to compile potential use-cases for AI/ML in NSCLC biomarker research. Therefore, we did not capture the model performance metrics of the studies we reviewed, nor did we appraise the validity of the prediction models. For quantitative sources on AI/ML model appraisal, we recommend the readers to refer to guidelines such as CHARMS (22), MLP-BIOM (23), TRIPOD (24), and PROBAST (25).
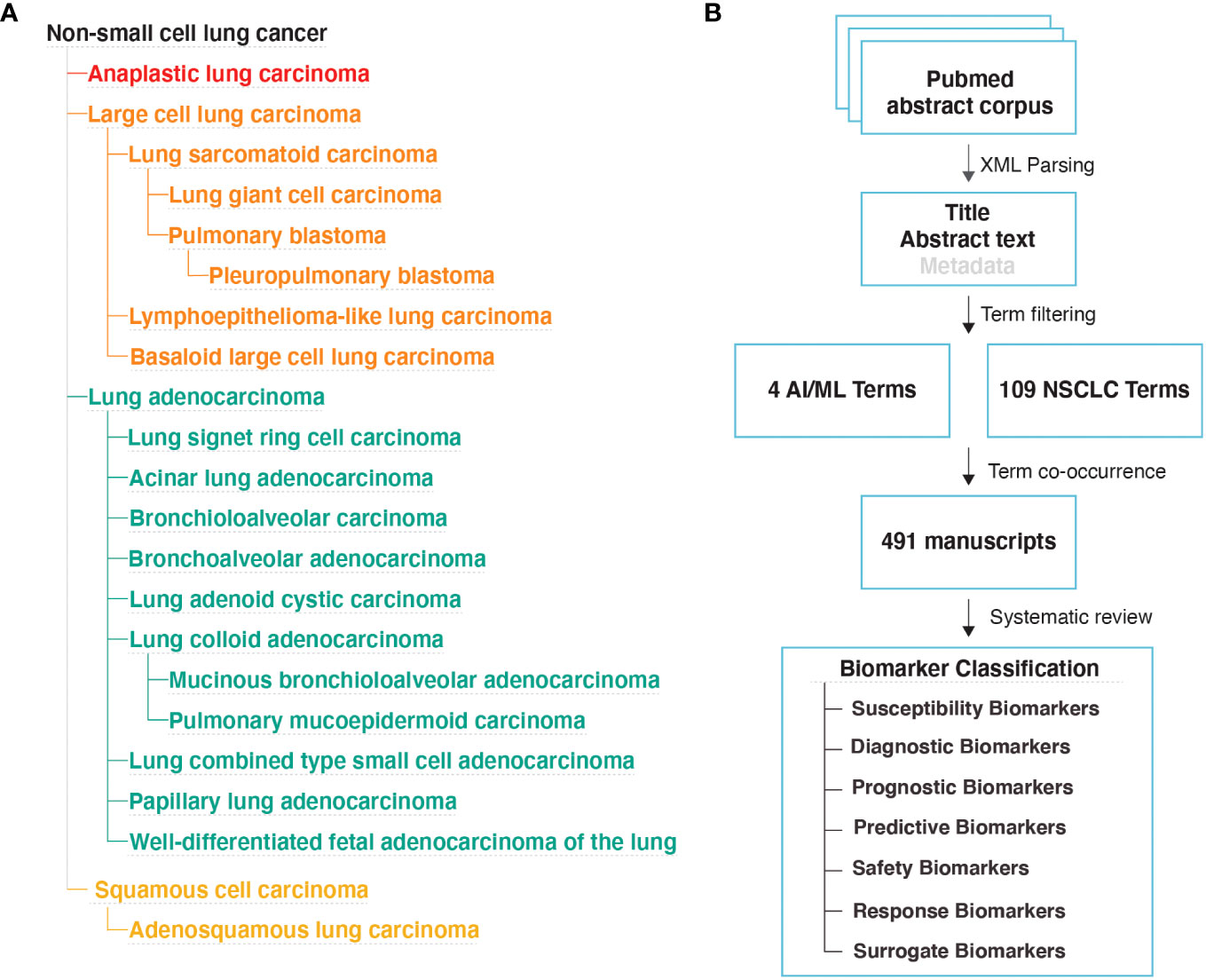
MethodsNSCLC termsWe downloaded the EMBL-EBI Experimental Factor Ontology (EFO) (26) obo file on April 28th, 2022. We extracted all disease IDs under the EFO:0003060; non-small cell lung cancer disease category. A total of 22 NSCLC sub-types (Figure 1A) and 85 additional synonymous disease IDs were present in the EFO dataset, which collectively formed the NSCLC terms category (Table S1B).
Figure 1 Literature Review Methodology (A) NSCLC disease subtypes based on the EMBL-EBI Experimental Factor Ontology (EFO) database. (B) Study design used to identify manuscripts that implemented AI/ML algorithms to discover new biomarkers for NSCLC.
AI/ML termsWe used the following four terms to represent the AI/ML terms category: machine learning, artificial intelligence, deep learning, neural network.
Text mining strategyWe downloaded MEDLINE/PubMed abstracts in xml format from the National Library of Medicine on May 4th, 2022. We used custom Python scripts to extract PubMed IDs from abstracts that include at least one of the NSCLC and at least one of the AI/ML terms. This approach (Figure 1B) identified a total of 491 articles that likely contain the findings of AI/ML studies on NSCLC.
Literature review approachWe reviewed each of the 491 manuscripts and excluded 31 manuscripts that were not classified as a research article or were not written in English. We evaluated the remaining 460 manuscripts and identified 215 that reported AI/ML models that were developed to identify NSCLC biomarkers.
Specifically, we required that the models incorporated at least one data type aligning with the BEST Glossary (3) biomarker definition (i.e., a molecular, histologic, radiographic, or physiologic characteristic that is measured as an indicator of normal biological processes, pathogenic processes, or biological responses to an exposure or intervention). Across the 215 studies, we were able to categorize biomarker data types into four broad groups: (i) Molecular Biomarkers (e.g., gene expression, genotype, DNA methylation), (ii) Histologic Biomarkers (e.g., Whole Slide Image, Cytology microphotographs), (iii) Radiologic Biomarkers (e.g., Computed Tomography (CT), Magnetic Resonance Imaging (MRI), PET/CT (Positron Emission Tomography/Computed Tomography)), and (iv) Multimodal Biomarkers (i.e., a combination of different modes or types of data).
We also required that the outcome of the AI/ML models can be categorized under one of the following seven biomarker categories: (i) Susceptibility/Risk, (ii) Diagnostic, (iii) Prognostic, (iv) Predictive, (v) Response, (vi) Safety, and (vii) Surrogate. The first six biomarker categories were defined based on the BEST Glossary (3) definitions. The last biomarker category, Surrogate Biomarkers, were defined as biomarkers that were not directly measured but were inferred using AI/ML applied to other, often less invasive, patient data (Figure 1B; Please see Box 1. Glossary, for Biomarker category definitions).
