
Remember me

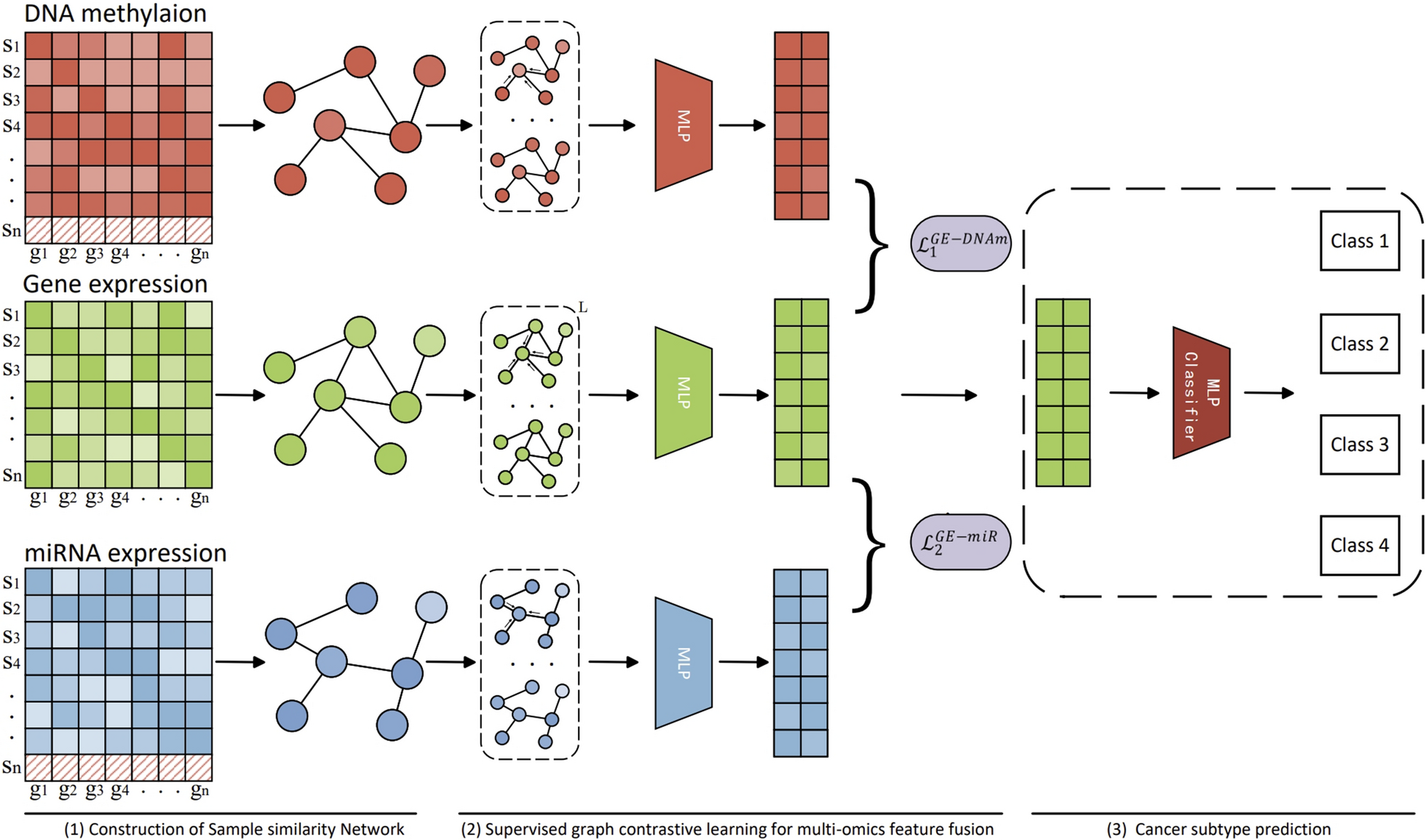

The work is a collaboration between Ulster University, UK, and the Indian universities: Era University, and King George Medical University.
Questionnaire formTo identify relevant features that impact lead toxicity, interviews are performed with the various members of the research and development team, which included: biomedical engineers, computer scientists, neonatologists, and gynaecologists. Together, they identified a range of sociodemographic features potentially relevant to lead toxicity based on existing literature and their expertise. Information on environmental and lifestyle factors including data on age, cosmetic use, clinical history, highest educational qualification, housing type, fuel source, water source, smoking history, and exposure to passive smoking (partner or other household member smoking) are included in the questionnaire form.
