
Remember me
Brain-Computer Interface (BCI) is a particularly created system to provide a direct path between the human brain and a computer-aided device. Its main objective is the facilitation of daily activities for specific individuals with severe motor disabilities due to various neurodegenerative disorders like amyotrophic lateral sclerosis, brain stem stroke, spinal cord injury, and various other diseases (Wolpaw, 2002). In the process of a BCI system, the main goal is the determination of the intent of an individual from various electrophysiological signals. Fundamentally, many BCI systems design a 5-stage algorithm, the stages of which are data acquisition, data preprocessing, feature extraction, feature selection, classification and performance evaluation (Isler, 2009; Degirmenci et al., 2023).
The first stage of such systems is called data acquisition. At this stage, data representing brain activities are collected. Various neuroimaging techniques such as Electroencephalography (EEG), functional Magnetic Resonance Imaging (fMRI), Magnetoencephalography (MEG), Positron Emission Tomography (PET), and optical imaging are available to collect brain activity in the literature (Sayilgan et al., 2022). However, EEG is the most popular technique among the different modalities due to its various advantages, especially ease of use, cheaper equipment, non-invasiveness, reliability, and disposability. Therefore, EEG signals have been mainly used to detect brain activities for BCI research studies (Chen et al., 2019; Sayilgan et al., 2022).
In prosthetic device design, various challenges were addressed in the literature. Designing reliable, functional, robust, and cost-effective BCIs as prosthetic systems is crucial for user acceptance. Many EEG-based BCI systems were designed to process various control signals (Wang et al., 2006; Sayilgan et al., 2022) and enable paralyzed patients to control a prosthetic device. Among these control signals, Motor Imagery (MI) is a well-structured methodology for BCI control because it induces more patterns of Event-Related Desynchronization/Synchronization (ERD/ERS) in various frequency bands. The distinctive patterns in MI-EEG signals enable the differentiation of multiple MI tasks. Consequently, the MI-EEG signal classification has become a major focus in BCI research.
In recent decades, various pattern recognition methods have been proposed to identify specific patterns within EEG-based signals for MI tasks. Machine learning, as one of those methods defines pattern recognition as a process consisting of the following stages: data collection, feature extraction, feature selection, and classification. In this respect, various feature extraction, feature selection, and machine learning algorithm methods have been used to analyze EEG signals following the data acquisition stage. Feature extraction, channel selection, and feature selection methods act as significant sub-components of MI-based BCI systems (Bashashati et al., 2007).
The feature extraction stage, which is the first crucial sub-component, determines a set of EEG signal features for effective discrimination of multiple MI tasks. The extracted features for MI-EEG signals analysis can be divided into the following categories: (i) time-domain features such as such as mean, mean absolute value, variance and the Hjorth parameters (Vidaurre et al., 2009; Sayilgan et al., 2021a), (ii) frequency-domain features such as the frequency of maximum spectral power, and the signal power within an extracted feature band using Fourier Transform (FT) and Power Spectral Density (PSD) (Mensh et al., 2004; Djamal et al., 2017), (iii) time-frequency domain features using various time-frequency representation algorithms such as Short-Time Fourier Transform (STFT) and Wavelet Transform (WT) (Ha and Jeong, 2019; Chaudhary et al., 2020), (iv) spatial features such as Common Spatial Patterns (CSP) and their different types, (Blanco-Diaz et al., 2022; Ang et al., 2012; Samek et al., 2013; Wu et al., 2014), and (v) various transformation-based features such as Empirical Mode Decomposition (EMD) and its various versions, and Intrinsic Time-Scale Decomposition (ITD) (Mwata-Velu et al., 2021; Degirmenci et al., 2024).
The second stage is called feature selection. The goal of feature selection is to avoid the curse of dimensionality and enable the design of cost-effective BCI systems. Feature selection methods have been used to extract the most informative and discriminative features and improve classifier performance for MI-based BCI systems. Among the various feature selection methods, Genetic Algorithms (GA) and Principal Component Analysis (PCA) have substantially been employed and implemented in the development of BCI systems (Bashashati et al., 2007; Mousa et al., 2016). Besides these methods, several other feature selection methods have also been used in BCI systems (Isler, 2009; Degirmenci et al., 2023; Yesilkaya et al., 2023).