Box 1. Glossary of biomarker types.
Descriptions of the Susceptibility/Risk, Diagnostic, Prognostic, Predictive, Response, Safety biomarkers were retrieved from the BEST (Biomarkers, EndpointS, and other Tools) Resource (3). BEST defines a biomarker as a defined characteristic that is measured as an indicator of normal biological processes, pathogenic processes, or responses to an exposure or intervention, including therapeutic interventions. Molecular, histologic, radiologic, or physiologic characteristics are types of biomarkers. *Biomarkers that predict histological disease subsets were included under the “Diagnostic Biomarkers” category. Biomarkers that predict molecular or potential molecular subsets were included under the “Surrogate Biomarkers” category.

The risk of developing a complex disease is explained by a combination of genetic and environmental factors. For NSCLC, cigarette smoking is the number one environmental risk factor with smokers being 15-30 times more likely to develop NSCLC than non-smokers (27). Among non-smokers, NSCLC is observed significantly more frequently in females than males, suggesting sex is a risk factor beyond cigarette smoking (28). Exposure to asbestos, radon, or other pollutants have also been reported as environmental risk factors of NSCLC (29). While NSCLC is considered a disease of the elderly with a median patient age of 70 at diagnosis, a subset of NSCLC patients (1-10%) are diagnosed at younger ages (<40 years) (30), indicating potential germline or distinct somatic driver mutations may be present in different patient age groups. Genome-wide association studies focusing on germline genetic variants have reported 16 independent loci associated with risk of developing NSCLC (31) (Table S1C). Polygenic risk score models based on the collective effect of these germline genetic variants were shown to successfully predict NSCLC risk beyond age and smoking years (32). While somatic genetic variants are important biomarkers used in selection of targeted therapies, they are not suitable for NSCLC risk assessment, as accessing lung tissue samples cannot be justified for routine risk assessment purposes. Similarly, using non-invasive genetic approaches such as circulating tumor DNA (ctDNA) sequencing is not suitable for risk prediction because ctDNA is at low concentrations even in early-stage cancers (33).
Susceptibility/Risk Biomarkers are defined as biomarkers that indicate the potential for developing a disease or medical condition in an individual who does not currently have clinically apparent disease or the medical condition (3). Using our approach (Figure 1B), we found that machine learning studies focused primarily on integrating behavioral risk factors, family history, and environmental factors into NSCLC risk modeling. We found only one study that applied ML to identify biomarkers that could be used for NSCLC risk prediction (34) (Table S1D). In this study, Umu et al. reported that ML models of circulating serum RNA levels can predict NSCLC risk 6-8 years before manifestation of disease symptoms and provided evidence that feature selection approaches (i.e., selecting the most discriminative variables while eliminating the redundant or irrelevant variables; please see Pudjihartono et al. (35) for a summary on feature selection algorithms) and histology-specific data subsets may enhance model performance metrics [for model performance metrics including accuracy, recall, specificity, precision, F1-score, please see Hicks et al. (36)].
AI/ML-derived diagnostic biomarkers of NSCLCEarly symptoms of NSCLC including shortness of breath, fatigue, coughing, and loss of appetite are often mistaken for other conditions due to their non-specific nature. The US Preventive Services Task Force recommends annual risk screening using low-dose CT for high-risk individuals who are between 50 and 80 years old and have at least a 20-pack-year smoking history (37). However, despite these efforts approximately 55% of NSCLC patients present with locally advanced or metastatic disease at the time of diagnosis (38). When NSCLC is suspected, the initial evaluation is performed using imaging tools including chest X-ray, CT, or PET/CT scan. Diagnosis requires histological confirmation using tissue samples stained with Hematoxylin and Eosin (H&E). When tissue morphology is insufficient for proper classification, immunohistochemistry (e.g., TTF-1, Napsin A, CK7, P63, CK5/6) is recommended to aid differential diagnosis (39). While molecular testing of somatic mutations could contribute to diagnosis of NSCLC, current use cases of such testing are primarily limited to informing the treatment plans of already diagnosed patients.
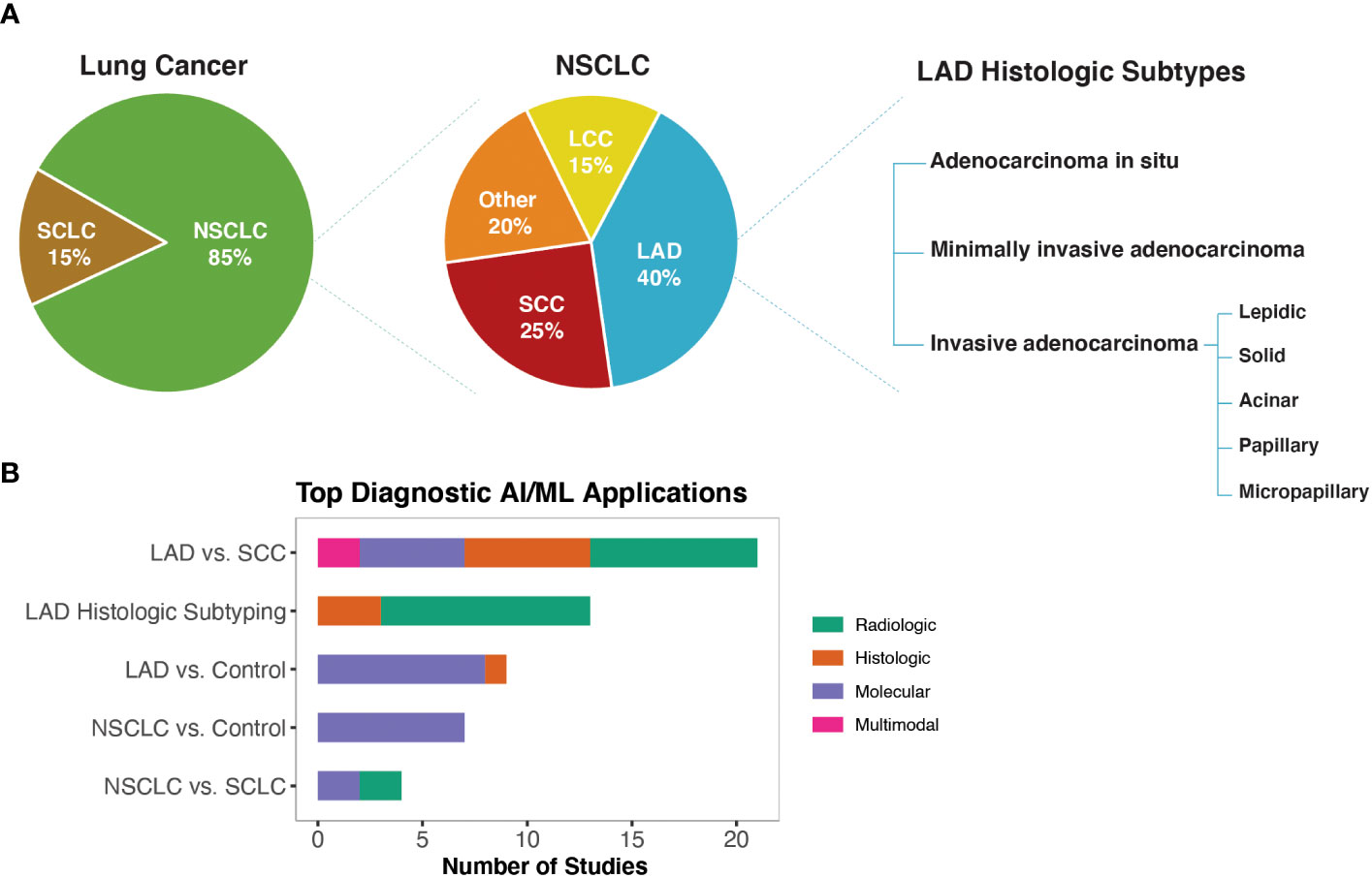