Features included in the questionnaire are significant and indicate typical exposure pathways of lead poisoning in pregnant women and consequently in the developing foetus. A feature like water sources is an important feature and signifies lead exposure pathways to the population at large that is not occupationally exposed. Water source and locality are the sources of baseline exposure to lead [22, 25, 26]. Lead exposure through smoking has a negative impact on pregnant women’s health and impacts the development and growth of the developing foetus [20]. Smoking is a common problem in India [20, 21] and including smoking-related questions is important. Therefore, in the questionnaire, two forms of smoking are included: (1) maternal smoking (type of smoking and number of times weekly smoking) and (2) family member smoking (type of smoking and number of times weekly smoking). A major part of lead toxicity results from its capacity to mimic other metals that take part in biological processes. Among the essential metals with which lead interacts are calcium, iron, and zinc [27]. Comorbidities like iron and calcium deficiency can enhance lead absorption. Anaemia is a common manifestation of lead toxicity and iron deficiency often coexists with lead intoxication [28]. The prevalence and severity of lead-induced anaemia relate directly to the blood lead concentration. Younger and iron-deficient children are at greater risk of lead-induced clinical anaemia [29]. Calcium and iron intakes appear to be inversely associated with blood lead concentrations in pregnancy [11]. Therefore, iron and calcium deficiencies are included in the questionnaire. Figure 1 shows an influence diagram indicating the set of features that have an association with maternal’s BLL and affect lead toxicity exposure.
Fig. 1
Influence diagram of features impacting maternal BLL and toxicity exposure
The influence diagram illustrates the relationships between the features themselves and more significantly, the relationship with the maternal’s BLL. The diagram comprises independent features (enclosed within the rectangles with thin lines) and summary features (enclosed within the rectangles with thick lines). Though summary features are influenced by independent features, they may also be a feature in their own right. For example, in Fig. 1, the independent features, age and education are likely to influence industry type (a summary feature), which consecutively can influence occupational exposure (a summary feature) and subsequently may affect a maternal’s BLL. Figure 1 additionally shows the perceived effect of lead toxicity on the developing foetus. It is perceived that the foetus’s BLL is impacted by the mother’s BLL and affects the baby’s weight, height, and physical and cognitive health.
Data collectionFollowing the identification of potential features pertaining to maternal lead toxicity levels, the study is designed to collect maternal data comprising sociodemographic features and blood samples. Before the start of the study, prior approvals are taken from the institutional review board and the data is collected over a period of 3 months.
Inclusion and exclusion criteriaThe study included only those subjects who are above 18 years of age and have given informed written consent to take part in the study. The study excluded those subjects who are below 18 years of age and/or refused to give consent for the study.
Subject recruitmentThe study is carried out at Era's Lucknow Medical College and Hospital. Pregnant women visiting the hospital for delivery are explained the significance, need, and design of the study. Informed, written consent is taken from the subjects eligible to participate in the study. Given the nature of the study along with a limited time and budget, the study enrolled 200 pregnant women, and the umbilical cord blood and blood samples are taken i.e., a total of 400 blood samples. Prior to the use of data, the data is anonymised to remove all sensitive information.
BLL estimationThe BLL estimation is carried out by collecting 2 mL of venous blood of the mother and 2 mL of umbilical cord blood in ethylene diamine tetra-acetic acid (EDTA) vacutainers. The samples are labelled and kept in a cooling box unless analysed. The collected mother and umbilical cord blood samples are analysed with the help of an inductively coupled plasma-optical emission spectrophotometer (ICP-OES), model Optima 8000, Perkin Elmer, USA) after prior microwave digestion. Table 1 details the experimental setup followed for the BLL determination.
Table 1 Experimental set-up for the BLL determinationa. Microwave digestion we used the microwave digestion technique as described in [30] with a little modification. The blood samples are digested with the help of a Microwave Reaction system (Multiwave 3000, Anton Paar, Perkin Elmer) with the Rotor 16HF100 (100 mL PFA vessels, 40 bar) and pressure–temperature (p/T) sensor. Blood samples (0.5 mL) are digested with 2.0 mL of HNO3:HCIO4 (3:1), 1.0 mL of H2O2 and 2.0 mL of H2O2 in the microwave digestion system. The microwave reaction system is programmed to attain 400 W of power with 5 min ramping hold for 10 min and then increased to power 800 W with 5 min ramping to hold for 10 min, then cooled to 0 power. A blank using Milli-Q water in place of the sample is also digested and prepared. The resulting clear solution after microwave digestion is cooled and analysed for lead levels.