In the aforementioned MI task classification studies, various pattern recognition methods have produced successful results. Consequently, various feature extraction, feature selection, and classification algorithms have been proposed for recognizing patterns in EEG signals. The literature studies show that it is important to utilize a combination of different types of feature extraction methods, feature selection methods, and machine learning algorithms and investigate them to design an efficient and cost-effective MI-based BCI system. Exploring the most effective combination of these methods through performance comparisons is the subtle aspect as it is crucial for the same purpose. The detailed comparison of different feature extraction methods together with different combinations of feature selection methods and different machine learning algorithms is relevant to explore effective combination of these methods. Additionally, studying the impact of the channel selection process is an important analysis for MI-based BCI systems. It is thought that, the analysis of effectiveness of different features from different feature categories and the effectiveness of different EEG channels will greatly contribute to this research area.
1.1 Related worksRecent studies have proposed or investigated various EEG features, feature selection methods, and machine learning algorithms to analyze MI-EEG signals.
Verma et al. (2014) conducted a study in 2014 by evaluating Discrete Wavelet Transform (DWT) and cross-correlation based features and implementing various classification algorithms to find the best feature extraction method and classification algorithm. They used five different machine learning algorithms to classify their feature sets. They achieved an average accuracy of 99.40% using DWT and Least-Square Support Vector Machine (LS-SVM) algorithm for binary-class extremity movement task classification on Dataset IVa of BCI competition III.
Lotte et al. (2009) presented subject-independent and subject-dependent BCI design that proposed a binary-class extremity movement task classification using the BCI Competition IV dataset IIa. They used the Filter Bank Common Spatial Pattern (FBCSP) algorithm by providing multi-resolution frequency decomposition and linear classification algorithms. Using these methods, they achieved the highest accuracy of 70.99% and 81.56% for the subject-independent and subject-dependent BCI design, respectively.
In 2020, Tabar and Halici (2016) proposed a deep learning-based approach using BCI Competition IV dataset 2b for binary-class extremity movement task classification. EEG signals were converted into 2D time-frequency maps using STFT. These feature maps were passed as inputs to Convolutional Neural Networks (CNN) architecture. They concluded that their proposed methods achieved a high accuracy of 77.60% for binary classification.
In 2017, Djamal et al. (2017) recommended a binary-class extremity movement task classification study using Fast Fourier Transform (FFT) and Learning Vector Quantization Network (LVQN). They only used one EEG channel (FP1 EEG channel) for EEG signal acquisition and signal processing. They obtained accuracy value of 70.00% with the FFT-based method.
In 2020, Molla et al. (2020) performed binary-class extremity movement task classification using the CSP method and Neighborhood Component Analysis (NCA)-based feature selection method. Their proposed methods using the Support Vector Machine (SVM) algorithm achieved average accuracy of 81.52% for subject-dependent binary classification on BCI Competition IV dataset 2b.
In 2023, Kabir et al. (2023) proposed binary-class extremity movement classification using CSP method for feature extraction stage. On the other hand, they examined the effects of different feature selection methods such as Correlation-based Feature Selection (CFS), Minimum Redundancy and Maximum Relevance (mRMR), and multi-Subspace Randomization and Collaboration-based unsupervised Feature Selection (SRCFS). They demonstrated the superiority of their proposed methods by using the SRCFS method and the Linear Discriminant Analysis (LDA) algorithm.
Gaur et al. (2015) presented an EMD-based approach to classify two different extremity movement tasks from BCI Competition IV dataset IIa. They selected and used only three channels, namely C3, C4, and/or Cz channels, for their proposed methods. Using these selected channels and the EMD algorithm, they achieved an average success of 70.20% with the LDA algorithm.
Mohamed et al. (2018) conducted a four-stage extremity movement task classification study using the ITD algorithm and Artificial Neural Networks (ANNs) algorithm. Using their proposed method, they achieved an average success of 92.20%.
In 2020, Dong et al. (2020) proposed a multi-class extremity movement task classification study using a novel hybrid kernel function relevance vector machine that combined the Gaussian kernel function and the polynomial kernel function. They used Phase Space Reconstruction (PSR) to project EEG data from the time domain into high-dimensional phase space. Then, they applied “One vs. One” Common Spatial Pattern (OVO-CSP) method to evaluate the characteristics of the Phase Space Common Spatial Pattern (PSCSP) features. These features were evaluated with their proposed hybrid structure. They achieved an average accuracy of 74.39% using Independent Component Analysis (ICA), PSR, and CSP methods on BCI Competition IV dataset IIa.
