
Remember me
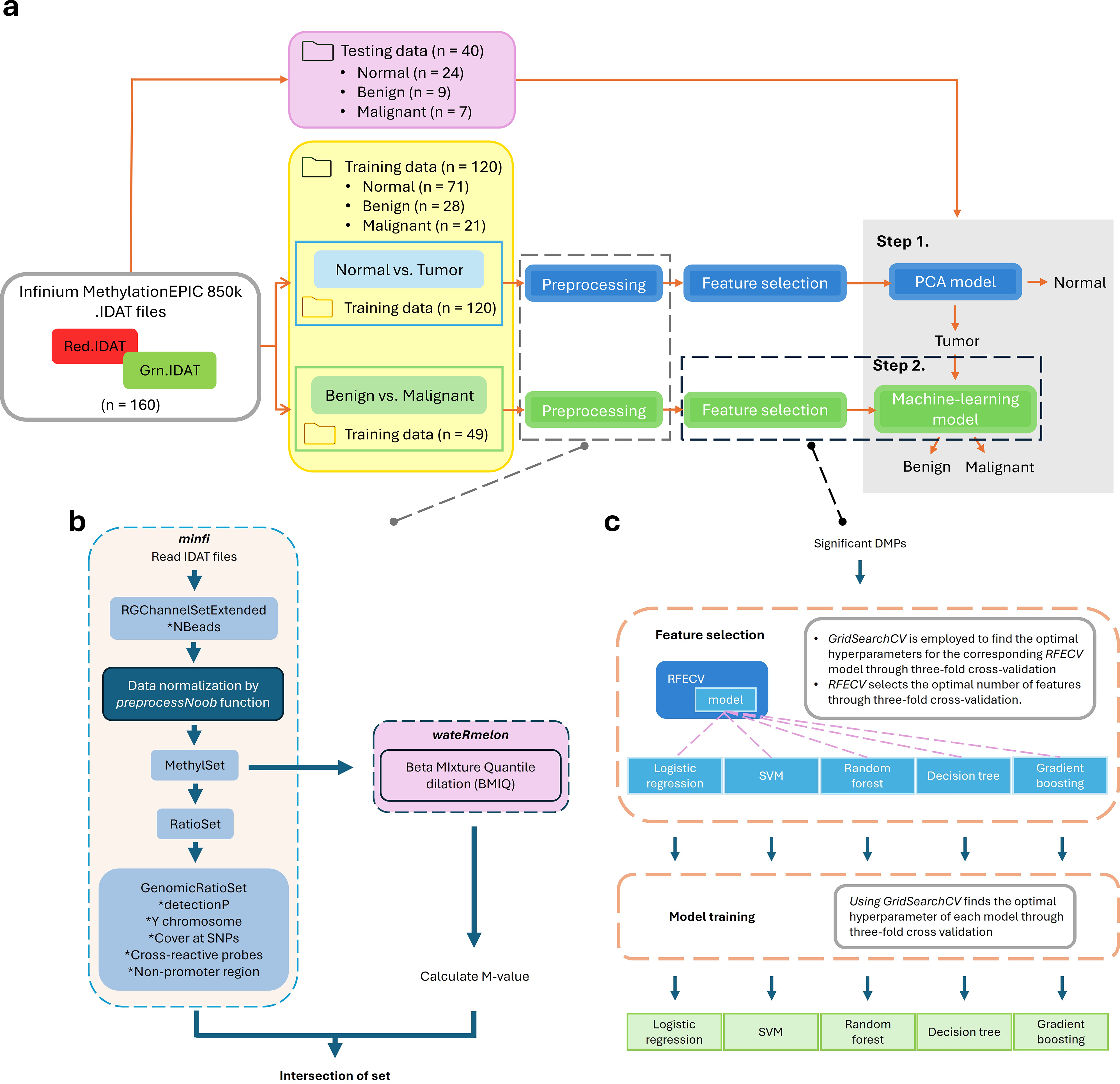









We extracted eligible instrumental variables (IVs) from GWAS summary data on COVID-19 and 17 common digestive diseases. SNPs significantly associated with COVID-19 were used as the IVs. The outcome variable was the presence of the 17 common digestive diseases, and a TSMR analysis was conducted. For exposures and outcomes with causal relationships, we further examined the causal relationship between potential mediators and outcomes, as well as the causal relationship between exposures and potential mediators. Once the true mediators were identified, we employed the Multivariable Mendelian randomization (MVMR) analysis to estimate the effect of these mediators on the outcome. We then multiplied this effect by the effect of exposure on the mediators to determine the mediator effect. Finally, we divided the mediator effect by the total effect of exposure on the outcome to calculate the proportion of mediation effect for each mediator (Fig. 1).