b. ICP-OES analysis the resulting clear solutions obtained after microwave digestion are analysed by ICP-OES for lead level using the Certified Reference Material (CRM) provided by Perkin Elmer, USA [31]. The ICP-OES operating conditions are described in Table 1. The ICP-OES instrument (Perkin Elmer Optima 8000, USA) is calibrated with different concentrations of lead standard. The working calibration standard solutions range from 0.005 to 1.0 mg/L of lead (Pb) and are prepared from a stock standard of 1000 mg/L by dilution in 0.2% nitric acid. A calibration curve is prepared with a correlation coefficient of 0.9999 using linear through zero (Fig. 2). The calibration blank is also prepared using Milli-Q water instead of the Pb standard. The samples and blank solutions after microwave digestion are analysed and the results of BLL are expressed in µg/dL. The recovery and limit of detection of lead are also carried out by spiking the blood samples with different concentrations of lead standard. More than 90% of recoveries are obtained with a limit of detection of 0.001 mg/L.
Fig. 2 Data analysis
Data analysisThe determined BLL values and details collected from the questionnaire form are collated together to make the maternal dataset of 200 samples. In total 27 features are collected along with gestation age, baby weight (kg), and BLL values of the mother and the newborn (Table 2).
Table 2 List of features collected in the datasetThe collated data is pre-processed to clean incorrect, incomplete, inconsistent, improperly formatted, duplicate, and missing values. Consequently, the data dictionary is created to convert the data from raw format to another format to allow for more convenient consumption of the data. For example, ‘cosmetic use’ is a single feature having collective information for the use of dye, kohl, lipstick, sindoor, and surma. However, each of these cosmetics has a different level of impact on BLL, therefore they are considered separate features in the analysis. In the collected dataset, each feature has many categories which means the built models are relatively complex with a high probability of lower accuracy [32]. For instance, age is a continuous value and education has too many categories. Since these features typically have too many categories, statistical tests like the Chi-squared test may have few instances of data in some categories, and this can weaken the test [32]. We, therefore, categorise each feature into fewer values based on relevance. Initial feature reduction is carried out and a manual screening is undertaken to prune out irrelevant features. The 27-feature set is consequently reduced to an 18-feature set. Table 3 provides details of the 18-feature set labelled with fewer categories.
Table 3 Details of the 18-feature set labelled with fewer categoriesThe maternals’ BLL values ranged from not detected (ND) to 35 μg/dL. The age feature is characterised as less than or equal to 30 and greater than 30 (Table 3). The education feature is categorised as “no college” (includes uneducated and education up to class 12th) and “college and higher degree” (includes graduate and higher degree). Occupational exposure indicates direct job working exposure to lead. The mother’s occupation is categorised into two types “housewife” and “office”, based on the collected data. To find the correlation between the BLL and the identified features, descriptive analysis is carried out in Python. The correlation between a mother’s age, education, and occupation with lead concentration is shown in Fig. 3.
Fig. 3
Correlation of lead concentration with mother’s age, education, and occupation
The collected data suggests a slightly higher level of lead concentration in pregnant women who are aged above 30. Figure 4 shows the correlation between lead concentration and the use of dye, kohl, lipstick, sindoor, and surma. From Fig. 4, it can be observed that the mothers who used kohl, lipstick, and sindoor have elevated levels of lead in the blood samples. This confirms the fact that lead-based cosmetics can be the reason for the elevated BLLs. The collected dataset has information for different sources of water: groundwater sources (tube well and submersible), tap water through pipelines, reverse osmosis (RO) water, use of both tap water and RO water, use of both groundwater and RO water, and use of both tap water and groundwater (Table 3). Figure 5 shows the correlation between different water sources and lead concentration.
Fig. 4
Correlation between lead concentration and use of cosmetics
Fig. 5
Correlation between different water sources and lead concentration
Second-hand smoking exposure due to smokers in the family is also a reason for a higher level of lead concentration in pregnant women and therefore, this information is also included in the dataset. Two features included in the study are the mother smoking and family member smoking. In the collected dataset, only one mother has a smoking habit. Figure 6 shows a correlation between lead concentration and family member smoking, type of smoking, and the number of times they smoked per week.