In 2024, Amiri et al. (2024) proposed channel selection using deep learning for multi-class extremity movement task classification. They used a flat CNN architecture for their feature extraction, channel selection, and classification process. They compared their channel selection method with different feature selection methods. According to their experimental results, they achieved 72.01% accuracy with their proposed methods and this accuracy value was higher than the success of other studies based on channel.
As outlined above, there exist many pattern recognition methods that were applied for the classification of extremity movement task. Majority of the proposed studies implement a complex classification algorithm that is unsuccessfully combined with all extracted features or selected features. The methods used generate a computational effort during classification and the classification performance remains at low values despite the load. Because these studies were not planned with detailed feature and effective channel analyses, on the contrary, they were designed and conducted to test the classification performance with more complex approaches (e.g., deep learning-based feature extraction and classification methods, and time-frequency representation based feature extraction methods).
To date, the effect of channel selection together with feature selection have not been investigated in literature. In this study, we used various MI-EEG features from different feature domains, such as time-domain, frequency domain, time-frequency domain, and non-linear domain of EEG signals, to analyze the success of feature extraction methods comparatively. We investigated four different feature sets and their two different combination feature sets. Additionally, we investigated the effects of the statistical significance-based feature selection method on each extracted feature set separately. One of the most important steps of this study is that it is the first study to apply detailed features and channel activity analysis, which also provides a different and new perspective on MI task classification studies. Feature and channel analysis were performed using statistically significant feature distribution, which represent the selected statistically significant feature distribution among 22 EEG channels for each feature set (time-domain, frequency-domain, time-frequency domain, and non-linear domain). We used nine different classification algorithms to reveal the effect of these methods. The classification was carried out using both all features and selected features to investigate the effect of the statistically significant-based feature selection method in this study.
1.2 ContributionsThe primary contributions of this study are as follows:
• Various feature domains, including time, frequency, time-frequency, and non-linear domains, were implemented to the feature extraction process, and the effects of these feature sets were investigated for binary-class and multi-class extremity movement task classifications separately.
• The effect of the statistical significance-based feature selection method was investigated for each feature set on binary-class and multi-class extremity movement task classifications.
• Feature and channel analysis were implemented using channel-based statistically significant feature distribution among 22 EEG channels for binary-class and multi-class extremity movement task classifications.
• To show the effect of the statistically significant feature selection method we comparatively evaluated nine different classifier algorithms using six different feature sets of all features.
• Finally, it must also be noted that this is the first study where the detailed feature and channel analysis are implemented for each feature set in addition to the investigation of the effects of different feature domains on extremity movement task classification, to the best of our knowledge.
2 Materials and methodsThe design of this study includes five stages, which were performed in the given order: data acquisition, feature extraction, feature selection, classification, and performance evaluation. The detailed background regarding each stage is provided in the respective sub-headings. The visual workflow of the multi-class extremity movement classification study is shown in Figure 1 with its five stages. Furthermore, in this study, motor imagery tasks of the right and left hands were differentiated for binary-class extremity movement classification.
