
Remember me
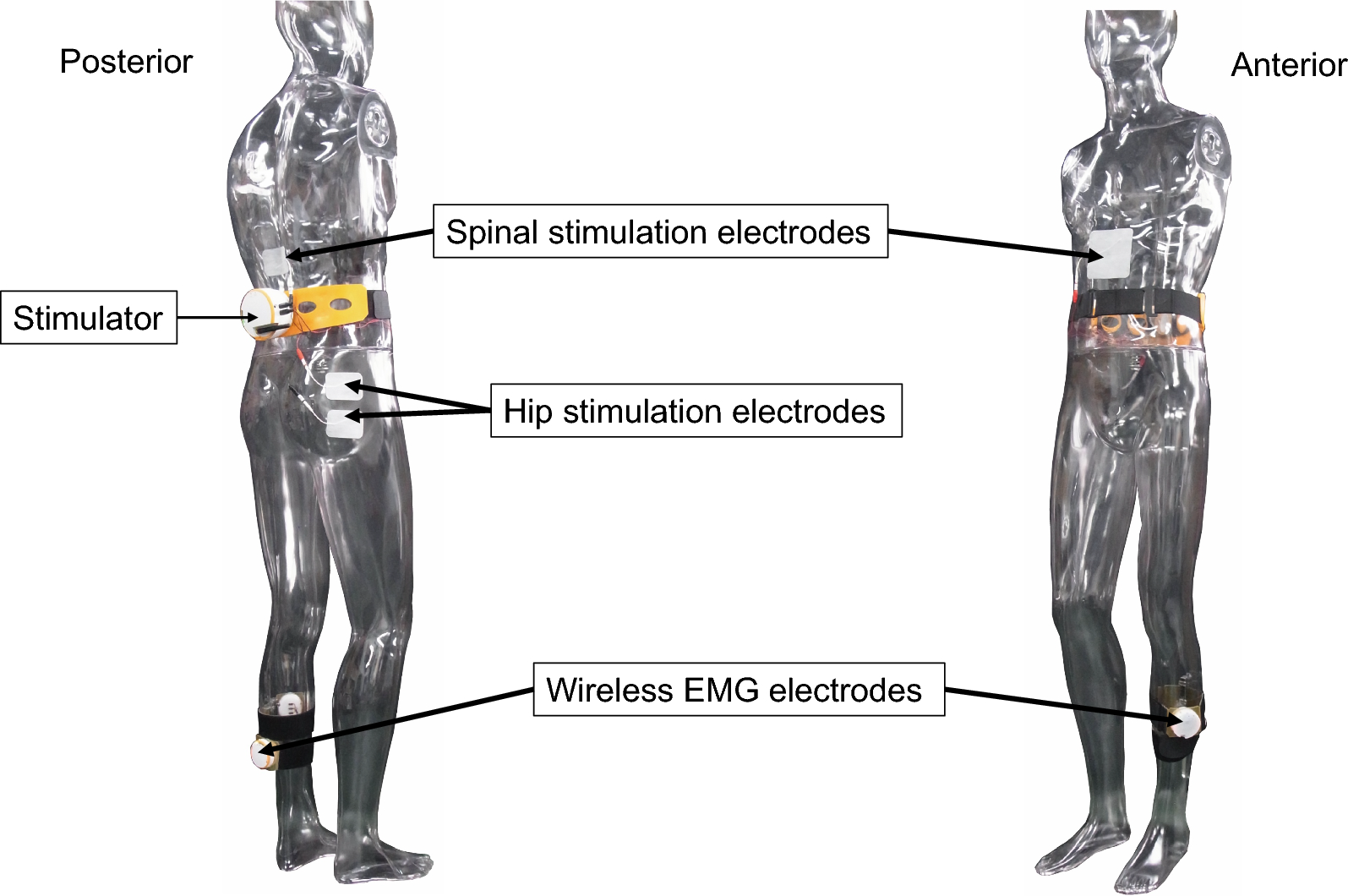
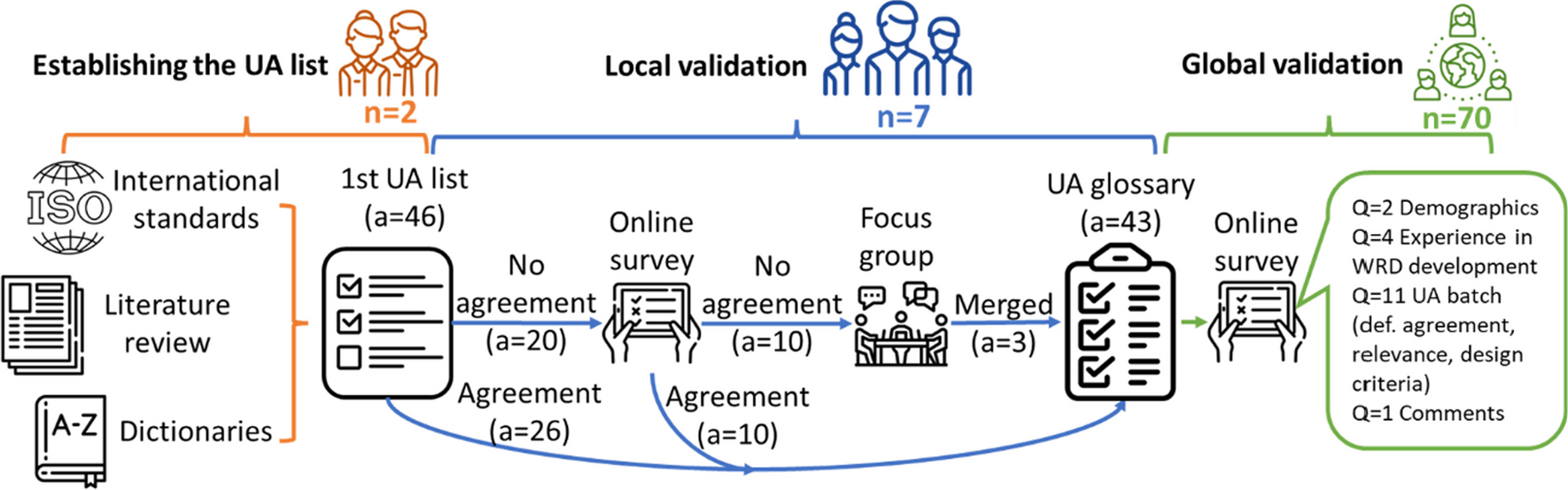


Fifty-five participants with stroke (age: 61.3 ± 11.3 years) of Hibino Hospital participated in this study. Of these, 41 participants (age: 61.7 ± 11.2 years) were evaluated as a group with driving aptitude, and 14 participants (age: 61.2 ± 11.4 years) were evaluated as a group without driving aptitude. Table 1 shows the baseline data for participants in the groups with and without driving aptitude. The participants were asked to take the following 10 types of tests: the functional independence measure (FIM) [12], a type of functional independence assessment method; MMSE [13, 14], TMT [15, 16], which are cognitive function tests; Rivermead behavioral memory test (RBMT) [17], which is a type of memory test; CAT [18], which indicates attention function; the Japanese perceived stress scale (JPSS) [19, 20], which is a type of self-perceived stress test; the Brunnstrom stages of motor recovery (BRS) [21], which indicates the degree of paralysis; dominant hand side before stroke and affected side after stroke were also included in this analysis; the BIT [22], which indicates the degree of unilateral spatial neglect; the hospital anxiety and depression scale (HADS) [23, 24], which determines the presence or absence of depression and anxiety; the apathy score (AS) [25, 26], which determines the presence or absence of apathy.
The participants performed an on-road driving test and simulator test at the Numata driving school to evaluate their driving aptitude as described previously [27]. Driving aptitude was evaluated by driving school instructors based on the results of these tests. Based on the driving simulator results and the on-road testing, the participants