Diagnostic biomarkers are defined as biomarkers that are used to detect or confirm the presence of a disease or condition of interest or to identify individuals with a subtype of the disease (3) (Figure 2A). Using the approach shown in Figure 1B, we identified 69 studies that used machine learning approaches to identify potential diagnostic biomarkers of NSCLC (Table S1E). Overall, most diagnostic efforts concentrated around building models that could be used to distinguish the two most common histological subtypes of NSCLC; lung adenocarcinoma (LAD) and squamous cell carcinoma (SCC) (41–61). Additionally, several studies have reported AI/ML models and proposed biomarkers that could be used to distinguish NSCLC or LAD from healthy control/non-malignant samples (43, 53, 59, 62–74), as well as for differential diagnosis of NSCLC and SCLC (75–78) (Figure 2B).
Figure 2 AI/ML Applications for Diagnostic Biomarker Discovery (A) Lung cancer, NSCLC, and LAD histologic subtypes, respectively. Subtype frequencies were retrieved from Schabath et al. (40) (B) Bar graph of the top five model outcomes/topics where AI/ML algorithms have been developed to identify potential diagnostic biomarkers for NSCLC. Color coding indicates the broad biomarker data type used in these studies (i.e., Molecular, Histologic, Radiologic, Multimodal data types). The acronyms are as follows: SCLC, Small Cell Lung Cancer; NSCLC, Non-Small Cell Lung Cancer; LAD, Lung Adenocarcinoma; SCC, Squamous Cell Carcinoma; LCC, Large Cell Carcinoma.
A body of literature has reported diagnostic AI/ML models leveraging CT or PET/CT radiologic datasets (Table S1E). These studies primarily used radiomics or CNN (Convolutional Neural Network)-based approaches to extract image features. Radiomics-based approaches are often criticized for having high variability due to use of manual/semi-automatic tumor segmentation techniques as well as for relying on pre-defined mathematical equations/hand-crafted features. Unlike radiomics-based approaches, CNN-based study designs often build end-to-end algorithms that automate the tissue segmentation, feature extraction, and classifier training steps. Although CNNs offer the potential to reduce human introduced bias, they require larger training datasets compared to radiomics-based approaches and offer less interpretability. In this regard, we identified several studies that integrated radiomics and CNN-based approaches to improve model prediction accuracy while providing clinical interpretability (52, 79–82).
Histology-based diagnosis of NSCLC subtypes can be complex as visual inspections by pathologists are prone to subjective assessments and may result in different interpretations. CNNs trained on H&E-stained Whole Slide Images (WSIs) have shown encouraging results for automated differential diagnosis of LAD vs. SCC as well as for histologic subtyping of LAD growth patterns (60, 83, 84). Despite these efforts, challenges related to the interpretability of CNN-based classifiers as well as computational constraints of high-resolution WSI datasets continue to be obstacles to their widespread clinical utility. Deep feature visualization (i.e., the process of generating visual representations of the features learned from deep neural networks) and resolution-based knowledge distillation (i.e., an approach to transfer knowledge from a high-resolution neural network to a smaller lower-resolution one) were among the emerging approaches to improve interpretability and computational feasibility of deep learning solutions for digital pathology (67, 85).
Molecular biomarkers, in particular somatic driver mutations, are increasingly being used to guide treatment plans for NSCLC patients. Molecular testing of tumor tissue biopsies is currently the gold standard practice to identify actionable molecular biomarkers, but the invasive nature of this process limits its use in routine diagnostic screening. Emerging non-invasive liquid biopsy tests also have limited applications for routine diagnostic screening, as ctDNA is at low concentrations in early-stage cancers (33). An ideal diagnostic biomarker requires low invasiveness and easy detection to allow early diagnosis. However, we found that ML studies that leveraged molecular biomarkers for diagnostic purposes have mainly used genome-wide gene expression data derived from lung tissue. A recurrent finding from these studies was that non-coding RNA expression signatures could differentiate NSCLC/LAD tissue from normal tissue (43, 59, 72, 73). Recapitulating known biology, ML algorithms that used lung gene expression levels to distinguish LAD vs. SCC have reported TP63, a known IHC marker for differentiating LAD vs. SCC, as well as several keratin-related genes (e.g., KRT5, KRT6A, KRT14, SERPINB13) among the top discriminative features (i.e., top attributes impacting model’s ability to differentiate between different classes) (48, 56). In liquid biopsy-based diagnostic studies, gene-expression signatures from tumor-educated platelets and small extracellular vesicles as well as cfDNA (cell-free DNA) fragmentation patterns (DELFI score; proportion of short (100-150 bp) to long (86–155) cfDNA fragments) were reported as potential biomarkers for NSCLC diagnosis (63, 68, 76).