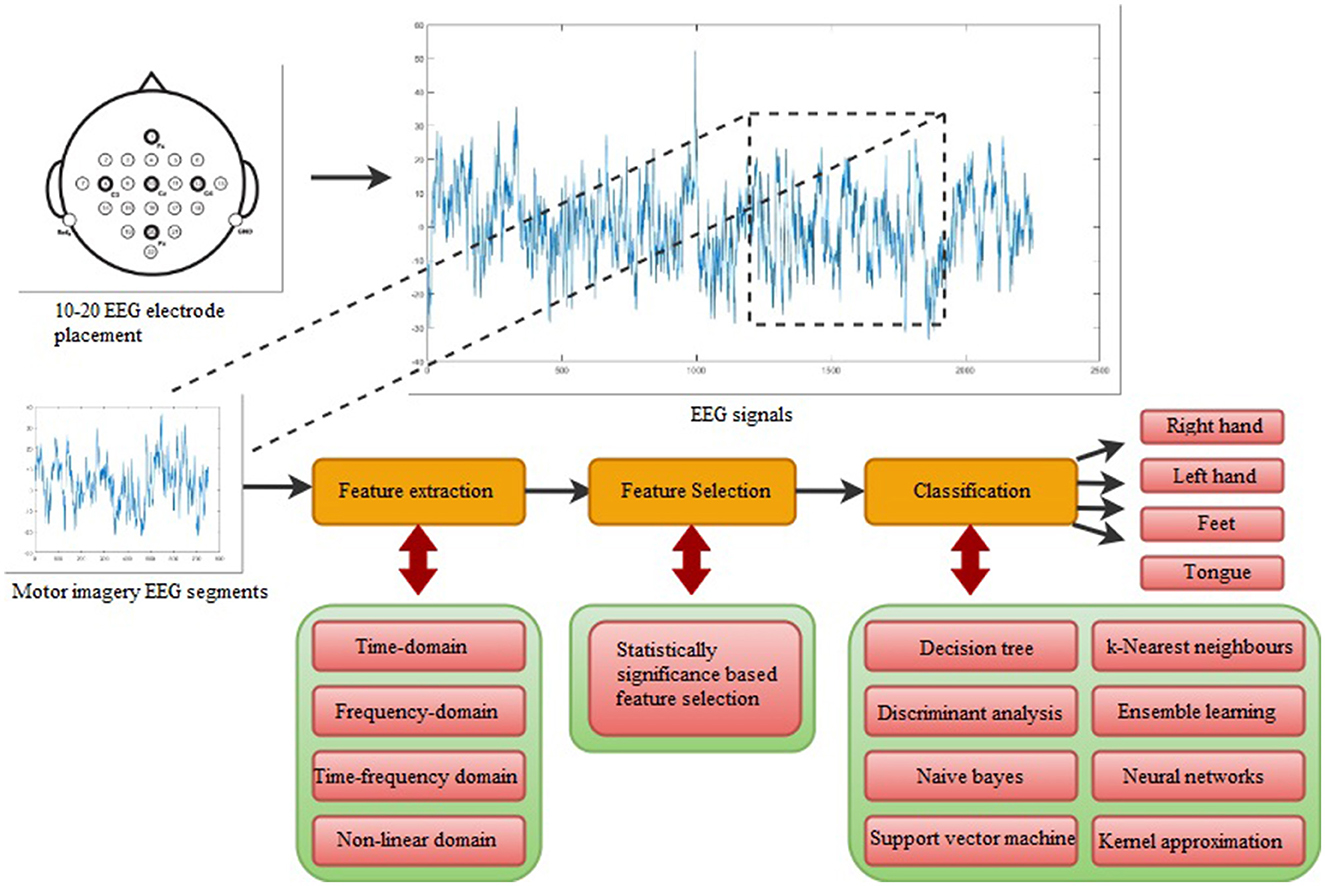
Figure 1. The flowchart of the suggested multi-class extremity movement classification study.
2.1 Data acquisition and datasetAs the source of data, BCI Competition IV Dataset IIa, which is a publicly available dataset for motor imagery EEG signal analysis, is adopted for binary and multiple extremity movement task classifications (Brunner et al., 2008). It consists of 22-channel EEG data that were recorded from 9 subjects (4 women and 5 men). The sampling rate was set at 250 Hz and EEG data were recorded via 22 Ag/AgCl electrodes. While recording of EEG signals, two filters were applied, i.e., a band pass filter operating between 0.5 Hz and 100 Hz and an additional 50 Hz notch filter, which is used to suppress line noise (Yan et al., 2021). Acquisition of EEG signals occurred during 4 MI tasks. Therefore, this dataset includes data for 4 different MI tasks, which are the imagination of movement of the left hand, right hand, feet, and tongue. The experiment is scheduled as two different sessions, each of which include six runs executed in two days. There are 12 trials available for each motor imagery task in a run, giving a total of 48 trials available for each run. Moreover, 288 trials were conducted after 6 runs for each subject. Therefore, cue-based motor imagery signals were recorded by imagining movements of four different extremity. The corresponding 3 s motor imagery EEG signals were segmented from long EEG signals for each trial before feature extraction and in further stages.
2.2 Feature extractionWithin the scope of this study, time-domain, frequency-domain, time-frequency domain, and non-linear features were calculated by utilizing 22-channel EEG signals to provide feature sets after extraction of MI EEG segments.