Fig. 6
Correlation between lead concentration with family member smoking, type of smoking, and the number of times they smoked per week
The next feature analysed is the type of utensils used for cooking. The utensil feature is categorised as steel, aluminium, both steel and aluminium, others and steel, and aluminium, ceramic, and steel. Figure 7 shows the correlation between different types of utensils and lead concentration. From Fig. 7, it can be observed that mothers using aluminium and steel do have elevated BLL values. In the collected dataset, information for non-specific generalised symptoms, related to lead toxicity, like lethargy, tiredness, and headache are also included. Figure 8 shows that mothers having these non-specific generalised symptoms have a higher lead concentration in the blood.
Fig. 7
Correlation between different types of utensils and lead concentration
Fig. 8
Correlation between non-specific generalized symptoms and lead concentration
Gastrointestinal manifestations of lead poisoning include chronic or recurrent abdominal pain [33]. Figure 9 shows a high correlation between abdomen pain and elevated BLLs. The data also reported pica symptoms in individuals. Figure 10 shows the correlation between pica symptoms and lead concentration. The prevalence and severity of lead-induced anaemia relate directly to the blood lead concentration. The collected data confirms this fact, Fig. 10 shows a high correlation between iron deficiency and lead toxicity. Also, in the literature, calcium deficiency has been linked to increased lead absorption [34]. The collected dataset indicates that individuals having calcium deficiency had higher lead concentrations (Fig. 10).
Fig. 9
Correlation between pica symptoms and lead concentration
Fig. 10
Correlation between pica symptoms and lead concentration
The existing literature reports that long-time exposure to lead can be the cause of anaemia among middle and older-aged people [35]. It would be interesting to see if the collected data reflects this pattern. Figure 11 shows the box plot of age versus iron deficiency with respect to lead concentration. Subjects who were above 30 and had an iron deficiency also had elevated lead concentration, reflecting a long time of exposure to lead.
Fig. 11
Box plot for iron deficiency versus age with respect to lead concentration
Women can be exposed to lead even by handling or washing their family’s lead-contaminated clothes [36]. Some of the jobs do come with the potential of more obvious lead exposure. For example, battery manufacturing/repair, construction, lead smelting, soldering, plumbing, auto-body repair, pottery, rubber and plastics manufacturing, stained glass, tile, ceramics, and manufacturing or using leaded paints, dyes, glazes, inks, or pigments. The collected dataset studied the occupation of family members for potential risk of take-home exposure and the details are provided in Table 4. The analysis reiterated the association between lead exposure and certain jobs. Pregnant women whose family members worked in plastic manufacturing, polishing, auto driving, soldering, pipefitting, battery manufacturing and repairing, construction, auto repair, and painting had higher lead concentrations. It is to be noted that certain combinations of jobs reflected very high lead exposure in a pregnant woman. This includes Polishing_Soldering (mean BLL = 19.7 μg/dL), Painting_Furniture (mean BLL = 11.05 μg/dL), and Construction_Painting_Plastic_Polishing (mean BLL = 12.6 μg/dL). For fuel sources and alcohol use, there is very limited data in each category, so it has not been shown in separate figures.
Table 4 Summary of the findings from the analysis of the dataTable 4 also details the summary of the findings from the analysis of the data. From the analysis, it can be concluded that certain features are significant and contribute to elevated lead levels in pregnant women. Features like active and passive smoking are important, especially in the context of developing countries like India, where tobacco exposure is a major concern. The analysis found that women who were exposed to second-hand smoke had elevated BLLs (Overall mean BLL = 7.18 μg/dL, beedi mean BLL = 10.87 μg/dL, cigarettes mean BLL = 6.81 μg/dL). Subjects who were aged above 30 had a higher lead concentration (mean BLL = 8.42 μg/dL), indicating that long-time exposure to lead has built up in the body. Lead is cumulative and the use of cosmetic products can bring about potential exposure to its toxicity. In the collected data, it was found that the subjects using cosmetics such as dye (mean BLL = 9.45 μg/dL), kohl (mean BLL = 5.58 μg/dL), lipstick (mean BLL = 6.31), sindoor (mean BLL = 6.35 μg/dL), and surma (mean BLL = 8.55 μg/dL) had elevated BLLs. The use of RO filters removes the lead from water, however in the collected dataset, surprisingly the subjects who used RO water had higher BLLs (mean BLL = 8.74 μg/dL). This may be due to other features causing elevated BLLs. It was also found that the use of aluminium-based utensils can be the reason for higher lead concentrations (mean BLL = 9.27 μg/dL). The clinician manifestation of lead toxicity is reflected in the non-specific, pica symptoms, and gastrointestinal features. The existence of headaches among 12 subjects was highly correlated to elevated lead concentration (mean BLL = 16.20 μg/dL). Also, pain in the abdomen was highly correlated to the elevated lead concentration (mean BLL = 12.60 μg/dL). The analysis found very high lead levels in 21 subjects who had iron deficiency (mean BLL = 16.18 μg/dL) and in 13 subjects who had calcium deficiency (mean BLL = 12.38 μg/dL). The take-home lead exposure due to family member/s working in lead-based professions was high, specifically in jobs like construction (mean BLL = 8.28 μg/dL, 13 subjects), painting (mean BLL = 8.69 μg/dL, 10 subjects), auto repair (mean BLL = 10.35 μg/dL, 9 subjects), painting and furniture (mean BLL = 11.05 μg/dL, 8 subjects), and batteries (mean BLL = 15.90 μg/dL, 4 subjects). The lead levels were also high in professions such as soldering, polishing, plastic manufacturing, pipe fitting, and auto driving. However, we have a limited number of subjects in these categories to draw a conclusion regarding the association between lead toxicity and these professions.