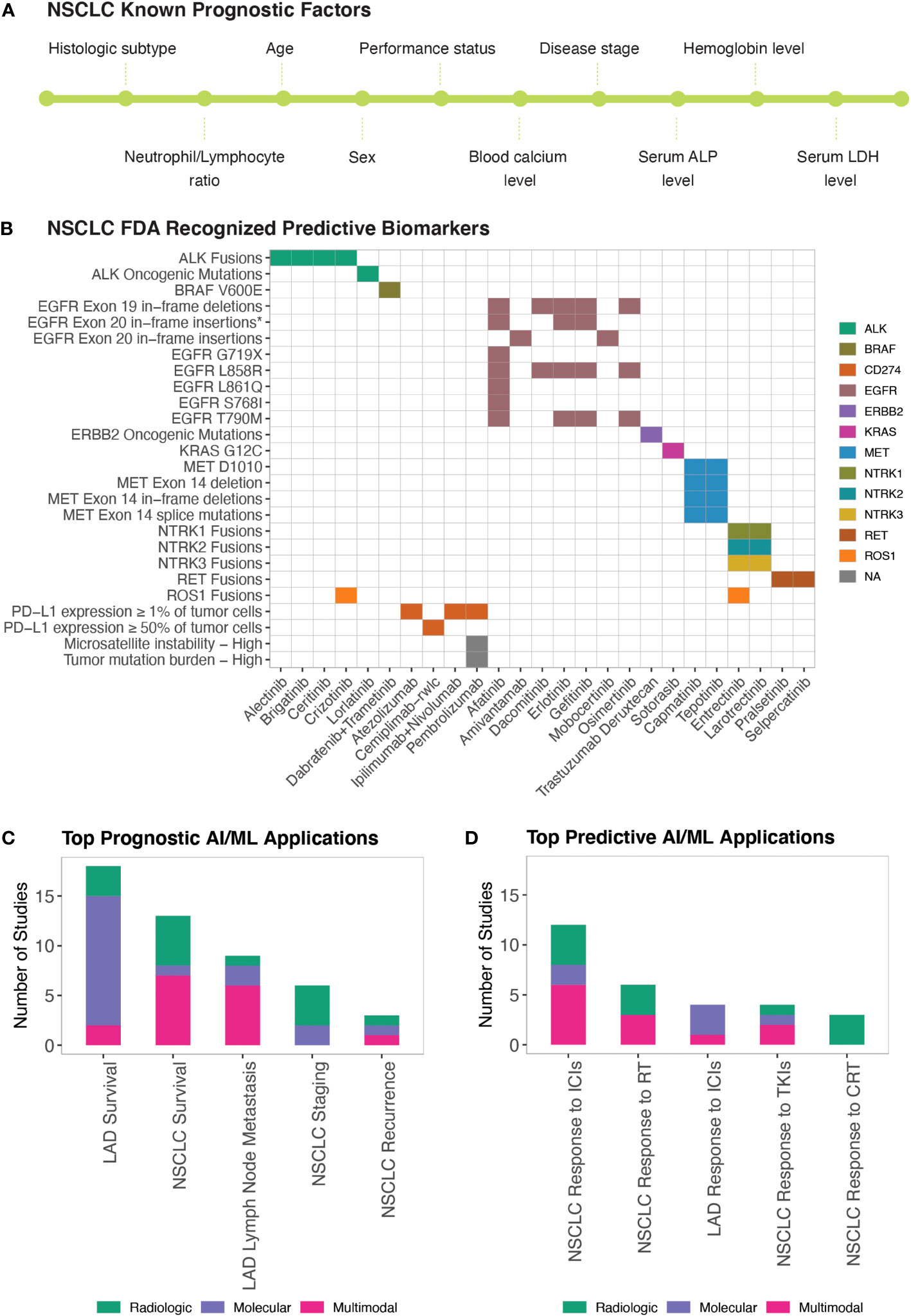
AI/ML-derived prognostic biomarkers of NSCLCNSCLC prognosis has been correlated with several clinical and demographic parameters including but not limited to the histologic subtype, disease stage, patient performance status, age, sex, blood hemoglobin and calcium levels, blood neutrophil-to-lymphocyte ratio, and serum lactate dehydrogenase and alkaline phosphatase levels (87, 88) (Figure 3A). Disease prognosis as well as the therapeutic options for NSCLC also depend on the molecular biology of the tumor (87) (Figure 3B). Similarly, Minimal Residual Disease (MRD) (i.e., small number of cancer cells that may remain in the body after cancer treatment and even when patient is in remission) levels have recently started being used in predicting NSCLC relapse risk (89).
Figure 3 AI/ML Applications for Prognostic and Predictive Biomarker Discovery (A) Commonly studied prognostic factors of NSCLC. LDH and ALP stand for Lactate Dehydrogenase and Alkaline Phosphatase, respectively. (B) FDA-approved Predictive Biomarkers for Non-Small Cell Lung Cancer. Gene, drug names, and biomarkers were retrieved from the Table of Pharmacogenomic Biomarkers in Drug Labeling (6) in December, 2022. The list of ALK and ERBB2 oncogenic mutations is included in Table S1A. *EGFR Exon 20 in-frame insertions (excluding A763_Y764insFQEA) are drug resistance biomarkers for Erlotinib; Gefitinib; Afatinib. (C) Bar graph of the top five model outcomes/topics where AI/ML algorithms have been developed to identify potential prognostic biomarkers for NSCLC. Color coding indicates the broad biomarker data type used in these studies (i.e., Molecular, Histologic, Radiologic, Multimodal data types) (D) Bar graph of the top five model outcomes/topics where AI/ML algorithms have been developed to identify potential predictive biomarkers for NSCLC. Color coding indicates the broad biomarker data type used in these studies (i.e., Molecular, Histologic, Radiologic, Multimodal data types). ICIs, Immune Checkpoint Inhibitors; TKIs, Tyrosine Kinase Inhibitors; RT, Radiotherapy; CRT, Chemoradiotherapy.
Prognostic biomarkers are defined as biomarkers that are used to identify the likelihood of a clinical event, disease recurrence, or progression in patients who have the disease or medical condition of interest (3). Prognostic biomarkers are often confused with predictive biomarkers because predictive biomarkers are associated with prognostic outcomes in response to receiving a particular treatment. With NSCLC having FDA recognized predictive biomarkers (Table S1A), cataloguing prognostic biomarkers independent of predictive biomarkers can be misleading because biomarkers that were once associated with unfavorable outcomes can now be associated with favorable outcomes in response to targeted therapies. To identify a predictive biomarker, BEST recommends a comparison of a treatment to a control in patients with and without the biomarker (3). However, upon reviewing AI/ML studies of NSCLC biomarker research, we found that published prognostic and predictive biomarker studies are often confounded in single-arm evaluations. Acknowledging these issues, we used proxy definitions and catalogued studies as “Prognostic” when the prognostic outcomes were investigated regardless of the patients’ treatment status and as “Predictive” when prognostic outcomes were investigated in patient cohorts that were exposed to a specific medical product or an environmental agent.
We identified 58 manuscripts that reported AI/ML models to identify potential prognostic biomarkers of NSCLC (Table S1F). The most frequently studied prognostic outcomes were LAD Survival (79, 87, 90–104), NSCLC Survival (105–117), LAD Lymph Node Metastasis (98, 118–124), NSCLC Staging (66, 125–130), and NSCLC Recurrence (131–133) (Figure 3C).