• Time-domain feature set: In the time-domain feature set, 24 different time-domain features were extracted using the directly original field of the EEG signals. These time-domain features are based on the amplitude and statistical changes of the EEG signal (Yesilkaya et al., 2023; Degirmenci et al., 2023).
• Frequency-domain feature set: The frequency-domain feature set was created using FT. Frequency-domain features were extracted based on the frequency-domain representation of the MI-EEG signal. The different EEG sub-bands, which are delta (δ), theta (θ), alpha (α), beta (β), and gamma (γ), were embedded in frequency-domain of original EEG signals. These EEG sub-bands were extracted from frequency representation of EEG segments by utilizing the Fast Fourier transform. Following the extraction of EEG sub-bands, the relevant and distinctive MI frequency characteristics were computed based on the energy, variance, and entropy values of different EEG sub-bands for each EEG segment. These frequency-domain features provide information about how power, variance, and entropy (irregularity) change in definite corresponding frequency bands. Their mathematical evaluations are detailed as follows (Sayilgan et al., 2021a; Degirmenci et al., 2023):
Energyf=∑k=1My(k)2 (1) Variancef=1M-1·∑k=1M(yk-y¯)2 (2) Entropyf=1log(M)·∑k=1MP(y(k))log(P(y(k)) (3)where f denotes the type of EEG sub-bands, M denotes the maximum frequency, and y(k) denotes the FT of a real discrete time EEG segment. In the formula, “y¯” indicates the average of the “y” signal. The probability of the EEG segment, which is in the corresponding frequency band, is denoted as P(y(i)).
• Time-frequency domain feature set: A time-frequency domain feature set was obtained using Wavelet Transform (WT). Using this algorithm, EEG signals were divided into frequency bands (δ, θ, α, β, and γ). Then, these frequency bands' energy, variance, and entropy values were calculated as time-frequency domain features. DWT utilizes both time and frequency domain information of EEG signals, and its several filters and bandwidths provide multi-resolution analysis (Sayilgan et al., 2021a). It can be utilized as a dual Finite-Impulse Response filter. Utilizing the frequency responses of these filters, high-frequency and low-frequency components of EEG signals are decomposed from EEG signals. The identical wavelet coefficients are selected in both Low-Pass (LP) and High-Pass (HP) filters for the multi-resolution algorithm of WT (Gandhi et al., 2011). The scaling parameter, defining the oscillatory frequency and the length of the wavelet, is associated with the coefficients of LP filter, while the wavelet function is associated with the coefficients of HP filter. The outputs of these filters are indicated as the approximate (a) coefficients and the detailed (d) coefficients, respectively. The original EEG time series are completely decomposed as (a) and (d) coefficients based on the defined decomposition level. The subsets of the corresponding coefficients of decomposition levels are included depending on the frequency domain of EEG sub-bands for the decomposition of five EEG frequency bands. In the extraction of the time-frequency domain feature set, the Wavelet packet decomposition is utilized, and the decomposition of the EEG frequency bands was performed at seven decomposition level for 250 Hz sampling frequency of EEG time series (Degirmenci et al., 2023). The “Haar” wavelet function is selected for Wavelet packet decomposition application in the feature extraction process (Sayilgan et al., 2021a; Degirmenci et al., 2023). Following the execution of this algorithm, five different EEG sub-bands were extracted from EEG signals and their energy, variance, and entropy values evaluated as features. According to the following mathematical formulations, the energy of each decomposition level was evaluated (Gandhi et al., 2011):
Energydi=∑j=1N|dij|2,i=1,2,3,...,l (4) Energyai=∑j=1N|aij|2,i=1,2,3,...,l (5)where the detail (dij) and approximate (aij) coefficients indicate the corresponding subsets for each frequency band. The wavelet decomposition level, which is defined in [1, l], is indicated as i = 1,2,3, ...,l. N represents the number of d and a coefficients.
The mathematical formula for computing variance of each decomposition level is defined as follows (Gandhi et al., 2011):
Variancei=1N−1·∑j=1N(dij−μi)2,i=1,2,3,...,l μi=1N·∑j=1Ndij,i=1,2,3,...,l (6)where μi denotes the mean of the decomposition level.