were classified into two groups: a group with driving aptitude that the driving school instructor judged to be able to drive, and a group assessed to be unable to drive or require further training. The study was approved by the Ethics Review Committee of the Hiroshima University Epidemiological Research (E-1554-2, E-466-3) and was performed per relevant guidelines and regulations. Written informed consent was obtained from all participants.
Proposed neural network modelThe log-linearized Gaussian mixture network (LLGMN) [28], a neural network based on a discriminative Gaussian mixture model, can estimate the posterior probability of the target class that the input data belong to by estimating the statistical distribution of the sample data. So far, several studies have demonstrated its effectiveness in recognizing biological information [29, 30], including an application to analyze the relationship between driving aptitude and physical and cognitive functions [31]. Moreover, since only the number of mixtures is a hyperparameter, the tuning cost is lower than that of general neural networks such as the multilayer perceptron [32]. However, simply evaluating driving aptitude using the LLGMN does not reveal the relationship between each participant’s clinical index and driving aptitude, rendering it challenging to realize the original intent of establishing an effective method for identifying subjects who must undergo an on-road driving test through hospital-based physical and cognitive function screening tests. Therefore, this study proposes an LLGMN-based sparse neural network that can automatically select indices related to driving aptitude by adding a dimensionality reduction layer with sparse weights before the input layer of the LLGMN.