Time-to-event is the typical outcome variable when the metric of prognosis is a survival phenotype. However, native ML models cannot handle time-to-event data while accommodating censored observations. Reflecting this, we found that ML studies predicting NSCLC/LAD survival mainly formulated the survival analysis as a classification problem and transformed time-to-event data into dichotomized endpoints (90–94, 96, 100, 102, 103, 106, 108–111, 113, 116, 117, 134, 135). To this end, utilizing Random Survival Forests (RSF) for continuous time-to-event survival prediction and those aiming to identify optimal time-to-event ML models were emerging (98, 99, 101, 105), but further applications and research in this area are warranted.
Prognostic ML studies using CT and PET/CT datasets were primarily based on pre-treatment images (79, 93, 105, 109, 111, 115, 126, 127, 129, 130, 133, 136). These studies emphasized the need for improved multi-institution data integration and image harmonization approaches to help build robust prognostic models (105, 109, 126). Prognostic molecular and multimodal ML studies mainly leveraged tumor gene expression datasets (Table S1F). Tumor microenvironment (TME) gene expression signatures have been investigated frequently in the context of developing prognostic ML models for NSCLC (92, 96, 99, 100, 110, 137, 138). In addition to TME immune gene signatures, other components such as hypoxia, pyroptosis, and intercellular communication were prioritized to build prognostic gene models for NSCLC (92, 96, 137).
AI/ML-derived predictive biomarkers of NSCLCClinical response to drugs can be influenced by many factors, including patient age, sex, body mass index, concomitant therapies, genetic make-up, circadian and seasonal variations, and drug absorption, distribution, metabolism, excretion (ADME) profiles. Precision/Personalized Medicine aims to customize treatment regimens based on known variables that predict response to available therapies. Pharmacogenetics and Pharmacogenomics efforts currently are the major driving forces enabling Precision Medicine in NSCLC treatment. Mutations in 11 genes (EGFR, KRAS, ALK, ROS1, BRAF, NTRK1, NTRK2, NTRK3, MET, RET, ERBB2), IHC quantified PD-L1 (CD274) expression, microsatellite instability, and Tumor Mutation Burden (TMB) constitute the FDA recognized predictive biomarkers predicting response to NSCLC therapies (Table S1A; Figure 3B). The FDA requires that Companion Diagnostics (CDx) tests/devices are used when screening these predictive biomarkers to accurately identify patient cohorts who are likely to benefit from the therapeutic products.
BEST defines predictive biomarkers as biomarkers that are used to identify individuals who are more likely than similar individuals without the biomarker to experience a favorable or unfavorable effect from exposure to a medical product or an environmental agent (3). In this study, as described in the previous section, we used proxy definitions due to the single arm study designs of the published AI/ML-based prognostic and predictive biomarker studies. We catalogued studies as “Prognostic” when the prognostic outcomes were investigated regardless of the patients’ treatment status and as “Predictive” when prognostic outcomes are investigated in patient cohorts that were exposed to a specific medical product or an environmental agent. We identified 34 manuscripts that used ML approaches to identify potential predictive biomarkers of NSCLC (Table S1G). The most frequently studied predictive outcomes were NSCLC/LAD Response to ICIs (96, 100, 139–152), NSCLC Response to Radiotherapy (86, 114, 153–156), NSCLC Response to Tyrosine Kinase Inhibitors (TKIs) (151, 157–159), and NSCLC Response to Chemoradiotherapy (160–162) (Figure 3D).
Three tumor-centric biomarkers; PD-L1 expression (≥ 1% or ≥ 50% of tumor cells), Microsatellite Instability (mutations in ≥30% of microsatellites/mismatch repair deficient), and Tumor Mutation Burden (TMB-H; ≥10 somatic mutations/Mb) are FDA-approved biomarkers for ICIs used to treat NSCLC (Figure 3B). However, only a fraction of the biomarker-positive NSCLC patients(20-30%) respond to ICI therapies (163). Among the ML studies we compiled, 16 reported predictive biomarkers for ICIs (96, 100, 139–152). In addition to the FDA-approved biomarkers, TMB and PD-L1 tumor proportion score (143, 145), TME-related immune gene signatures (141, 148), neutrophil-to-lymphocyte ratio (142, 143), and mutant allele tumor heterogeneity (MATH) (145) were reported as potential biomarkers predicting response to ICIs.
Mutations in eight genes (EGFR, ALK, ROS1, NTRK1, NTRK2, NTRK3, MET, RET) are FDA-approved biomarkers predicting response to NSCLC TKIs (Figure 3B). For biomarker positive NSCLC patients, the overall response rate to TKIs is more than 60% (164, 165). Through our literature search, we identified four studies that leveraged AI/ML to identify predictive biomarkers for TKIs in NSCLC patients (151, 157–159) and two in LAD-specific cohorts (87, 166). These studies mainly reported radiomics-based predictive models (151, 157, 158, 166). There was a report of a liquid-biopsy based protein signature in patients with ALK rearrangements predicting response to crizotinib (159) and an OncoCast ML framework that revealed that mutations in TP53 and ARID1A define a high-risk group with shorter survival in patients who received TKI therapies (87).
Stereotactic body radiation therapy (SBRT) is the standard of care treatment for early-stage NSCLC patients who are not candidates for surgery (153). For qualified patients, local control rate with SBRT treatment is around 90% but, as with surgical patients, distant failure is observed in about 20% of patients (167). Accurate prediction of response to SBRT in NSCLC patients can help identify patients who are more likely to benefit from upfront SBRT vs. systemic therapies. To this end, radiological image-only (114, 154, 155) and multimodal (86, 153, 156) classifiers have been reported, with consistent findings that CNNs demonstrate superior predictive power compared to pre-defined tumor image features (114, 154), and that inclusion of the biologically effective dose (BED) of SBRT improves predictive abilities of the models built (86, 153).
Concurrent chemoradiotherapy (CCRT) is a standard treatment option for stage II and stage III NSCLC patients with unresectable locally advanced cancer. The overall response rate to CCRT is around 80% (168). Identifying patient subsets who may benefit from intensified CCRT is important for better treatment planning. We identified three studies that reported predictive biomarkers for CRT (160–162) (Figure 3D). All three studies were based on PET/CT data and here ad-hoc consensus and fusion ML approaches were shown to increase the prediction accuracies of the resulting models (161, 162).