The entropy of each decomposition level is evaluated based on the following equation (Isler, 2009):
Entropyi=∑j=1Ndij2log(dij2),i=1,2,3,...,l (7)• Non-linear feature set: In non-linear feature set, non-linear parameters were calculated using Poincare plots of EEG time series. Poincare plot measures provide the non-linear dynamics that are embedded in MI-EEG signals. These measures were adopted and computed in this study considering their clinical ability demonstrated in similar studies (Isler, 2009; Narin et al., 2014). A Poincare plot is a simple 2-dimensional graph where each EEG sample (xi) is located on the x-axis and the next EEG sample (xi+lag) is located on the y-axis. After the indication of xi and xi+lag intervals, Poincare plots were obtained for each EEG signal. Thereafter, an ideal ellipse was applied to the graph of the Poincare plot, and the standard deviation of the distance of the points on these plots denoting the width (SD1) and length (SD2) of the ellipse (Brennan et al., 2001) were evaluated. The mathematical formulation of these measures is detailed as follows (Isler, 2009):
xi=(x0,x1,...,xN-m) (8) xi+lag=(xm,xm+1,...,xN) (9) xb=xi+lag+xi2 (10)In the Equations 8, 9, the EEG sample data and its next interval EEG data are indicated as xi and xi+lag, respectively. SD1 and SD2 measures were evaluated using defined EEG intervals based on the Equations 10, 11. The standard deviation of the defined time interval vectors is denoted as SD in Equation 11. Also, the selected intervals were defined based on the m-lagged Poincare plot measurements. lag=m was defined, and m was identified as 1 and 9 for the interval-defining process. The measures were also calculated for the lag=9 condition due to its positive outcomes from our previous study (Degirmenci et al., 2022a). The designed non-linear feature set, which lag=9 condition provided a relevant and effective feature set for MI-EEG signals (Degirmenci et al., 2022a). Therefore, (SD1) and (SD2) measures were calculated for each lag=m condition. Additionally, the products (SD1SD2) and the rates (SD1/SD2) were calculated to examine the relations of (SD1) and (SD2). Four Poincare plot measures were calculated for each lag=m condition. In the non-linear feature set, a total of 8 Poincare plot measures were calculated from each EEG sample for two different lag=m conditions.
2.3 Statistical significance-based feature selectionFeature selection reduces the computational load by selecting effective and relevant features for classification (Narin et al., 2014). Selection of these features and application of them for classification improve the classification performances (Yesilkaya et al., 2023). There are several feature selection methods such as recursive feature selection (Al Ajrawi et al., 2024), LASSO regression (Huang et al., 2024; Muthukrishnan and Rohini, 2016), Correlation-based Feature Selection (CFS) (Kabir et al., 2023), Maximum Relevance Minimum Redundancy (MRMR) (Kabir et al., 2023), statistical significance-based feature selection (Bulut et al., 2022; Degirmenci et al., 2022b, 2023), and Genetic Algorithm (GA) (Ramos et al., 2016) for MI task classification in BCI research area. In this study, we preferred statistical significance-based feature selection methods since it is an easy-to-use method and its effectiveness has been proven in previous studies (Degirmenci et al., 2022b, 2023).
In this study, a total of four different feature sets were obtained, and the statistical significance-based feature selection process was performed for each of them separately. Additionally, motor imagery EEG signal classification was performed for both binary-class and multi-class extremity movement task classifications in this study. Thus, two different statistical significance based feature selection methods were employed to determine relevant and discriminative features. These methods are the independent t-test and one-way ANalysis Of VAriance (ANOVA), which are used for binary-class and multi-class extremity movement classifications, respectively. The class number of preferred classifications has an effect on the selection of the types of proposed feature selection method. The independent t-test was applied in feature selection of binary extremity movement classification to determine the relevant features of all provided feature sets. This method is mostly preferred to appear significance of differences between measures of two definite groups (Degirmenci et al., 2023; Narin et al., 2014). On the other hand, the ANOVA test, which is commonly utilized to show whether there is a difference between the means in states where there are two or more groups, was applied in multi-class extremity movement classification to determine the relevant features. Using these methods, p-values, which indicate the statistical significance of features, were calculated first. Then, the statistically significant features were determined considering the statistical significance level (α) equal to 0.05 in this study. Therefore, the effect of the independent t-test and ANOVA test was investigated on four different feature sets. To investigate and prove the effectiveness of these tests, the results of classifications performed using all extracted features and selected statistically significant features are compared.