Fig. 1
Overview of the proposed neural network model for evaluating driving aptitude. The proposed network is composed of two parts: a dimensionality reduction layer with \(L_1\) regularized weights and a log-linearized Gaussian mixture network (LLGMN) [28]. This network calculates the posterior probability \(p(c|\textbf)\) of the presence or absence of driving aptitude (i.e., drivable or undrivable) using the indices \(\textbf\) obtained from the physical and cognitive function tests as input. The weight parameters of the dimensionality reduction layer are denoted by \(\textbf = \_^P\)
The overview of the proposed network is shown in Fig. 1. The network’s input is a P dimensional index value \(\textbf \in \mathbb ^P\) obtained from 10 physical and cognitive tests. The output is the posterior probability \(p(c|\textbf)\) of class \(c \in \\) representing the presence or absence of driving aptitude. The following equation can express the relationship between the input and output in the dimensionality reduction layer:
$$\begin y_i=w_i x_i \ \ \ (i=1,2,...,P), \end$$
(1)
where \(y_i\) is the dimensionality reduction layer’s output, and \(w_i\) is the dimensionality reduction layer’s weights. In the proposed network, the corresponding input dimension is reduced by sparsifying the dimensionality reduction layer’s weights.
Given a set of training data \(\textbf_n\) and corresponding target values \(t_\) indicating the presence or absence of driving aptitudes (\(n = 1, \ldots , N\); N is the number of participants for learning), let us consider the training of the proposed network. The target \(t_\) is a vector of one-of-C form, indicating the presence or absence of driving aptitude, where \(t_ = 1\) if \(\textbf_n\) belongs to class c, \(t_ = 0\) otherwise. The solution of the proposed network can be obtained at the same time as learning by applying \(L_1\) regularization to the weights \(w_i\) of the dimensionality reduction layer. Here, the energy function E of the proposed network is defined as follows:
$$\begin E = -\sum ^_\sum ^_ t_ \ln p(c|\textbf_n)+\lambda \sum _^ |w_i|, \end$$
(2)
where the first term represents the cross-entropy error and the second term is the \(L_1\) regularization term, which penalizes the error according to the magnitude of the absolute value of the dimensionality reduction layer’s weights (\(w_i\)). The parameter \(\lambda\) is a regularization coefficient that determines the strength of \(L_1\) regularization.
The proposed network minimizes the energy function E based on the error backpropagation method. Hence, the parameters of the entire network can be learned in an end-to-end fashion to reduce the error within the range where \(w_i\) does not become large. Some \(w_i\) will be completely zero at the end of training by applying \(L_1\) regularization to the dimensionality reduction layer’s weights. Thus, input indices corresponding to \(w_i\) that become zero can be excluded from the model, and input indices related to driving aptitude can be selected automatically. As a result, redundant input dimensions may be minimized, further identifying crucial indices that are highly relevant to the evaluation of driving aptitude and reducing test time in future applications.
Importance of indicesIt is important to identify the key features of a model in relational analysis using machine learning. \(L_1\) regularization is applied to \(w_i\) in the dimensionality reduction layer in the proposed network to perform parameter reduction estimation and dimensionality reduction by actively reducing the \(w_i\) with a low contribution to zero error reduction. The \(w_i\) remaining after learning represents the contribution of each index to the discrimination result; hence, the importance of each index may be obtained by examining the magnitude of \(w_i\).
We also examined the importance of indices using the permutation importance [33], which is one way to evaluate the importance of machine learning inputs, and compared it with the learned \(w_i\) in the proposed network. The permutation importance used the following algorithm to evaluate the importance of indices.
1.After splitting the whole dataset into training and validation datasets based on the cross-validation procedure, the model is trained using the training dataset.
2.The validation data, \(\textbf^\text = \^\text_n\}\) (\(n = 1, 2, \ldots ,N^\text\); \(N^\text\) is the number of participants in the validation data), are input to the trained model to calculate the cross-entropy error e which is a measure to evaluate the accuracy of the model:
$$\begin e = L(t^\text_, \textbf^\text) = -\sum ^}_\sum ^_ t^\text_ \ln p(c|\textbf^\text_n), \end$$
(3)
where \(t^\text_\) is the corresponding target value.
3.Shuffle the order of the i-th feature in the validation data (i.e., permutation) to create a new validation data matrix \(\widetilde}^\text\).
4.Input \(\widetilde}^\text\) into the trained model and compute the error \(e_i = L(t^\text_, \widetilde}^\text)\) based on the output.
5.Calculate the difference in the error before and after permuting i-th feature, \(PI_i\), which is the evaluation value of permutation importance:
$$\begin PI_i = e_i - e. \end$$
(4)
6.Repeat steps 3 to 5 for all features \(i = 1,...,P\).