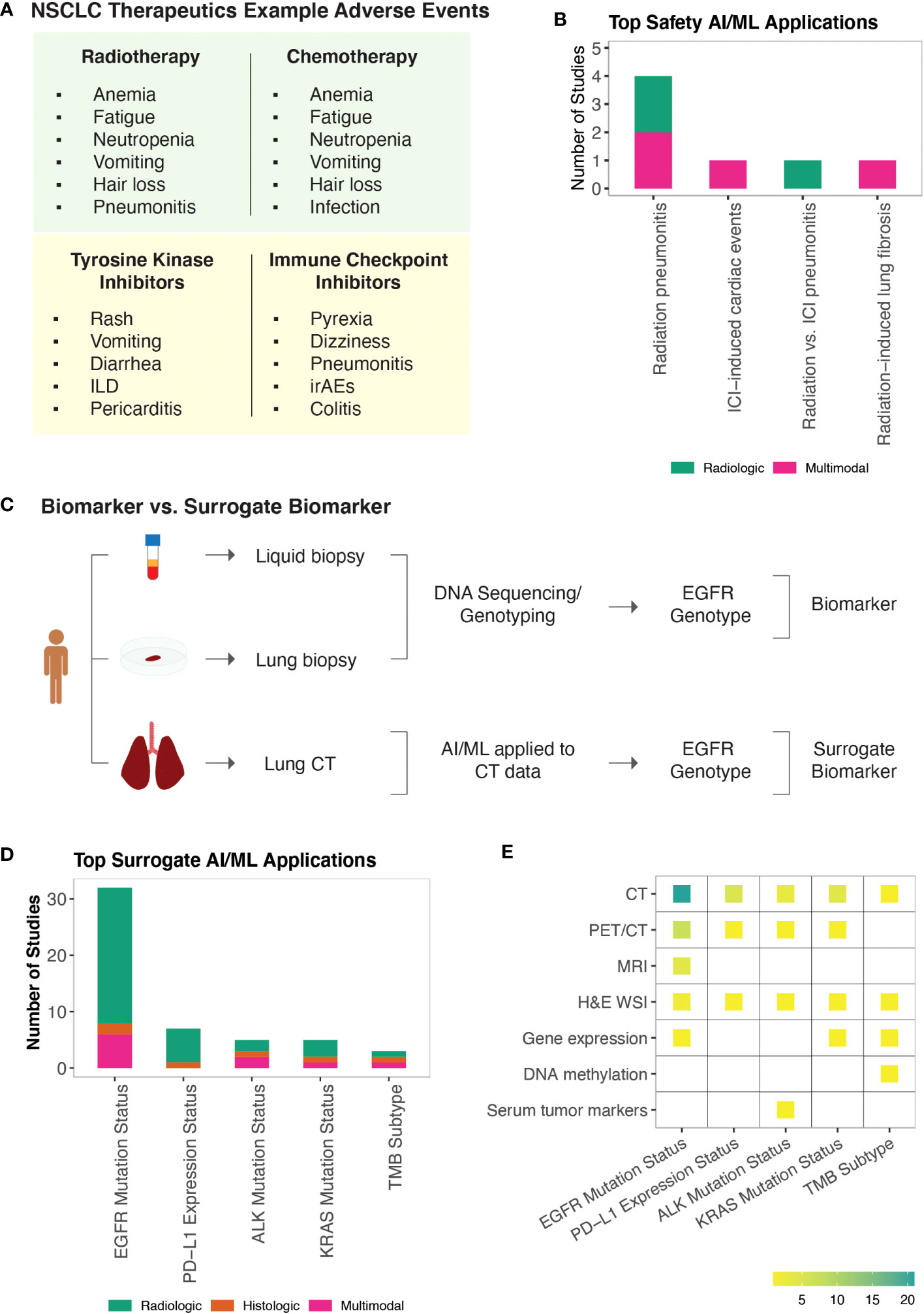
AI/ML-derived safety biomarkers of NSCLCThe FDA Adverse Event Reporting System (FAERS) is the primary surveillance tool that contains adverse events and safety concerns that are attributed to marketed drugs (169). Early detection of treatment-related adverse events is important for symptom management and successful treatment. Non-specific cancer treatments including radiotherapy and chemotherapy are mainly associated with hematologic (e.g., anemia, neutropenia, fatigue), gastrointestinal (e.g., nausea, vomiting), and dermatological (e.g., skin rashes, hair loss) toxicities. Pneumonitis is among the most severe of toxicities attributed to lung radiotherapy. Targeted therapies have a more variable spectrum of adverse events relative to non-specific cancer treatments (169, 170). TKIs are commonly associated with reversible symptoms including skin changes, vomiting, and diarrhea. However, more serious drug-specific adverse events such as interstitial lung disease and pericarditis have also been reported. Similarly, adverse events from ICIs range from reversible symptoms (e.g., dizziness, pyrexia) to more serious off-target inflammations that are referred to as immune-related adverse events (irAEs) (Figure 4A). While mild adverse effects can be managed symptomatically, moderate or severe toxicities necessitate dose reduction or treatment breaks, ultimately impacting drug efficacies. Similarly, many promising combination therapies for NSCLC face challenges due to increased toxicities of drug combinations (171), highlighting the need to identify safety biomarkers that can help tailor treatment approaches or guide the design of clinical trials.
Figure 4 AI/ML Applications for Safety and Surrogate Biomarker Discovery (A) NSCLC non-specific and targeted therapies and examples of their known adverse events. Note that adverse events associated with KRAS and Serine/threonine kinase inhibitors are not included. Representative adverse events were pulled from Open Targets Pharmacovigilance tables, which are based on the FDA Adverse Event Reporting database (169, 170) (B) Bar graph of the model outcomes/topics where AI/ML algorithms have been developed to identify potential safety biomarkers for NSCLC. Color coding indicates the broad biomarker data type used in these studies (i.e., Molecular, Histologic, Radiologic, Multimodal data types). (C) An example illustration of “Biomarker Quantification” (i.e., Direct assay) vs. “Surrogate Biomarker” Prediction (i.e., AI/ML applied to indirect assay data) (D) Bar graph of the surrogate biomarker types where biomarker prediction was made through applying AI/ML to other indirect data types. Color coding indicates the broad biomarker data type used in these studies (i.e., Molecular, Histologic, Radiologic, Multimodal data types). (E) A heatmap of the indirect biomarker data types that were leveraged through AI/ML applications to predict corresponding surrogate biomarker types. Heatmap density indicates the number of ML studies that used the data types shown on the y-axis to infer NSCLC biomarkers displayed on the x-axis.
Safety biomarkers are defined as biomarkers measured before or after an exposure to a medical product or an environmental agent to indicate the likelihood, presence, or extent of toxicity as an adverse effect (3). We found seven studies that used AI/ML to identify safety biomarkers that can be used to predict adverse events in response to NSCLC treatments. Potential safety biomarkers were reported for radiation pneumonitis (172–175), radiotherapy-induced lung fibrosis (176), ICI-induced cardiac toxicities (177), and to distinguish radiotherapy-induced vs. ICI-induced pneumonitis in patients who were treated both with radiotherapy and ICIs (178) (Figure 4B).