2.4 ClassificationIn this study, EEG features in different feature sets have been classified by utilizing nine well-known classification algorithms. The selected classifiers and interrelated algorithms were applied by using the Classification Learner Toolbox, which is an element of Statistics and Machine Learning Toolbox available in the Matlab software package (Matlab, 2023). The technical information about corresponding machine learning algorithms is described below:
• Decision tree: Decision Tree (DT) is a type of common machine learning algorithm that creates and runs over structures consisting of root nodes, child nodes (e.g., leaf nodes), and branches (i.e., edges). The name of the classifier was inspired by its tree-like structure. It is a fast classification method and separates the data into various subgroups. In its structure, a feature is represented with each internal node of the tree; the feature combinations that result in classifications are indicated as branches of the tree, and class labels are indicated as leaves of the tree. The class of samples is predicted in the decision tree structure by evaluating from root to leaf (Tzallas et al., 2009; Sharma et al., 2022). The decision tree classifiers named the fine, medium, and coarse algorithms were employed in the classification process of this study.
• Discriminant analysis: The Discriminant Analysis (DA) classifier is one of the pattern recognition methods, and its main objective is to correctly separate the independent variables in the data into homogeneous groups (Chakrabarti et al., 2003). In this study, for the purpose of classification, linear and Quadratic Discriminant Analysis (QDA) algorithms were included in the study design. Among these classifiers, the LDA algorithm defines the group elements and estimates the probability that each element belongs to different groups. Then, the sample is assigned to the group with the highest probability result. It supposes that the predictors have a Gaussian distribution and are normally distributed. It also creates a linear discrimination function that assumes that different classes have class-specific elements and equal variance/covariance. Contrary to the LDA algorithm's assumption, variance/covariance equality is not accepted in the Quadratic Discriminant Analysis algorithm. In this algorithm, the covariance matrix may be different for each class category. Hence, it constructs the discrimination function to be quadratic (Lotte et al., 2018; Hart et al., 2000).
• Logistic regression: Logistic Regression (LR) is a commonly applied machine learning algorithm for binary classification. The fundamental process of this algorithm is based on representative of the probability of an event. Binary classification results are generated as outputs. In the technique of this algorithm, the logistic function, which is also known as the sigmoid function, is adapted to the corresponding data using probability (Tzallas et al., 2009). It maps the data points regarding a line, and all log-odds values are determined. These values are expressed as inputs and transformed to probability values. These calculated values are evaluated as the algorithm's outputs. Therefore, this input-output conversion is important for fitting the sigmoid function. In the classification process of this algorithm, the various line rotations are defined and evaluated via calculating, logging, and summing conditional probabilities for all steps. Then, the best sigmoid function that provided the maximum probability is calculated (Alkan et al., 2005).
• Naive Bayes: The Naive Bayes (NB) algorithm is a statistical classification approach that uses the Bayes Theorem on probability and variables' independence and normal state (Miao et al., 2017; Hart et al., 2000). Hence, all features provide the same effect value on the prediction process. The classification process is performed by employing the sample's likelihood of belonging to each class in the feature set. The class that provides the highest probability of membership is defined as the datum's predicted class. The Gaussian and kernel NB classifiers were incorporated and evaluated in this study.
• Support Vector Machine: The SVM algorithm, which was proposed by Vapnik (1999), is one of the well-known machine learning algorithms. It can be used in both classification and regression processes (Hart et al., 2000). It generates a model finding decision boundaries defined by a hyperplane to separate the data into categories based on the geometric characteristics of the data set. The optimum hyperplane that will best separate this data in space is selected to provide more accurate classification performance. The data is assigned as an element of a different class dependent upon which side of the hyperplane it is located on Bascil et al. (2016). In this study, various types of this algorithm, such as linear, quadratic, cubic, fine Gaussian, medium Gaussian, and coarse Gaussian, were adopted and run.