Figure 12a shows a relative plot of the mother’s and baby’s BLL values. The plot indicates that babies, whose mothers had relatively higher BLL values, had higher BLL values in most of the cases. This confirms that a significant amount of lead transfers from the mother to the foetus.
Fig. 12
a Relative plot of mother’s and baby’s BLL values. b Histogram of mother’s BLL values
Predicting lead toxicity levelThe focus of our work is to analyse the pregnant women’s background for the potential risk of lead toxicity. The collected maternal data is used to build a computational model that takes in the sociodemographic features and predicts the lead toxicity level. It is anticipated that such a computational model can analyse personal, second-hand smoking, take-home exposure, general, and clinical features and then can predict the output class variable, lead content level.
The range of BLL values that should be considered as high toxicity levels vary from country to country and the current permissible BLL limit is set to 10 μg/dL by the WHO. However, the BLL value of 10 μg/dL, previously measured to be safe is now considered unsafe for health and harms multiple organs, even in the absence of explicit symptoms [37]. However, recent studies have found that neuro-behavioural damage occurs at a BLL of 5 μg/dL and even lower. Therefore, a definite BLL threshold below which lead causes no injury to the developing brain is difficult to identify. Lately, the Centres for Disease Control and Prevention have set a new threshold of 5 μg/dL concerning childhood BLLs [38]. In the collected dataset of 200 samples, the BLL values ranged from 2.3 to 34.8 µg/dL. The sample also contains no ND values. These are recorded for those cases where lead is not detected in the blood sample. There are 81 data points with ND as a BLL value. The BLL values are discretised into discrete states to incorporate them into the model. It is postulated that directly using continuous lead values may result in making the model sensitive to variations in the values [39]. Nevertheless, directly incorporating continuous lead values (the measured BLL) into a model is a complex and computationally intensive process that may not prove to be very informative for prediction [39]. Also, a large amount of data is required for such an approach, therefore we focused on using discretised BLL values. Because the primary focus of this paper is to exhibit the use of sociodemographic features in building a prediction model that can predict lead content level, we here follow a simple process of visual inspection to discretise the BLL values. However, there are other methods to discretise the continuous data, which are detailed in [39]. Figure 12b shows a histogram of BLL values and their frequency in the collected dataset. There is a clear separation between the data, resulting in clear distinct clusters; thus, making the visualisation straightforward. Based on this representation, the data is therefore discretised into five clusters and the output class variable, the lead content level is labelled as ND, LessThan5, Between5_10, Between10_15, and GreaterThan15.
Classification algorithmsFor developing the most suitable algorithm for predicting the lead content level, a range of data mining algorithms are explored to find their suitability in building the prediction model [40]. Table 5 presents the details of the algorithms and parameter settings used in our case.
Table 5 Classification algorithms details and parameter setting used in building prediction modelsHandling imbalanced classesIn the collected dataset, the output class variable, lead content level, has a varying number of data points for each of the categories: ND = 81, LessThan5 = 24, Between5_10 = 52, Between10_15 = 14) and GreaterThan15 = 29. As a result, the given data is imbalanced and this imbalance in the class sizes can influence the outcome of some of the classification algorithms, typically with a bias towards the majority class (i.e., the one which has a higher number of values) [32]. The size distribution of the classes is 40.5% ND, 12% LessThan5, 26% Between5_10, 7% Between10_15, and 14.5% GreaterThan15. Due to this imbalance in the collected data, the fitted models have a higher possibility of incorrectly classifying most of the unknown instances to the majority class, i.e., the ND class in our case. Therefore, in this work, we also investigated the benefits gained by using resampling techniques.