Radiation pneumonitis (RP) is a common (15-40%) complication of lung radiotherapy (179). The severity of RP is tracked using the National Cancer Institute Common Toxicity Criteria with radiation pneumonitis grade ≥ 2 (RP2) being symptomatic and limiting daily living activities. We identified four studies that developed ML models to predict RP2 outcome (172–175) and one study that built a classifier to distinguish radiation vs. ICI induced pneumonitis (178). Here, the concepts of integrating latent and hand-crafted variables (175), dosimetric and radiomic features (173), as well as clinical and baseline cytokine levels (174), were employed to improve the accuracy of RP2 risk prediction models.
Radiation induced lung fibrosis (RILF) is a severe side effect of radiotherapy that significantly impacts quality of life and can lead to non-cancer related death. RILF is classified from grade 0 to grade 5 depending on the clinical manifestation. Accumulating evidence suggests that genetic background as well as cytokines involved in tissue reorganization and immune response modulation are important factors contributing to RILF pathogenesis (180). We identified one ML study that built a classifier to predict RILF risk (176). This study highlighted baseline circulating CCL4 levels, along with dosimetric and clinical parameters as top discriminating features predicting grade ≥ 2 risk (176).
ICI-associated cardiotoxicity is rare but often fatal. Combination immune therapy has been shown to be a risk factor for ICI-associated cardiac events (181). Using our literature search approach, we identified one study that built ML models to predict cardiac events in patients receiving ICI therapy (177). In this study, Heilbroner et al. reported increased age, extremes of weight, presence of cardiac history, low percentage of lymphocytes, and high percentage of neutrophils among the top predictors of ICI-associated cardiotoxicity risk (177).
AI/ML-derived surrogate biomarkers of NSCLCIdentification of biomarkers from tissue biopsies is challenging due to their invasive nature of collection and small tissue volume, limiting their usefulness for performing repeated measurements, additional tests, and longitudinal monitoring. Non-invasive CDx assays (e.g., cobas EGFR Mutation Test v2, FoundationOne Liquid CDx, Guardant360 CDx) of ctDNA have been approved for certain NSCLC biomarkers (182). Alternative efforts continue to be pursued to detect approved and potential biomarkers of NSCLC. To this end, AI/ML algorithms have been applied to use relatively non-invasive patient data as a substitute to predict clinically approved or other potential biomarker types, which are collectively referred as the surrogate biomarkers in this study (Figure 4C).
Under the surrogate biomarker category, we identified 60 ML studies (Table S1I). The top predicted biomarkers were EGFR mutation status (44, 58, 183–209), PD-L1 expression status (190, 210–215), ALK mutation status (94, 216–219), KRAS mutation status (44, 194, 197, 220), and TMB subtype (221–223) (Figures 4D, E).
In clinical practice, EGFR and KRAS mutations are routinely detected using DNA-based assays including real-time PCR and sequencing. The detection of PD-L1 expression is based on IHC assays and is considered suboptimal (224). ALK mutations or rearrangements can be detected through both DNA- and protein-based assays. There is currently one FDA-approved CDx test for TMB status, which is solid biopsy and sequencing based (182). As a complementary method to existing biomarker tests, we found several ML studies that have demonstrated the value of using CT or PET/CT datasets to predict EGFR (58, 188, 190–195, 197, 198, 200, 201, 203–209), PD-L1 (190, 211–215), ALK (216–219), KRAS (44, 190, 194, 197, 220), and to some extent TMB (223) status. Besides the promise of using radiological image data to predict surrogate molecular biomarkers, the proposed models were also shown to provide potential utility in understanding tumor heterogeneity in which biological inference from different image pixels were shown to reflect intra-tumor heterogeneity (207–209).
In addition to noninvasive radiological data, invasive yet potentially time-efficient and tissue saving alternatives were also reported to be useful in predicting surrogate biomarkers. For example, Sha et al. developed a deep learning model that could predict PD-L1 status from H&E stained WSIs in NSCLC patients (210). Similarly, Chen et al. developed ML models that were trained on H&E stained WSIs to predict multiple genetic aberrations (ALK, BRAF, EGFR, ROS1 mutation status) and transcriptional subtypes (proximal-inflammatory, proximal-proliferative, terminal respiratory unit) of LAD (94), highlighting the potential of AI/ML approaches to infer different molecular characteristics through the repeated use of the same biological material.
DiscussionBiomarker discovery is a multifaceted process with many applications in healthcare such as identification of high-risk patients, improving diagnostic accuracies, as well as predicting prognostic outcomes and sensitivity to therapeutics. Despite the advancements in targeted therapies, approximately 30% of NSCLC patients do not harbor known driver mutations, and about 55% do not carry actionable mutations (225, 226). Additionally, even among patients who respond to targeted therapies, adverse events and acquired resistance may interrupt treatment plans, leading to disease progression. Expanding the repertoire of NSCLC biomarkers is critical for both the development of innovative treatments as well as for monitoring disease progression and adverse events. Here, to our knowledge, we report the first comprehensive review of AI/ML applications in the NSCLC biomarker space, catalogue the clinical challenges that are targeted by these studies, and summarize emerging patterns that could inform researchers and clinicians in this field.
Formally, ML is a sub-field of AI and the approaches used across the 215 manuscripts we catalogued could have fit under the ML category, however we used AI/ML interchangeably as this was the case in most published manuscripts. Similarly, the difference between ML and traditional statistics has been the subject of many controversies (227). ML can be built upon both statistical and algorithmic frameworks and common statistical methods can be used for both inferential and predictive modeling. We therefore relied on authors’ self-declaration regarding the use of AI/ML methods in predicting potential biomarkers for NSCLC. Additionally, starting in 2014, guidelines such as CHARMS (22), MLP-BIOM (23), TRIPOD (24), and PROBAST (25) have been published to improve the reporting and appraisal of the prediction models used for diagnostic and prognostic purposes. However, we did not evaluate the manuscripts based on these checklists as our goal was to catalogue the ongoing AI/ML efforts in NSCLC biomarker research rather than assessing the immediate clinical utility of the proposed models or biomarkers.
We catalogued 215 studies identified with respect to the BEST (3) biomarker sub-types (Figure 1B). We did not find any AI/ML-derived biomarkers that could fit under the Response Biomarker category (i.e., a biomarker used to show that a biological response, potentially beneficial or harmful, has occurred in an individual who has been exposed to a medical product or an environmental agent). We instead included a new biomarker category, which we referred to as Surrogate Biomarkers, where AI/ML algorithms have been applied to relatively non-invasive patient data to predict the presence of clinically approved or other potential biomarkers of NSCLC. While biomarker discovery is often formulated as a feature selection problem (228), we also included studies that did not select features but had reported classification utility with respect to relevant organismal phenotypes under each biomarker category.