The above algorithm obtains the evaluation value of permutation importance \(PI_i\) for each feature. Since the cross-entropy error is used as the score for evaluating the model’s accuracy, the larger \(PI_i\) value indicates that the model’s accuracy deteriorates when the data order is randomized, suggesting that features with larger \(PI_i\) are important.
Relationship between evaluation indices and driving aptitudesMore than 300 indices were obtained from the 10 physical and cognitive function tests. Analyses of all these indices would require a great deal of time. Therefore, the indices that were considered to be related to driving aptitude were selected from all the indices under specialized physicians’ guidance. Indices that were highly related to driving aptitude were rated as \(\circledcirc\), those that were related as \(\bigcirc\), and those that were slightly related as \(\triangle\). Table 2 shows the evaluation results for each test. The results were \(\circledcirc\): 48 indices, \(\bigcirc\): 17 indices, and \(\triangle\): 7 indices. Moreover, the effective indices for driving aptitude evaluation were selected by machine learning using the proposed network using the three datasets created based on the evaluation results. Dataset 1 consisted of 48 indices with a rating of \(\circledcirc\). Dataset 2 consisted of 65 indices with a rating of \(\circledcirc\) and \(\bigcirc\). Dataset 3 consisted of 72 indices with a rating of \(\circledcirc\), \(\bigcirc\), and \(\triangle\). The data was standardized (mean = 0, standard deviation = 1) for each index. Table 3 shows the results of ROC analysis of the identification results by the proposed network. The AUC of dataset 1, dataset 2, and dataset 3 were 0.918, 0.946, and 0.862. Therefore, dataset 2 consisting of 65 indices of physical and cognitive functions listed in Table 4 were selected for analysis in this study (i.e., \(P = 65\)). The presence or absence of driving aptitude was used as the target value, and the values of 65 indices shown in Table 4 were used as input data. The experiments were run on a computer with an Intel Xeon X5-2620 (8 cores, 2.1\(-\)3.0 GHz) processor and 16 GB RAM.
Table 2 Evaluation results by physiciansTable 3 Results of ROC analysis based on datasetsThe indices for driving aptitude evaluations were selected by machine learning using the proposed network, thereby judging the indices whose \(w_i\) was non-zero at least once to be effective. In this study, 11-fold cross-validation was used for analysis. The ROC analysis was also conducted using the posterior probability of driving aptitude identified by LLGMN and the presence or absence of driving aptitude. The classification accuracy of driving aptitude by the selected indices was evaluated using AUC values. This study examines the validity of the indices selected based on the proposed method by comparing the results with those of permutation importance.
The evaluation value of permutation importance, \(PI_i\), was calculated based on the 11-fold cross-validation using LLGMN on the dataset created with only the indices selected by the proposed network to verify whether the weight \(w_i\) of the proposed network expresses the importance of the indices. Since the permutation importance calculates the evaluation value \(PI_i\) for each fold of the cross-validation, 11 evaluation values can be obtained for each index i. This study calculates the average of \(\_i, PI^_i, \ldots , PI^_i\}\) obtained for each index in cross-validation as permutation importance for the final evaluation.
We also evaluated the prediction ability of the proposed method by comparing it with conventional methods. The LLGMN with dimensionality reduction by partial KLI [31, 34, 35] and Lasso regression were used as conventional methods. As an indicator of the importance of the selected indices, the reduction rate of the AUC value generated by deleting each index after dimensionality reduction was used in LLGMN with dimensionality reduction by partial KLI, and the magnitude of the standardized partial regression coefficient was used in Lasso regression.
Table 4 List of indices used in the analysisThe proposed network was trained using stochastic gradient descent (SGD) with a learning rate of 0.01, a batch size of 50, and a number of epochs of 10,000. The learning was terminated when the loss did not improve by more than \(1\times 10^\) for more than 5 epochs. The regularized parameter \(\lambda\) of the proposed network was optimized using the tree-structured Parzen estimator (TPE) [36]. The detailed settings of the TPE are described in Additional file 1.
Statistical analysisFisher’s exact test was performed to confirm the relationship between the evaluation of driving aptitude by the indices selected by the proposed network and the evaluation by the instructor of the driving school at a significance level of 5%. The evaluation of driving aptitude by the indices selected by the proposed network was discriminated against using thresholds of the maximum sum of sensitivity and specificity attributed to the ROC analysis. Additionally, Yule’s correlation coefficient was calculated to confirm the strength of the relationship. The AUC values for the conventional methods and the proposed method were calculated and compared using the Holm-adjusted Delong test at a significance level of 5%.
Comments (0)