The objective of undertaking resampling is not to improve the accuracy but to handle the bias. If the classes are not balanced, the majority class will dominate and in extreme cases all the unknown cases get assigned to the majority class, thus leading to misclassification [32, 41]. The purpose of the resampling technique is to let the model classify the unknown cases solely based on the robustness of a classification algorithm and the merits of the selected features. Therefore, to build more accurate prediction models and minimise bias, the imbalance in the data is handled by applying a resampling technique.
To handle the imbalance between the classes, the Synthetic Minority Over-Sampling Technique (SMOTE) is applied to the data. SMOTE is a commonly used technique due to its effectiveness and simplicity [42]. The given data is resampled using the SMOTE filter in WEKA Experimenter (University of Waikato, Version 3.8) and the classes are given a boost as shown in Table 6. In Weka, the new instances of the minority class created are added at the end of the data. Therefore, the order of appearance of the data instances is subsequently randomised to avoid overfitting. This is performed using the Randomize filter in the Weka Experimenter.
Table 6 SMOTE applied to the four minority classesFollowing the process of resampling, the new data is an 18-feature dataset with 81 instances each of ND, LessThan5, Between5_10, Between10_15, and GreaterThan15 each and in a total of 405 instances. In the given data, the ND values are assigned to those instances, where the BLL is less than or equal to 3 μg/dL. However, the ND and LessThan5 values are two clusters very close to each other with respect to the BLL values and therefore, can be merged into one cluster. Consequently, in the next modelling phase, we merged ND and LessThan5 labels, resulting in a new class label, ND_5. The new output classes are ND_5 (105), Between5_10 (52), Between10_15 (14), and GreaterThan15 (29), which is still imbalanced data. Therefore, again the SMOTE is applied to rebalance the data based on the output classes ratio, followed by the randomisation technique.
Feature selectionIn the next step, feature selection is carried out to identify features that can make a good prediction of class membership for the output classes under investigation.
Univariate analysisA univariate analysis is carried out by applying the Chi-square test on each of the 18 features against the output class, lead content level. While applying the pair-wise test, those cases which have the missing information are dropped as these cases do not add up to any information in finding a relationship between the two variables (i.e., the feature and the output class variable) [32, 41]. A Chi-square test is applied to the 18-feature set with four class labels (ND_5, Between5_10, Between10_15, and GreaterThan15). Based on the p-values obtained for the features, Age (p-value = 0.008), TakeHomeExposure (p-value = 0.019), NonSpecific (p-value = 0.000), GastroIntestinal (p-value = 0.000), and PiccaSymptoms (p-value = 0.000) are found to be significantly associated with the output class, lead content level.
Multivariate analysisIn the influence diagram, shown in Fig. 1, a few of the features are directly related to the output class, whereas a few of them may be indirectly related. The univariate analysis showed a limited direct correlation between the features and the output classes. This may be because the Chi-squared test may not be able to identify all the relevant features. The multivariate analysis produces more accurate feature ranking by evaluating multivariate statistics that consider the dependencies among features when calculating feature scores. Keeping this view in mind, next the multivariate analysis is carried out to find which combination of features can work best to predict the lead content level, reduce the computational complexity, increase the accuracy of the built models, and optimise the cost of feature selection. Here we apply two multivariate feature selection methods namely, the multinomial logistic regression and the Boruta algorithm.
Multinomial logistic regressionLogistic regression is a technique used when the dependent variable is categorical (i.e., nominal). For binary logistic regression, the number of dependent variables is two, whereas the number of dependent variables for multinomial logistic regression is more than two. Multinomial logistic regression is an extension of binary logistic regression that allows for more than two categories of the dependent or outcome variable [43]. Table 7 shows the likelihood ratio tests obtained by applying the multinomial logistic regression to the data with four class labels. From the analysis, out of 18 features, 8 features are found to be significant and have a p-value < 0.05.
Table 7 Likelihood ratio tests table obtained by applying multinomial logistic regressionBoruta algorithmA feature might be important in the prediction of an outcome, and yet may not be captured in the analysis. For example, the logistic regression method used in [32, 41], to carry out the multivariate analysis, may not capture all the features that are important. This is because the logistic regression captures only certain relationships (linear) between the input and output variables. Therefore, here we use another feature selection method called Boruta. The Boruta algorithm is statistically grounded and works well without any specific input from the user [
Comments (0)