As expected, the models proposed have not been evaluated for their clinical utility. However, the clinical questions, computational challenges, and emerging solutions discussed here can serve as a reference for clinicians and data scientists leveraging biomarker datasets and AI/ML in medicine. Transfer learning methods to relax training set requirements, data harmonization algorithms to minimize technical variability in data generation, the contexts of feature selection and stability to allow interpretable models are among areas that are rapidly advancing. In addition to the stochastic nature of AI/ML models, tumor-specific temporal and spatial molecular heterogeneities, the dynamic composition of the TME, and limitations in tumor tissue access continue to further challenge the evolving landscape of biomarker modeling for NSCLC. Non-invasive approaches including liquid biopsy-based biomarkers and surrogate biomarkers inferred through the use of AI/ML, hold promise to navigate these limitations and advance our understanding of the dynamic nature of tumor progression. Longitudinal data generated through non-invasive means can, however, pose a new challenge; the data generated can be overwhelmingly large as well as complex to analyze and interpret efficiently using traditional methods. The use of automated AI/ML tools in clinical monitoring may thus be essential to facilitate efficient analysis of the substantial amounts of longitudinal biomarker data.
Of note, while AI/ML models have been used (229) and show potential for numerous applications in clinical trials, including opportunities to enhance trial design, safety monitoring, and predictive analytics, there are currently no FDA-released guidelines or performance metrics specific to the use or evaluation of AI/ML algorithms in clinical trials (230). To this end, we anticipate that FDA guidelines for regulating AI/ML-based medical devices (231) and CONSORT-AI (232) recommendations for reporting AI-interventions in trials will facilitate the development of a formalized regulatory process, enabling effective and robust use of AI/ML in clinical trials.
Identification, cataloguing, and continuous updating of emerging biomarkers can expedite the clinical adoption of the innovative biomarkers and technologies. Here, we provided an overview of the fast-growing AI/ML applications in NSCLC biomarker discovery space and discussed the gaps and challenges in the field. By compiling relevant literature on NSCLC biomarker discovery, we revealed a comprehensive picture of the clinical challenges that are commonly targeted using AI/ML approaches and highlighted potential biomarkers and signatures that once adequately appraised may be translated into clinical decision support systems.
Author contributionsMÇ: Conceptualization, Data curation, Investigation, Methodology, Visualization, Writing – original draft, Formal analysis. KT: Methodology, Validation, Writing – review & editing, Investigation.
FundingThe author(s) declare financial support was received for the research, authorship, and/or publication of this article. This study received funding from Daiichi Sankyo, Inc. The funder approved publication of this article once it was conducted and prepared by the authors of this study.
AcknowledgmentsThe author MÇ gratefully acknowledges Daniel Baker for sharing his time and providing support during the writing of this manuscript.
Conflict of interestAuthors MÇ and KT were employed by the company Daiichi Sankyo.
The authors declare that this study received funding from Daiichi Sankyo, Inc. The funder had the following involvement in the study: approval for publication.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary materialThe Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fonc.2023.1260374/full#supplementary-material
References1. Duma N, Santana-Davila R, Molina JR. Non-small cell lung cancer: epidemiology, screening, diagnosis, and treatment. Mayo Clin Proc (2019) 94(8):1623–40. doi: 10.1016/j.mayocp.2019.01.013
PubMed Abstract | CrossRef Full Text | Google Scholar
3. FDA-NIH Biomarker Working Group. BEST (Biomarkers, EndpointS, and other Tools) Resource. Silver Spring (MD) Bethesda (MD (2016).
4. Srivastava S, Wagner PD. The early detection research network: A national infrastructure to support the discovery, development, and validation of cancer biomarkers. Cancer Epidemiol Biomarkers Prev (2020) 29(12):2401–10. doi: 10.1158/1055-9965.EPI-20-0237
PubMed Abstract | CrossRef Full Text | Google Scholar
5. Whirl-Carrillo M, McDonagh EM, Hebert JM, Gong L, Sangkuhl K, Thorn CF, et al. Pharmacogenomics knowledge for personalized medicine. Clin Pharmacol Ther (2012) 92(4):414–7. doi: 10.1038/clpt.2012.96
PubMed Abstract | CrossRef Full Text | Google Scholar
7. Chakravarty D, Gao J, Phillips SM, Kundra R, Zhang H, Wang J, et al. OncoKB: A precision oncology knowledge base. JCO Precis Oncol (2017) 2017. doi: 10.1200/PO.17.00011
CrossRef Full Text | Google Scholar
8. Tate JG, Bamford S, Jubb HC, Sondka Z, Beare DM, Bindal N, et al. COSMIC: the catalogue of somatic mutations in cancer. Nucleic Acids Res (2019) 47(D1):D941–D7. doi: 10.1093/nar/gky1015
PubMed Abstract | CrossRef Full Text | Google Scholar
10. Zhang J, Bajari R, Andric D, Gerthoffert F, Lepsa A, Nahal-Bose H, et al. The international cancer genome consortium data portal. Nat Biotechnol (2019) 37(4):367–9. doi: 10.1038/s41587-019-0055-9
PubMed Abstract | CrossRef Full Text | Google Scholar
11. Jain N, Mittendorf KF, Holt M, Lenoue-Newton M, Maurer I, Miller C, et al. The My Cancer Genome clinical trial data model and trial curation workflow. J Am Med Inform Assoc (2020) 27(7):1057–66. doi: 10.1093/jamia/ocaa066
PubMed Abstract | CrossRef Full Text | Google Scholar
12. Zwanenburg A, Vallieres M, Abdalah MA, Aerts H, Andrearczyk V, Apte A, et al. The image biomarker standardization initiative: standardized quantitative radiomics for high-throughput image-based phenotyping. Radiology. (2020) 295(2):328–38. doi: 10.1148/radiol.2020191145
PubMed Abstract | CrossRef Full Text | Google Scholar
13. Prior FW, Clark K, Commean P, Freymann J, Jaffe C, Kirby J, et al. TCIA: An information resource to enable open science. Annu Int Conf IEEE Eng Med Biol Soc (2013) 2013:1282–5. doi: 10.1109/EMBC.2013.6609742
PubMed Abstract | CrossRef Full Text | Google Scholar
14. Benjamin DJ, Haslam A, Gill J, Prasad V. Targeted therapy in lung cancer: Are we closing the gap in years of life lost? Cancer Med (2022) 11(18):3417–24. doi: 10.1002/cam4.4703
PubMed Abstract | CrossRef Full Text | Google Scholar
16. Nagasaka M, Singh V, Baca Y, Sukari A, Kim C, Mamdani H, et al. The effects of HER2 alterations in EGFR mutant non-small cell lung cancer. Clin Lung Cancer. (2022) 23(1):52–9. doi: 10.1016/j.cllc.2021.08.012
PubMed Abstract | CrossRef Full Text | Google Scholar
Comments (0)