Fig. 1
This figure is a flow chart of the article. ① Z: effects of exposure on possible mediators, X: effects of exposure on outcome, X1: effect of exposure on the outcome after adjusting for potential mediators, Y: effect of potential mediators on the outcome after adjusting for exposure; ② MR satisfies the following three assumptions: (1) there is a strong association between the instrumental variable A and the exposure factor B; (2) the instrumental variable A is not associated with any confounding factors D that are related to the association between A and B–C; (3) the instrumental variable A does not affect the outcome C unless it is possibly achieved through its association with the exposure B
Data sourcesThe GWAS data for COVID-19 were obtained from the COVID-19 Host Genetic Initiative (HGI) (Round 5), encompassing three categories: SARS-CoV-2 infection (cases: controls = 38,984:1,644,784), COVID-19 hospitalization (cases:controls = 9986:1,877,672), and severe COVID-19 (cases:control = 5101:1,383,241). The GWAS data for 17 common digestive diseases were primarily derived from the UK Biobank study and the FinnGen study, including Gastroesophageal reflux disease (cases:controls = 129,080:473,524), irritable bowel syndrome (cases:controls = 10,939:451,994), Gastric ulcer (cases:controls = 1834:35,936), duodenal ulcer (cases:controls = 1908:461,025), Acute gastritis (cases:controls = 1284:189,695), Chronic gastritis (cases:controls = 5213:189,695), Ulcerative colitis (cases:controls = 4320:210,300), Nonalcoholic fatty liver disease (cases:controls = 894:217,898), Cholangitis (cases:controls = 778:195,144), Cholelithiasis (cases:controls = 19,023:195,144), Chlocystitis (cases:controls = 2013:195,144), Acute pancreatitis (cases:controls = 3022:195,144), Chronic pancreatitis (cases:controls = 1737:195,144), Acute appendicitis (cases:controls = 11,899:201,886), Crohn’s disease (cases:controls = 732:336,467), Colorectal cancer (cases:controls = 5657:372,016), and Gastric cancer (cases:controls = 6563:195,745). Based on previous observational and MR studies, we considered BMI and type 2 diabetes [9, 10] as potential mediators. The BMI data (Sample size: Number of SNPs = 336,107:10,894,596) were obtained from the UK Biobank study, while the type 2 diabetes data (cases:controls = 74,124:824,006) were obtained from the latest meta-analysis by Mahajan et al. based on two European ancestry GWASs. The populations in the aforementioned data sources, except for gastric cancer (East Asian ancestry), consisted of individuals of European ancestry, including both males and females. All datasets used in this study are publicly available, and ethical approval and written informed consent were obtained in the original studies (Additional file 1).
Selection of instrumental variablesWe collected SNPs significantly associated with COVID-19 (P < 5 × 10−8) and removed SNPs in strong linkage disequilibrium (LD) (r2 < 0.001, 10,000 kb) to avoid biased results [11]. SNPs associated with digestive diseases (P < 5 × 10−8) were excluded. To ensure a strong correlation with the exposure, we selected SNPs with an F statistic > 10 as IVs [12]. The F statistic was calculated using the formula F = R2(N − K − 1)/K(1 − R2), where R2 was calculated using the formula R2 = (2 × EAF × (1 − EAF) × Beta2)/[(2 × EAF × (1 − EAF) × Beta2) + (2 × EAF × (1 − EAF) × N × SE2)] [13, 14]. Palindromic SNPs with intermediate allele frequencies (allele frequencies between 0.01 and 0.30) were also removed [15]. Palindromic SNPs refer to SNPs where the alleles correspond to nucleotides that are paired with each other in a DNA molecule. In cases where SNP data were unavailable in the GWAS, proxy SNPs were obtained using the LDlink online platform (https://ldlink.nci.nih.gov/).
Statistical analysisIn this study, we primarily employed the IVW, MR-Egger regression, and weighted median methods for MR analysis. The IVW method involves weighting each instrumental variable by the inverse of its variance, assuming the absence of an intercept, and calculating the weighted average of the effect estimates from all instrumental variables. The MR-Egger method differs from IVW by considering the presence of an intercept during regression and using the inverse of the outcome variance as a weight for fitting. The Weighted Median Estimation (WME) is defined as the median of the weighted empirical density function of the ratio estimate. If at least half of the instruments are valid, the causal relationship can be consistently estimated. The heterogeneity test examines the differences between instrumental variables, where larger differences indicate greater heterogeneity. A random-effects model was used in this study to estimate the MR effect size. The pleiotropy test assesses whether multiple instrumental variables exhibit horizontal pleiotropy, commonly indicated by the intercept term in MR-Egger regression. A significant deviation of the intercept term from zero suggests the presence of horizontal pleiotropy [16]. The leave-one-out sensitivity test calculates the MR result with one instrumental variable excluded at a time [17]. If the MR result with the remaining instrumental variables significantly differs from the overall result after excluding a specific instrumental variable, it indicates the sensitivity of the MR result to that variable. Additionally, to validate the robustness of the results, MR pleiotropy residual sum and outlier (MR-PRESSO) were used to detect outliers. If outliers were identified, they were removed, and the analysis was repeated. All statistical analyses were conducted using R version 4.2.1 (R Foundation for Statistical Computing, Vienna, Austria). The Two-sample Mendelian randomization (TSMR) (version 0.5.6) [12] and MR-PRESSO (version 1.0) [18] R packages were employed for the MR analysis.
Comments (0)