• k-Nearest Neighbor: The k-Nearest Neighbor (kNN) is a non-parametric machine learning algorithm, and it is computed in both classification and regression studies. It is a distance-based learning model and predicts the datum's class by evaluating the distance of the implemented sample to all k neighbors and assigning them as the one with the most prevalent neighbors (Tzallas et al., 2009; Isler, 2009). Various distance calculation methods are available (Hart et al., 2000). In this study, fine, medium, coarse, cubic, cosine, and weighted algorithms among the kNN classifiers are selected as classifiers. The Euclidean distance measurement method is one of the most computed distance calculation methods, and it is implemented for employing fine, medium, coarse, and weighted kNN algorithms (Hart et al., 2000; Isler, 2009). In cubic and cosine kNN algorithms, cubic and cosine distance measurement methods were utilized, respectively.
• Ensemble learning: As the name implies, it is an ensemble of classifier algorithms. Basically, different classifiers are brought together as a combination to form a single classifier algorithm. Ensemble methods, rather than the individual classifiers that make them up, generally provide far more accurate results thanks to different properties of classifiers such as reduction of variance (bagging), reduction of bias (boosting), and improvement predictions eliminating the over-fitting problem. Ensemble methods assume that a single prediction algorithm may not obtain precise and accurate classification results owing to some problems such as possible noise, overlapping data distributions, and outliers in the data (Khare et al., 2022; Matlab, 2023). Therefore, this method assumes that there is no single classifier that computes best for every classification study (Sayilgan et al., 2021b). Ensemble Learning (EL) algorithms have been frequently employed in recent research for the classification of different biomedical signals (Sayilgan et al., 2021b,a, 2022, 2020, 2019; Degirmenci et al., 2022a,b). In this study, Boosted, Bagged, Subspace Discriminant, Subspace k-NN, and RUSBoosted Trees algorithms are adopted.
• Neural networks: Neural networks (NN) classification algorithms are typically coined to have good predictive accuracy and can be used for multi-class classifications as well as binary classifications. Compared to other machine learning algorithms, the training process is longer due to the number of layers in their structure and many other parameters (Narin and Isler, 2021). NNs' architectural elements are layers of nodes, namely, the input layer, fully connected hidden layers, and output layer. Essentially, NNs' NNs differ by the number of fully connected hidden layers between the input and output layers, which affects the complexity of classifiers. Architectural complexity of NNs increases with the size and number of fully connected layers (Narin and Isler, 2021). The first fully connected layer of the neural network has a connection from the network input (predictor data), and each subsequent layer has a connection from the previous layer. Each fully connected layer multiplies the input data with a weight matrix and then adds a bias vector. An activation function follows each fully connected layer. The final fully connected layer and the next softmax activation function generate the output of the network, i.e., classification scores (next probabilities) and prediction labels (Narin and Isler, 2021; Richard and Lippmann, 1991; Pan et al., 2012). In a NN, to reach the optimum number of fully connected layers, as Geoffrey Hinton recommends, is to add layers until the model starts to overfit the training set (LeCun et al., 2015; Srivastava et al., 2014). In this study, narrow, medium, wide, bi-layered, and tri-layered NN algorithms were run for the classification process to investigate the effect of the size of the fully connected layers.
• Kernel Approximation: Kernel Approximation (KA) classifiers can be used to carry out non-linear classification of data containing many samples (Lei et al., 2019; Maji et al., 2008). In large datasets, KA classifiers tend to train and predict faster than SVM classifiers with Gaussian kernels (Maji et al., 2008). Gaussian kernel classification models map predictors in a low-dimensional space to a high-dimensional space and then generate a linear model to transform predictors in a high-dimensional space (Lei et al., 2019; Maji et al., 2008). In this study, support vector machine and logistic regression KA classifiers were employed for the purposes of classification.
2.5 Performance evaluation metricsIn this study, a 5-fold cross-validation method was performed to calculate the performance of the classification process by defining train, test, and validation data. In the evaluation of classification results, the reel labels of EEG segments were compared to those predicted by the classification algorithms. The MI classification results of machine learning algorithms consist of True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN) in the binary and multiple classifications. Using these values, the statistical measure of Accuracy (ACC), which is the number of correctly predicted segments, is utilized for the evaluation of proposed methods. The mathematical formula for the accuracy performance metric is given in Equation 12 (Hart et al., 2000; Degirmenci et al., 2024).
ACC=TP+TNTP+FN+TN+FP (12) 3 Results and discussionIn this study, the binary-class and multi-class classification problems of MI-EEG signals were analyzed with six different feature sets, a statistical significance-based feature selection method, and nine different classification algorithms. Firstly, four different feature se
Comments (0)